基于Kinect 传感器的人体行为分析算法*
2015-03-26战荫伟
战荫伟,张 昊
(广东工业大学 计算机学院,广东 广州510006)
0 引 言
人体行为分析一直是计算机视觉领域的一个研究热点,在人机交互、视频监控、视频检索及智能家居等方面有着重要的应用。此前,人体行为分析主要是在二维彩色图像视频数据的基础上进行研究,通过视频序列提取行为描述的特征信息,用行为识别算法对行为特征分类和理解,以达到识别行为的目的。
关于人体行为识别已有大量的研究工作。普遍方法是对视频中的兴趣点使用时空特征进行建模,如局部时空兴趣点STIP[1],还有梯度特征如HOG[2]。但是,单纯使用点特征或者梯度特征都不甚理想。另一类方法是统计模式识别,如典型的隐马尔可夫模型(HMM)、条件随机场(CRF)模型。HMM 是生成式模型,即先建立样本的概率密度模型,再利用模型进行推理预测。CRF 模型属于判别式模型,其思想是在有限条件下建立判别函数,直接研究预测模型。Brand M 等人[3]利用Coupled HMMs 识别双手活动。Weinland D 等人[4]用HMM 结合三维网格对人体动作建模。Martine F 等人[5]利用HMMs 和动作模版识别人体活动。与HMM 生成模型类似,Lan T 等人[6]借助人与人之间的交互分析使用一种判别模型。Sminchisescu C 等人[7]应用CRF 对人体行为(如走、跳等)进行分类,相比HMM 方法有所提高。Kumar S 等人[8]应用CRF 模型完成图像区域标记工作。Torralba A 等人[9]引入Boosted Random Fields,模型组合了全局和局部图像信息进行上下文目标识别。
以上算法虽然能达到较好的性能,但因光照变化、物体遮挡及环境变化等因素的干扰,识别精度会大幅度降低。为此,本文尝试通过引入Kinect 红外传感器,其可同时获取彩色图像和深度图像,深度图像中像素值仅与Kinect 到物体表面距离有关。深度图像具有颜色无关性,不受阴影、光照、色度变化等因素的影响;其次,根据距离很容易将前景与背景分开,这也解决利用RGB 图像进行识别时难以将人体分割出来的困难。LuX等人[10]利用Canny算子对深度图像进行边缘提取,通过计算距离变换,利用模型匹配,计算出头部位置并根据经验比例定位整个人体,进而达到检测与跟踪的目的。Abhishek K[11]通过距离变换与模型匹配方法,对头部定位选择Haar 特征级联的分类模型。Shotton J 等人[12]用像素差分法提特征,分类器用了随机森林算法,训练样本采用合成的人体深度图像,对人体各部位进行识别。
本文首先通过阈值分割方法对Kinect 获取的深度图处理,提取前景人物,然后提取深度图像上的局部梯度特征,作为条件随机场模型的输入变量,进行模型训练,设计实验对算法的有效性进行验证。
1 基于深度图的特征提取
采用Kinect 传感器进行图像采集,结构图如图1 所示,深度采集范围为0.8~4 m,输出RGB 图像帧率为30,深度图分辨率为640×480。算法能够在帧率为30 的图像采集速度下实现实时处理。

图1 Kinect 传感器Fig 1 Kinect sensor
