知识进化算法及其在关联分类中的应用
2015-04-21梁红硕刘云桥
梁红硕, 刘云桥, 赵 理,2
(1. 石家庄职业技术学院,河北 石家庄 050081;2. 北京理工大学, 北京 100081)
知识进化算法及其在关联分类中的应用
梁红硕1, 刘云桥1, 赵 理1,2
(1. 石家庄职业技术学院,河北 石家庄 050081;2. 北京理工大学, 北京 100081)
针对传统的关联分类算法在构造分类器的过程中需要多次遍历数据集从而消耗大量的计算、存储资源的问题,该文提出了一种基于知识进化算法的分类规则构造方法。该方法首先对数据集中的数据进行编码;然后利用猜测与反驳算子从编码后的数据中提取出猜测知识和反面知识;接着对提取出来的猜测知识进行覆盖度、正确度的计算,并根据不断变化的统计数据利用萃取算子将猜测知识与反面知识进行合理的转换。当得到的知识集中的知识的覆盖度达到预设的阈值时,该数据集中的知识被用来生成分类器进行分类。该方法分块读入待分类的数据集,极大地减少了遍历数据集的次数,明显减少了系统所需的存储空间,提高了分类器的构造效率。实验结果表明,该方法可行、有效,在保证分类精度的前提下,较好地解决了关联分类器构造低效、费时的问题。
知识进化;猜测;反驳;关联分类
1 引言
传统的进化算法是建立在达尔文的自然选择学说基础上,对生物自然进化过程的模拟,是人们对从自然演化过程中抽象出来的概念、原则和机制的类比应用,已被广泛用来解决复杂的计算问题,目前的研究工作大多仍集中在生物自然选择层面上[1-2]。然而,科学哲学家在研究科学发展的过程中发现:科学发展过程也实际存在着类似的进化机制,但是这种机制更具有自身的特殊性。著名批判理性主义的创始人卡尔·波普尔指出[3]“科学理论的选择是一个类似于达尔文所说的自然选择过程, 我们的知识总是由假说构成的,它通过在生存斗争中存在下来而显示它的相对适应性, 竞争消除了那些不适应的假说。……科学知识的独特之处是对我们理论的自觉和系统的批判,使得生存斗争更艰难。”
和其他分类方法相比,利用关联规则构造的关联分类器取得了比较高的分类精度和分类效率[4-5]。然而,传统的关联分类方法(例如,CBA和CMAR)存在的一个主要的问题就是:在构造关联分类器时,需要消耗大量的时间扫描可能的规则空间。特别是在支持度阈值被设到一个很小的值时,这一现象更为明显[6-7]。文献[8]提出一种被称为“CPAR”的分类方法,该方法联合了关联分类和传统的基于规则分类的方法的优点。该方法利用贪婪算法直接从训练数据中产生规则,而不像传统的关联分类方法那样先产生大量的候选规则,再生成分类器。文献[9]提出一种被称为基于人工免疫算法的关联分类算法(AIS-AC),该算法只寻找能构造有效分类器的规则的子集来生成分类器,提高了关联分类的效率。杨广飞等[10]提出了一种叫做“EvoCMAR”的进化的分类方法直接挖掘分类的关联规则。
本文提出一种基于波普尔知识进化论的知识进化算法(KEA)来有效地生成关联分类器。和以往的算法不同,该方法整合了分类规则的寻找和分类器的生成,利用猜测与反驳操作来代替传统的变异操作,克服了普通的进化算法在关联分类规则搜索时,过度局部搜索的问题。同时,合理设计知识的覆盖度阈值,使之符合构造优化分类器的要求。
本文剩余部分组织如下:我们首先回顾了关联分类和知识进化的有关特点;然后提出了用于关联分类的知识进化算法;接着利用实验对该算法做了相应的分析和比较;最后指出了该算法的优势与不足。
2 相关工作
2.1 关联分类
Liu首先提出了一种关联分类方法[11],被称为CBA方法。该方法基于发现的关联分类规则来构造分类器。关联分类规则的挖掘和关联规则的挖掘的不同之处就在于,前者可以同时挖掘用来表示不同分类的频繁项集,而后者挖掘的是所有的频繁项集。假设一个数据集是一个标准的、由N个实例组成的关系表,每个实例可以用t个不同的属性来描述。我们可以把每个实例当做一个由若干属性和一个类标签组成的集合。每个属性被称为一个项。
关联分类的框架由以下两步组成: (1)产生所有的关联分类规则,形式如“iset=>c”,其中iset表示属性的集合,c表示类。(2)基于关联分类规则,构造分类器。一般来说,关联分类器的构造是基于分类规则的可信度大小,由关联分类规则的子集构成。
