基于Adaboost 算法的主客观句分类
2015-03-25黄瑾娉
黄瑾娉,陶 杰
(安徽工业大学 计算机科学与技术学院,安徽 马鞍山243002)
0 引言
近年来,文本主客观分类的研究工作逐渐成为热门,研究方向从篇章级、段落级、语句级逐级微观化。判断句子是否为观点句是区分句子主客观的基本方法。但由于汉语以表意为主,不拘泥于语法规范的特性,往往在句子中省略了部分元素。例如“特别敬重你”,在句中省略了主语“我”,是主观句。这使得语句不能使用固定的语法结构来判断其主客观性。另一方面,上例的句子若不省略观点主体且主体词是“他”时,又是客观句。由此看出,主客观的判定需要结合词性、词汇等特性综合判定。
主客观句分类的常见方法有基于词典规则和基于统计的两大类,前者通过构建特定的情感词典等判定句子的主客观性,后者则通过机器学习模型构建主客观分类器。其中后者是应用的主流。以往的研究重心集中于语句的特征选择,训练阶段则多数选用单一分类器。考虑到分类器在主客观分类中的重要性,其优化相关的研究也越来越得到重视。
该文提出了一种使用Adaboost 算法进行主客观分类的方案,使用词汇、词性特征进行实验,验证方案的可行性。Adaboost 是集成学习算法[1],是一种迭代算法,有利于综合各分类器优势,达到更佳的分类效果。
1 相关知识
1.1 分类流程描述
使用机器学习机进行主客观句分类包括了分类模型建立和分类的实施两个阶段,主要流程如图1 所示。与一般分类问题相似,包括了语料集的获取、文本预处理工作、特征表示、机器学习模型的生成和分类等几个步骤。在主客观分类领域中,特征选择和数据模型的生成有其特殊性,是研究的重点内容。
除了一般分类的预处理过程,主客观分类的文本预处理还包含了人工标注句子主客观性的过程,一部分用于分类模型的训练,另一部分用作测试。特征表示包括特征选择和向量化表示。首先结合语句特点选取适当的词汇、词性特征,然后使之向量化。
1.2 主客观特征表示
特征选择在语句集预处理完成后进行,其目的是通过选择适当的特征,舍去不重要特征,将语句看作是多个特征合成的一个合体。特征选择的优劣将很大程度上影响到最后机器学习的数据模型生成质量。
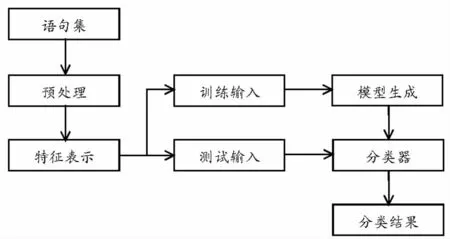
图1 主客观句分类流程
主观句、客观句在语义和语法上都存在着一些隐含的特征。语义层面上主要通过词汇特征体现,语法特征主要通过词性表达。由于词汇、词性特征非常多,这将导致向量化后的维度很高,在主客观分类应用中使用超高维度将使得训练时间很长,同时也可能导致训练结果精确度的降低。课题紧抓语句的词汇、词性特征,通过查阅相关文献[2-3]总结了常见的主客观特征并进行筛选。
词汇特征以Hownet 情感分析词典为准,包括了正负面情感词2090 个、正负面评价词6846 个、主张词38个、程度级别词219 个。另外还加入了人称代词作为特征。由上述可知,直接进行词汇特征向量化导致了向量维度较大,在集成学习中运算量过于庞大的问题,因此结合哈工大同义词词林扩展版,在将语料向量化表示后进行维度的压缩,按照近义词词典的第四级别进行词合并操作,降低一定的维度,最终获得的词汇特征样例如表1 所示。

表1 特征词汇统计
N-POS(多元词性特征)[4]指句子中N 个连续词的词性连续组合,各句子的长度不同可得到的N 值也不同,而现实应用中取N 为较小整数时就可以较好的体现句子特征,例如N=2 或N=3,相反当N 较大时并不一定会提升分类效果反而导致了维度灾难。词性在主客观句分类中是重要的区分特征,例如在2-POS中,“副词+动词”的组合具有主观色彩,而“名词+数词”的组合在客观句中比较常见。
上述方法获取到的特征使用统计CHI(统计)筛选,CHI 统计结果反应了主客观特征在的重要程度。计算方法如公式(1):

