基于Hadoop 的图像纹理特征提取
2015-03-18赵进超朱颢东李红婵
赵进超,朱颢东,申 圳,李红婵
(郑州轻工业学院 计算机与通信工程学院,河南 郑州450002)
0 引言
基于人类对纹理视觉感知的心理学研究,Tamura 等[1]提出了一种新的纹理特征表达方法.该方法包含6 个分量,分别与心理学上对纹理特征定义的6 种属性相对应,它们依次是粗糙度(Coarseness)、对比度(Contrast)、方向度(Directionality)、线像度(Linelikeness)、规整度(Regularity)和粗略度(Roughness). 这些特征中最重要的是粗糙度(Coarseness)、对比度(Contrast)、方向度(Directionality).图像分辨率越高,图像细节部分的信息就会得到更好的体现,我们就能得到更好的纹理特征,但是随之而来的是计算量和计算时间的增加.为了缩短纹理特征提取时间,笔者拟将Tamura 算法和Hadoop 相结合,提出一种基于云计算Hadoop 的Tamura 算法,以实现纹理特征快速提取.
1 Hadoop 简介
Hadoop[2]是一个并行计算平台,在与图像相关的领域有广泛应用. 例如朱义明[3]在Hadoop上实现的图像分类系统;张良将等[4]在Hadoop平台下实现的canny 边缘检测、尺寸调整运算;陈广钊[5]以Hadoop 为基础开发出海量图像检索平台;李倩等[6]根据Hadoop 平台对内部数据类型的设计要求,实现了一种功能可扩展的支持图像文件的Hadoop 数据类型;Ranajoy Malakar 等[7]将NVIDIA 开发的CUDA 技术与Hadoop 相结合实现了一个高性能图像处理系统;Liu 等[8]实现了一个基于HBase 和Hadoop 的海量图像管理系统.
1.1 MapReduce
MapReduce[9]是谷歌开发的并行数据处理框架,该框架具备高可靠性和良好的容错能力,基于它编写的Hadoop 程序可以在由数千台计算机构成的大型集群上安全高效的运行,对海量数据进行并行处理.Hadoop 能够实现对多种类型文件的处理,比如文本、图像、视频等.我们可以以特定需求为依据来编写特定的应用程序完成任务目标.下面以Hadoop 自带的WordCount 程序为例来说明MapReduce 执行流程,如图1 所示.
首先,由TextInputFormat 把目标文件分割为逻辑上的split,每个split 会被应用到一个单独的Mapper 上;同时提供RecorderReader 的实现,用来对逻辑分片中的数据进行处理并形成键值对<key,value >,作为Mapper 任务的输入.
其次,Map 接收RecorderReader 形成的<key,value >对,根据程序设定的处理逻辑对数据进行处理,生成新的<key,value >对. 获得map计算所得的<key,value >对后,Mapper 会以key值大小为基础,按照字典排序的方法对上述<key,value >对进行排序,并执行Combine 过程,将key 值相同的value 值累加,从而得到Mapper的最终输出结果Intermediate Files.
最后,Reducer 会先将接收到的Intermediate Files 进行排序,再交由用户自定义的reduce 方法进行处理,得到新的<key,value >对,并作为程序的处理结果,按照程序设计者设定的输出格式,由RecordWriter 写入指定位置.
