基于用户人口统计与专家信任的协同过滤算法*
2015-03-27焦东俊
焦东俊
(北京邮电大学智能通信软件与多媒体北京市重点实验室,北京 100876)
基于用户人口统计与专家信任的协同过滤算法*
焦东俊
(北京邮电大学智能通信软件与多媒体北京市重点实验室,北京 100876)
推荐系统是学术研究的热门课题,在工业界应用也越来越广泛,推荐系统旨在为用户推荐相关的感兴趣的物品。协同过滤算法被用来比较用户及物品的相似度,向用户推荐与其最近邻用户的偏好。为了提高协同过滤算法预测的准确率,提出基于用户人口统计与专家信任的协同过滤算法,先比较用户人口统计属性,然后进一步比较用户与专家的人口统计属性来得到用户与专家的相似度,从而提高预测的准确性。实验验证表明,提出的算法能够有效提高协同过滤算法预测的准确率。
推荐系统;协同过滤算法;人口统计;专家信任
1 引言
近年来,推荐系统成为学术研究的热门课题,在工业界应用也越来越广泛。推荐系统通过用户的历史偏好信息,来预测用户可能感兴趣的物品,好的推荐系统能够为用户准确推荐他们感兴趣的项目。为了提高预测的准确率,本文提出基于用户人口统计与专家信任的协同过滤算法,引入基于用户人口统计来提高准确率,并将用户与专家的背景知识相比较,使得预测结果在专家的专业意见和兴趣相似、背景相似的用户意见之间得到平衡。
2 基于用户人口统计的协同过滤算法
现有的基于用户的协同过滤算法仅利用用户对项目的评分来计算用户相似度,由于没有考虑到用户年龄、性别、职业、地区的差别性,推荐效果比较单一,让用户缺乏惊喜感,推荐准确率也不高。本文在协同过滤算法上引入基于用户人口统计的方法,在用户评分相似度的基础上,比较用户间的人口统计信息,找到同性别、同年龄段以及背景相似的用户,以期在推荐系统中使用户找到符合自己意愿的推荐结果。
有一些用户打分记录普遍比较高,存在着个人偏好,文献[1]提出用基准偏移量bu,i来表示用户偏好:
bu,i=u+bu+bi
其中,bu和bi分别表示用户u对物品i的偏好,u表示评分矩阵里用户评分的平均分。
考虑用户人口统计资料来选择近邻和插入权重来计算用户相似度:
其中,Rk(u)表示用户u的k个邻居的集合;bu,i表示基准偏移量;wu,v表示插入的权重,是在基准偏移量之上的偏移量;(rv,i-bu,i)表示偏移量的系数。当u和v相关度wu,v比较高,(rv,i-bu,i)也高时,表示实际值高出预测偏移量,增加(rv,i-bu,i)×wu,v偏移量到基准偏移量中。当(rv,i-bu,i)接近为0时,表示基准偏移量达到了一定的精确程度,不会增加过多偏移量到基准偏移量中。
当预测用户u对物品i的评分时,查找对物品i打分的所有用户集R(u),再计算用户u和集合里每个用户之间的相似度,通过用户人口统计来计算kNN(k-Nearest Neighbor)近邻。用户u的m维人口统计信息向量为(V1,V2,…,Vm)。
用余弦相似性表示两个用户间的相关性:
其中,sim(u1,u2)表示通过用户u1和用户u2的两个n维向量得到的两个用户的余弦相似性。
Pearson相关系数用下面的公式来计算:
其中,sim(u1,u2)表示用户u1和用户u2的相似程度,β为参数,n/(n+β)表示两个用户对n个物品进行评分时,对越多物品评分则n(n+β)越接近于1,相似度高,反之则相似度低。
在相似度算法中,用sim(u1,u2)直接作为wu,v表示用户u和v之间的评分关系。为了寻找相似背景的用户,在计算用户相似度时加入人口统计信息,比如本文中所使用的MovieLens数据集中用户年龄、性别、职业和邮编。文献[2]提出将两种用户相似度结合,用以下公式表示:
cor(u,v)=sim(u,v)+sim(u,v)×dem_cor(u,v)
其中,cor(u,v)表示用户u和用户v的总体相似度,sim(u,v)表示用户u和用户v的评分相似度,dem_cor(u,v)表示用户u和用户v的人口统计相似度。
3 基于专家信任的协同过滤算法
文献[1]在2009年提出在协同过滤算法中使用专家意见(比如在电影推荐系统中,使用电影评论家的评分和评论),抛弃除了活跃外的其他用户的评分来提高推荐准确率。结合基于用户人口统计的协同过滤算法,本节借助专家评分提高预测准确率。利用用户的人口统计属性来比较用户间的相似度,然后把电影评论专家的评分结合用户的评分,用来权衡专家和相似人口属性的用户间的预测结果。
基于专家意见协同过滤算法采用专家的评分数据。专家评分数据矩阵相比普通用户的评分数据矩阵要更加合理,为用户u做预测的时候,不采用除了u的别的用户,使用专家的评分数据。先来计算u和专家e间的相似性sim(u,e):
sim(u,e)=
