一种改进的图像场景识别算法*
2015-03-20申龙斌魏志强
申龙斌,李 臻,魏志强**,刘 昊
(1.中国海洋大学信息科学与工程学院,山东 青岛 266100;2.中国石化胜利油田分公司物探研究院,山东 东营 257022)
一种改进的图像场景识别算法*
申龙斌1,2,李 臻1,魏志强1**,刘 昊1
(1.中国海洋大学信息科学与工程学院,山东 青岛 266100;2.中国石化胜利油田分公司物探研究院,山东 东营 257022)
基于图像的场景识别是目前计算机视觉研究的热点之一,然而此前的场景识别算法存在分类结果准确率不高的问题。针对图像场景识别首先提出一种改进的高斯差分采样特征,在对图像进行高斯差分滤波的基础上,根据预先设定的模板进行采样并作为图像的基本特征,之后通过词袋模型和空间金字塔算法生成图像的特征直方图。其次,提出了一种基于K近邻修正的模糊支持向量机图像场景分类算法,算法对现有的支持向量机算法进行改进,引入K近邻算法对结果进行修正,实验结果证明提出的特征的分类准确率较高,而且改进分类算法的结果也优于现有的算法。
高斯差分;支持向量机;场景识别;K近邻算法
基于内容的图像场景识别算法近年来受到了广泛的关注,随着图像捕捉设备的日益普及,基于图像的场景识别方法的应用范围也在逐步扩大,包括医疗,监控,智能交通,视频结构化等方面具有广泛的应用价值。很多研究机构都对场景识别算法,尤其是其中的特征提取方法进行了专门的研究,并提出了多种特征。
基于RGB通道的彩色直方图是最基本的图像特征之一,基于色度的直方图[1],适应光线变化的可变性RGB直方图[2]都为场景检测提供了有效的特征。CEDD[3]特征合并了颜色和边缘信息用于静态图像的检索。SIFT[4]是目前最著名的图像特征并被广泛应用在了场景识别,对应点匹配等领域。针对SIFT算法也衍生出了许多相关的特征提取算法例如HSV-SIFT[5],HueSIFT[1],C-SIFT[6]等。LAPTEV等人[7]提出了一种联合HOG和HOF特征的针对动态图像的运动场景识别的算法。然而目前现有的特征也都存在对光照敏感,运算方法较为复杂或者计算量大等问题。
针对图像的场景识别,本文首先提出了一种改进的高斯差分采样(DS)特征进行图像的低层特征的提取。原始的高斯差分采样特征是基于灰度图像的,本文将彩色信息加入到DS特征中,产生新的彩色DS特征,使特征能够适应复杂光照,并且所包含的信息量更大。同时采用词袋模型对所提取的彩色DS特征进行优化,生成在对应词袋上的特征分布直方图,并利用空间金字塔方法对直方图进行分割,以确保局部信息不会丢失。最后提出了基于K近邻(K-Nearest neighbor)算法修正的模糊支持向量机分类方法(KNN-FSVM)对图像场景进行识别。整体算法流程见图1。
