面向中文文本的情感信息抽取语料库构建
2015-04-21李寿山周国栋
戴 敏,朱 珠,李寿山,周国栋
(苏州大学 计算机科学与技术学院自然语言处理实验室, 江苏 苏州 215006)
面向中文文本的情感信息抽取语料库构建
戴 敏,朱 珠,李寿山,周国栋
(苏州大学 计算机科学与技术学院自然语言处理实验室, 江苏 苏州 215006)
情感信息抽取是情感分析中的一个重要子任务。虽然该任务已经开展有一段时间,但是面向中文文本的情感信息抽取任务研究才刚刚起步。目前中文文本的情感信息抽取面临的首要困难在于现有的相关中文语料库还非常有限。为了更好开展中文文本的情感信息抽取研究,该文重点研究了中文语料标注体系,构建一个规模较大、标注类型丰富的中文情感信息抽取语料库。除了常见语料库标注的情感倾向性、评价对象、情感词等信息外,重点标注了评价对象的省略、无情感词情感句表达及极性转移等情况。由语料信息统计可知,该文所指出的特殊现象(例如,评价对象的省略)在中文情感表达中是非常普遍的,开展这方面的研究很有必要。该文所构建的中文文本语料库将为中文情感信息抽取任务提供语料基础。
情感分析;情感信息抽取;中文语料库
1 引言
随着互联网技术的飞速发展,愈来愈多的人们从被动接受信息转变为主动发布信息。互联网用户可以通过处理这些富含情感色彩的文本来了解公众对于某个产品或某个事件的看法、评价等。但是,随着这类信息的迅速膨胀,单靠人工方法来处理无疑是非常困难的,情感分析便应运而生了[1-3]。情感分析又称意见挖掘(Opinion Mining),是借助计算机帮助用户快速获取、整理和分析相关评价信息,对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。它包含了一系列的子任务,如主客观分类、情感倾向性分类、情感信息抽取、情感信息检索、情感信息归纳等[2]。这些子任务的研究具有广泛的应用价值和理论研究价值。
情感信息抽取,作为情感分析的一个重要子任务,旨在抽取情感文本中有价值的情感信息,是一种关于细粒度文本的情感分析。该任务在近年来受到了广大学者的关注,相继出现了大量的抽取方法[4-7]。而随着基于监督学习的情感信息抽取方法研究的开展,监督学习方法表现出了其良好的任务独立性和抽取性能[8-9]。因此,基于监督学习的情感信息抽取方法是情感信息抽取方法研究的一种趋势[10-11]。而基于监督学习的情感信息抽取方法需要依靠大量的人工标注语料作为基础,因此,语料库建设问题也成为情感信息抽取任务中的一个重要研究方面。