其中,|Iu|和|Ie|表示某用户u与专家e评论的项目集合,|Iue|=|Iu|∪|Ie|。
在为u选择最近邻的时候,先选取和u相似度较高的前n位专家形成的相似近邻集CS(u),筛选相似度的阈值与最近邻阈值CS(u)得出相似近邻集S(u),这样用户u对物品i的预测评分值ru,i为:

3.1 专家与用户差异对预测结果的影响
基于专家意见的协同过滤算法只使用了专家的意见来做预测,因为专家评分数据与用户评分数据相比有很多优点,并且专家数量大大小于用户数量,这样为用户查找相似最近邻时搜索范围也大大降低。
由于专家与用户背景知识很不同,所以专家对同一事物的看法也会不同。比如对于电影评论家来说,他们对电影有比较深刻的认识,衡量电影好坏也是从专业的角度去看,利用专业评价标准来评价电影。普通用户对同样一部电影的评价会因为他们的职业、爱好以及所处环境不同而不同。这样就造成电影评论专家认为是一部好电影,普通用户则可能因为无法理解电影中内容以及不符合自己的兴趣、爱好等原因而不喜欢它。普通用户评分很高的电影,电影评论专家又觉得不符合电影专业的标准而给电影差评。
只使用电影评论专家的评分数据并不太准确。平均绝对偏差是评价推荐质量的公认标准,基于电影评论专家意见的协同过滤算法和传统的基于用户的协同过滤算法相比,并没有很大程度地降低平均绝对偏差。
所以,基于以上分析,本节在基于用户人口统计的基础上,更进一步利用电影评论专家评分意见,来减少电影评论专家与用户背景知识的差异对预测结果带来的负面影响,为目标用户寻找最近邻的时候,使用一种新的级联式的基于用户人口统计的相似度度量方法。
3.2 用户-专家最近邻的选择
由于相似专家集只是找到和目标用户相似兴趣的专家,用户u的相似专家集记作S_E(u)。
相似用户集要求找与目标用户兴趣相似以及背景知识相似的专家e。为了寻找这样的专家,用公式计算用户-专家人口统计相似度:
cor(u,e)=sim(u,e)+sim(u,e)×dem_cor(u,e)
4 改进的基于用户人口统计与专家信任的协同过滤推荐算法
本节提出级联式的基于用户人口统计与专家信任的协同过滤算法,以改进协同过滤算法的单一性。具体步骤是先使用协同过滤算法找到基于用户评分的用户相似度,在此基础上比较用户人口统计属性来提高用户相似度的准确性;然后进一步比较用户与专家的评分相似度以及用户-专家的人口统计属性来得到用户与专家的相似度,从而提高预测准确性。
在得到目标用户u的相似专家集S_E(u)和相似用户集S_U(u)后,u对项目i的预测评分Pu,j为:

这样得到的Pu,j,通过ɑ的调节,既得到专家的意见指导,又参考了背景知识用户的相似意见。
5 实验结果与分析
5.1 实验环境
CentOS 5.10, JDK1.6.0_12,Apache-Tomcat-6.0.36,Apache-Maven-2.2.1,Hadoop-0.20.204.0,Mahout-0.5,MySQL 5.0.95,MyEclipse 2013 SR2。
5.2 实验数据集及评测标准
用户数据来自MovieLens[16]。本实验采用100 K数据集,包含了943位用户对1 682部电影的10多万条评分。用户属性包括:年龄、性别、职业和邮编,电影属性包括:名称、年份及类别等。
设用户有m维属性,包括年龄、性别、职业和邮编。将每维数据信息处理成用数字表示下面的信息,比如,在本文中采用的MovieLens数据集里:
(1)性别信息。
0:男性;
1:女性。
(2)年龄信息。
1:18岁以下;
2:18~24岁;
3:25~34岁;
4:35~44岁;
5:45~49岁;
6:50~55岁;
7:56岁以上。
(3)职业信息。
0:“other”ornotspecified;
1:“academic/educator”;
2:“artist”;
3:“clerical/admin”;
4:“college/gradstudent”;
5:“customerservice”;
6:“doctor/healthcare”;
7:“executive/managerial”;
8:“farmer”;
9:“homemaker”;
10:“K-12student”;
11:“lawyer”;
12:“programmer”;
13:“retired”;
14:“sales/marketing”;
15:“scientist”;
16:“self-employed”;
17:“technician/engineer”;
18:“tradesman/craftsman”;
19:“unemployed”;
20:“writer”。
(4)邮政编码采用原数据集中的数字邮政编码。