2.2 知识进化的特点
知识的进化过程实质上就是已确立的思想习惯与扩大了的观察领域的矛盾的不断消除和适应的过程。新知识的产生是一种“识知”的过程,是人脑不断与自然环境、社会环境进行信息交换的过程,是人类通过感觉器官,从外部环境中获得各种数据、信息与头脑中存储的原有知识共同作用的结果。因此,知识的增长是历史知识系统与当前外部信息交互作用,通过系统内部创新,不断实现适应外部环境的一个动态过程。该过程遵循着“实践——认识——再实践——再认识”的认识发展辩证途径[12]。
知识的进化包括质的发展和量的增长两方面。所谓知识量的增长,是指一定历史阶段人类全部知识总量的增加,而知识质的发展,是指人类知识相对于以前的某一历史阶段在深度和真理度方面的提高。知识的进化是一个历史性的概念,知识的进化总是需要两个特征相互对照才能显现出来。知识无论在量方面的增长,还是在质方面的发展,都应包括内容方面的进化、形式方面的进化、工具方面的进化等几个方面同时呈现出上升性的变化趋势,它们是构成知识进化或知识增长的因素。
2.3 试错法
试错法与理论推导法相反,是一种常见的解决问题、获取知识的方法。该方法通过间断或连续地改变黑箱系统的参量、试验黑箱所作应答,来寻求达到目标的途径。其中,猜测与反驳是试错法的两个重要步骤。通过猜测,我们可以积极创造条件,在已经掌握的部分事实材料的基础上,通过猜测、审查使事物的本质全部尽快暴露出来。通过反驳,我们可以在获得的初步结论中寻找毛病,发现错误,使认识得到提高[13]。试错法是猜测与反驳相结合的方法,该方法是对已有认识的试错,通过寻找能推翻、驳倒已有认识的反例,并排除这些反例,从而使认识更加精确、科学。
3 知识进化算法及其在关联分类中的应用
3.1 知识的表示
事实: 每次实践得到的真实结果。
假说: 是基于事实提出的、对系统相关特征、逻辑关系所做出的猜测,是未经证实的知识。
反面知识: 是被事实证明错误的假说。
在知识进化算法中,一方面,随着实践的不断向前推进,猜测算子不断产生新的假说。这些假说必须满足简单、可独立检验、尽可能长久地不被推翻替代等相关特性;另一方面,反驳算子不断将以往产生的猜测知识与本次事实相对比。被证伪的猜测放入
反面知识集,与本次事实相符或无关的猜测知识,继续留在猜测知识库,等待进一步检验。
3.2 知识进化算法框架
知识进化算法的基本框架由以下三部分组成:假说集(Hypotheses Set)、反面知识集(Inaccurate Knowledge Set)和猜测反驳萃取法(Conjecture、Refutation and extraction Method),如图1所示。
知识进化算法(KEA)的伪代码如下:
Algorithm KEA-2 Begin t=1 Initialize H0Initialize I0While(the termination condition is not achieved) Ht=conjecture(It-1,Ht-1,Ft) It=refute(Ht-1,It-1,Ft) Ht= Ht+extract(It-1) t=t+1 end reduce end
其中,t为知识进化代数,H0为初始假说集,I0为初始反面知识集,Ht,It,分别为第t代假说集和反面知识集,Ft为第t次事实,conjecture()为猜测函数,refute()为反驳函数。
3.3 基于知识进化算法的关联分类
在本文提出的知识进化算法中,将数据集中每条记录看作一个事实,将针对该数据集的关联规则看作知识。算法利用提出的猜测与反驳算子代替传统进化算法中的选择、交叉、变异等操作。
3.3.1 事实及知识的编码
知识进化算法中的编码方式包含实值编码、二进制编码和符号编码,具体使用哪种编码方式应该由算法的应用背景决定。本算法中考虑到关联分类规则的复杂性,将知识进化算法的编码原则定义为根据事实或知识个体中属性值的不同,采用不同的编码方式对属性进行编码,最后,将这些编码按一定顺序连接,组成个体。
如图2所示,本文中按属性不同,将事实分割为不同的基因段, Ui表示条件属性,V表示决策属性。

