服务流程检索技术研究
2015-04-17吴晓铭王凌阳
张 林,吴晓铭,王凌阳
ZHANG Lin1,WU Xiaoming2,WANG Lingyang2
1.武汉大学 软件工程国家重点实验室,武汉430072
2.武汉大学 计算机学院,武汉430072
1.State Key Lab of Software Engineering,Wuhan University,Wuhan 430072,China
2.College of Computer,Wuhan University,Wuhan 430072,China
1 引言
在工作流和服务计算领域,流程片段的重用研究具有很大的研究价值。许多研究关注于如何分割和描述流程片段。例如,Vanhatalo[1]提出一种将原流程片段分割成更小的单入单出(Single-Entry-Single-Exit,SESE)片段的模型。在文献[2]中,为更好地描述和提取片段信息,将流程片段描述成不同的零碎知识。Schumm[3]详细讨论了使用流程片段库和集成应用的潜在影响。此外,一个全面的框架[4]关注于如何提取动态、渐进、上下文感知适应的流程片段。但是这些方法没有考虑提取流程片段的潜在信息,特别是如何提取一个超出人工提取能力的大流程片段信息。
事实上,任意粒度的服务流程片段[5-7]都有被重用的潜力,尤其是那些已被手动编辑,且能够直接运行的流程片段,其作用甚至高于原子服务。例如,一个仅包含顺序关系的简单服务流程S1 →S2 →S3,不仅能够重用片 段S1 →S2 和S2 →S3,而且可以重用S1 →S2 →S3整个片段。
服务流程片段重用的目的是进一步利用现有的流程片段,即尽可能挖掘出更多的可重用子流程片段,从而满足新的服务组合需求。此外,服务重用并未考虑重复使用的对象是否为原子或组合服务。例如,图1 展示了一个与旅游相关的服务流程实例,它包含5 个原子服务。若一个客户旅行乘坐火车改乘船,利用现有技术,开发人员不得不手动分析和重建全过程。尽管在上述组合服务中可以通过一个轮船订票服务替换火车订票服务,达到重用一些服务片段的目的,但是如果服务流程库非常庞大,开发者很难找出哪些片段可以被重用。服务库样例如表1 所示。
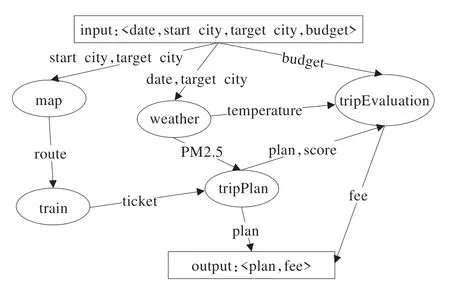
图1 一个服务流程样例

表1 服务库样例
在不同的需求方面,为有效发现和重用服务流程片段,本文提出了一种新的索引机制(CLI)。由于其他流程关系可以被转化为线性关系流程,所以本文中的流程都是具有线性关系的流程。首先,服务接口描述和服务之间依赖关系转换成二进制编码的标签,图2 给出对应于图1 转换后的标签图。在标签图中所有顶点和边组成服务标签树(Service Label-tree,SL-tree),即每个流程对应于一棵SL-tree。然后,在统一实现原子服务和组合服务的检索时,本文提出了一种新颖的数据结构,即服务标签合并树(SLM-tree)。这样,搜索的服务将不仅仅局限于原子服务。通过快速计算将绝对不相关的流程片段过滤掉,剩下可能相关的流程片段,之后采用传统考虑服务依赖性的方法进行匹配筛选。最后,择优选取检索到的流程片段。

