智能信息检索应用技术研究
2015-03-11宋文宾钱兴华
宋文宾 钱兴华 刘 鹏
(中国舰船研究院 北京 100192)
智能信息检索应用技术研究
宋文宾 钱兴华 刘 鹏
(中国舰船研究院 北京 100192)
智能信息检索是在传统信息检索技术的基础上发展起来的一种信息检索技术,是人工智能与信息检索等多个领域的结合。论文首先介绍智能信息检索技术和应用,然后以基于本体的智能信息检索系统进行体系结构设计,并描述其关键技术和检索流程。
智能信息检索; 本体; 语义网
Class Number TP393
1 引言
在网络和电子等技术的发展影响下,每天网络中产生大量的数据,图灵奖获得者Jim Gray提出了一个关于网络环境下数据量的定律:网络环境下每18个月产生的数据量等于有史以来数据量之和[1]。如此海量的数据中蕴含着大量有用的信息[2],检索正是实现信息发现的有效方法。信息检索是指将信息按照一定的方式组织存储起来,并根据用户的需求检索出有关信息的过程[3]。信息检索经历了手工检索、计算机检索到网络化、智能化检索等多个发展阶段,检索的内容也从最初的独立的、稳定的、相对封闭的内容变为形式多样、动态、更新快、分布广泛、管理松散的数据信息。随着信息多样化和信息检索能力的要求,基于关键词匹配算法的传统检索检索方法虽然快捷、简单,但检准率低,已无法有效实现检索,不能满足检索要求和结果的个性化呈现[3]。适应网络化、智能化以及个性化的需要是信息检索技术发展的必然趋势[4],由此智能检索技术应运而生。
2 智能信息检索技术及应用
2.1 智能信息检索技术
智能信息检索是在传统信息检索方法的基础上,运用人工智能技术,对所检索的内容分析、理解、推理、决策等,并以良好的形式展现给用户。它除了提供传统的快速检索,相关度排序等功能,还提供用户角色登记、用户兴趣自动识别、内容的语义理解、智能化信息过滤和推送等功能。智能信息检索将信息检索从基于关键词层面提高到基于知识(或概念)层面。理想的智能信息检索系统应具有的主要功能:提供多种样式的检索能力;语义推理能力;基于自然语言或其他语言;信息的及时更新;能力扩充;个性化结果呈现等。
根据信息检索技术的不同,智能信息检索系统的特点和应用领域存在较大差异。其中典型的智能信息检索技术有:基于垂直搜索的信息检索技术、基于语料库的信息检索技术和基于语义网的信息检索技术等。
2.2 基于垂直搜索的信息检索技术及应用
垂直搜索是专业领域检索的典型技术,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务,其具专、精、深的特点,且具有行业色彩。
文献[5]以12580餐饮垂直检索为例,提出针对垂直检索的策略,对垂直检索的查询效率、查准率、信息抽取等方面进行改进。垂直检索相比一般的检索,其检索内容的范围具体,更容易获取需要的信息。例如搜狗购物、360团购等都是典型购物检索引擎。
2.3 基于语料库的信息检索技术及应用
基于语料库的信息检索是以语料库为基础,通过在语料库中对查询信息的语义匹配分析,查找相关语义的信息内容。基于语料库的信息检索技术广泛应用于不同形式的自然语言之间的信息检索,例如中英文平行检索、文言文检索等。
文献[6]提出一种基于语料库的跨语言信息检索方法。通过语料库将一种语言形式的检索语句转变为其他语言形式,实现跨语言的信息检索。
2.4 基于语义网的信息检索技术及应用
基于语义网的信息检索技术是在对信息进行由下而上组织表示的基础上,对信息和信息之间关系的发现和检索。基于语义网的信息检索技术已经广泛应用于数字图书馆、电子商务、电子政务等多个领域。