随着网络在中国的普及,越来越多的中文评论文本的出现,解决面向中文文本的情感信息抽取任务的需求日益增多。目前,面向中文文本的情感信息抽取任务的研究较少,相应的语料资源较匮乏。因此,建设一个规模较大的、标注类型丰富的中文情感信息抽取语料库是目前中文情感信息抽取任务的一个重点。
此外,已有的中英文语料库所标注的信息都忽视了一些表达特点,而这些情况本身也具有一定的研究价值。如以下例句:
例1 我很喜欢,很好看。
例2 这个电影,哎,都看的睡着了。
例3 前台服务员态度不是很好。
三个例句都表达了评论作者的情感倾向,但是较以往处理的情感信息抽取问题有其特殊性。如例句1中,作者所表达的情感倾向是正面的,有着明显的情感词“喜欢”,“好看”,但评价对象在句中未有出现;例句2中的评价对象为“这个电影”,虽然句子表示了这个电影不好看的含义,但并没有情感词出现;例句3中由于否定词“不”的出现,整句话的情感倾向相对句中情感表述“好”所表达的情感倾向发生了翻转。
本文分别称这三种现象为评价对象的省略现象、隐含情感及情感极性转移现象。这三种现象同情感信息抽取任务密切相关,对情感信息抽取任务的完成造成了一定的影响。例如,现有的评价对象抽取方法部分依赖于评价对象与情感词的关系来帮助抽取评价对象[9-10],若句中无情感词,一些之前表现良好的特征便不适用了。情感极性转移现象会使整句的情感倾向相对于情感词的情感倾向发生反转等。而其中评价对象的省略现象也是中文文本的一个非常特殊的表达现象。因此,在建设新的中文情感信息抽取语料库时,考虑以上的现象是有必要的。本文将面向中文文本标注一个用于情感信息抽取任务的大规模语料。该语料的特色在于,除了包括了一些传统的情感信息,例如,评价对象、评价词等,还包括了评价对象的省略现象、隐含情感及情感极性转移现象的标注。
本文结构组织如下: 第二部分介绍现有的相关中英文语料库;第三部分介绍本文提出的语料标注体系;第四部分给出语料库的部分统计信息;第五部分给出结论。
2 相关工作
近年来,为了推动情感分析技术的发展,国内外一些研究机构组织了一些公共评测,为情感分析的方法研究提供统一的平台。如国际文本检索会议TREC Blog Track*http://trec.nist.gov/tracks.html任务、NTCIR*http://research.nii.ac.jp/ntcir/index-en.html的情感分析评测,国内近期的COAE评测[12-14]等。此外,也有研究单位和个人提供了一定规模的语料,如麻省理工学院(Massachusetts Institute of Technology)的Barzilay等人构建的多角度餐馆评论语料等。下面分别介绍一些现有英文语料库和中文语料库的情况。