图2 转换成标签图
2 CLI机制
本文仅关注于不同网络服务的连接,而对于初始化服务流程并不重要的控制结构如if 与while 等不会过多关注。因此,本文需要牺牲一定的准确性来大幅提高服务流程片段的检索效率。
在只考虑顺序序列的情况下,流程可简化为一个有向图,称为Web 服务图(Web Service-graph,WS-graph),其中每个顶点和每条边分别对应于Web 服务和连接服务之间的依赖关系。服务流程片段查询类似于搜索限制宽泛的子图匹配问题。因此,服务流程片段查询(SFF-query)只关注于服务的输入和输出参数以及它们之间的依赖关系。
在WS-graph中,某个流程片段P可以用Gp=(W,E)表示,其中W={w1,w2,…,wm}是顶点集合,E={<wi,wj>}={<wi.out→wj.in>}(i,j∈m)是边集合。每个顶点表示一个服务,每条边代表wi和wj之间依赖关系。一个SFF-query 可以用Gq=(W′,E′)表示,如果查询成功,则要求对Gq中任意一条边<wx′,wy′>,wx′的输入和wy′的输出必须分别包含于Gp中服务集合的输入集和输出集内。
2.1 WS-graph 标签
为便于理解,假设每个Web服务只有一个操作。WSgraph 标签包括顶点标签vLab(w)和边标签eLab(wiwj),其中每个标签都对应于一个二进制串。Web 服务可以描述为wi=<wi.in,wi.out>,其中wi.in和wi.out分别表示服务的输入和输出参数集。由于可以通过本体映射、近义词替换等将服务语义概念统一,之后采用合适的哈希函数,例如DJBHash 和PJWHash,可以将服务wi编码成统一格式的二进制位串。
给定服务w包含输入参数集w.in={in1,in2,…,inp}和输出参数集w.out={out1,out2,…,outq}。
vLab(w)定义如下:
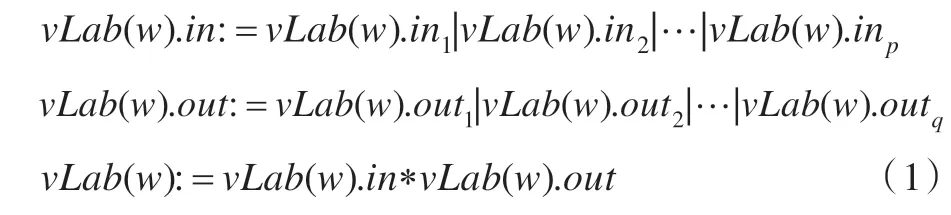
eLab(wiwj)定义如下:
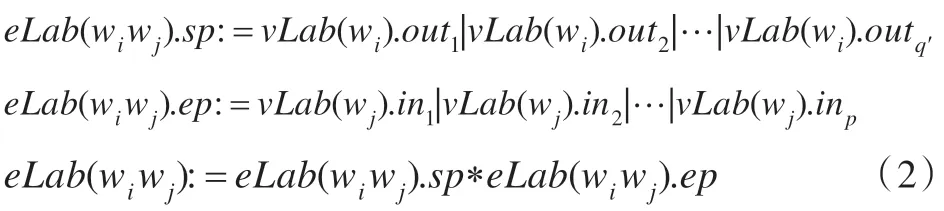
其中“|”表示或操作,“*”表示连接操作。对于任何服务的连接,连接服务的输入参数必须完全满足要求,但一些连接服务的输出参数可以不使用。因此,在公式(2)中有q′=p≤q。
图3 和图4 分别显示如何分配标签给图1 中天气服务以及旅行计划服务和旅行估价服务之间的关系。
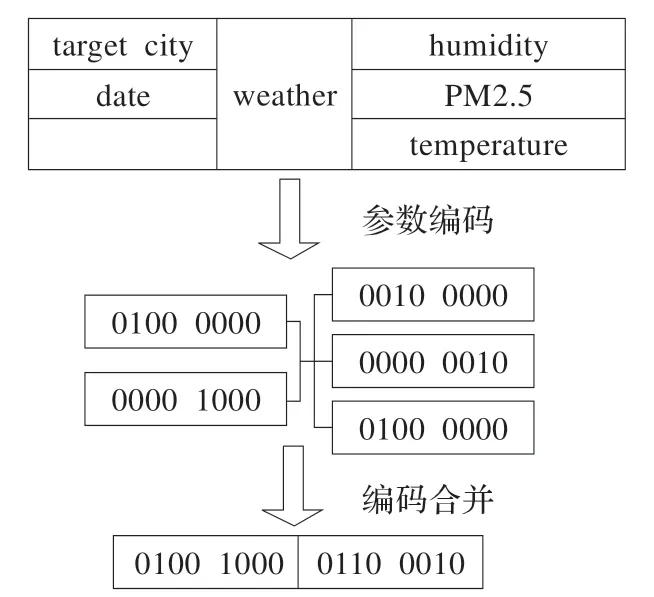
图3 服务标签实例
2.2 服务标签合并树
通过编码Web 服务和不同服务之间的依赖关系,WS-graph 将被转换成一个标签图,称为流程标签图(Flow Label-graph,FL-graph)。本节将讨论如何将这些标签组织成CLI。CLI 将提供更加便捷、高效的服务流程片段查询,其过程仅仅使用有限的位运算组织这些标签。
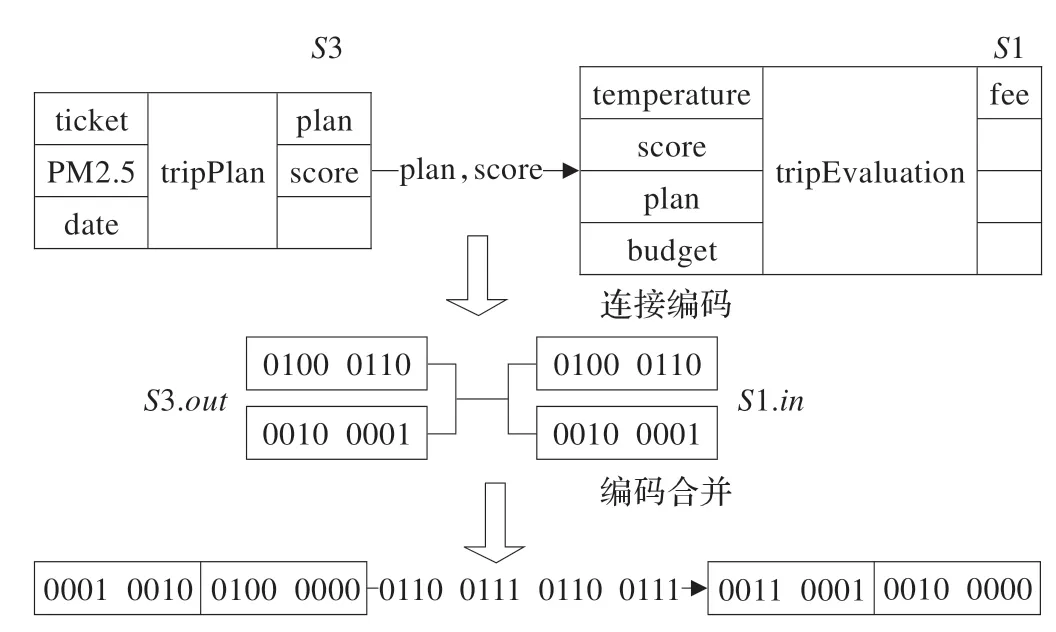
图4 服务连接标签实例