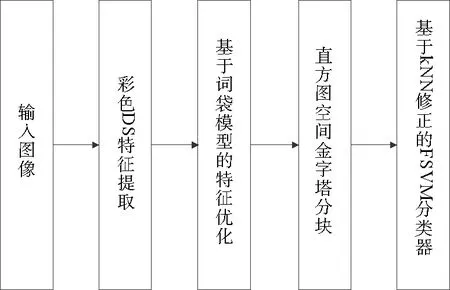
图1 算法流程
1 场景识别特征提取
1.1 高斯差分采样(DoG Sampling)特征
对于场景识别的图像特征,本文采用的高斯差分采样(DS)特征[8]是基于高斯差分进行特征提取的方法。该方法类似于LBP[9]采样算法,首先定义了以采样点为中心,半径为r的圆。对经过了高斯差分滤波之后的图像在圆上采集r×8个点作为最终的特征,r一般取值为1,2或3。同时也可以选择多个模板结合进行采样,因此最终特征的维度为8~48维不等。对图像选择一个适合的模板,然后对图像上的每个点根据模板采点,并将采样到的点整合成一个特征。采样模板如图2所示,上面的3个模板分别表示为采样半径为1,2,3的采样模板,下面3个模板则为复合模板。根据模板对经过高斯差分过滤的图像进行特征提取,则可以得到高斯差分采样(DS)特征。
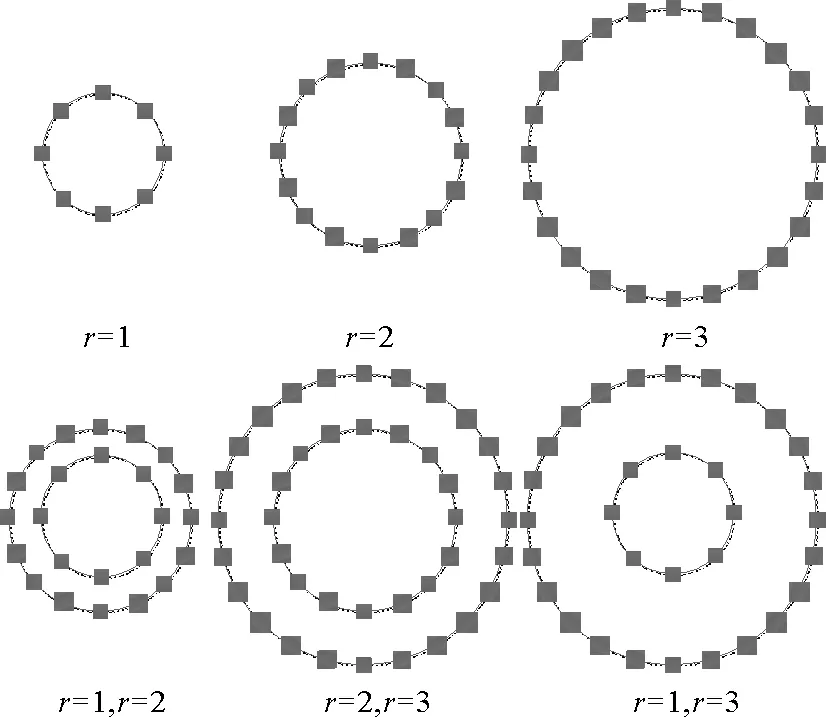
图2 采样模板
1.2 改进的彩色DS特征提取算法
由于原始的DS特征提取算法仅考虑了灰度图像的信息,并没有融合颜色信息,会导致这些信息的缺失。因此本文提出了一种改进的彩色DS的特征提取算法。该特征考虑到了颜色对于场景识别的作用,将原始图像分为RGB 3个通道分别进行DS特征提取,同时为了减少光照对于彩色图像的影响,借鉴了Color SIFT的思想[10]对3个颜色通道进行归一化,归一化计算如式(1)所示:
(1)
其中:μR,μG,μB为图像的RGB 3个通道的均值;σR,σG,σB为对应的3个通道的标准差。对于归一化后的3个通道的颜色值分别进行高斯差分得到R'DoG,G'DoG,B'DoG,模板按照图2所示提取r=1和r=2的复合模板进行采样点的特征提取,由于当r为1时可以采样8个点,r为2是可以采样16个点,因此每个通道的特征为24维。将3个通道的特征拼接起来形成一个新的彩色DS特征,对于原始图像上每一个点共有72维的彩色DS特征。
1.3 特征直方图生成
对于一幅像素大小为480×640图像,每一个点提取72维的特征并将所有点的特征连接起来会导致最终的特征维数十分巨大,对于分类算法的速度会有很大的影响。因此本文采用词袋模型[11](Bag of Words)来简化特征,该模型最初被应用在信息检索领域,它忽略了一个文档的单词语序,语法等条件,仅仅计算每个单词出现的次数,并且每个单词的出现不依赖于其他单词。对于图像而言,一幅图像可以被看作含有多个单词的一份文档,通过词袋模型可以计算出每一个单词出现的次数,将他们连接起来形成一个新的图像的特征向量。