在数字图书信息检索领域,文献[7]提出基于智能引擎的智能信息检索方法,采用语义网技术体系中的本体方法,在知识层面对数字图书馆中的信息进行表示,从检索意图的分析与判断能力、知识库动态监视和更新反应功能、各种形式的信息广泛整合支持、灵活检索机制、专业层面的强大索引功能等方面改进数据图书馆的检索效率。
在电子商务领域,文献[8]智能信息检索为解决网络时代企业信息膨胀而提出面向电子商务领域,专门设计改进搜索引擎,提出使用基于语义Web的电子商务核心语言,实现在电子商务领域智能信息检索的高效检索和高检准率。基于代理和机器学习的智能信息检索技术在电子商务领域中的应用为系统使用者提供更加个性化的信息推送和检索结果排序,根据对使用者购买记录、关注点、操作习惯等方面的分析,电子商务中的智能信息检索为每个使用者提供了“量身定制”的个性化检索引擎。例如淘宝网,京东商城等电子商务网站都开始将这种个性化的服务提供给用户。
以上三种典型的智能信息检索技术在技术、适用范围、应用情况、各自优缺点等方面的对比如表1所示。基于语义网的信息检索技术实现了知识层面的信息检索,尤其在查全率、个性化、隐含知识发现等方面优势突出,成为智能信息检索技术中的主流技术之一。本文以基于语义网的智能信息检索技术为例,对采用该技术系统的体系架构进行设计、对关键技术进行介绍。

表1 三种检索技术的比较
3 基于语义网的智能检索技术体系架构
基于语义网的智能信息检索技术是数据资源采用语义网技术体系统一描述的基础上,引入自然语言识别,采用自然语言对数据进行检索。它是语义网技术,检索技术,人机交互技术,自然语言识别技术等多种技术的综合,本文构建的体系结构由数据获取、数据语义处理、语言转换和应用共四层组成,为在应用层面保障交互环境的可信,在四层结构中引入安全和可信技术,其体系结构如图1所示。

图1 基于语义网的智能信息检索体系结构
数据获取层主要实现对获取的数据进行处理,为上一层的语义处理提供该领域内数据的来源。根据数据的组织形式,领域中的数据主要分为两类:结构化数据和非结构化数据。结构化数据采用标准的、统一的格式,对数据进行组织。非结构化数据是指结构未经标准化的文档、语音资料、视频资料等。非结构化数据经过识别、提取和转换等手段对其中的有用信息进行抽取,采用结构化形式进行数据描述。其他领域相关数据和抽取后的结构化数据汇集起来成为领域数据。
数据语义处理层的实现是在对领域内数据采用统一编码描述的基础上,运用资源描述框架、本体、逻辑、证明和数字证书等技术,形成领域内本体数据库,在语义层实现对数据和数据关系的检索。索引的建立有利于对领域内整体情况的理解,也有利于对知识进行针对性检索。
语言转换层主要实现非规范检索语言到规范检索语言的映射转换。若输入为自然语言,系统通过自然语言识别,对自然语言进行词法分析、语法分析,并按照规范语法,对自然语言中的元素进行重新组织,形成规范化的查询语句,例如SPARQL查询语句等。
应用层是系统对用户所提供的应用接口。用户既可以是人也可以是其他系统。安全和可信技术在各层中的具体功能不同,在数据获取层,安全和可信技术主要确保获取数据的可信和数据存储的安全等;在数据语义处理层,它主要控制对数据的非法访问;在语言转换层,可信技术要确保转换规则的正确,保证语言转换前后语义的正确;在应用层采用的安全和可信技术更为丰富,从应用的角度确保系统整体数据环境和对外接口等方面的安全和可信。
4 基于语义网的智能信息检索关键技术
4.1 领域本体建立