对于服务流程片段查询(SFF-query),查询条件可以转换成一个查询标签图(Query Label-graph,QL-graph),转换过程类似于对WS-graph 转化为FL-graph。因此要解决的本质问题是如何在FL-graph 中有效找到匹配的QL-graph。一个简单的算法如下:
步骤1对每个vi∈V(QL-graph),找到点集Ri={ui1,ui2,…,uin}满足条件vi&uij=vi,uij∈V(FL-graph)以及uij∈Ri。其中“&”是二进制与操作,V(*)是顶点集合。
步骤2通过依赖关系进一步验证这些点集,最终选取一些相匹配的QL-graph。
在本文中,S-tree[8]是一种提供包含检索功能的高度平衡树。在S-tree 中,每一个中间结点是通过位与运算叠加所有子标签而组成。因此,利用一棵S-tree 可以有效地完成第一步。然而,S-tree 不能支持累加服务之间的依赖关系。因此,本文提出一种新的索引结构即服务标签树(Service Label-tree,SL-tree),支持任意粒度的服务流程片段查询。如图5 所示,该图对应于图1 例子的一棵SL-tree。
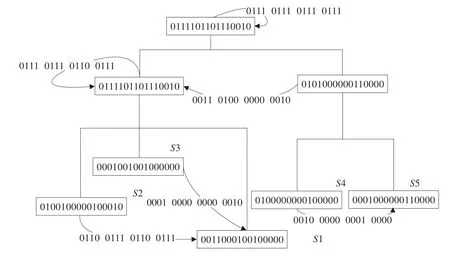
图5 图1 转化为SL-tree
尽管可以通过SL-tree 搜索任意粒度的服务流程片段,但是仍然需要检索大量SL-tree。因此,将所有SL-tree的根结点再通过一棵S-tree 进行组织,以此进一步提高搜索流程片段的效率,这棵S-tree 定义为服务标签合并树(Service Label Merge-tree,SLM-tree)。此外,SLMtree 的叶结点可能是一个原子服务,但是组合服务必须有自边,由此通过判定SLM-tree 中叶结点是否存在自边,区分对待原子服务和组合服务的搜索。所以CLI 可以统一检索这两种类型服务。
3 检索过程
本章将讨论如何通过SLM-tree进行服务片段查询。具体策略是自顶向下通过SLM-tree 在一个庞大的服务流程存储库中过滤寻找一些候选集,并且按照一定策略从中择优选取。
3.1 片段检索原理
在2.2节介绍过,一个SFF-query可以转换为QL-graph,而SFF-query 可分为严格或非严格检索。对于严格SFFquery,结果必须完全满足查询条件,它们可以直接被重复利用。与此相反,在非严格SFF-query 中,允许结果部分满足查询条件。由于篇幅所限,本文只介绍严格的SFF-query。
定义3.1对于一个FL-graphG*和一个QL-graphQ*,其 中G*,Q* 分 别 包 含Web 服 务 集 合W={w1,w2,…,wm}和U={u1,u2,…,un},当且仅当以下条件成立时G*是满足严格查询Q*:
条件1对于任何ui∈U,存在wj∈W,使得vLab(wj).in&vLab(ui).in=vLab(wj).in并且vLab(wj).out&vLab(ui).out=vLab(wj).out。这意味着所有查询条件的Web 服务是被包含在流程中。
条件2对Q*中的任何uiuj,在G*中,存在wiwj使得eLab(uiuj)&eLab(wiwj)=eLab(uiuj),其中wiwj可能是一条被许多叶结点合成的边。