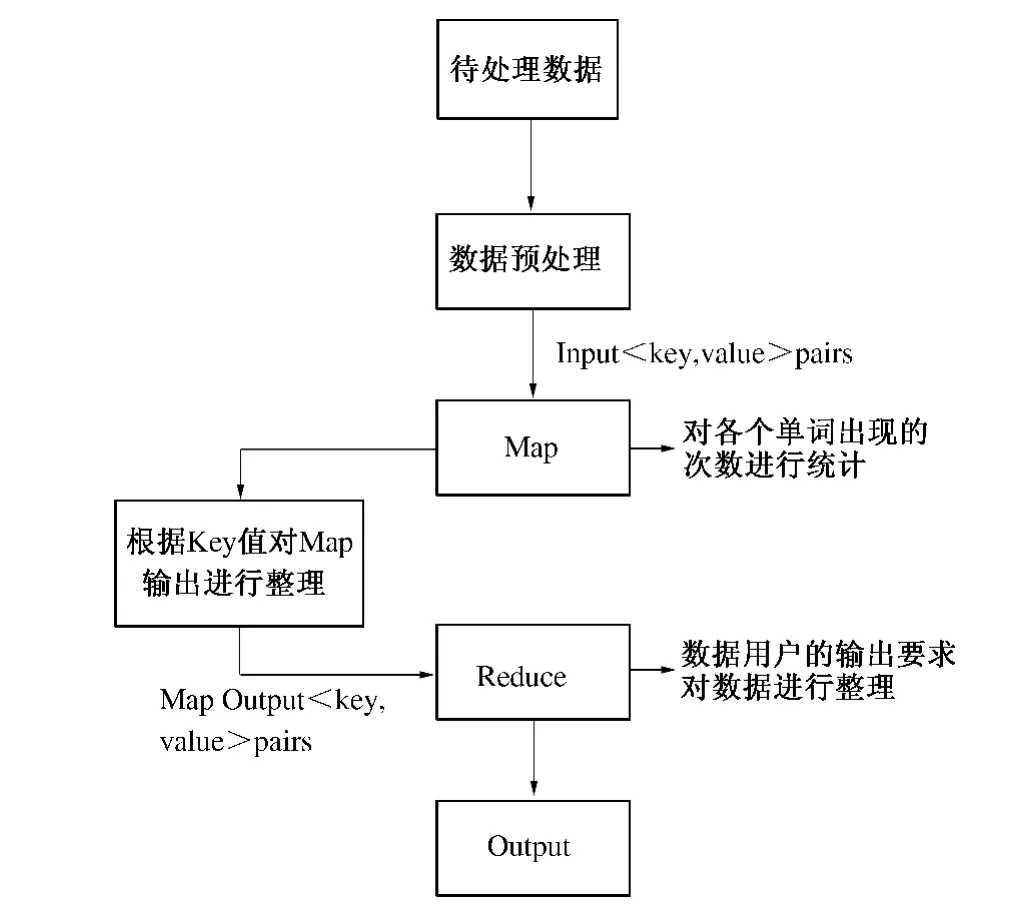
图1 MapReduce 执行流程图Fig.1 MapReduce Execution Process
1.2 HDFS
Hadoop 是一个能够让用户轻松构建和运行的开源并行云计算平台,用户可以在Hadoop 上实现对海量数据的高效处理,其中,Hadoop 分布式文件系统(HDFS)[3]扮演了非常基础的作用,它以文件系统的形式为应用提供海量数据存储服务.HDFS 具备现有的分布式文件系统的很多共同点,例如高可用性、高安全性和负载均衡等,但是它也存在一些新的特点,例如支持超大文件、流式数据访问等. 因此,HDFS 在高并发、高吞吐量的环境下得到了广泛的应用.
HDFS 的架构如图2 所示,整体上是以Master/Slave 架构为主,主要包括包括4 个功能模块:Client,NameNode,Secondary NameNode 和DataNode.
(1)Client:用户与NameNode、DataNode 进行信息交换,实现对HDFS 中文件的存取.
(2)NameNode:HDFS 文件系统的控制核心,负责对系统中文件目录信息、元数据信息等进行管理维护,随时监控各个DataNode 的健康状态.
土墙日光温室主要是指以板打墙和机械碾压土墙为温室墙体的日光温室,我省目前数量为13万栋以上,其中,机械碾压土墙是现存量最大的日光温室类型,占土墙温室90%以上,占全省日光温室数量总量的55%以上,主要分布在湟水谷地的大通、湟中、湟源、互助、乐都、平安、民和等县,其次是黄河谷地贵德、共和、尖扎、同仁县。土墙日光温室(本文主要指机械碾压土墙温室)的好坏直接关系到冬季蔬菜生产状况,维护保养和升级改造土墙日光温室对高效利用该蔬菜生产设施具有重要作用。
(3)Secondary NameNode:定期合并fsimage和edits 日志,并传输给NameNode.
(4)DataNode:每个节点配置一个DataNode,数据以若干个大小固定的block 块的形式在其上存储,在规定时间内与NameNode 进行通信,汇报本节点内的空间利用和数据存储情况.