结合主客观分类,公式中p 表示一种模式,例如在N-POS 中是一种词性的组合形式;c 表示主客观两个类别,j 取0 或1;N 表示训练集句子总数;A 表示类中p 模式的频度;B 表示中p 模式出现频度;C 表示类中未出现p 模式句子数;D 表示类中未出现p 模式的句子数。
2 Adaboost 及其改进
2.1 算法描述
Adaboost 是一种Boosting[5-6]集成学习算法,用于解决二分类问题。Adaboost 使用迭代思想,意图在于将若干个弱分类器组合成一个强分类器,使得分类效果得到提升。Adaboost 算法在1995 年由Freund 和Schapire 提出。随后,该算法在机器学习领域得到了广泛应用,应用效果得到了认可。
Adaboost 算法的核心思想是对于给定大小为n 的训练集合,其中,,…,。是训练文本的向量化表示形式,是其对应的类别标记。首先给予每个训练样本以相同权重1/n。然后进入了弱分类迭代学习过程,各个弱分类器产生自身预测函数和函数权重,最后更新样本权重并指导下一轮弱分类器的学习。Adaboost 训练完成后使用各弱分类器的预测函数以投票方式对新文本进行分类。
2.2 权值更新的改进
在分类过程中,分类错误的样本将得到权重的加成。但当遇到某样本在弱分类器迭代训练中不断分类错误时,就可能其导致权重过度扩张,而已分类正确的样本将出现权重过低现象。最终导致整个分类正确率的降低,产生退化现象。在主客观分类中,由于维度较高且训练过程中确实可能遇到某些句子比较中性(主客观特性均衡)的情况,为避免上述的现象,课题采用了改进方法。
以主客观分类为例,为避免样本的权重过度扩张,给持续分类错误的样本以权重的调整,分类错误z 次的样本在权重调整后乘以系数。训练语料中的主客观句数量成一定比例o:s,其中o+s=1。在训练过程中,学习机产生的错误分类将导致主客两类的总权重不再是o:s,甚至严重偏离此比例,将导致继续迭代学习时某一类的权重过大的问题。为此在权重更新过程中对各样本再次进行权重平衡,使之保持o:s 比例。通过以上修改,得到了改进的算法如图2 所示。

图2 Adaboost 改进算法
改进算法中,训练语料D 增加错误次数z 标识并在迭代过程中动态变化,在步骤⑤中对权重更新进行调整;增加了步骤⑥调整了类别间的权重。这样有效的防止了类别间和类别中各自的权重扩张过度现象。
3 实验及结果分析
实验中的样本取自COAE2014-任务4&任务5 的语料库,提取的4000 条评论句并进行人工主客观的标注,使用哈工大LTP 平台进行分词和词性标注等一些预处理工作。词汇特征使用表1 中列举的特征,词性特征选用了前50 维作为训练特征,
使用Weka 作为试验环境,弱分类器使用SVM、Native Bayes、C4.5 三种。随机抽取3000 条作为训练语料,1000 条作为测试语句。训练并测试Adaboost 算法在主客观分类中的有效性。
实验结果使用计算精确率(P)、召回率(R)、平均值(F)最为评价标准。其中,语料初始分布情况如表2 所示:

表2 样本初始分布情况
通过训练,将SVM 训练算法作为基线与Adaboost 算法的测试结果进行了对比,表3 中展示了Adaboost算法及其改进算法的训练精确率P 的结果,改进算法中使用a=1.5。

表3 Adaboost 结果对比
表3 的实验结果反映了Adaboost 在迭代15 次时达到顶峰,改进后的算法在迭代初期就有较好性能,达到顶峰后也比经典算法稳定性强。表4 是将SVM 作为基线与Adaboost 进行对比,结果表明Adaboost 作为主客观分类的强分类器是有效的。使用了Adaboost 训练算法后,分类结果分别在P 值、R 值、F 值上均有提高。

表4 Adaboost 与SVM 结果对比
4 结语
该课题探索了Adaboost 集成学习算法在主客观文本分类中的应用。在运用Adaboost 方法时考虑到了权重过度扩张对分类性能的影响并作出了相应的优化。最后通过实验,表明运用Adaboost 方法能够有效地提高主客观分类效果。中文语法、语义是相当复杂的,目前的研究成果中短文本主客观分类成功率不高,还有许多努力方向,选择性集成和半监督集成学习在主客观分类中的效率也是值得研究的方向。
[1] 李凯,崔丽娟.集成学习算法的差异性及性能比较[J].计算机工程,2008(6):35-37.
[2] 李光敏,许新山,张磊.微博中产品意见挖掘研究[J].情报杂志,2014(4):135-138.
[3] 姚旭,王晓丹,张玉玺,等.特征选择方法综述[J].控制与决策,2012(2):161-166,192.
[4] 张博,周延泉,毛昱,等.对中文主客观分类特征选择的研究[C]//中国人工智能学会第十三届学术年会论文集,2009:601-608.
[5] 曹莹,苗启广,刘家辰,等.AdaBoost 算法研究进展与展望[J].自动化学报,2013(6):745-758.
[6] 雷蕾,王晓丹.基于损失函数的AdaBoost 改进算法[J].计算机应用,2012(10):2916-2919.