利用深度图检测人体与Kinect 之间的距离,得到人体在三维空间中的坐标值,从而确定人体空间区域的初始位置,再由Kinect 获取的深度图计算出人体目标的深度直方图,由深度直方图选取阈值去除背景和图像噪声,阈值的选取与人体要有一定距离才能完整提取人体目标信息。图2和图3 分别为获得的RGB 图和Depth 图。对深度图的定量分析采用方向梯度直方图(HOG)方法。设深度图为I,像素为x,dI(x)是x 点处的深度值。设集合D 为方向集

图2 彩色图Fig 2 RGB image

图3 深度图Fig 3 Depth image
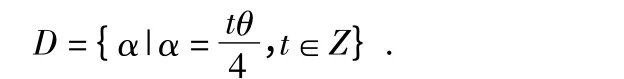
Kd=(k1,k2)代表以x 为起点沿d 方向的偏移向量,满足
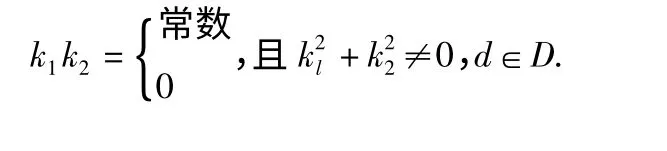
任取2 个偏移向量,组成向量对θ=(kU,kV),共有28 对,对每个θ 局域梯度特征计算如下
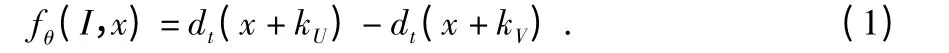
fθ(I,x)反映了像素x 周围的梯度信息,具有空间不变性,当人体在场景中自由移动时,其表面上的点特征数值是不变的。图4 为像素点八邻域的空间关系图,中心像素指向周围8 个像素,形成8 个方向,用公式(1)计算每个像素28 个向量对的局部梯度值fθ(I,x)。
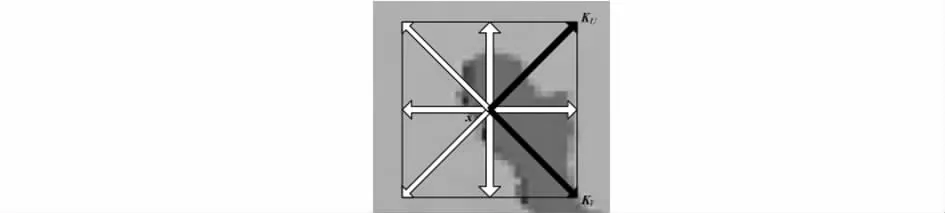
图4 特征提取图Fig 4 Feature extraction image
2 CRF 模型识别人体动作
CRF 模型是概率图模型中的一种无向图模型,它是在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率分布。假设G=(V,E)表示一个无向图,随机变量Y=(yv)v∈V,Y 中元素与无向图G 的顶点一一对应。如果G为一阶链式结构,有G{V={1,2,…,n},E={(i,i+1)},对应人体行为识别问题可抽象为线性链条件随机场模型,对一段n 帧图像行为视频,可抽象为观察序列X=(x1,x2,…,xn),行为标记序列为Y=(y1,y2,…,yn),如图5 所示。
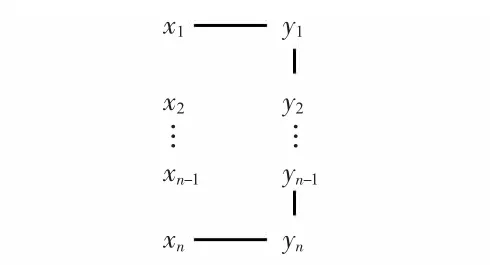
图5 线性链CRF 结构图Fig 5 Linear linked CRF structure graph
其对应的行为标记为Y=(y1,y2,…,yn)的概率为
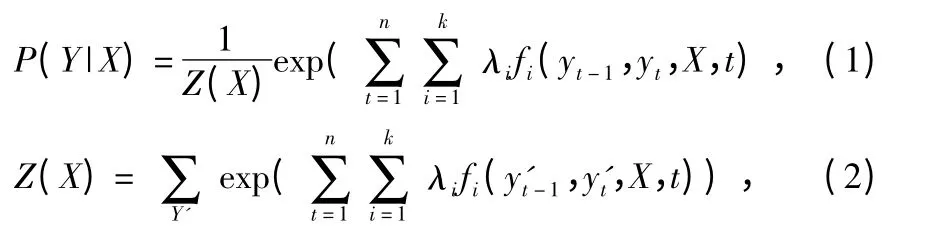
式中 Z(X)为相对于每个观察序列X 的归一化因子;fi(yt-1,yt,X,t)为二值表征函数,对状态转移yt-1→yt,衡量观察序列X 中第t 个位置是特征。用最大似然估计法计算λ,求其对数似然函数的一阶导数得到
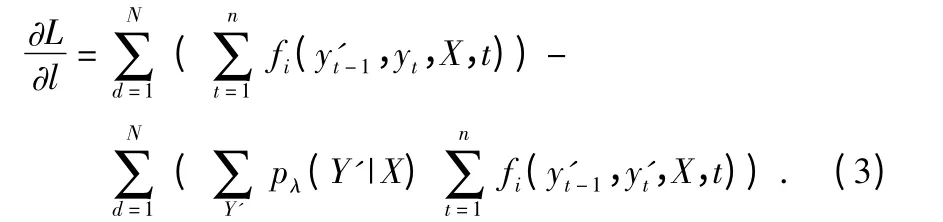
3 实验分析
由于目前还没有基于Kinect 的标准数据库做基准数据,因此,自制了行为数据库。因为Kinect 视角场的范围限制,该视频是在室内场景录制的,数据库包含5 名实验人员分别录制一个动作。动作被分类为:“stand”,“sit”,“walk”,“jump”,“bend”这几种常见行为。总共录制5 000 张左右的样本图片作为训练样本。训练前,每段视频进行特征数据提取,每10 个连续帧作为一个数据序列,随机抽取3000 张训练;剩下2000 张用于测试 经过多次实验后,用平均识别准确率度量算法性能表1 给出了行为识别模型的识别结果。其中列表示实际行为,行表示推断的结果,表中计算数据表示平均识别率。
