基于空间自回归和空间聚类的渔情预报模型
2015-04-11袁红春谭明星顾怡婷陈新军
袁红春, 谭明星, 顾怡婷, 陈新军
(上海海洋大学: 1.信息学院; 2.海洋科学学院, 上海 201306)
传统的远洋渔情预报中, 多数学者采用多元线性回归方法定量地对环境数据及渔获数据进行分析,获得预报模型。如沈金鳌等[1]通过多元线性回归分析,将带鱼的资源量指数、各汛期的总捕捞努力量及长江径流量作为预报因子建立模型, 预报嵊山冬季带鱼(Trichiurus lepturus)鱼汛期的渔获量。陈新军等[2]在分析东黄海鲐(Scomber japonicus)的渔场时, 采用广义线性模型(Generalized Linear Model, GLM)和广义可加模型(Generalized Additive Model, GAM), 结合海洋环境因子建立预报模型, 以分析渔场资源的形成机制。陈新军等[3-4]研究了西北太平洋柔鱼(Ommastrephes batrami)渔场与环境因子的内在关系,利用月相对光诱鱿钓作业的影响, 证明月相对日产量的影响显著。但由于环境数据和渔获数据之间的关系并非线性的, 传统的线性回归预报模型不能准确地预测渔情信息。随着人工智能的崛起, 近年来有学者将人工智能技术用于渔情预测。杜云艳等[5]采用空间聚类方法建立关于渔业数据和对应水温间的时空分布模型。袁红春等[6]利用BP(Back Propagation)神经网络预报西北太平洋柔鱼渔获情况。张月霞等[7]利用案例推理预报东海区鲐鱼中心渔场。但单纯的空间聚类、专家系统、人工神经网络或案例推理方法并不能准确地反应渔业数据的时空分布。单独的空间聚类只考虑空间因素, 忽略了其他因子的影响,从而导致预测误差较大; 专家系统过于依靠专家知识经验; 人工神经网络的黑箱操作导致训练结果不易理解。上述原因阻碍了人工智能在渔情预报中的应用。其他学者, 如 Masahiko等[8]、Mohri等[9]、Daniel等[10]分别研究了最适宜大眼金枪鱼栖息的水温范围对产量的影响。日本的 Hiroaki[11]通过 GLM方法标准化印度洋大眼金枪鱼的延绳钓渔获量, 研究海洋环境与金枪鱼渔获量之间的关系。综上, 现有方法仅用单一的模型描述整片海域中的渔情信息, 而同一片海域中不同位置的自然环境不同, 单一的模型不能准确地预报整体渔情。同时, 依据现有统计数据可知, 大量渔获数据缺失, 因数据缺失而导致无法准确描述及研究环境和渔获量之间的关系, 也是渔情预报过程中亟待解决的问题之一[12]。本研究以印度洋大眼金枪鱼为例[13,14], 提出一种基于空间自回归和空间聚类的动态渔情预测模型, 以丰富预测方法,提高预测水平。