由于图像中并不存在现成词典,而且不同的特征所构建的词典也是不同的,因此词袋模型的关键问题就是如何生成词典,一般采用K-均值(K-mean)算法[12],首先设定词典的大小,之后对低层特征进行k类的聚类,聚类后每一簇的中心作为一个词典中的一个单词。
由于直接通过词袋模型产生的直方图仅仅考虑了全局信息,而忽略了图像内部布局的信息,会导致识别率的下降。因此本文采用了空间金字塔(Spatial pyramid)[13]的方法对图像特征直方图进行多解析度的分割,从而加入局部信息,以保证场景识别算法的鲁棒性。
空间金字塔算法的核心在于计算不同网格尺度下的特征分布直方图,并将不同网格尺度下获得到的直方图按照一定权重相加从而得到最终的合并直方图来进行特征的提取。直方图在不同尺度下的权重不同,网格越细密,则权重值越大。一般尺度取为2(见图3),第0层为全局直方图,第一层将图像分割为2×2的分块,分别提取直方图,第二层则将图像分为4×4的分块。每一层针对所有分块分别提取直方图,再将该层的所有直方图连接起来。
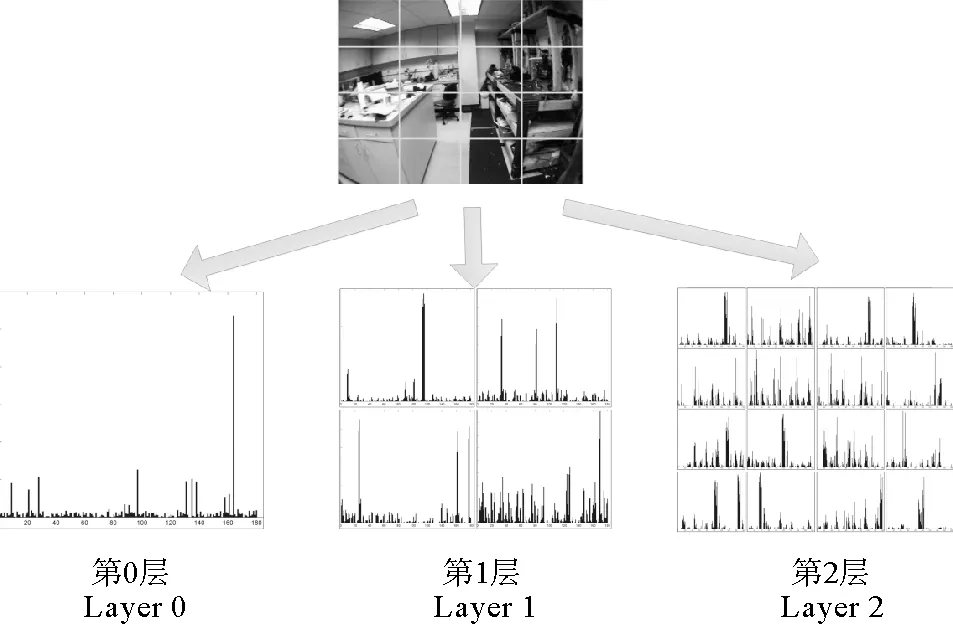
图3 空间金字塔模型
每一层的直方图记为Ln,其中n为层级,则最终图像的金字塔直方图由式(2)得出
(2)
式中:N为金字塔总共的层数,对于图像I,其SP特征记为SP(I)。通过空间金字塔算法可以将全局以及局部的特征信息融合在一起,更具有区分性以及统计性。
2 基于KNN修正的FSVM图像场景分类器
2.1 传统支持向量机(SVM)
在完成特征提取之后,需要采用机器学习的方法对场景进行分类,本文采用支持向量机(SVM)进行分类。支持向量机由统计学习理论发展[14]出来,是一种二类的判别式分类器,它基于结构风险最小化以及统计学理论中的VC维理论,构建出一个可以平衡学习能力与模型复杂度之间关系的分类器。它利用核方法将原本的特征通过非线性变换映射到另一个高维空间。并通过此种映射使得在原始空间中线性不可分的问题在变换后的空间中得到解决,并找到对应的最优的分界超平面。SVM的泛化能力较强,分类速度比较快,并且对训练样本的数量要求不高,能较为有效的解决传统机器学习中的过拟合以及维数灾难等问题,因此在大量的模式识别[15-16]应用中得到广泛的利用。
由于SVM只能被用来进行二类问题的分类,而多类问题的分类需要通过多个分类器进行转化。通常采用以下2种方法构建多个分类器。