利用SLM-tree 的特性,反复通过定义3.1 从上到下实现过滤操作。因为树状结构的每个分支都含有大量流程或原子服务,所以每一步操作都有可能过滤大量不相关结果。
3.2 使用SLM-tree
基于SLM-tree 创建的索引能够统一实现原子和组合服务两种查询。事实上,原子服务查询可以看成是仅包含一个服务的特殊SFF-query。因此,下文只详细描述SFF-query 的步骤。
SFF-query 主要包含两个步骤。第一步,查询输入标签和输出标签分别与SLM-tree 的根结点标签做位与操作,判断是否匹配。如果匹配不成功,快速排除即可。如果查询条件与根结点或任何内部结点匹配,由于在SLM-tree 中位或操作的模糊积累并不能表明查询流程片段存在,所以只获得流程片段的候选集,即许多SL-tree 根结点组成的集合。
在上一步的匹配过程中,为了快速筛选最不相关的流程片段,只考虑顶点的存在,而忽略顶点之间的依赖关系。在第二步中,将进一步利用关系标签找到包含查询流程片段的流程片段。如果第一步产生的候选集中某个流程片段与查询条件中的顶点标签和边标签任何一项不匹配,该流程片段将会被排除。
3.3 选取SFF
服务质量(Quality of Service,QoS)代表Web 服务的许多非功能特性,例如响应时间,吞吐量和可达性等。由于每一个服务质量特性不尽相同,根据文献[9]需要将它们归一化到区间[0,1],具体公式如下:

其中公式(3)表示正向属性归一公式,公式(4)表示负向属性归一公式,vi是第i维QoS 属性值,v′i是归一化后的结果。
现假设某流程片段P={s1,s2,…,sn},该流程片段总体服务质量为QoSp。针对不同QoS 属性,QoSp的每一维属性累加方法不相同,具体策略如表2。

表2 累加方法
为便于理解,现考虑二维属性,例如响应时间和价格。假设经过索引机制CLI检索出前7 个候选服务流程片段,如表3 所示。
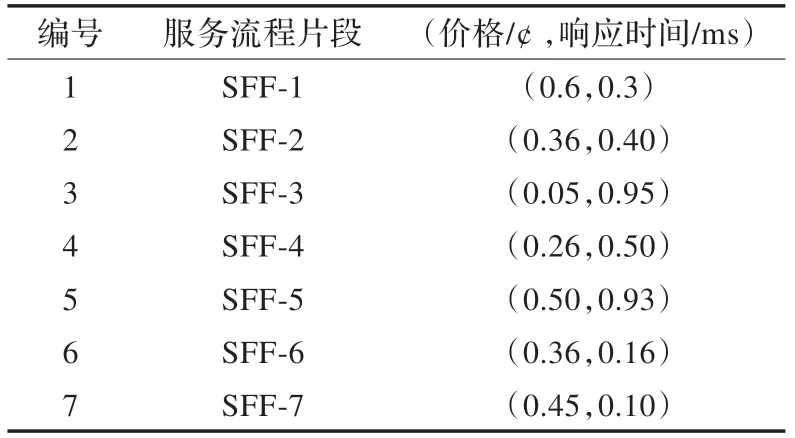
表3 候选流程片段样例
根据文献[10-12]提出的纸带模型,第一步需按照Skyline 点集合在Skyline 空间坐标系中的位置将整个Skyline 空间坐标系分成三个区域,分别为支配区域A,盲点区域B和被支配区域C。三个区域划分事例如图6所示,其中有7个服务片段被按照二维QoS映射至Skyline坐标系中,Skyline集合为{SFF-3,SFF-4,SFF-6,SFF-7}。
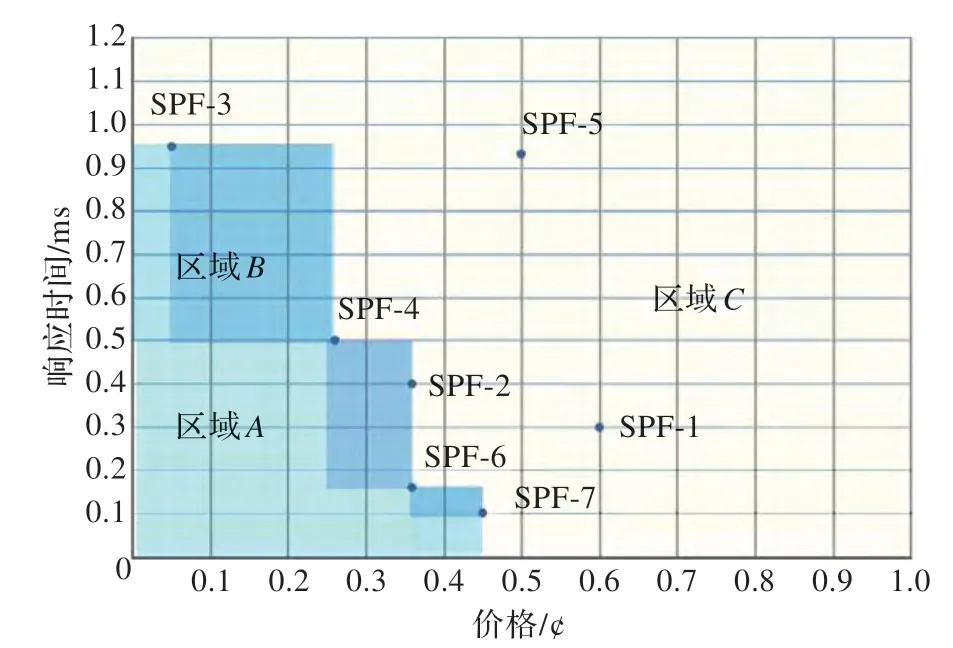
图6 基于纸带的Skyline坐标实例
(1)支配区域A。此区域位于Skyline 集合各点左连线的下部,包括连线部分,但不包括Skyline 上的各个服务片段点,为图6 所示的浅蓝色标有区域A的部分。在算法运行过程中,新服务片段按QoS 映射至此坐标系时,若落到区域A,则新服务片段必然会支配已经生成的Skyline 集合中某些数据点,亦即某些服务片段。此时在将新服务片段映射到坐标系中的同时,需要从原Skyline 集合中删除被新进服务片段支配的服务片段。若无服务片段点位于支配区域A,则判断为支配区域A的点必然为增加服务片段操作。