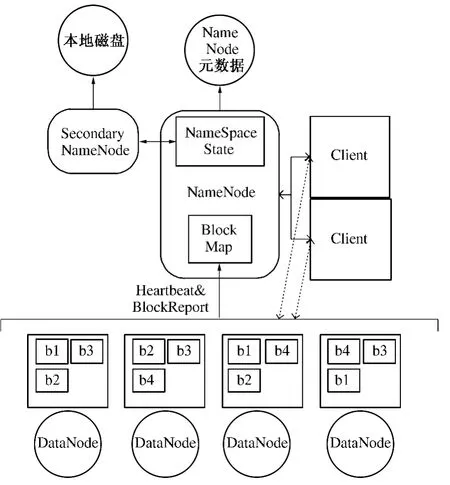
图2 HDFS 架构图Fig.2 HDFS Framework
2 Tamura 纹理特征
2.1 粗糙度
粗糙度[1]是纹理最基本的特征之一,是反映纹理中颗粒度一个量.当窗口大小不同时,具有较大窗口的纹理模式让人觉得更为粗糙. 粗糙度的具体计算步骤如下:
首先,设定窗口大小为2k×2k,用公式(1)计算目标图像中窗口范围内像素的平均灰度值.
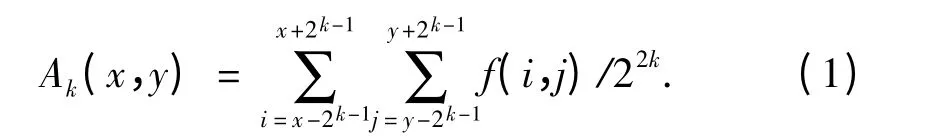
其中,k = 0,1,…,5;f(i,j)是坐标(i,j)处像素的灰度值.
其次,分别计算当前位置像素在水平和垂直方向上互不相交的窗口之间的平均灰度差值,如公式(2)所示.
Ek,h(x,y)=| Ak(x +2k-1,y)- Ak(x -2k-1,y)|;Ek,v(x,y)=| Ak(x,y +2k-1)-Ak(x,y -2k-1)|. (2)
最佳尺寸计算公式为Sbest(i,j)= 2k,若当前k 值可以使差值E 达到最大,即为最佳尺寸.
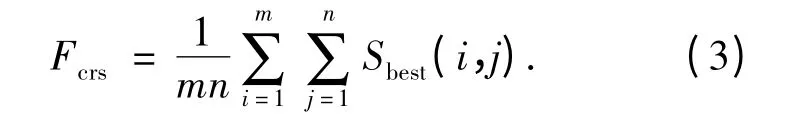
其中m 和n 分别为图像的长和宽.
2.2 对比度
对比度[1]是对目标图像的灰度值分布进行统计得到的.一般情况下,可以通过α4= μ4/σ4来定义.对比度是通过公式(4)衡量的.
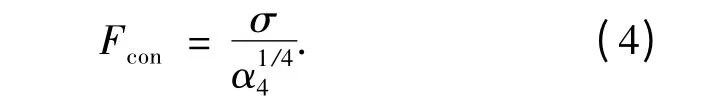
式中:μ4是四次矩;σ2是方差.Fcon给出整个图像或区域内对比度全局度量.
2.3 方向度
由于不同的纹理图像具有不同的方向性,因此Tamura 用方向度[1]来描述纹理在某些方向上发散或者集中.首先,计算当前像素位置的梯度向量.该向量的模和方向定义如公式(5)所示.
| ΔG| = (| ΔH| +| ΔV|)/2;
θ = tan-1(ΔV/ΔH)+ π/2. (5)
其中ΔH和ΔV是使用图3 所示两个3 ×3 算子与图像做卷积得到的.
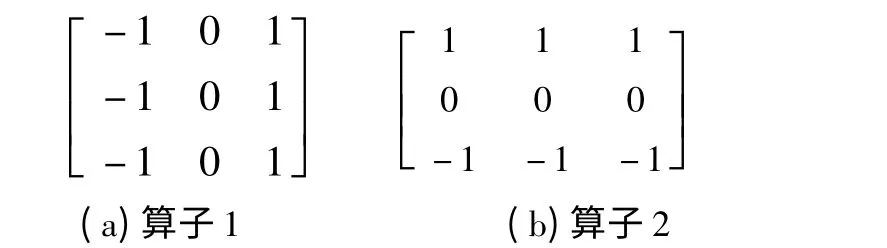
图3 3 ×3 算子示意图Fig.3 3 ×3Schematic diagram of operator
其次,利用公式(6)来获得θ 的直方图.