2.1 英文语料库
DSRC语料是一个较著名的关于情感信息抽取的英文语料,来源于德国达姆施塔特工业大学(Technische Universität Darmstadt)的Ubiquitous Knowledge Processing(UKP)Lab,包含了services和universities两个领域的234和256篇评论文本。该语料是对评论文本在句子级以及表达级(Expression Level)上的意见相关(Opinion Related)信息的较为详细标注,其中主观句标注了四种情感信息类别(观点持有者、评价对象、修饰词、评价词)。文献[15]详细描述了DSRC语料的标注规范。DSRC语料用MMAX2标注工具标注,组织成MMAX2的工程结构。
此外,英文的情感抽取语料还包括Zhuang[7]的影评语料。该语料来源于IMDB,其中包含了对20个不同电影的评论,每个电影抓取了100条评论,共有2 000篇评论文本,去重后有1 829篇影评。相比于DSRC语料而言,该语料标注体系较为简单。语料以XML的格式组织,以句子为情感标注单元。对于含有评价对象/观点对(Feature/Opinion pair)的句子(主观句)作标注。在标注结果中,标注信息用一个四元组表示,分别代表评价对象、评价对象类别、评价词语和评价的情感极性。
2.2 中文语料库
相对于英文语料,有关中文情感信息抽取的语料标注起步稍晚了一些。随着近几年的迅速发展,也相继出现了一些标注语料。
在近几年的举办的COAE(Chinese Opinion Analysis Evaluation)评测[12]中,设置了关于“评价对象”识别的一项评测任务,相应有部分标注语料。在2011发布的评测语料里面,共包含三个领域,分别是电子、娱乐和财经。每个领域有2 000个文档用于“评价对象”的识别,识别的结果用一个三元组表示,分别是句子中观点的评价对象、评价短语和对该评价对象的观点极性。而2012~2013年的评测[13-14]中设置了比较句的识别与要素抽取的任务,此任务分为两个部分,首先识别句子是否为比较句,然后在识别出的比较句中抽取出比较实体、实体要素及情感倾向性。COAE2012~2013发布的此项任务的评测语料均包含电子和汽车两个领域,其中2013的评测语料中每个领域有约500句为比较句,并针对比较句标注其中的比较对象、商品属性、观点倾向性等信息。2013年的评测中还加入了微博观点句要素抽取任务,语料规模为12 000篇,要求从中识别出观点句,然后从识别出的句子中抽取相应的评价对象,被评价的产品属性以及相对应的观点倾向性。