1 材料与方法
1.1 数据来源
海洋环境数据(海面高度, 海表温度, 叶绿素浓度)来源于美国国家海洋和大气管理局, 渔业作业数据(渔获量)来源于印度洋金枪鱼委员会。
1.2 基于空间自回归的数据预处理
1.2.1 数据的补缺
由于渔获数据缺失严重, 若要利用该数据建立预测模型, 需进一步补全缺失数据[15]。本研究在传统用于补全数据模型的基础上增加修正项, 构建空间自回归模型。首先, 给定观察数据为一个n维向量Y, 表示渔业产量数据, 一个n×m的矩阵X为海洋环境数据(m为环境因子数)。假设Y中每一个因变量yi都互相影响, 即:yi=f(yj),i≠j。回归方程可以修正成如下形式:
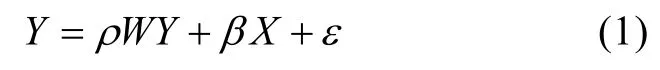
W是邻接矩阵, 在回归模型的空间拓展上起决定性作用。ρ是解释变量和因变量之间空间独立性强度的参数。残差向量ε被假定为服从独立同分布的标准正态分布,β是系数矩阵。
本研究用八-邻居准则构建邻接矩阵W。一个八-邻居准则构建的矩阵见图1。

图1 八-邻居邻接矩阵Fig.1 An eight-neighborhood its adjacency matrix
图1(a)表示空间上A、B、C、D 4个单元格的位置关系, 图1(b)表示每个点与其余点位置的关系矩阵。以矩阵第二行为例, 第二行表示单元格 B与其余单元格的位置关系, 因B与A有相邻的边、与C共享一条边和一个顶点、与 D有相接的顶点, 所以第一列(A)为1, 第三列(C)为1, 第四列(D)为1, 其余位置为0。标记每个单元格与其他单元格之间的关系后, 得到图1(b)中以二进制形式表示的邻接矩阵。然后对邻接矩阵中有标记的数值进行归一化。具体方法为: 令每一行之和为 1, 即归一化后的标记值为 1除以该行不为0的数值的个数。以第二行为例, 有标记的个数为3, 1/3约为0.3, 则每个有标记的值归一化后均为0.3。
当ρ=0, 式(1)就变成传统回归方程。修正后的模型有以下优点: (1)残差有很少的空间自相关性;(2)如果空间自相关系数在统计学上非常大, 就可以确定空间自相关存在的数量。这意味着因变量y变化的范围是y到相邻观测值的平均值; (3)模型的拟合度很高。
选取产量数据不为零的数据作为数据集, 构建空间自回归模型。模型建立后, 对空间缺失值进行插补, 插补方式为

其中Yi为待预测的缺失产量数据,表示该预测区域内产量的平均值,Wi为空间标准加权矩阵W的第i行,Y是表示渔业产量的向量,Y中缺失产量用0表示。
1.2.2 数据的归一化