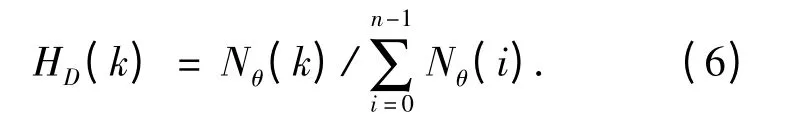
式中:n 为方向角度的量化等级;t 为阈值.Nθ(k)是当| ΔG |≥t,(2k - 1)π/2n ≤θ ≤(2k +1)π/2n 时像素的数量.若当前图像的方向性并不突出,则直方图HD比较平缓,反之会出现较为明显的峰值.
最后,使用公式(7)来计算方向度.
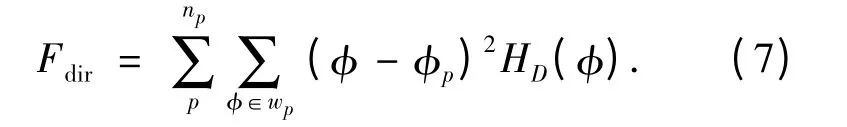
式中:np是对直方图HD中峰值数量的统计值;p为直方图HD中的峰值,对于任意一个峰值p,wp为图像中达到该峰值的所有区域;φp是wp中最大直方图值中的波峰中心位置.
3 图像纹理特征提取实现
笔者把一个图像文件作为一个split,把整个图像集合视为一个作业进行处理,每个Map 任务对应一个图像文件,进而可以同时提取集合内图像的纹理特征.还使用单独一个Reduce 任务将计算结果按照设定格式写入到指定输出位置. 为了实现上述功能,首先,需要实现一个新的数据类型Image,用来存储图像像素信息;其次,与文件输入相关的InputFormat 和RecordReader 也需要重定义,用于图像文件和特定数据类型之间的转化;最后,在Map 处理阶段实现图像纹理特征提取.
3.1 数据类型Image
Hadoop 本身没有定义和图像相关的类作为Key 和Value 的备选类型.Hadoop 规定,用户自定义的类型只有通过实现Writable 接口才能使用.为解决上述问题,笔者自定义了数据类型Image,该数据类型是以Bufferimage 为基础进行扩展,对Hadoop 中Writable 所定义的用于输入输出的基本方法进行了重写.与其他类型相比,该类型在实现读取图像尺寸、图像路径等功能的基础时,又根据实际需要增加了相应的功能模块,例如灰度变换、颜色空间变换等功能. 部分扩展内容如图4所示.
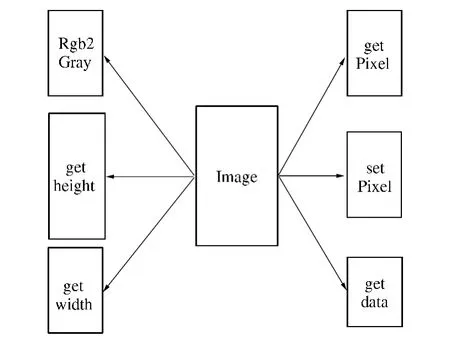
图4 Image 类型内容缩略图Fig.4 Image content thumbnail
3.2 图像文件的输入格式
InputFormat 描述了Hadoop 作业输入的细节规范,而FileInputFormat 则是所有以文件作为其数据来源的InputFormat 实现的基础类型.Hadoop提供的API 实现了下面两个类:
(1)ImageFileInputFormat:继承自ImageFileInputForma 类的实现,将一个图像文件视为一个split,不再对图像进行分割.
(2)ImageRecordReader:继承自RecordReader 类的实现,把输入分片转化为一个<key,value>对.
3.3 图像文理特征中粗糙度计算
Tamura 对粗糙度计算中k 值设定描述为两种情况:①k =0,1,2,3:图像无噪声,在该范围内Sbest恒定Max,计算量小;②k =0,1,…,5:图像存在噪声,Sbest结果表现不稳定,不仅对计算结果造成影响,而且计算量与无噪声情况下相比要大.因此在提取纹理特征前需要对输入图像进行预处理以祛除噪声,保证结果质量的同时还可以减少计算.