专家数据集来自MovieLens+IMDb/RottenTomatoes[17],包含了2 113名用户及专家对10 197部电影的855 598条评价。
实验采用的度量标准和大多数协同过滤推荐算法采用的度量标准一样,使用了平均绝对偏差MAE。
5.3 推荐结果比较
利用本文改进的基于人口统计与专家信任算法和传统基于用户的协同过滤算法比较,基于用户人口统计的协同过滤算法以及基于专家信任的协同过滤算法进行了比较,实验分别设置不同近邻比例以及专家意见阈值ɑ (2%~20%),并计算最近邻算法中相对应的邻近个数,最近邻相似度采用Pearson相关系数,得出的实验结果如图1所示。
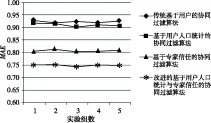
Figure 1 Experimental results of collaborative filtering algorithm based on user demographics and experts opinions
由实验结果观察:
改进前的结果:传统基于用户的协同过滤算法的准确率较低,而基于用户人口统计的协同过滤算法对准确率提高很小。这表明,用户在评分的过程中,用户的年龄、性别、职业、地区已经很大程度上反映在了评分结果中。单独使用基于专家信任的协同过滤算法对准确度有一定的提高。
改进后的结果:改进的基于用户人口统计与专家信任的协同过滤算法的准确率最好,算法既考虑了用户的人口属性对预测评分的影响,又考虑了专家信任的人口属性对预测评分的影响,从而实现了比较好的预测准确率。
实验表明,改进的基于人口统计属性及专家信任的协同过滤算法好于传统基于用户的协同过滤算法,也好于分别使用基于人口统计的协同过滤算法和基于专家信任的协同过滤算法。
6 结束语
本文在传统基于用户的协同过滤算法基础上,使用基于人口统计属性的协同过滤算法,以改进传统协同过滤推荐系统,并进一步分析基于专家的协同过滤算法存在的缺点,提出要同时使用用户评分和专家意见。使用用户-专家的人口统计学属性提出了一种相似度度量方法,找到用户专家间的相似度。这样在为目标用户预测时,既考虑到用户间的背景相似度,也同时借助于兴趣相似、背景知识相近的专家意见,有效提高了预测准确率。实验在Rotten Tomatoes上获取的专家数据和MoiveLens数据的两个子集上验证了本文提出的结合人口统计属性与专家意见的协同过滤算法的预测结果,最终结果显示,该改进算法有效也提高了预测质量。
致谢 感谢北京邮电大学孟祥武教授对本文研究工作的悉心指导并提出的反复修改意见。
[1] Koren Y. Factorization meets the neighborhood:A multifaceted collaborative filtering model[C]∥Proc of ACM Conference on KDD, 2008:426-434.
[2] Shang Ming-sheng, Zhang Zi-ke, Zhou Tao, et al. Collaborative filtering with diffusion-based similarity on tripartite graphs[J]. Physica A:Statistical Mechanics and its Applications, 2010,389(6):1259-1264.
[3] Liu Jian-guo, Zhou Tao, Wang Bing-hong. Advances in personalized recommendation system[J]. Progress in Natural Science, 2009, 19(1):1-15. (in Chinese)
[4] Amatriain X, Lathia J M, Pujol H, et al. The wisdom of the few:A collaborative filtering approach based on expert opinions from the web[C]∥Proc of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval,2009:532-539.
[5] Odic A, Tkalcic M, Tasic J F, et al. Relevant context in a movie recommender system:Users’ opinion vs. statistical detection[C]∥Proc of the 4th Workshop on Context-Aware Recommender Systems, 2012:1.