为了研究印度洋大眼金枪鱼延绳钓渔业产量与相应栖息地海域海洋环境因子的关系, 需要建立一种客观标准反映该区域的资源丰度。单位捕捞努力量渔获量(Catch Per Unit Effort, CPUE)的大小常被作为资源丰度的相对指数来反映资源丰度的变化, 其定义为
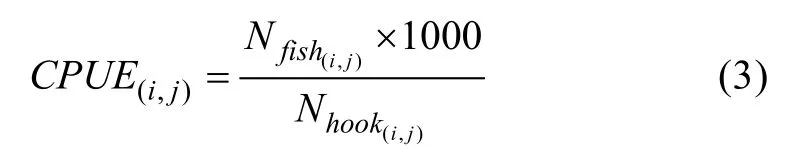
其中,CPUE(i,j)代表以经纬度(i,j)为起点的范围5°×5°区域内钓获率,Nfish(i,j)为该范围内的渔获尾数,Nhook(i,j)为该范围内的下钩枚数。CPUE(i,j)也可解释为每千钩上钩的大眼金枪鱼数量。再对单位捕捞努力量渔获量进行处理, 使用相对资源指数(Relative Abundance Index, RAI)构建栖息地适宜性指数模型。相对资源指数由某一时间地点的单位捕捞努力量渔获量值除以所有单位捕捞努力量渔获量值中的最大值得到, 计算方法为
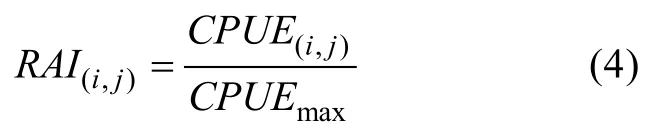
相对资源指数可看作反映栖息地质量的指标,等价于实际的栖息地适宜指数。
1.3 基于空间聚类的渔区划分
根据环境数据及渔获数据的相关性, 利用每条数据的地理位置信息进行 K-Means聚类, 把地理位置相对较近、渔获数据之间相关系数较高的区域划分为一类, 从而大大降低预测误差。空间中数据对象的记录主要包括空间实体的位置、形状以及对象之间的相互关系, 这种关系通常以坐标或者拓扑的形式表示。本研究将每5°×5°区域看作空间上的一个实体点, 每个实体点包含地理位置数据(纬度, 经度)和产量数据(栖息地适宜性指数 HSI)。其中, 地理位置数据中的纬度和经度为实体点的空间数据, 产量数据 HSI为实体点的属性数据。结合空间实体点的空间数据和属性数据等多方面因素考虑, 并参考大量有关聚类分析的文献后[16-18], 设计如下适用于渔情预报的空间聚类算法:
算法1 空间聚类算法
输入: 地理位置数据和产量数据
输出: 聚类结果
步骤如下:
(1) 确定待聚类数据集D, 聚类数K, 预设迭代次数m和收敛条件;
(2) 初始化聚类重心Ci;
(3) 计算每个数据Di到各个Ci的距离, 选取最近的距离归并到该类中;
(4) 更新重心Ci;
(5) 计算所有Ci值的变化;
(6) 直到满足收敛条件或达到迭代次数m, 停止迭代。
其中聚类重心的计算方法如下:
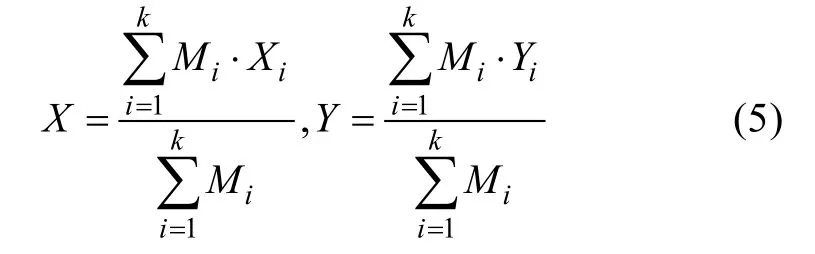
X为聚类重心的经度,Y为聚类重心的纬度,Mi为渔区i每个月的产量,Xi为渔区i重心点的经度,Yi为渔区i重心点的纬度, 渔区的个数为k。通过该聚类方法可以把地理位置相对较近、渔获数据之间相关系数较高的区域划分为一类, 从而减少因不同地理位置或不同环境所引起的误差。