图2 事实的编码
规则知识,包含假说知识和反面知识,采用与事实类似的编码方式,考虑到知识规则的简单性,将规则知识中不包含的属性所对应的基因段的值为“O..O”(“O”的个数表示该基因段的长度)。具体情况见图3。

图3 知识的编码
3.3.2 猜测算子
标准进化算法中变异算子的基本内容是对个体基因座上的基因值作相应变动,其目的是提高算法的局部随机搜索能力,并维持群体多样性,其特点是随机性、无逻辑性。知识进化算法中猜测算子其基本内容也是对个体基因座上的基因值作相应变动,然而这种变动本身强调的是知识体系之间的逻辑性和关联性,因而,逻辑推理是猜测算子得以进行的主要手段。
域Di: 组成实例的某个条件属性所对应的所有属性值与空值(用“O..O”表示)做并运算,就构成了某个属性的全域。
规则知识空间: 由条件属性和决策属性形成的一组域的迪卡尔积,可表示为式(1)。

(1)
其中,每条记录被称为一条规则知识。
猜测知识群: 将实践产生的事实中每个条件属性的值与空值做并运算,然后将所产生的不同条件属性的域及决策属性做迪卡尔积,就得到了某条事实所对应的猜测知识群R0,可表示为式(2)。
R0=D1′×D2′×...×Dn′⊆D1×D2×...×Dn=R

(2)
猜测操作: 顺序考察R0中每条知识ri(d1,d2,...,dn),若ri∈Rd(Rd为反面知识库),则将Rd中该条反面知识ri的覆盖数量Cri加1;若ri∈Rh(Rh为猜测知识库), 则将Rh中该条猜测知识ri的覆盖数量Cri加1;若ri∉Rh且ri∉Rh,则根据简单性原则按猜测概率p(ri)产生猜测知识ri,并将其放入猜测知识库Rh。
其中,猜测概率p(ri)可表示为p(ri)=1/L(ri),(L(ri)为该条知识ri所包含非空条件属性的个数)。
3.3.3 反驳算子
排除错误是知识进化的本质,反驳算子通过与当前实践的对比,来减少猜测知识的错误,并确保理论的被接受及运用。
定义1 AND*运算符,表示将两个二进制操作数按位进行逻辑与运算。
① 将当前事实对应分解为条件属性组合ri1′和决策属性组合ri2′;初始化猜测知识变化i(i=1)和最大猜测知识数量I。
② 若 i<=I, 则提取猜测知识库Rh中第i条猜测知识ri(d1,d2,...,dn),将其分解为条件属性组合ri1和决策属性组合ri2。
③ 反驳操作:
IF (ri1 AND* ri1′= ri1 AND ri2 <> ri2′) THEN (F(ri)= F(ri)+1; AND Rd=Rd ∪ ri);
IF (ri1 AND* ri1′= ri1 AND ri2 = ri2′) THEN (C(ri)= C(ri)+1);
IF (ri1 AND* ri1′ <> ri1) THEN (do nothing);
i=i+1;
转步骤②。
3.3.4 萃取算子
算法中,萃取算子的主要作用是不断统计反面知识库中每条知识的反驳度F(ri)。当反驳知识库中某条知识的反驳度低于某个给定阈值时,将该条知识转移到猜测知识库中,继续进行正确度判断。
反驳度Re(ri): 一条知识规则ri的反驳度F(ri)是通过统计该条知识规则的反驳数量与覆盖数量来衡量的,计算公式如式(3)。