此外,2012年举办的nlp&cc评测为中文微博情感分析任务,评测的对象是面向中文微博的情感分析核心技术,包括观点句识别、情感倾向性分析和情感要素抽取,相应的有部分标注语料。其中任务三“情感要素抽取”要求找出微博中每条观点句作者的评价对象,即情感对象,同时判断针对情感对象的观点极性。在2012年发布的评测语料中,包含了十个话题的中文微博语料,每个话题有100个标注文档。
另一个比较著名的语料是NTCIR 提供的标准测试集,其中中文简体语料共包含255个文档,4 877个句子,其中被标为情感句的有1 102个,标注的其他信息包括评价对象、观点持有者、情感极性。
由此可见,可用于中文情感信息抽取的语料库规模较小,且大多仅关注了情感倾向性、评价对象等信息,标注情况简单。本文将在考虑了前文所述的三种表达情况下,重点标注评价对象的省略现象,构建一个更完整的规模更大的中文情感信息抽取语料库。
3 语料标注体系介绍
构建好的情感信息抽取标注语料是实现性能更佳的学习系统的基础。因此,我们考虑构建一个中文情感信息抽取语料库。除了标注句子的情感极性,句中出现的评价对象和情感词,我们还考虑了以下几种信息: 评价对象和情感词的对应关系;评价对象的省略现象;情感句中情感词未出现的情况(隐含情感)及情感极性转移现象。
本节将重点介绍标注体系的设计,分为标签设置和标注过程两个方面进行阐述。
3.1 语料库标签设置
本标注体系共设置了四类标签来覆盖上文所提到的标注信息,以篇章为单位进行语料标注。示例文档给出了一篇已标注完成的语料,其中第二、三两句分别存在评价对象的指代和省略现象,第四句中存在隐含情感的现象。下面将结合示例详细阐述本标注体系的标签设置。
示例文档:

1.这次我们选择住在了
第一类标签: 主要作用为标注句子的情感倾向性。标注位置在句首。标签表示方法及代表含义如表1所示。例如: 示例中第二、三两句的情感极性为正面的,因此标注为<+P>。
第二类标签: 标注评价对象,并为文中出现的评价对象计数, 便于省略和指代现象的表示。标注位置为句中评价对象出现的位置。标签表示方法及代表含义如表2所示。

表1 句子情感极性标签的表示和说明
为了便于表示情感词和评价对象的关系,及评价对象的省略与指代现象,需要对文档中出现的评价对象依次计数,以标签中的“tgtNUM”表示。因此表2中三个标签内的“tgtNUM=n”均表明此评价对象为文中的第n+1个评价对象,如示例最后一句中的“早餐”是整个文本中出现的第三个评价对象,因此tgtNUM=2。而表中的