1.4 基于非线性回归的栖息地适宜性指数模型
HSI模型在20世纪80年代由美国鱼类和野生动物保护委员会提出[19-21], 被用来定量地描述野生动物的栖息地质量。
考虑到渔获量的高低不仅与地理位置有关, 还与鱼类生存的环境因子, 如海表温度(SST)、海面高度(SSH)和叶绿素浓度(CHL-a)等有关。因此, 本研究针对每个环境因子, 利用其和栖息地适宜性指数之间的关系, 分别计算其对大眼金枪鱼产量影响的适宜性指数(Suitability Index, SI); 最后, 通过回归分析关联各种SI值得到综合HSI模型(图2)。

图2 栖息地适宜性指数模型构建方法Fig.2 Method for constructing the habitat suitability index model
利用综合优化分析计算软件平台——First Optimization的公式拟合工具箱, 对每个环境因子和其对应的 RAI分别作非线性拟合, 把最佳拟合公式作为栖息地适宜性指数计算公式中的单项栖息地适宜性指数SI, 通过对 3种环境因子在不同月份的拟合结果比较可知, 3种环境因子与栖息地适宜性指数的拟合形式可用如下形式表示:

其 中,A= (a1,a2, … ,a10),B=(0 , 1,… ,9),X=(x1,x2,… ,xm)′为环境因子。因此, 在计算参数A时,可先计算XB, 令Y=XB, 将非线性回归形式转为线性回归形式:

计算完每一项SI之后, 本研究将栖息地适宜性指数模型设置为:

SI是单项栖息地适宜性指数,d为回归方程中的常数项。根据每个月不同的环境数据和栖息地适宜性指数数据, 利用回归方程(8)计算出参数a、b、c和d即可得到每个月的综合栖息地适宜性指数模型。
2 实验过程与实验结果
2.1 实验过程
本研究的整个实验流程见图3, 在数据预处理部分加入空间自回归对缺失数据进行补全; 然后利用空间聚类对补全后的数据进行渔区划分; 再对每个渔区分别建立栖息地适宜性指数模型; 最后通过捕捞点的地理位置和环境信息, 确定该点所属渔区,结合该渔区的预测模型对该点产量进行预测, 并与真实数据对比, 从而验证该模型。
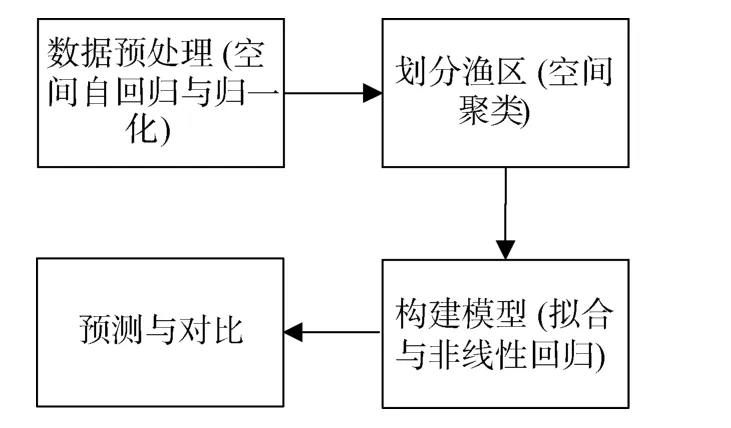
图3 实验流程及对应方法Fig.3 Experimental process and corresponding methods