(3)
其中,F(ri)表示记录ri的反驳计数个数,C(ri)表示记录ri覆盖的元组数。
3.3.5 知识的覆盖度与正确度
覆盖度C(ri): 猜测知识库或反驳知识库中知识规则ri的覆盖度C(ri),是指该规则的条件属性部分所能覆盖的数据集D中的实例个数。计算公式如式(4)所示。

(4)
其中,|D|表示数据集D中实例总数,N(ri)表示ri覆盖的实例数。
正确度A(ri): 知识规则ri的正确度A (ri)是指测试数据集D中, ri的所有非空条件属性及决策属性所能覆盖的实例个数与所有非空条件属性所能覆盖的实例个数之比。计算公式如式(5)。

(5)
其中,N(ri)′表示ri正确分类的实例数,N(ri)表示ri覆盖的实例数。
3.3.6 知识的约简
知识约简的目的是: 使最终得到的猜测知识集具有更少的规则知识条数。知识约简的方法: 将猜测知识库Rh中的每条猜测知识ri(d1,d2,...,dn)按支持度从大到小排序,当前m条知识所覆盖的记录总数超过该数据集的覆盖度阈值时,前m条知识就是本算法所求的精简后的知识集,该集合用来生成分类器。
3.3.7 知识进化算法的实现步骤
知识进化算法的实现步骤如下:
步骤1 读入一个数据块的记录(事实),通过对该记录块的分析,将获得的猜测知识加入到猜测知识库;
步骤 2 读入一个新的数据块,利用反驳算子检验猜测知识库中知识是否与新读入数据块中事实相矛盾。若矛盾,则将该知识投入反面知识库。
步骤3 利用猜测算子产生针对该数据块的新的猜测知识,将其加入到猜测知识库中。
步骤4 判断猜测知识库中所有知识的覆盖度,若超过预定的阈值,算法停止。否则,转步骤2。
4 仿真实验
我们在配置为: 主频3.0 GHz、内存512MB、操作系统Microsoft Windows XP的Pentium PC机上对提出的算法进行了实验。实验用到的数据集来自于UCI机器学习的专业数据集[34]。
4.1 不同参数的效果
我们对比了不同数据块规模对分类精度及分类器中知识数目的影响,发现数据块规模对分类器的分类精度影响很小,但是对分类规则(知识)的数目影响较大。从图4可以看到,当数据块规模设置为1 000,2 000,3 000,4 000及6 000条规则,最小支持度门限设置为10%时,得到的分类器的分类精度极为类似。然而,在以上各种情况下,分类器中规则的数目差距是比较大的,且随着数据块规模的增大,发现的规则的数目越来越少。

图4 数据块大小对分类精度及分类规则数目的影响
我们进一步验证了数据块规模对算法运行时间的影响,发现: 对于相同的数据集(图5中左图),算法的运行时间随着数据块的规模的增加而变的越来越长。对于不同的数据集(图5中右图),算法的运行时间主要由记录的属性个数和数据集中项的个数总和来决定。从图5中可以看到,四个不同的数据集Nursery、Krkopt、Poke和Adult的属性的个数分别为: 8、6、10、14。它们的项的总数分别为: 27、