表2 评价对象标签的表示和说明
第三类标签: 作用是标注情感词,同时以编号指出此情感词所评价的对象,当评价对象没有在本句中出现时,便发生了评价对象的省略情况。当此句中无明显情感词时,便为隐含情感。标注位置分别有在句中标注和在句末标注的两种情况。标签表示方法及代表含义如表3所示。
这一类标签以

表3 情感词标签的表示和说明
第四类标签: 标注修饰词。标签表示方法及代表含义如表4所示。其中标签

表4 修饰词标签的表示和说明
以上内容详细介绍了本标注体系设计的四类标签。标签可以表示的内容充分覆盖了本节开始所提到的计划标注的信息,并重点标注了评价对象的省略情况,此标注内容也将作为接下来研究的重点。
3.2 语料库标注流程
本文构建的中文情感信息抽取语料库的标注过程大致分为两个部分: 首先进行句子级别的情感倾向性标注;然后对情感句进行细粒度的标注,先后标注评价对象、情感词和修饰词。情感句的细粒度标注是本标注体系的重点,标注过程较为繁琐,工作量大。为便于理解,图1展示了其中评价对象和情感词的标注过程。
情感句的细粒度标注过程中,首先需要标注评价对象,第一步要判断句中是否有评价对象。如果无评价对象出现,则表明句中出现了省略现象,留待稍后标注;若出现评价对象,则进行下一步,关注评价对象是否为代词,若为代词则需要标注出指代的评价对象实体。
然后标注情感词,同样首先判断句子中是否存在情感词。如果句中含有情感词,则进一步寻找情感词所评价的对象,关注是否存在评价对象的省略现象,以及省略的对象是否在上下文中出现;如果句中不含有情感词,即隐含情感现象,同样也关注是否存在评价对象的省略现象,省略的对象是否在上下文中出现这些内容,而标注位置在句末。
以上是对本标注体系的标签设计及标注过程的详细介绍。由此可以看出,此语料库重点标注了评价对象的省略,隐含情感及极性转移等现象。这三种情况能够影响情感信息抽取的结果,具有一定的研究价值,而其中的评价对象省略现象更是中文文本的一个特有表达,是中文文本的评价对象抽取任务的一个难点。而本文所设计的标注体系为今后的这一类问题提供了标注方法,根据此体系标注完成的语料库能够为中文评价对象的省略现象的进一步研究提供充分的语料资源。
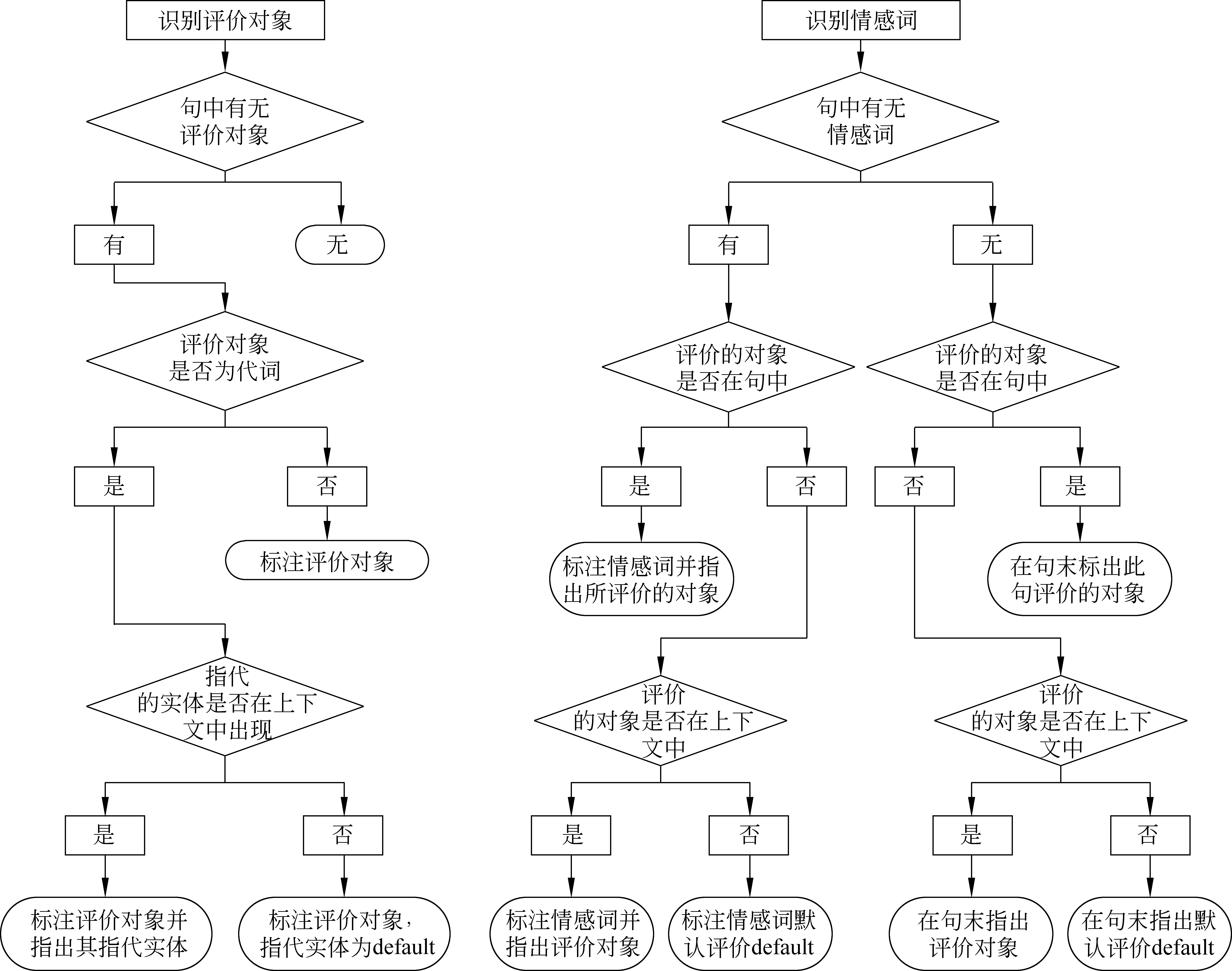
图1 评价对象和情感词标注流程
4 语料库的相关信息统计
本节将重点给出本语料库的相关统计数据,以此说明本文提出的三类现象在情感文本中的发生比例,及本语料库在未来中文情感信息抽取任务方面的应用价值。