(1)一对余方法(One Versus Rest)。对于n类问题,构建n个分类器,每个分类器将第n类与其他的各类区分开,第n类作为正类,其余的数据作为负类。进行判定时,将待识别样本分别输入n个分类器,若只有一个分类器的输出值大于零则将该类作为样本的类别,若有多个分类器的输出值大于零则选取值最大的分类器所对应的类别。
(2)一对一方法(One Versus One) 。与OVR不同,一对一方法需要构建n(n-1)/2个分类器,所有类别两两之间都要训练一个分类器,然后通过投票的方法进行判别。对于一个样本经过所有的分类器判别之后,得到票数最多的类别就被认为是最终类别。
然而这2种方法都有许多不足,OVR方法的每个分类器所需要的样本数量大,训练时间长。而且两类之间的样本数量差别也很大,会导致过拟合问题的发生,同时也会存在某一个样本不属于任何分类的情况。而OVO的缺点在于会出现一个样本同时属于多个类别的情况。
为了解决SVM处理多类分类的情况,本文采用了基于模糊理论的多类SVM分类器(FSVM),并提出了基于K近邻修正的KNN-FSVM分类算法。
2.2 模糊SVM分类器
由于SVM分类过程中出现的噪音点及孤立点会对结果产生影响,Inoue T等人提出了模糊SVM[17]的算法,对每一类引入一个隶属度mi,转而通过计算mi来解决多类SVM分类中遇到的上述问题。
该方法定义了一个与第i类和第j类分界平面垂直的一维隶属度函数为
(3)
其中:N为所有分类类别;Dij(x)为二类分类器的决策函数,则对于第i类其隶属度则为mi(x)。
(4)
对于所有的类别计算得到其对应的隶属度之后,可通过式(5)来计算一个待识别的样本x的归属的类别。
(5)
隶属度函数对不同的采样点会取得不同的惩罚函数,与传统SVM相比更加精确,准确率更高。
2.3 基于K近邻修正的FSVM(KNN-FSVM)多类分类算法
K近邻分类器[18]是模式识别算法中最基本的方法之一,该方法计算待识别样本x与周围最近的K个训练样本的类别情况,在这K个样本中,属于哪一个类的样本的个数最多,则将待识别样本标记为该类别,如公式(6)所示
(6)
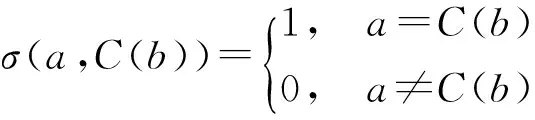
(7)
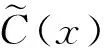
本文将KNN算法应用在OVO的多类FSVM分类算法中,具体流程如图4所示首先将训练数据映射到高维空间,并采用基于OVO的多类FSVM分类器,对每一类获得其对应的隶属度值。同时提取出所有的分类器中的支持向量及其对应的类别作为KNN算法的训练点,在此计算的是样本与支持向量在高维特征空间中的距离,并采用KNN算法判断待识别样本的分类,并通过式(8)将KNN的算法结果与FSVM得到的隶属度进行合并从而得到最终的分类结果。