图5 数据块大小对算法运行时间的影响

图6 不同支持度门限对算法的影响
40、85、127。尽管数据块大小和支持度门限被设为相同的值,算法针对这四种数据集的运行时间的差距还是很大的。并且随着项和属性数目的增加,运行时间变的越来越长。
当数据块规模被设置为2 000条记录时,我们测试了所提出算法的性能,并且发现: 随着支持度门限的降低,分类器的分类精度越来越高;但是分类器中分类规则的数目也变的越来越多。
4.2 算法的比较
我们将所提出的知识进化算法KEA-1与文献[8]中所提出的CBA算法做了比较。在CBA算法中,最小可信度被设置为50%,数据块规模被设置为1 000条。两种算法的支持度门限统一设置并被表示在表1中。其中第1列表示数据集名称,第2列表示数据集属性个数,第3列表示类个数,第4列表示支持度门限,第5~6列表示CBA算法的分类精度和该算法需要用到的内存规模(容纳记录条数),第7~8列表示KEA算法的分类精度和需要用到的内存规模。
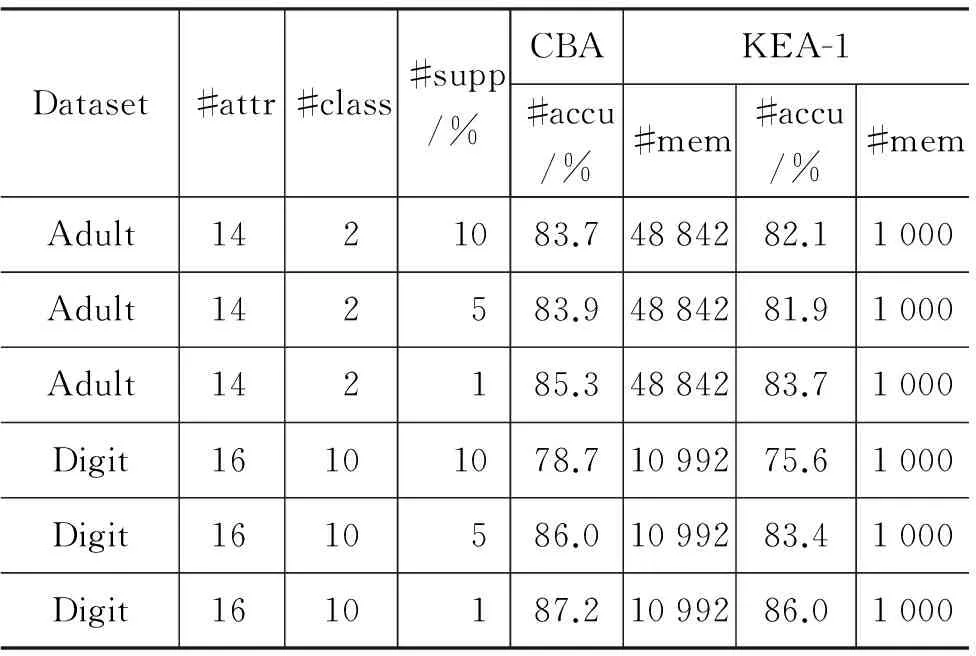
表1 算法对比

续表
我们对来自UCI数据集中的六个标准数据集作了对比分析,发现CBA算法的平均分类精度略高于KEA算法。然而,CBA算法需要用到的存储空间要远远高于算法KEA。CBA算法是静态分类算法,该算法需要多次扫描整个数据集来生成分类器。所以,为了加速分类器的构造,需要将数据集中所有数据读入内存。而KEA算法是动态分类器构造算法,该算法不需一次读入所有数据集中记录。只需分块读入该数据集,就可以扫描一次数据集进而构造分类器。所以,其优势是显而易见的。
4.3 算法的比较2
为了解决KEA算法的分类精度低于CBA算法的问题,我们将猜测与反驳过程中的统计数据引入到知识的正确程度的判定中来,提出算法KEA-2。当猜测知识库中的某条知识的正确度A(ri)低于某个阈值Ф1=0.9时,将其放入反面知识库。随着事实的不断检验,当反面知识库中的某条知识的反驳度Re(ri)低于某个阈值Ф2=0.1时,将其放回猜测知识。我们对上节的六个标准数据集重新做了对比分析,发现: 在计算速度变化不大的前提下,通过修改算法流程并引入两个阈值Ф1、Ф2,KEA算法的分类精度得到了明显的提升,这两种算法的平均分类精度非常类似。然而,CBA算法需要用到的存储空间要远远高于算法KEA。CBA算法是静态分类算法,该算法需要多次扫描整个数据集来生成分类器。所以,为了加速分类器的构造,需要将数据集中所有数据读入内存。而KEA算法是动态分类器构造算法,该算法不需一次读入所有数据集中记录。只需分块读入该数据集,就可以扫描一次数据集进而构造分类器。所以,其优势是显而易见的。