4 对比实验及结果分析
本Hadoop 实验平台由5 台计算机组成,操作系统均为CentOS-6.4 64bit,配置均为八核Intel-Corei7 处理器,4GB 内存,1TB 硬盘,Hadoop 版本为1.1.2,Java 版本为1.7.25,每个节点通过100 Mb/s 的局域网连接.
为了验证该算法在不同图像分辨率、不同图像数量和不同节点数目情况下Hadoop 平台的提取效率,笔者选用3 个数据集:Flavia,ICL 和ImageClef,下载网址如表1 所示.从3 个数据集中抽取2 000 张图片,分100 张、200 张、500 张、1 000张、2 000 张5 组,分别使用3 节点和4 节点进行纹理特征提取结果对比.所用时间如图5、图6 所示,算法加速比如图7 和图8 所示.

表1 数据集网址Tab.1 Data set website
图5、图6 说明随着图像数量的增加,Hadoop平台的特征计算时间基本呈倍数级增长. 原因有如下两点:①Flavia 库中图像分辨率均为800 ×600,ImageClef 的为500 ×800 左右,ICL 的为300×400 左右,Tamura 纹理特征中粗糙度的计算量和图像分辨率密切相关,因此计算时间增长较为明显;②计算特征时采用的是Hadoop 的默认调度策略,并未针对并行图像处理的特点对调度策略进行调整.
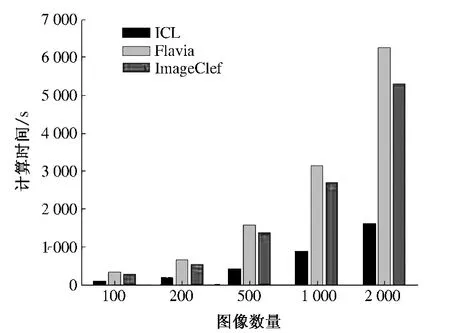
图5 3 节点时Hadoop 平台计算时间Fig.5 Consumed Time of Hadoop Platform with Three Nodes
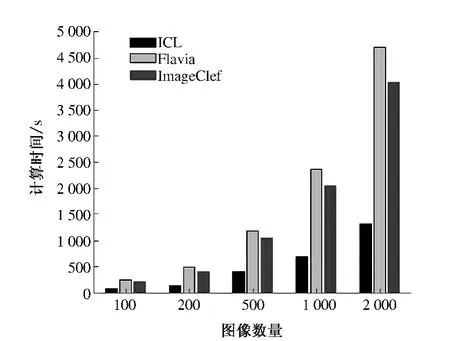
图6 4 节点时Hadoop 平台计算时间Fig.6 Consumed Time of Hadoop Platform with Four Nodes
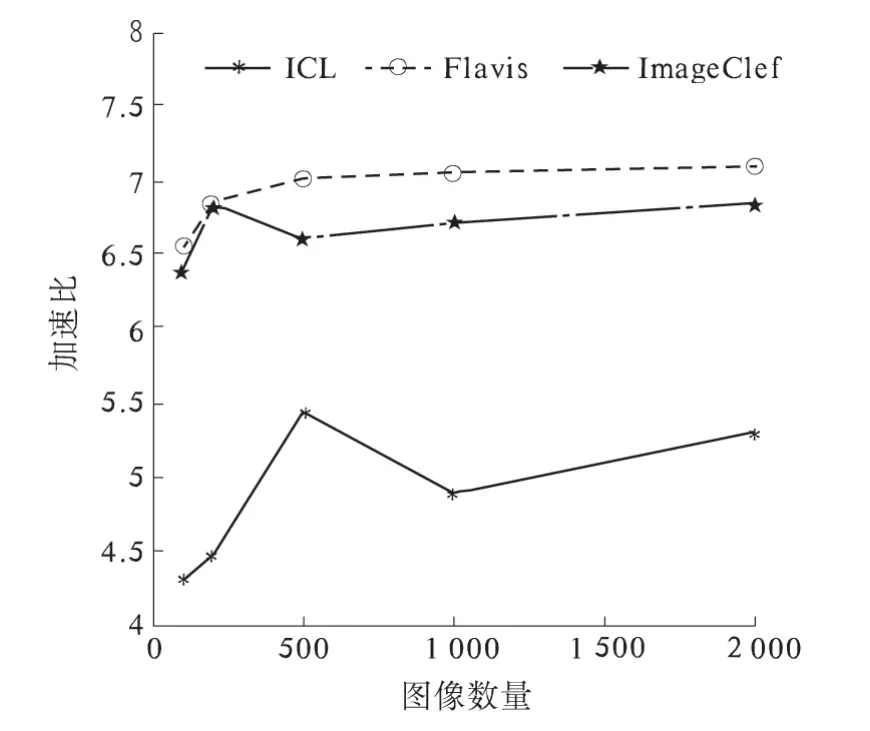
图7 3 节点时加速比Fig.7 Speedup ratio of hadoop platform with three nodes
将图5 和图6 对比,结合图7、图8 可以看出:在图像数量较少和分辨率较低的情况下,不同的节点数量对处理时间的影响并未呈现出明显的差异,加速比则表现出一定的差异;随着图像数量的增加和图像分辨率的提高,不同节点数量的处理时间和加速比的差异尤为明显. 实验表明基于Hadoop 平台的Tamura 算法可以有效地运用于大规模图像数据集的特征提取.