(8)
其中:a为权重参数,基于OVO的FSVM分类器仅仅考虑了类别两两之间的关系,而没有将所有类别融合到一起进行比较。因此KNN的引入可以看作是对原始结果的修正。同时,由于原始样本数量较大,会导致KNN算法的不准确,通过FSVM仅提取分类的特征向量作为KNN的训练集会大大减小KNN算法的时空复杂度,并提高算法效率。
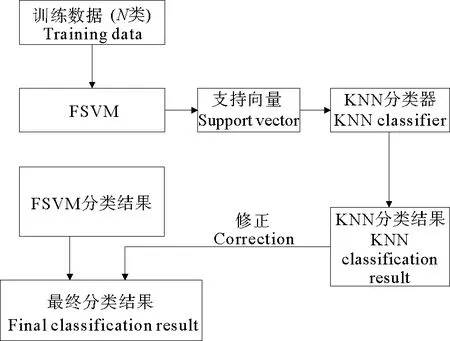
图4 KNN-FSVM算法
3 实验结果
本文使用3000张图片作为实验数据对所提出的算法进行测试,同时与其他图像场景分类算法进行对比实验。
3.1 实验数据
为了实现场景识别,本文选取了10个场景作为实验用的场景,每个场景选取300张图像作为测试集和训练集,所有的数据都是由可穿戴设备进行捕捉。这10个场景见图5,分别为:卧室(BD),办公室(OF),实验室(LB),走廊(CR),会议室(MR),户外(OD),餐厅(DR),商场(MA),车内(IC),厨房(KT),图像由10个被检测者在佩戴可穿戴设备获得。验证方法同样采用10次交叉验证的方法,对于每一类场景的300张图片随机分成10份,每次选取其中的9份作为训练集,另外一份作为测试集进行实验,总计重复10次。

图5 实验数据
3.2 本文算法的实验结果
表1为本文提出的场景识别算法的实验结果,表中每一行表示每一类图像场景的识别结果。算法检测办公室场景的识别率最高,而对于厨房,餐厅,走廊的识别率相对较低。这是由于这些场景下佩戴者的运动幅度较大,并且由于室内光线较暗导致图像清晰度降低,从而影响图像场景的识别率。例如厨房的场景会被会识别为餐厅或者实验室。本算法的整体识别率可以达到89.32%。
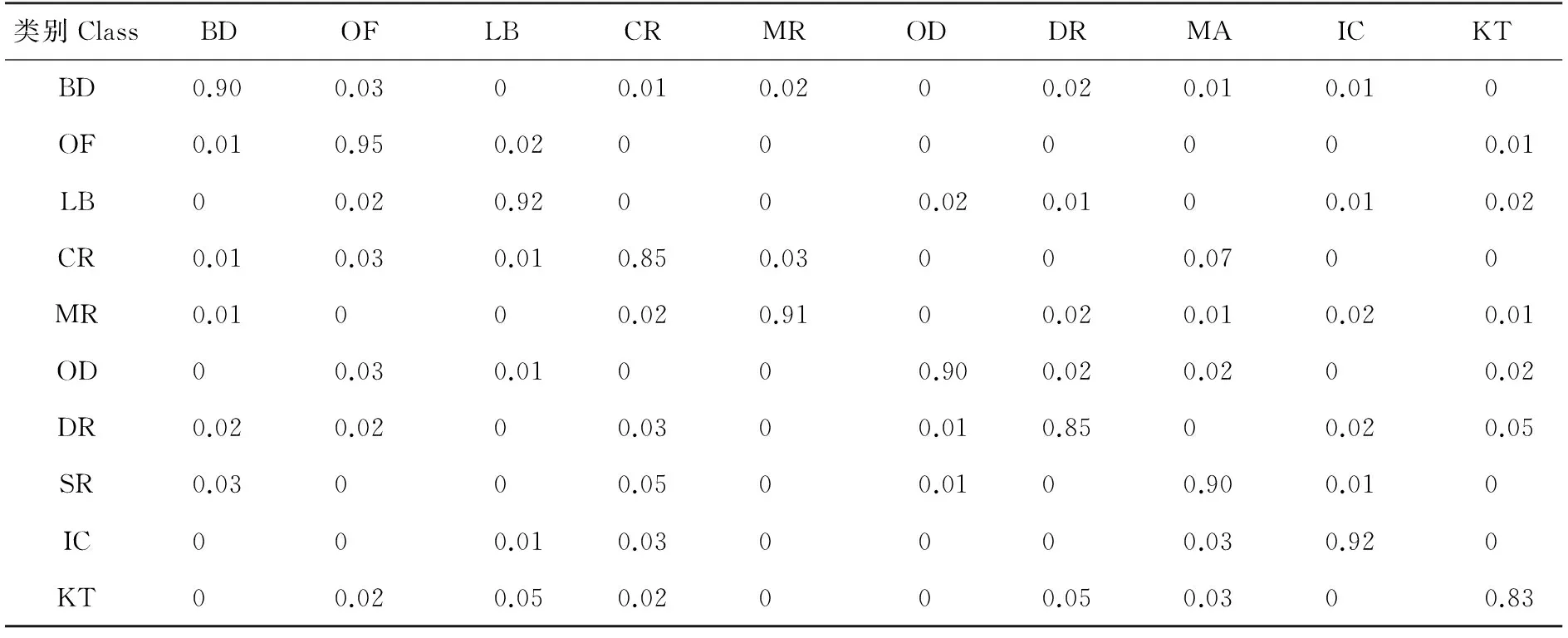
表1 本文算法的实验结果
3.3 与其他图像特征的比较结果
本节比较了彩色DS特征与基于其它图像特征如BoW-SIFT特征,GIST和原始的DS特征的场景识别结果(见表2)。其中彩色DS特征的识别率最高,其次,BoW-SIFT对本文构建的训练数据库的识别率也可以达到87.97%。但是SIFT算法的时间复杂度相比彩色DS特征复杂的多。未提取彩色信息的DS特征也同样能够取得较高的识别率,但是比彩色DS特征低,这说明改进的彩色DS特征所包含的信息更加全面,从而保证识别率更加准确。
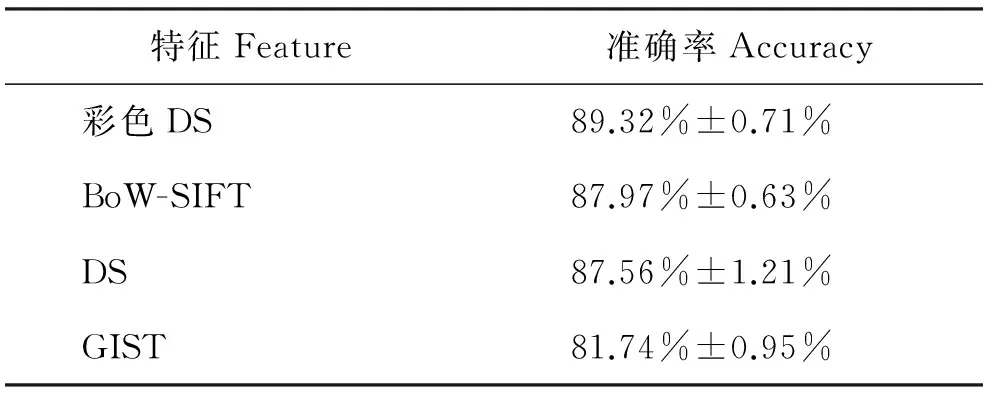