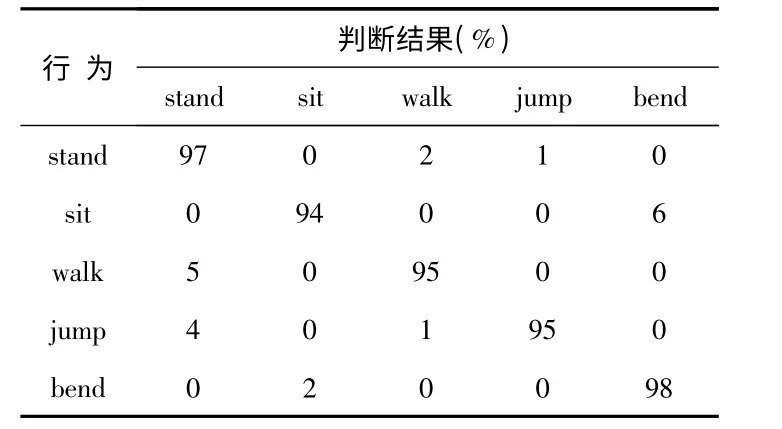
表1 实验结果Tab 1 Experimental result
用本文的方法再对当前流行的行为数据库Weizzman和KTH 分别计算,得到的结果与本实验结果做实验对比,见表2。由表2 看出:使用Kinect 录制的数据库与其他数据库相比是可靠的,实验环境是在室内,但拍摄背景要比其他数据库复杂,所得的平均识别率也相对较高。
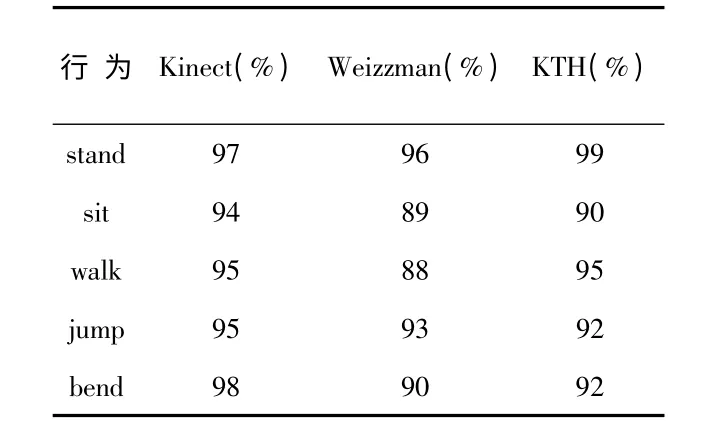
表2 条件随机场模型在不同行为数据库下的识别结果Tab 2 Recognition result of CRF in different behavior database
文献[13]采用HMM 对Kinect 的行为视频数据进行分析,与文献[13]的实验结果做对比,表3 给出了HMM 和CRF 模型下的平均识别率,对比实验结果表明:对序列数据的分类问题,CRF 模型优于HMM。
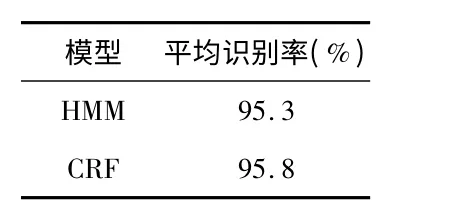
表3 实验结果对比Fig 3 Comparison of experimental result
4 结束语
本文分析了人体行为在时间上的运动序列性质,在深度图像上使用局部方向梯度描述行为特征,建立了人体行为识别的条件随机场模型,在自制Kinect 视频数据库上对几个简单动作识别,与Weizzman 和KTH 视频库相比,自制的数据库背景更加复杂,实验对比结果表明了使用深度图进行特征提取更容易处理复杂背景,也可达到同样的处理效果,从而实现准确的人体行为识别,具有一定的实用价值。
[1] Laptev.On space-time interest points[J].International Journal of Computer Vision,2005,64(2/3):107-123.
[2] Dalal N,Triggs B.Histograms of oriented gradients for human detection[C]∥Proc of the IEEE Conf on CVPR,San Diego:IEEE Press,2005:886-893.
[3] Brand M,Oliver N,Pentland A.Coupled hidden Makov models for complex action recognition[C]∥Proc of the IEEE Conf on CVPR,San Juan:IEEE Press,1997:994-999.
[4] Weinland D,Boyer E,Ronfard R.Action recognition from arbitrary views using 3D exemplars[C]∥Proc of the 11th IEEE Int’l Conf on CV,Rio de Janeiro:IEEE Press,2007:1-7.