(2)盲点区域B。此区域位于Skyline 集合各点左连线的上部,右连线的下部,不包含左右连线,但包括Skyline 集合各点,为图6 中标有区域B的深蓝色部分。因其不归原Skyline 各点支配,也不支配原Skyline 中的元素,所以称为盲点区域。若新进服务片段与原Skyline无相互支配关系,则新进服务片段直接加入到Skyline集合。如果为删除服务片段操作,则删除的服务片段必为Skyline点。
(3)被支配区域C。此区域位于Skyline 集合各点右连线的上部,包括连线上的各点,不包括Skyline 集合各点,为图6 中浅黄色部分标有C区域标记的部分。此区域的各点被Skyline 支配,所以称为被支配区域。如新进服务片段位于此区域,并不影响原Skyline 各点,可直接将服务片段隐身进空间坐标系即可;若欲删除部分位于此区域,亦不影响原Skyline,可直接将服务片段从空间坐标系删除即可。
将Skyline 集合中按单属性进行排序组织成属性纸带,在此以图6 Skyline 空间坐标系为例,建立此集合的二维纸带模型,所需2 条纸带分别为响应时间纸带和价格纸带。其中响应时间纸带对应坐标系的竖轴表示服务片段的响应时间,按从小到大排序;价格纸带对应坐标系的横轴表示服务片段的价格,按从大到小排序。图6 Skyline 空间坐标系中Skyline 集合形成的二维纸带模型如图7 所示。
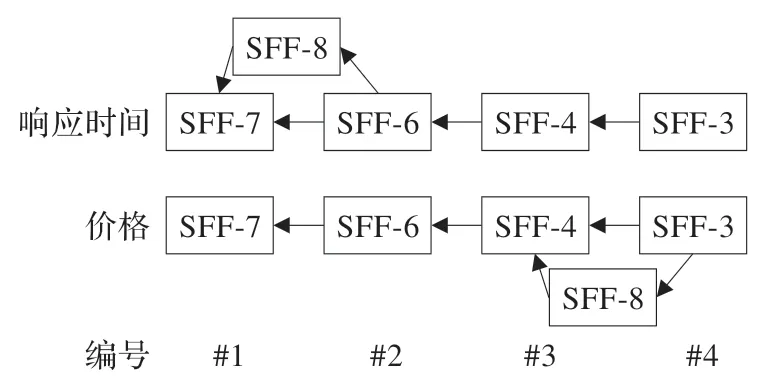
图7 纸带模型实例
计算新增服务片段或欲删除服务片段在所有纸带中的位置,规则如下:
规则1若变动服务片段SFF 在某一纸带P的K编号服务片段和K+1 编号服务片段之间,规则定义SFF在纸带P上的编号为K+0.5。
规则2若变动服务片段SFF 在某一纸带P有与其相等的编号K,此时编号为K的服务片段与服务片段SFF 在此维度上QoS 相等。规则定义SFF 在此纸带P上的编号为K。
规则3若变动服务片段SFF 在某一纸带P在第一个服务片段之前,规则定义SFF 在此纸带P上的编号为0.5。若在最后一个服务片段之后,算法定义SFF 在此纸带P上的编号为N+0.5,其中N为此纸带上服务片段的个数。
依据上述规则,假设现加入SFF-8 响应时间属性与SFF-7 相等,其价格属性与SFF-4 相等。由于SFF-7 在响应时间纸带上的编号为1,根据规则2 得SFF-8 在响应时间纸带上的编号为1,同理可知在价格纸带上SFF-8 的编号为3。
落入A支配区域的变化服务片段SFF 必然会支配某个或者某些原Skyline 集合中的服务片段,根据上示纸带模型可知,如果SFF 支配原Skyline 集合中的SFF-X服务片段,可知在响应时间和价格纸带上的编号的值不大于SFF-X 服务片段在对应纸带上的值,并且在某一维度SFF 的编号小于SFF-X 的编号。从上述纸带中可知在响应时间纸带上比SFF-8 差或相等集合为{SFF-3,SFF-4,SFF-6,SFF-7},在价格纸带上比SFF-8 差或相等的集合为{SFF-4,SFF-6,SFF-7}。当两个集合有交集时可知原Skyline中有被SFF-8支配的服务片段,所以SFF-8服务片段落至A支配区域,同理,可推出落入B盲点区域或者C被支配区域编码的关系。