利用2005年1月~2010年12月印度洋大眼金枪鱼的数据进行建模。首先, 根据本研究提出的空间自回归对缺损的数据进行补全。从IOTC官方网站下载印度洋 40°S~15°N, 40°E~120°E 区域内大眼金枪鱼渔获数据。根据文献[13]中显示, 印度洋大眼金枪鱼除45°S以上的高纬度区域之外均有产量。但获取的作业数据中, 许多地理位置没有记录相应的产量数据。通过选取产量不为零的数据作为建立模型的数据集, 对产量的空间缺失值进行插补, 扩充后续建模数据样本。
以 2009年 1月数据为例, 先对东经取正值, 西经取负值, 北纬取 90-纬度值, 南纬取 90+纬度值,对环境数据进行归一化, 与渔业作业数据进行匹配即可获得适合后续聚类、回归的数据样本。表1为2009年1月经过组织之后的数据样本。
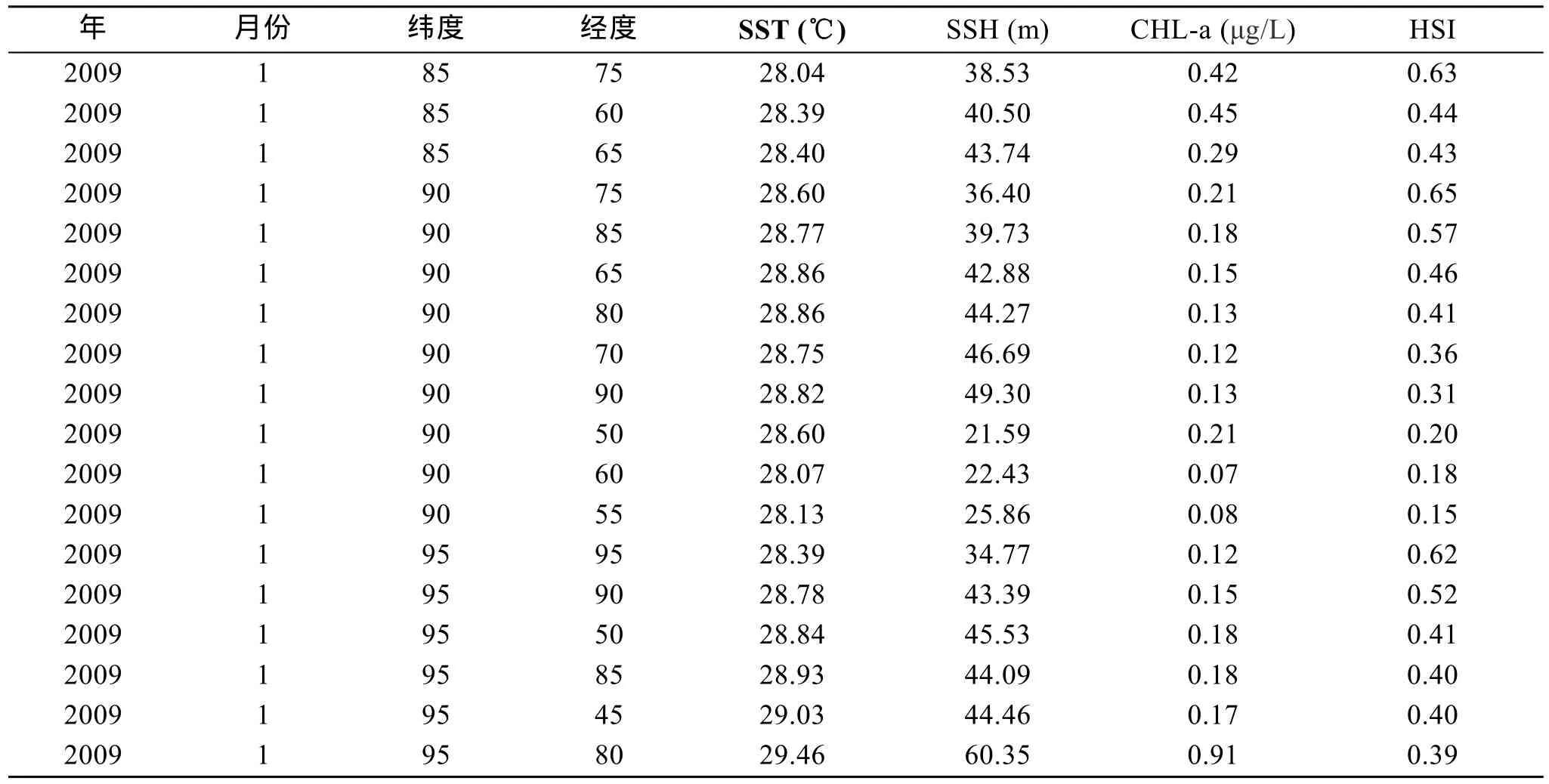
表1 2009年1月数据样本(部分)Tab.1 Data sample in Jan 2009(partial)
然后根据算法1, 得到聚类结果。聚类数量根据实际应用而定, 它的值会直接影响最终聚类结果,在实际应用中K值通常取为2~5。因此, 本研究将K分别设置为2、3、4、5, 利用Matlab2012b进行仿真实验。根据不同K值对数据进行聚类, 得到所有数据点归属类别后, 逐类别进行相关系数计算, 设xi=(xi1,xi2,...,xip)和xj=(xj1,xj2,...,xjp)是第i个和j个数据点观测值, 两个数据点之间相关系数为:
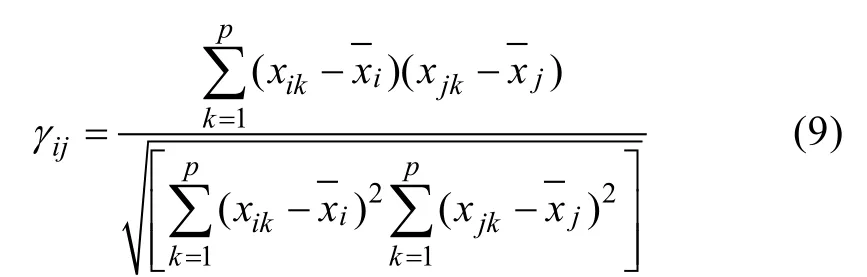
总体相关系数为:

通过算术平均方法得到不同K值下的相关系数,表2为相关系数计算结果。

表2 K取不同数值的相关系数Tab.2 Correlation coefficients of different K values
根据计算结果, 当K=3时, 得到的相关系数最大。因此, 本研究将K值确定为3。
在K均值算法中, 聚类重心的确定对后续聚类结果有很大影响。由于聚类的目的是找到地理位置上相对集中的几个区域, 从而减少回归的误差,而聚类的指标是以距离为度量值, 因此, 本研究通过均匀划分经纬度选取初始聚类重心。由于研究区域为印度洋 40°S~15°N, 40°E~120°E, 其经向范围较纬向范围大, 因此, 本研究以赤道 0°为纬度基线, 以此基线平分经度跨度, 东经取正值, 西经取负值, 北纬取 90-纬度值, 南纬取 90+纬度值,则初始中心的坐标以经纬度表示约为(0, 54), (0, 80)和(0, 106)。
令阈值为0.5, 将最终聚类迭代次数限定为1000次, 利用前文提出的空间聚类算法, 以表1的数据为例根据经纬度数据以及HSI数据, 对2009年1月份聚类结束后, 经过组织得到表3。