表2 彩色DS特征与其他图像特征的比较结果
3.4 与其他分类方法的比较结果
为了验证本文提出的改进的KNN-FSVM分类器分类算法,本小节对不同的分类方法进行了比较。其中有标准SVM,FSVM,人工神经网络。其结果如图6所示,本文提出的算法的识别率最高,未经过KNN修正的算法识别率次之。因此经过KNN修正后可以提高FSVM算法识别的准确率及鲁棒性。人工神经网络方法在场景识别算法的表现并不理想。
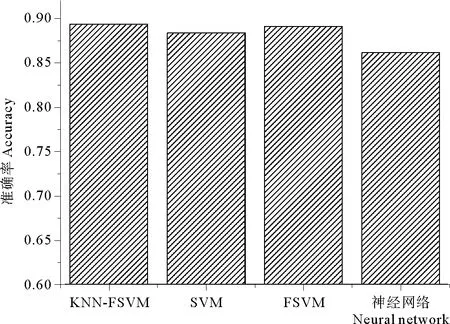
图6 与其他分类方法的比较结果
4 结语
为了提高基于图像的场景识别的准确率,本文提出了一种基于彩色DS的特征提取算法,将彩色图像的3个通道进行DoG滤波之后,对每一个通道的每一个点的周围区域按照一定的顺序进行采样,并生成新的特征。并采用词袋模型对特征进行简化以加快运算速度,同时引入了金字塔直方图以确保最终的图像特征既包含全局信息,又包含局部信息,从而提高提取特征的可区分性和鲁棒性。此外还提出了基于KNN修正的模糊SVM场景分类算法,将原有的模糊SVM分类器与K邻近算法结合,在多类分类的问题上,首先采用FSVM分类器进行基于OVO的多类分类,同时对于所有的在分类过程中获得的支持向量采用K近邻算法进行二次分类,并将该分类结果与之前的结果相融合,从而提高分类算法的准确性。通过实验结果证明基于彩色DS特征及KNN-FSVM分类器的场景识别算法都取得了较高的识别率,彩色DS特征的准确率高于目前常用的BoW-SIFT,Gist等特征,而基于KNN修正的FSVM分类算法所获得的识别率也优于其他识别算法的获得的结果。
[1] WEIJER J Van De, GEVERS T, BAGDANOV A D. Boosting color saliency in image feature detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(1): 150-156.
[2] REDDY S, PARKER A, HYMAN J, et al. Image browsing, processing, and clustering for participatory sensing: lessons from a DietSense prototype [C]// Proceedings of the 4th workshop on Embedded networked sensors. New York: ACM Press, 2007: 13-17.