4 实验分析
本文中的索引CLI 和SFF-query 算法均采用C++实现。设计并开展了一系列评估准确性和效率的实验,实验使用的个人电脑配置是CPU:2.8 GHz和内存:4 GB。
通过CTG[13]生成了一个包含大约20 万个流程片段和1.05 亿个原子服务的服务库,每个流程片段包含100~300 个不等的随机原子服务。此外,每个服务包含5~10个输入或输出参数。
CLI 的性能可能与许多参数有关,如在流程库中流程的数量(Amount Process,AP)、原子服务的平均数目(Average Atomic Service,AAS)、每个流程之间服务的依赖关系(Process Relation,PR)、抽象服务平均数量(Average abstract Service,AS)、每次查询条件依赖关系(Query Relation,QR)、标签编码的长度(Length Label,LL)和SLM-tree 中每个结点的孩子结点数量范围(Number range of Children,NC)NC=[r1,r2]。r1 是SLM-tree 内任意结点的孩子最小数目,r2 是任意结点的孩子最大数目。在本章中,通过改变上面不同参数进行了一系列评估性能的实验,所有实验重复5 次,每一种情况取平均值。LL 是CLI 最重要的参数指标之一,图8 和图9 分别显示通过采用不同的LL 对效率和准确性的影响,其中AP=500 KB,AAS=100 和NC=[8,16]。

图8 不同LL 效率比较

图9 不同LL 准确性比较
如图8 所示,查询效率明显随LL的增加而提高,因为高层SLM-tree 将明显不相干的流程片段较早过滤掉,但是更大的LL消耗更多内存,所以需要找到效率和内存成本之间的平衡点。此外,当LL>240 时,所有曲线显示突然发生强烈变化,现象出现原因是当CLI 的规模大于可用内存时,额外的I/O 操作降低了效率。
从图9 可以看出,准确性随着标签长度增加而提高。就像其他标签树,如果LL很短,将节省大量内存空间,装载更多的索引结点到内存中。但是,同时也导致更多的服务或关系被映射到相同的标签中,短小的LL将导致标签重复,造成精度降低。此外,更复杂的查询条件依赖于较长的LL,因为需要更多的比特位确保查询标签的真实性。总结图8 和图9 中实验结果,最终选择LL=218,可以支持非常复杂的查询,并且将被用于后续的实验中。
NC=[r1,r2]直接影响SLM-tree 深度,是另一个重要的参数指标。较大的NC将获得更高的查询效率,然而这样会导致大多数无用的结果不能被SLM-tree 的高层过滤掉。所以,有必要确定r1 和r2 的合适值以及它们之间的比率。如图10 所示,当AP=500 KB 和AAS=100 时,对所有AS来说其效率更稳定的比率为1∶2。此外,选择图10 中稳定性最高的3 个不同NC的曲线,分析它们对于不同规模的流程不同表现。图11 展示了它们效率与灵敏度之间的关系。虽然当AP<300 KB 时,r1=8 和r2=16 的曲线不是最高效率的曲线,但对更大规模流程显示出更好的优越性。最终,本文确定NC=[8,16]。