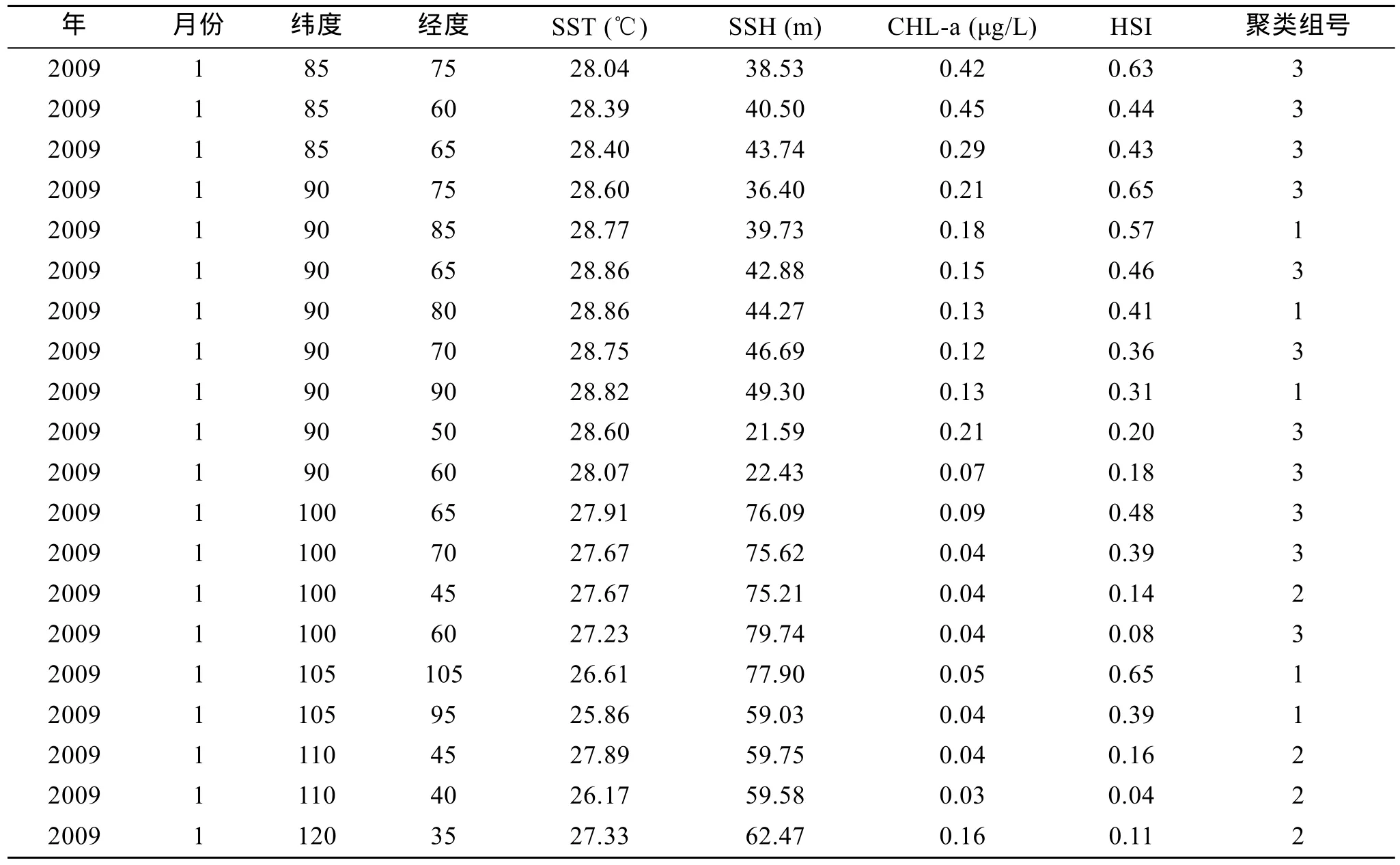
表3 2009年1月数据聚类结果(部分)Tab.3 Results of data clustering in Jan 2009 (partial)
根据2005年1月至2010年12月的聚类结果, 类别 1为赤道~35°S、80°E~110°E 的东印度洋区域; 类别 2 为 10°N~10°S、50°E~85°E 热带印度洋区域; 类别 3 为赤道~35°S、30°E~55°E 的西印度洋区域。
将2005年1月~2010年12月每一个月的数据进行聚类, 然后对所有数据进行类别标号。选取 2005年1月~2010年12月的金枪鱼延绳钓产量数据和相关海洋环境因子作为建模数据。对每一个环境因子和产量分别作非线性拟合, 将最佳拟合公式作为栖息地适宜性指数计算公式中的单项 SI, 再利用公式(8)计算出参数a、b、c和d即可得到每个月的综合栖息地适宜性指数模型。
2.2 实验结果
本研究通过聚类过程发现: 当海表温度在 26℃~29℃, 叶绿素浓度在(0.1~0.3)mg/m3, 海面高度较高时, 栖息地适宜性指数较高, 这与文献[13, 22~24]中的表述一致。
本研究以2005年至2010年的1月份数据为例,将栖息地适宜性指数大于 0.4的网格点在地图上标出, 结果发现: 印度洋大眼金枪鱼延绳钓的产量分布面较广, 除 45°S以上的高纬度海域外, 几乎整个印度洋海域, 均有其产量分布; 主要渔场集中在10°N~20°S, 50°E~85°E 的海域; 高产渔区以西印度洋为主; 东印度洋也有分布, 但产量明显稀少。以上均与文献[13]和文献[25]中吻合。
由于在构建栖息地适宜性指数模型之前对数据进行了空间聚类, 将地理位置相对较近而且栖息地适宜性指数与环境因子相关性较高的数据样本聚集到一起, 因此在模型检验及后续预测中心渔场中,需要根据数据样本到每个聚类重心的距离选取栖息地适宜性指数模型。
本研究采用 2011年 1~12月的数据对模型进行验证。针对每月数据, 根据每条记录对应的经纬度,计算其到3个聚类重心的距离, 确定其所属类别。再将该记录的环境数据代入相应的栖息地适宜性指数模型, 得到对应的栖息地适宜性指数估计值。最后在同一张图中对比预测值与真实值得到图4。
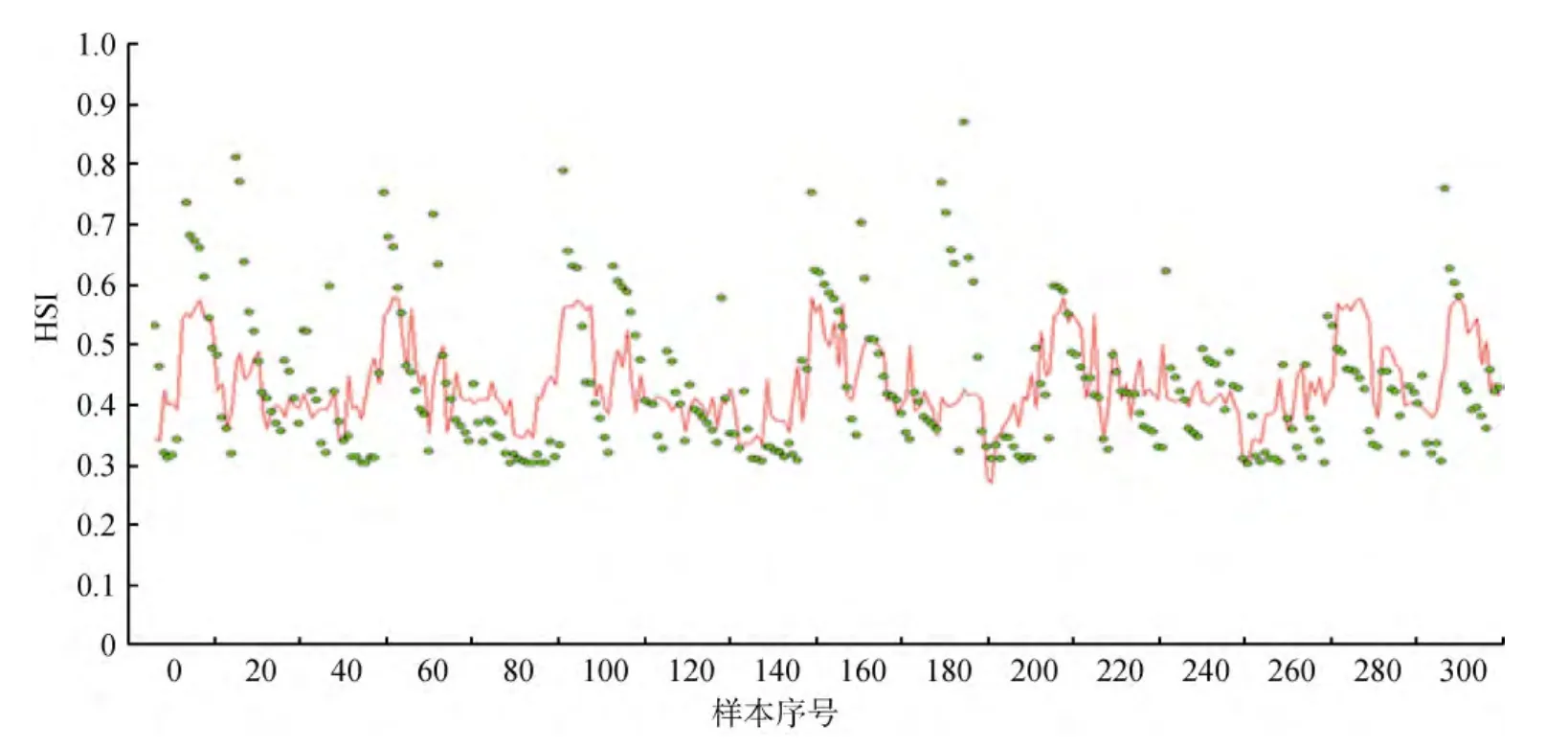
图4 预测与真实数据比较Fig.4 Comparison of predicted and actual data
在图4中横坐标表示每组数据的序号, 圆点是实际HSI值, 折线为预测模型得到的HSI值, 由图可知真实HSI最高值接近1.0, 但多数集中在0.4~0.6, 而预测值最高约为0.5, 且出现频率较高, 与事实符合。