[6] Sun bin. Personalized intelligent recommendation engine algorithm and its application[D]. Wuhan:Huazhong University of Science and Technology,2012. (in Chinese)
[7] Yun Long. Research and implementation of collaborative filtering recommendation system key issues[D]. Harrbin:Heilongjiang University, 2011.(in Chinese)
[8] Chen Zhi-min,Li Zhi-qiang.Collaborative filtering recommendation algorithm based on user characteristics and project properties[J]. Computer Applications, 2011,31(7):1748-1755. (in Chinese)
[9] Jiao Dong-jun. Research and design movie recommender system based on Mahout[D]. Beijing:Beijing University of Posts and Telecommunications, 2014. (in Chinese)
[10] Aim H J. A new similarity measure for collaborative filtering to alleviate the new user cold--starting problem[J].Information Sciences, 2008,178(1):37-1.
[11] Huang Chuang-guang,Yin Jian,Wang Jing,et al.Uncertainty neighbor collaborative filtering recommendation algorithm[J]. Journal of Computers,2010,33(8):1369-1377.(in Chinese)
[12] Zhao Zhi-dan,Shang Ming-sheng.User-based collaborative-filtering recommendation algorithm on Hadoop[C]∥Proc of the 3rd International Conference on Knowledge Discovery and Data Mining, 2012:478-481.
[13] Ge Shi-ne, Gen Xin-yang. An SVD-based collaborative filtering approach to alleviate cold-start problems[C]∥Proc of 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2012),2012,DOI:10.1109/FSKD.2012.6233900.
[14] Xiao Min, Yan Bing-jie. Collaborative filtering recommendation algorithm based on shift on users’ preferences[C]∥Proc of 2011 International Conference on Business Management and Electronic Information, 2010:520-523.
[15] Vozalis M,Margaritis K G.Collaborative filtering enhanced by demographic correlation[C]∥Proc of the ALU Symposium on Professional Practice in AI,the 18th World Computer Congress,2004:393-402.
[16] http://grouplens.org/datasets/movielens/.
[17] http://grouplens.org/datasets/hetrec-2011/.
附中文参考文献:
[3] 刘建国, 周涛, 汪秉宏. 个性化推荐系统的研究进展[J]. 自然科学进展, 2009, 19(1):1-15.
[6] 孙斌.个性化智能推荐引擎算法研究及应用[D].武汉:华中科技大学,2012.
[7] 云龙.协同过滤推荐系统中关键问题研究与实现[D].哈尔滨:黑龙江大学,2011.
[8] 陈志敏,李志强.基于用户特征和项目属性的协同过滤推荐算法[J].计算机应用,2011,31(7):1748-1755.
[9] 焦东俊.基于Mahout的电影推荐系统研究和实现[D].北京:北京邮电大学,2014.
[11] 黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
JIAO Dong-jun,born in 1970,MS,senior engineer,his research interests include recommender system, and machine learning.
Collaborative filtering algorithm based on user demographics and expert opinions
JIAO Dong-jun
(Beijing Key Laboratory of Intelligent Telecommunications,Beijing University of Posts and Telecommunications,Beijing 100876,China)
Recommender systems have been used tremendously in academia and industry, and the recommendations generated by these systems aim to offer relevant interesting items to users. Collaborative filtering algorithm is used to calculate the similarities between users and items, and recommends the nearest neighbors’ preferences to users. In order to improve the prediction accuracy of collaborative filtering algorithm, we propose a collaborative filtering algorithm based on user demographics and expert opinions. First we compare users’ demographic attributes, which are then compared with expert demographic attributes to calculate the similarities between users and experts. Experimental results verify that the algorithm proposed in this paper can effectively improve the prediction accuracy of collaborative filtering algorithm.
recommender system;collaborative filtering;demographic correlation;expert opinions
1007-130X(2015)01-0179-05
2014-09-13;
2014-11-16
TP274
A
10.3969/j.issn.1007-130X.2015.01.028

焦东俊(1970-),男,安徽安庆人,硕士,高级工程师,研究方向为推荐系统和机器学习。E-mail:nelson.jiao@gmail.com
通信地址:100876 北京市北京邮电大学智能通信软件与多媒体北京市重点实验室
Address:Beijing Key Laboratory of Intelligent Telecommunications,Beijing University of Posts and Telecommunications,Beijing 100876,P.R.China