在标注过程中,共有两个标注人员参与标注,并且在标注过程中不断讨论完善标注标准,尽量避免争议较大的标注。我们采用了Cohen’kappa[16]值作为衡量语料标注一致性的指标,两个标注人员标注结果的Kappa值为72.62%。
本文将所设计的语料体系应用到三个领域的产品评论语料中,分别是笔记本、宾馆和化妆品。为表述方便,将以NB、Hotel、Beauty分别代表笔记本、宾馆和化妆品三个领域。标注过程以文档为单位,保留上下文信息。标注内容反映了以下情感信息:
1. 句子的情感倾向性;
2. 情感句中出现的评价对象;
3. 情感句中出现的情感词;
4. 情感词与评价对象的对应关系;
5. 作为评价对象的代词所指代的实体;
6. 情感句中未出现评价对象的现象,并指出了所省略的评价对象;
7. 情感句中未出现情感词的现象;
8. 情感词的修饰词,重点反映了极性转移现象。
表5为语料库的情感倾向性信息统计。NB领域标注了2 000篇文档,其中褒义句和贬义句各2 015、2 038句;Hotel领域标注了1 000篇文档,其中褒义句和贬义句各1 171、2 587句;Beauty领域标注了2 000篇文档,其中褒义句和贬义句各1 518、1 157句。由数据可知,我们标注的三个领域的语料含有丰富的带有情感色彩的文本,这些标注文本可以有效地帮助情感倾向性分类任务。
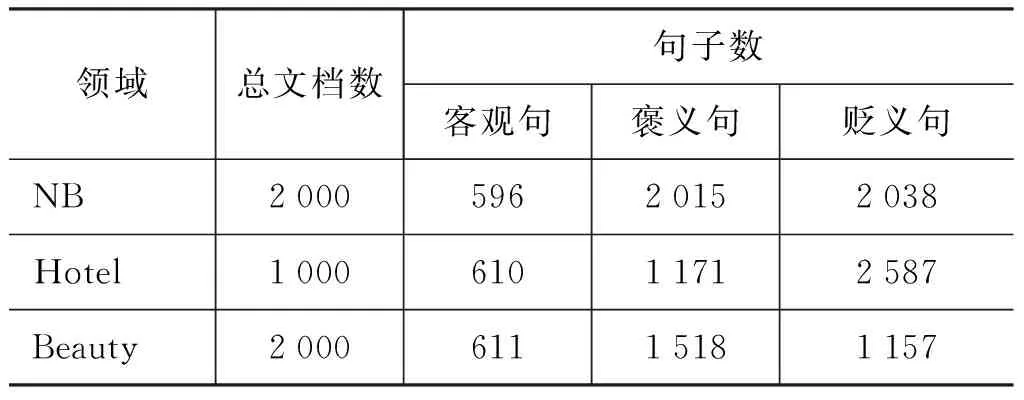
表5 情感倾向性信息统计
表6统计了评价对象和情感词的信息。以NB领域为例,2 000个文本中共有5 167个评价对象,评价对象的平均长度为1.76词/个,平均每个文档中有2.85个评价对象;共有情感词6 512个,平均每个文档中有3.26个情感词。由表6可以得到其他两个领域的相关信息。鉴于目前已有的中文情感信息抽取语料库的局限,这些大量标注文本可以用于中文情感信息抽取任务的研究,尤其是基于监督学习的评价对象抽取方法研究。
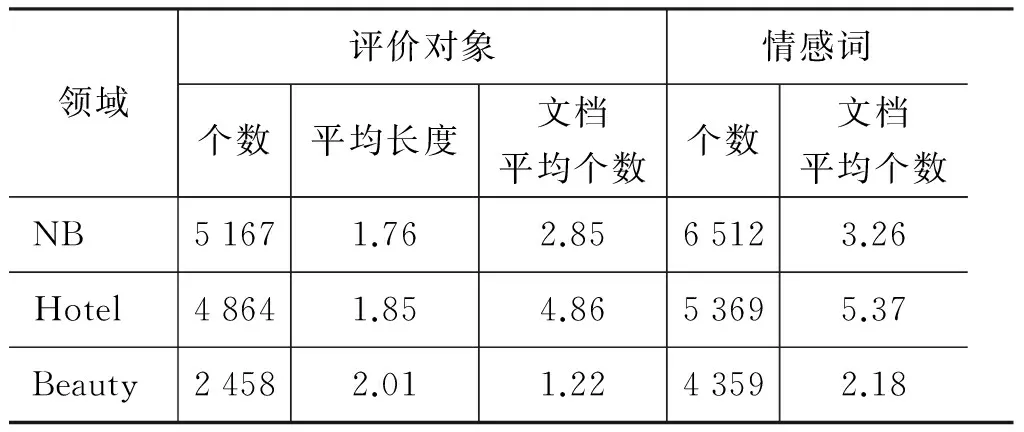
表6 评价对象及情感词信息统计
表7反应了本文中所重点提出的三类现象在语料中的出现情况。在NB领域中,含有省略评价对象的句子共1 082句,情感句中未出现情感词的句子数为854,出现否定转移的句子数为596句,分别占情感句总数的26.69%、21.07%和14.71%。由此可见,这三种情况在中文表达中较为常见,有值得进一步研究的价值。而本语料库重点标注了这三种情况,是进行下一步研究的良好的语料基础。