[5] Martine F,Orrite C,Herrero E,et al.Recognizing human actions using silhouette-based hmm[C]∥Proc of the 6th IEEE Int’l Conf on AVSS,Genova:IEEE Press,2009:43-48.
[6] Lan T,Wang Y,Yang W,et al.Beyond actions:Discriminative models for contextual group activities[C]∥Proc of Advances in Neural Information Processing Systems Conference,2010:23.
[7] Siminchisescu C,Kanaujia A,Metaxas D.Conditional models for contextual human motion recognition[C]∥Proc of the 10th IEEE Int’l Conf on CV,Beijing:IEEE Press,2005:210-220.
[8] Kumar S,Hebert M.Discriminative random fields:A discriminative framework for contextual interaction in classification[C]∥Proc of the 9th IEEE Int’l Conf on CV,Nice:IEEE Press,2003:1150-1157.
[9] Torralba A,Murphy K,Freeman W.Contextual models for object detection using boosted random fields[C]∥Proc of Advances in Neural Information Processing Systems Conference,2004:17.
[10]Lu X,Chen C,Aggarwal,et al.Human detection using depth information by Kinect[C]∥Proc of the IEEE Conf on CVPR,Colorado:IEEE Press,2011:15-22.
[11]Abhishek K.Skeletal tracking using microsoft Kinect[J].Methodology,2010,4(3):1-11.
[12]Shotton J,Fitzgibbon A,Cook M,et.al.Real-time human pose recognition in parts from single depth images[C]∥Proc of the IEEE Conf on CVPR,Providence:IEEE Press,2011:129-1304.
[13]Zhao C Y,Zhang X L.Human behavior analysis system based on Kinect[J].JBICT,2012,3(12):189-195.