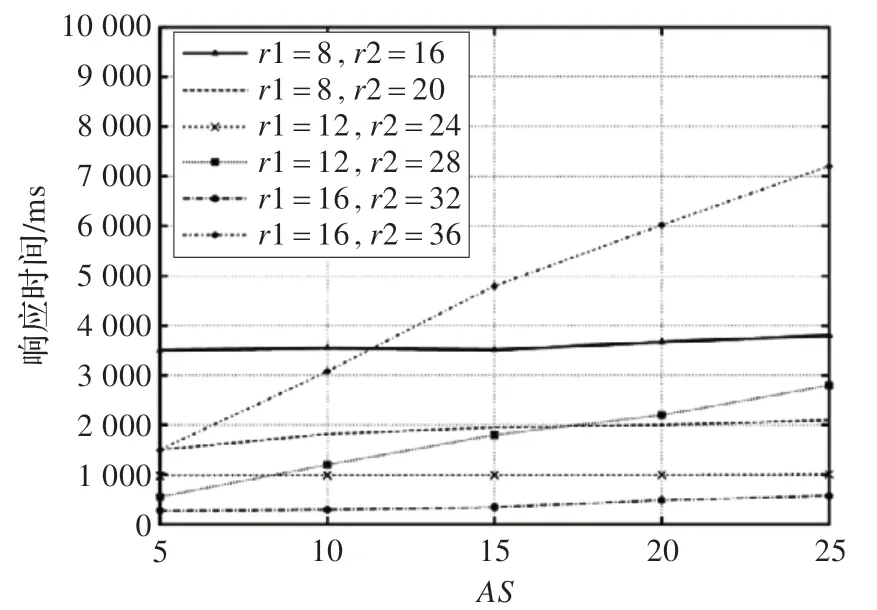
图10 不同NC 稳定性比较

图11 不同NC 效率比较
5 结束语
在传统服务计算研究领域[14-15]中,很少考虑服务流程的重用。但是,能够最大努力地重用流程片段,不仅能够提高服务组合的效率,而且对企业也可以节省人力和物力成本。本文提出了一种可变索引机制CLI,它能够检索任意粒度的流程片段,并达到重用的目的以满足更复杂的业务需求。结合数字标签和编码匹配技术,CLI 可以同时实现原子服务及组合服务的检索。最后通过一系列的实验验证了方法的可行性和有效性。今后工作主要目标是针对非严格SFF-query,进一步提高流程片段的利用率。
[1] Vanhatalo J,Völzer H,Leymann F.Faster and more focused control-flow analysis for business process models through sese decomposition[M].Berlin Heidelberg:Springer,2007.
[2] Eberle H,Unger T,Leymann F.Process fragments[M]//On the Move to Meaningful Internet Systems:OTM 2009.Berlin Heidelberg:Springer,2009:398-405.
[3] Schumm D,Karastoyanova D,Kopp O,et al.Process fragment libraries for easier and faster development of processbased applications[J].Journal of Systems Integration,2011,2(1):39-55.
[4] Bucchiarone A,Marconi A,Pistore M,et al.Dynamic adaptation of fragment-based and context-aware business processes[C]//2012 IEEE 19th International Conference on Web Services(ICWS),2012:33-41.
[5] Granell C,Gould M,Grønmo R,et al.Improving reuse of web service compositions[M]//E-Commerce and Web Technologies.Berlin Heidelberg:Springer,2005:358-367.
[6] Sonntag M,Karastoyanova D,Leymann F.The missing features of workflow systems for scientific computations[C]//Software Engineering(Workshops),2010:209-216.