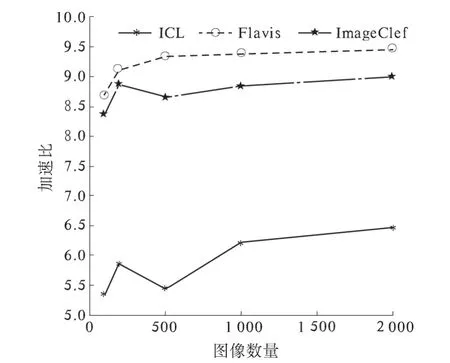
图8 4 节点时加速比Fig.8 Speedup ratio of hadoop platform with four nodes
5 结论
笔者主要基于Hadoop 平台,利用Tamura 算法实现图像纹理特征的快速提取,针对Hadoop 平台无法直接读取图像文件的实际情况,设计实现了一种新的输入格式ImageInputFormat 和数据类型Image 来满足图像输入、数据处理的需要.该方法充分发挥了Hadoop 平台对大数据并行处理的能力,在保证数据精度的同时也缩短了计算时间,对比实验表明了该方法的有效性.然而,在实验过程中,由于Hadoop 的Block 块大小为64 MB,而实验所用图像大小不超过1 MB,浪费了大量的存储空间.同时,受限于Hadoop 平台的调度策略,使得算法的时效性受到影响.如何提高系统在存储大量小尺寸文件时的存储空间利用率,设计出更好的调度策略,是笔者下一步的研究重点.
[1] TAMURA H,MORI S,YAMAWAKI T. Textural features corresponding to visual perception [J]. IEEE Transactions on Systems,Man and Cybernetics,1978,8(6):460 -473.
[2] ARMBRUST M,FOX A,GRIFFITH R,etal. A view of cloud computing[J]. Communications of the ACM,2010,53(4):50 -58.
[3] 朱义明.基于Hadoop 平台的图像分类[J]. 西南科技大学学报,2011,26(2):70 -73.
[4] 张良将,宦飞,王杨德.Hadoop 云平台下的并行化图像处理实现[J]. 信息安全与通信保密,2012,20(10):59 -62.
[5] 陈广钊. 基于MapReduce 的海量图像检索技术研究[D]. 西安:西安电子科技大学计算机学院,2012.
[6] 李倩,施霞萍.基于Hadoop MapReduce 图像处理的数据类型设计[J]. 软件导刊,2012,11(4):182-183.
[7] MALAKAR R,VYDYANATHAN N. A CUDA-enabled hadoop cluster for fast distributed image processing[C]//Proceedings of the 2013 National Conference on Parallel Computing Technologies. Bangalore,India:IEEE,2013:1 -5.
[8] LIU Yue-hu,CHEN Bin,HE Wen-xi,et al. Massive image data management using hBase and mapreduce[C]//Proceedings of the 2013 21st International Conference on Geoinformat ics. Kaifeng,China:IEEE,2013:1 -5.
[9] MARSTON S,LI Zhi,SUBHAJYOTI B,et al. Cloud computing the business perspective[J]. Decision Support Systems,2011,51(1):176 -189.