3 讨论与结论
得到每个月的栖息地适宜性指数估计值之后, 计算其均方误差(MSE), 图5为本研究提出的基于空间聚类的渔情预测方法(Spatial Clustering Based Fishery Forecasting, SCBFF)和传统线性回归方法的误差对比。
由图5可知, 本研究提出的方法要优于传统的线性回归方法, 这是因为传统的线性回归预测方法并未考虑到因为数据缺失而导致预测精度偏低的问题, 作者通过空间自回归模型补全数据, 从数据本身的角度出发, 为之后的预测奠定了良好的基础。此外传统的预测方法是直接对整个渔区进行建模预测,并未考虑不同地理位置或不同环境所引起的偏差,作者充分考虑该偏差所引起的预测误差较大的问题,根据环境数据随着地理位置变化而变化的特点, 采用基于空间聚类的渔区划分方法, 将渔获量之间相关性较高并且相对地理位置较近的数据, 聚集在同一个类中, 对每个渔区分别建立模型, 有效地提高了预测精度。
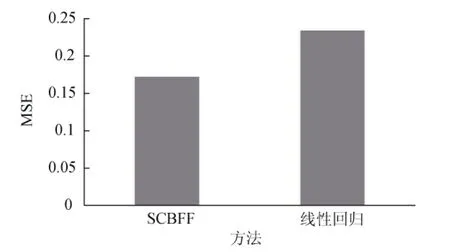
图5 SCBFF与线性回归的均方误差比较Fig.5 Comparison of MSE between SCBFF and linear regression
由于环境数据采集困难, 本研究仅从海表温度、海面高度和叶绿素浓度等 3个方面考虑海洋环境因子对金枪鱼产量的影响, 但实际上还有许多影响印度洋金枪鱼分布的因素, 包括海水盐度、饵料生物分布等环境因子, 这为本课题的后续研究提供空间。同时, 本研究能够根据现有的 3种环境因子与栖息地适宜性指数之间的关系构建出栖息地适宜性指数模型, 且平均预测性能良好, 但对于部分极值, 如栖息地适宜性指数非常高的区域并不能很好地预测出来,这也将成为后期深入研究方向之一。
本研究针对传统渔情预报方法由于精度偏低的问题, 利用空间自回归、K均值空间聚类、非线性回归等技术的优点, 提出一种基于空间自回归和空间聚类的渔情预报模型。首先, 利用空间自回归根据空间位置插补数据的能力, 插补缺损数据, 从而补全数据。再利用基于空间聚类的渔区划分方法, 对渔区进行划分。最后根据每一类中环境数据和产量数据之间的数学关系, 通过函数拟合与非线性回归分析,得到每个不同渔区块各自的栖息地适宜性指数模型。通过与传统的金枪鱼预测方法进行对比试验, 实验结果表明, 在提高模型拟合程度和减小预测误差方面, 本方法要优于传统的渔情预报方法。
[1] 沈金鳌, 方瑞生.浙江近海冬汛带鱼渔获量预报方法的探讨[J].水产科技情报, 1982, 5: 1-5.