[7] Granell C,Ramos J F.An object-oriented approach to GI web service composition[C]//15th International Workshop on Database and Expert Systems Applications,2004:835-839.
[8] Deppisch,Uwe.S-tree:a dynamic balanced feature index for offline retrieval[C]//SIGIR,1986.
[9] Alrifai M,Skoutas D,Risse T.Selecting skyline services for QoS-based web service composition[C]//Proceedings of the 19th International Conference on World Wide Web,2010:11-20.
[10] 胡建强,李涓子,廖桂平.一种基于多维服务质量的局部最优服务选择模型[J].计算机学报,2010,33(3):526-534.
[11] Ma Y,Chen L,Hui J,et al.Cbbcm:clustering based automatic service composition[C]//2011 IEEE International Conference on Services Computing(SCC),2011:354-361.
[12] Kolb J,Kammerer K,Reichert M.Updatable process views for user-centered adaption of large process models[M]//Service-Oriented Computing.Berlin Heidelberg:Springer,2012:484-498.
[13] Zheng Z,Zhang Y,Lyu M R.Distributed qos evaluation for real-world web services[C]//2010 IEEE International Conference on Web Services(ICWS),2010:83-90.
[14] Yu T,Zhang Y,Lin K J.Efficient algorithms for Web services selection with end-to-end QoS constraints[J].ACM Transactions on the Web(TWEB),2007,1(1).
[15] Yang J,Papazoglou M P.Service components for managing the life-cycle of service compositions[J].Information Systems,2004,29(2):97-125.