表2 算法改进前后对比
5 结论
KEA-1算法在考虑是否是反面知识的过程中,一次判断就确定知识的真伪,可能会有一些偶然性。因此,在KEA-2算法中通过引入统计数据以及判定阈值Ф1来解决此类问题。实验中将Ф1设为0.9时,得到了较为满意的结果。
总之,该算法是建立在人类认识论的基础之上的一种算法。该算法依靠逻辑推理和实践验证,使知识得到的进化,进而抽象出可全面描述某一复杂系统的知识体系。这一领域还有很多工作要做,从理论上证明该算法的完备性和正确性,对该算法的效率进行分析,增加该算法对时变系统的支持,对该算法的应用领域的扩展等等,都是今后研究的重点。
[1] Das S, Suganthan P N. Differential Evolution: A Survey of the State-of-the-Art [J]. IEEE Transactions on Evolutionary Computation, 2011,15(1): 4-31.
[2] Ashlock D. Computational Intelligence in Bioinformatics [J]. Computational Intelligence Magazine, 2009,4(4): 60-61.
[3] 卡尔·波普尔. 猜测与反驳:科学知识的增长[M]. 上海:上海译文出版社, 1986.
[4] R. Agrawal, R. Srikant, Fast algorithms for mining association rules[C]//Proceedings of the 20th International Conference Very Large Data Bases(VLDB),1994:487-499.
[5] J Han, J Pei, Y Yin. Mining frequent patterns without candidate generation[C]//Proceedings of 2000 ACM SIGMOD Intl. Conf. Manage Data, 2000:1-12.
[6] W Li, J Han, J Pei. CMAR: Accurate and efficient classification based on multiple class association rules[C]//Proceedings of the IEEE International Conference on Data Mining (ICDM01), 2001:369-376.
[7] B Liu, Y Ma, C K Wong. Classification using association rules: Weaknesses and enhancements[C]//Proceedings of the Data Mining for Scientific and Engineering Applications, Berlin,Germany:Springer-Verlag,2001
[8] X Yin, J Han. Cpar: Classification based on predictive association rules[C]//Proceedings of the 2003 SIAM International Conference Data Min.(SDM′03),2003.
[9] Tien Dung Do, Siu Cheung Hui, Bernard Fong. Associative classification with artificial immune system [J], IEEE Transactions on Evolutionary Computation, 2009,13(2), 2009: 217-228.
[10] Guangfei Yang, Shingo Mabu, Kaoru Shimada, et al. A New Associative Classification Method by Integrating CMAR and An Evolutionary Three-layers Structure[C]//Proceedings of ICCAS-SICE, 2009: 2920-2925.
[11] B Liu, H Hsu, Y Ma. Integrating classification and association rule mining[C]//Proceedings of the 4th International Conference Knowledge Discovery and Data Mining (KDD98), 1998: 80-86.
[12] 何云峰.从普遍进化到知识进化[M],上海:上海教育出版社,2001.
[13] 严太山,崔杜武.知识进化算法研究[J].计算机工程与应用,2008,44(26): 8-11.