[2] 陈新军, 郑波, 李纲.GLM和GAM模型研究东黄海鲐资源渔场与环境因子的关系[J].水产学报, 2008,32(3): 379-386.
[3] 陈新军.西北太平洋柔鱼渔场与水温因子的关系[J].上海海洋大学学报, 1995, 3: 181-185.
[4] 陈新军, 田思泉, 钱卫国.月相对北太平洋海域柔鱼钓获率的影响[J].海洋渔业, 2006, 28 (2): 136-140.
[5] 杜云艳, 周成虎, 崔海燕, 等.遥感与 GIS支持下的海洋渔业空间分布研究——以东海为例[J].海洋学报, 2002, 24(5): 57-63.
[6] 袁红春, 顾怡婷, 汪金涛, 等.西北太平洋柔鱼中长期预测方法研究[J].海洋科学, 2013, 37(10): 65-70.
[7] 张月霞, 丘仲锋, 伍玉梅, 等.基于案例推理的东海区鲐鱼中心渔场预报[J].海洋科学, 2009, 33(6): 8-11.
[8] Masahiko M, Yasuaki T.Vertical distribution and optimum temperature of bigeye tuna in the eastern tropical India Ocean based on deep tuna longline catches[J].Journal of National Fisheries University, 1997, 46(1):13-20.
[9] Mohri M, Hanamoto E, Takeuchi S.Optimum water temperatures for bigeye tuna in the Indian Ocean as seen from tuna longline catches[J].Nippon Suisan Gakkaishi, 1996, 62: 761-764.
[10] Daniel G, Francis M.Comparative analysis of the exploitation of bigeye tuna in the Indian and eastern Atlantic oceans with emphasis on purse seine[R].Victoria:IOTC Proceedings, 1999, 2: 158-171.
[11] Hiroaki O, Naozumi M, Takayuki M.GLM analyses for standardization of Japanese longline cpue for bigeye tuna in the indian ocean applying environmental factors[R].Japan: IOTC Proceedings, 2001.
[12] Menard F, Marsac F, Bellier B, et al.Climatic oscillations and tuna catch rates in the Indian Ocean: a wavelet approach to time series analysis[J].Fisheries Oceanography, 2007, 16(1): 95-104.
[13] 苗振清, 黄锡昌.远洋金枪鱼渔业[M].上海: 上海科学技术文献出版社, 2003: 24-26.
[14] 李军, 李志凌, 叶振江.大眼金枪鱼渔业现状和生物学研究进展[J].齐鲁渔业, 2005, 22(12): 35-38.
[15] Herrera M L, Pierre M J.Review of the statistical data available for the tropical tuna species[R].Maldives: Indian Ocean Tuna Commission, 2011.
[16] Lin C R, Liu K H, Chen M S.Dual clustering: integrating data clustering over optimization and constraint domains[J].IEEE Transactions on Knowledge and Data Engineering, 2005, 17(5): 628-637.
[17] Zhou J G, Guan J H, Li PX.A Dual clustering algorithm for distributed spatial databases[J].Geo2spatial Information Science, 2007, 10(2): 137-144.
[18] 柳盛, 吉根林.空间聚类技术研究综述[J].南京师范大学学报(工程技术版), 2010, 10 (2): 57-62.
[19] 王家樵, 朱国平, 许柳雄.基于 HSI模型的印度洋大眼金枪鱼栖息地研究[J].海洋环境科学, 2009, 28(6):739-742.
[20] 陈新军, 冯波, 许柳雄.印度洋大眼金枪鱼栖息地指数研究及其比较[J].中国水产科学, 2008, 15(2):269-278.
[21] 胡振明.利用栖息地适宜指数分析秘鲁外海茎柔鱼渔场分布[D].上海: 上海海洋大学, 2009.
[22] 杨胜龙, 张禹, 樊伟, 等.热带印度洋大眼金枪鱼渔场时空分布与温跃层关系[J].中国水产科学, 2012,19(4): 679-689.
[23] 曹晓怡, 周为峰, 樊伟, 等.印度洋大眼金枪鱼、黄鳍金枪鱼延绳钓渔场重心变化分析[J].上海海洋大学学报, 2009, 18(4): 466-471.
[24] 陈雪冬, 崔雪森.卫星遥感在中东太平洋大眼金枪鱼渔场与环境关系的应用研究[J].遥感信息, 2006, 1:25-28.
[25] 杨胜龙, 马军杰, 伍玉梅, 等.印度洋大眼金枪鱼和黄鳍金枪鱼渔场水温垂直结构的季节变化[J].海洋科学, 2012, 36(7): 97-103.