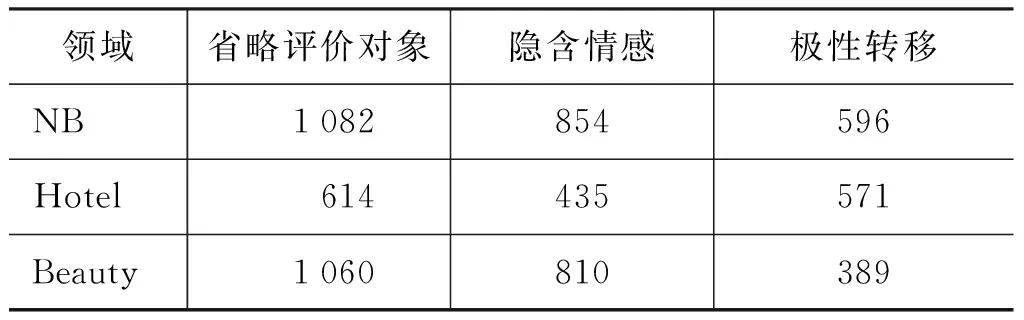
表7 含有特殊表达的句子数
由以上统计数据可以看出,本文所构建的中文情感信息抽取语料库不仅能够为一些常见的中文情感信息抽取子任务如评价对象抽取、评价词语抽取等提供丰富的语料支持,也为后续对本文所提到的评价对象的省略、隐含情感及情感极性转移等现象的研究完成了语料准备。
本文使用了一部分语料进行了评价对象抽取任务的基本实验。采用Jakob等[9]的方法为模板,即将评价对象抽取建模成序列标注问题,使用条件随机场模型CRFs实现评价对象的抽取,实验对于特征部分仅采用词形和词性两个基准特征。其中词形表示当前单词的字符串特征,词性表示当前单词的词性标记特征。
在本实验中,条件随机场模型的实现采用CRF++,使用默认参数,词与词性的窗口大小为3。评价指标采用P(Precision)、R(Recall)、F1(F1-Measure)。训练集和测试集均为500个句子。表8为三个领域的评价对象抽取实验结果。
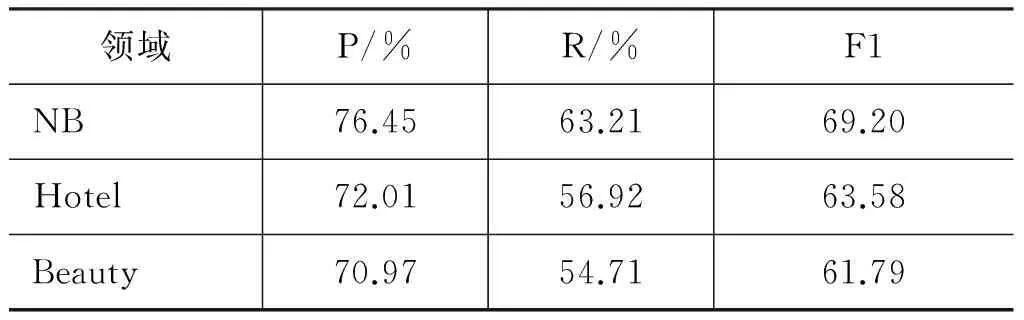
表8 评价对象抽取实验结果
实验结果显示,本文所标注的语料在评价对象抽取任务中已能达到较好的效果,如三个领域的评价对象抽取的Precision值均在70%左右,与英文语料采用相同特征与方法的结果[9]相比较好,可能是由于本文的标注体系较英文语料更完善。
5 小结
本文设计了一套中文情感信息抽取语料库的标注体系,除了标注常见的句子情感极性、情感词、评价对象等信息以外,还重点考虑了情感表达中的评价对象省略、隐含情感及极性转移等现象。统计结果表明,这几种情况在中文表达中较为常见,有值得研究的价值。本文通过对三个领域的产品评论语料的标注,为下一步的基于监督学习方法的中文信息抽取方法研究提供了一定的基础。语料中所重点标注的评价对象的省略现象等也将作为后续工作进行进一步的研究。*本文所述语料将在论文发表后在实验室网站公布
[1] Pang B, Lee L. Opinion Mining and Sentiment Analysis[J]. Foundations and Trends in Information Retrieval, 2008, 2(1-2) :1-135.
[2] Pang B, Lee L, Vaithyanathan S. Thumbs up? Sentiment Classification using Machine Learning Techniques[C]//Proceedings of EMNLP-02. 2002: 79-86.