[3] Chatzichristofis S A, Boutalis Y S. CEDD: Color and Edge Directivity Descriptor: A Compact Descriptor for Image Indexing and Retrieval [C]//Proceedings of the 6th International Conference on Computer Vision Systems. Berlin, Heidelberg: Springer-Verlag, 2008: 312-322.
[4] DUAN L, XU D, TSANG I W-H, et al. Visual event recognition in videos by learning from Web data [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(9): 1667-1680.
[5] BOSCH A, ZISSERMAN A, MUOZ X. Scene classification using a hybrid generative/discriminative approach [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(4): 712-727.
[6] ABDEL-HAKIM A E, FARAG A A. CSIFT: A SIFT descriptor with color invariant characteristics [C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2006, 2: 1978-1983.
[7] LAPTEV I, MARSZALEK M, SCHMID C, et al. Learning realistic human actions from movies [C]//IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, Alaska: IEEE, 2008: 1-8.
[8] CAO Z, YIN Q, TANG X, et al. Face recognition with learning-based descriptor [C]//2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, California: IEEE, 2010: 2707-2714.
[9] OJALA T, PIETIKINEN M, HARWOOD D. A comparative study of texture measures with classification based on featured distributions [J]. Pattern Recognition, 1996, 29(1): 51-59.
[10] VAN DE SANDE K E A, GEVERS T, SNOEK C G M. Evaluating color descriptors for object and scene recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1582-1596.
[11] FEI-FEI L, PERONA P. A bayesian hierarchical model for learning natural scene categories [C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2005, 2: 524-531.
[12] LEUNG T, MALIK J. Representing and recognizing the visual appearance of materials using three-dimensional textons [J]. International Journal of Computer Vision, Springer, 2001, 43(1): 29-44.
[13] LAZEBNIK S, SCHMID C, PONCE J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories [C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2006, 2: 2169-2178.
[14] VN VN. Statistical learning theory[M]. New York: Wiley-Inter Science, 1998.
[15] CUMANI S, LAFACE P. Analysis of large-scale SVM training algorithms for language and speaker recognition [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(5): 1585-1596.
[16] LIU Y-H, CHEN Y-T. Face recognition using total margin-based adaptive fuzzy support vector machines [J]. IEEE Transactions on Neural Networks, 2007, 18(1): 178-192.
[17] INOUE T, ABE S. Fuzzy support vector machines for pattern classification [C]//International Joint Conference on Neural Networks. Washington DC: IEEE, 2001, 2: 1449-1454.
[18] 李蓉,叶世伟,史忠植. SVM_KNN分类器一种提高SVM分类精度的新方法 [J]. 电子学报, 2002(5): 745-748.
责任编辑 陈呈超
Research on Scene Recognition Based onK-Nearest Neighbor and Fuzzy Support Vector Machine
SHEN Long-Bin1, 2, LI Zhen1, WEI Zhi-Qiang1, LIU Hao1
(1 College of Information Science and Engineering, Ocean University of China, Qingdao 266100, China; 2 Geophysical Research Institute, Shengli Oilfield Limited Company, Dongying 257022, China)
Scene recognition is one of the hotspot of computer vision.However, the accuracy of current scene recognition methods is not good.An improved feature based on Difference of Gaussian sampling is proposed for scene recognition in this paper.Through this feature, the image is filtered based on DoG,then features are sampled according to a predefined template, the bag of word and Spatial Pyramid are utilized to generate a feature histogram. Then, an improved KNN-FSVM classifier is proposed for scene recognition. The SVM is improved and the KNN is introduced to correct the results. Through experiments, it is demonstratedthat the proposed features extraction method improve the performance of scene recognition and the results of KNN-FSVM method is more accurate than other methods.
difference of Gaussian; support vector machine; scene recognition;K-nearest neighbor
国家自然科学基金项目(61202208);青岛市科技发展计划项目(11-2-1-16-hy)资助
2013-08-17;
2013-09-16
申龙斌(1971-),男,高级工程师。E-mail:slofslb@qq.com
** 通讯作者: E-mail:weizhiqiang@ouc.edu.cn
TP391
A
1672-5174(2015)04-116-06
10.16441/j.cnki.hdxb.20130327