梁红硕(1979—),硕士,讲师,主要研究领域为进化计算、人工智能。E-mail:lianghs_sjzpt@163.com刘云桥(1973—),硕士,讲师,主要研究领域为数据挖掘、知识发现。E-mail:67465984@qq.com赵理(1974—),博士后,副教授,主要研究领域为智能计算、流挖掘。E-mail:zhaoli@bit.edu.cn
第二十一届全国信息检索学术会议(CCIR2015)在洛阳成功召开
8月22—25日,第二十一届全国信息检索学术会议(CCIR2015)在洛阳顺利召开。本次会议由中国中文信息学会和中国计算机学会联合主办、洛阳外国语学院承办。参加本次会议的代表来自全国从事信息检索理论与应用研究的近70所高校和科研机构,共260余人,既有享誉国内外学术界和产业界的资深专家,也有崭露头角的青年学者。
洛阳外国语学院的领导出席了会议开幕式并致辞。中国中文信息学会副理事长兼秘书长孙乐研究员、中国计算机学会理事长郑纬民教授、中国中文信息学会信息检索专委会主任白硕研究员出席了开幕式并致辞。
本届会议共收到论文176篇。通过通信评审和程序委员会会议复审两个阶段,最终确定录用论文122篇,录用率约为69%,录用的论文总体反映了国内在信息检索领域的最新成果。会议评出5篇优秀学生论文,并颁发优秀学生论文奖证书。
本次会议有幸邀请到中国科学院计算技术研究所倪光南院士、中国科学院自动化研究所王飞跃研究员、华为公司诺亚方舟实验室主任李航教授、微软研究院首席研究员周明博士作了大会特邀报告。微软亚洲研究院林钦佑博士、史树明博士和中国科学院计算技术研究所徐君博士分别作了大会专题讲习班。中科院自动化所刘康副研究员、复旦大学邱锡鹏副教授作了青年学者论坛报告。由阿里UC移动
事业群技术总监陈一宁博士、搜狗搜索研究部负责人许静芳博士、复旦大学张奇副教授、中国科学院计算技术研究所徐君博士共同完成了主题为“移动搜索的产品与技术变革”的Panel。此外,本次会议还进行了信息检索相关产品展示,举办了“第七届中文倾向性分析评测”(COAE2015)。会议录用的所有论文均在分组会上进行了宣读和poster展示。
会议期间,围绕信息检索、文本分类、聚类及挖掘、多媒体检索、社会媒体分析等学术前沿问题,与会代表们展开了热烈深入的研讨,大家各抒己见,畅所欲言,学术气氛十分浓厚、活跃。
国双公司、搜狗公司、百度公司、拓尔思公司、明略公司、捷通华声语音技术公司为本次会议提供了必要的赞助支持,特此深致谢忱!经过CCIR指导委员会与信息检索专委会联席会议讨论决定,第二十二届全国信息检索学术会议(CCIR2016)由华南理工大学承办。
全国信息检索学术会议瞄准国家重大战略需求,关注国内外信息检索研究领域的最新进展,对本领域面临的种种挑战性科学问题和关键性技术难题展开了深入研讨,力争为提升我国信息检索学术研究的整体水平作出新贡献。本次会议获得了圆满的成功,不仅促进了相关学科领域与IT界的学术交流,而且增进了同行之间的学术友谊。
Knowledge Evolutionary Algorithm and Its Application for Associative Classification
LIANG Hongshuo1, LIU Yunqiao1, ZHAO Li1,2
(1. Shijiazhuang Vocational Technology Institute, Shijiazhuang, Hebei 050081, China;2. Beijing Institute of Technology, Beijing 100081, China)
To avoid the repeated exhaustive search of the data in classical associative classification approaches, a knowledge evolutionary algorithm based on evolutionary epistemology is proposed. Firstly, data in the data set is encoded. Secondly, the hypotheses knowledge and inaccuracte knowledge are gained by conjecture and refutation operator. Thirdly, the coverage and accuracy of the hypotheses and inaccurate knowledge are calculated. Then, an extraction operator is used to extract rules from library of inaccurate knowledge and to put them into hypotheses library. Finally, the knowledge obtained with this method was used to build a classifier. In this way, the dataset can be read in a computer partly and the whole times used for read in and read out were reduced largely. The results have shown that knowledge evolution algorithm can speed up the calculation process under the guarantee of similar accuracy of classification.
knowledge evolution; conjecture; refutation; associative classification
1003-0077(2015)04-0126-08
2013-06-26 定稿日期: 2015-04-09
中国博士后科学基金(2013M530534); 河北省教育厅科学研究计划(Z2014181);国家自然科学基金(61272283;60873035);河北省人社厅项目(JRS-2014-1103)
TP
A