[3] 宗成庆. 统计自然语言处理[M]. 北京: 清华大学出版社,2008:1-475.
[4] Kim S, Hovy E. Extracting Opinions, Opinion Holders, and Topics Expressed in Online News Media Text[C]//Proceedings of the ACL Workshop on Sentiment and Subjectivity in Text. 2006: 1-8.
[5] Ku L, Liu I, Lee C, et al. H. Sentence-Level Opinion Analysis by CopeOpi in NTCIR-7[C]//Proceedings of NTCIR-7 Workshop. 2008.
[6] Hu M, Liu B. Mining Opinion Features in Customer Reviews[C]//Proceedings of AAAI-2004. 2004: 755-760.
[7] Zhuang L, Jing F, Zhu X. Movie review mining and summarization[C]//Proceedings of CIKM-2006. 2006: 43-50.
[8] Li B, Zhou L, Feng S, et al. A Unified Graph Model for Sentence-based Opinion Retrieval[C]//Proceedings of ACL. 2010:1367-1375.
[9] Jakob N, Gurevych I. Extracting Opinion Targets in a Single and Cross-Domain Setting with Conditional Random Fields[C]//Proceedings of EMNLP-2010. 2010: 1035-1045.
[10] 王荣洋,鞠久朋,李寿山,等. 基于CRFs的评价对象抽取特征研究. 中文信息学报[J],2012,26(2): 56-61.
[11] Li S, Wang R, Zhou G. Opinion Target Extraction using a Shallow Semantic Parsing Framework[C]//Proceedings of AAAI 2012. 2012:1671-1677.
[12] 赵军,许洪波,黄萱菁,等. 中文倾向性分析评测技术报告[C]//Proceeding of COAE-2008.
[13] 刘康,王素格,廖祥文,等. 第四届中文倾向性分析评测总体报告[C]//Proceeding of COAE-2012.
[14] 谭松波,王素格,廖祥文,等. 第五届中文倾向性分析评测总体报告[C]//Proceeding of COAE-2013.
[15] Toprak C., Jakob N., and Gurevych I. Sentence and Expression Level Annotation of Opinions in User-Generated Discourse[C]//Proceedings of ACL-2010. 2010: 575-584.
[16] Cohen. A coefficient of agreement for nominal scales[J]. Educational and Psychological Measurement, 1960:37-46.
Corpus Construction on Opinion Information Extraction in Chinese
DAI Min, ZHU Zhu, LI Shoushan, ZHOU Guodong
(NLP Lab, School of Computer Science and Technology, Soochow University, Suzhou, Jiangsu 215006, China)
Opinion information extraction (OIE) is an important sub-task in the research on sentiment analysis. Currently, one pressing issue in Chinese OIE is that the Chinese corpus is not readily avalable. This paper focuses on the annotation framework for Chinese OIE, and constrcuts a Chinese corpus containing rich information. Specifically, in additions to the popular elements including sentiment orientation, opinion target and opinion keyword, our corpus contains the information of opinion target ellipsis, the expressing opinion without sentimental words and the sentimental polarity shifting. The statistics show the popularity and necessity of these special points (e.g., opinion target ellipsis) in Chinese texts.
sentiment analysis; opinion information extraction; Chinese corpus

戴敏(1989—),硕士,主要研究领域为自然语言处理。E-mail:dmin.mousse@gmail.com朱珠(1991—),硕士研究生,主要研究领域为自然语言处理。E-mail:zhuzhu0020@gmail.com李寿山(1980—),博士后,教授,主要研究领域为自然语言处理。E-mail:shoushan.li@gmail.com
1003-0077(2015)04-0067-07
2013-07-13 定稿日期: 2013-12-10
国家自然科学基金(61003155,60873150);模式识别国家重点实验室开发课题基金
TP391
A