智能信息检索系统的构建是由智能信息检索所面对的信息、使用者、系统的功能性要求、非功能性要求、系统的软硬件环境、安全环境等共同影响的。这些共同的影响因素共同形成了领域特点,针对不同的领域,需要进行领域信息的表示。由于本体具有对信息组织表示和描述信息之间的内在联系的能力。所以本体论成为知识获取和表示、规划、进程管理、数据库框架集成、自然语言处理和企业模拟等研究领域的核心。基于本体论的知识库的建立将提供一个内容丰富和现代的框架以实现术语的规范、服务和管理[9]。
为实现对数据的语义检索,采用本体技术对结构化数据或从非结构化数据中提取的结构化信息进行描述,描述的基础是领域本体库的建立。领域本体库建立的步骤[10]通常为
1) 明确业务领域。一般从领域的具体业务流程出发,重点关注领域所涉及的业务对象、关系、规则、限制、与其他领域关系等;
2) 属性建立。根据对业务领域的理解,抽象出领域内的实体成为本体,并对其属性进行描述;
3) 明确属性约束;
4) 明确本体关系;
5) 明确函数、限制、规则和公理等。
4.2 实例抽取技术
实例抽取采用自动方式,主要实现非结构化数据向结构化数据转变和结构化数据抽取为实例两个过程。
非结构数据向结构化数据的转换常采用基于特征提取的方法。非结构化数据虽然形式多样,种类很多,但是拥有两个特点是: 1) 存在大量的冗余的信息; 2) 信息通过各种特征表现出来。通过对非结构化数据进行合理的分类,对每类数据进行特征抽取,这些特征来源于特征库中定义的特征类型。通过对提取的特征进行值域分析,进行信息转换和去除无用信息[11]。通过特征提取,将非结构化数据中信息转变为结构化数据,如图2所示。

图2 非结构数据特征提取
格式化数据由于采用固定的格式,所以可以直接通过程序自动抽取为信息的本体描述。
针对结构化数据和非结构化提取后的结构化数据,按照领域本体库中建立的本体框架,对结构数据中的信息进行抽取,形成实例,并存储到数据库中。
例如非结构化数据的输入为“2014年9月1日11:00,卫星拍摄到某舰船的画面(附照片),并通过定位确定其经纬度为120.20-29.51,高度为0”。图片信息中通过图像处理算法获取到该舰船为航空母舰,数量为1。通过该数据信息中文字信息和图片信息的特征提取,获得信息见表2。

表2 某舰船 特征值信息
对获取的特征信息中的部分信息抽取,获得信息实例的描述,用RDF描述如下。
〈目标〉
〈时间〉2014-09-01 11:00.000〈/时间〉
WK〈类型〉水面〈/类型〉
〈型号〉航空母舰〈/型号〉
〈数量〉1〈/数量〉〈高深度〉0〈/高深度〉
〈经度〉120.20〈/经度〉
〈纬度〉29.51〈/纬度〉
〈/目标〉
非结构化数据具有数据量大、信息组织松散等特点,计算机难以直接处理。将非结构化数据的特征进行提取形成结构化数据,使得非结构化数据转化成为计算机可理解的本体实例。实例抽取技术为智能信息检索提供了数据基础。
4.3 语言转换技术
语言转换实现非规范检索语言与语义网检索语言之间的转换。非规范检索语言可以是自然语言、其他系统检索语言等。自然语言的处理方法主要有基于关键词匹配的方法、基于模式匹配的方法、以句法-语义分析为主的方法、基于大规模语料库的自然语言处理等。
本文所介绍的体系结构中,使用以句法-语义分析为主的方法作为自然语言处理技术,借助对查询语句的语义理解,按照语义网检索语言的格式和规则,进行转换。例如要将以汉语形式表述的查询语句“我想查找关于智能检索领域的最新论文”转换为语义网查询语言SPARQL。首先对查询语句采用分词技术(通常采用最大匹配度算法)对查询语句分词,得到的结果是“我、想、查找、关于、智能检索、领域、的、最新、论文”。通过对分词以后的查询语句进行语义分析,分析得出检索的结果为论文,属性中类别为智能检索领域,并且按照时间倒序排列,最终返回结果为下载地址。转化为SPARQL语言如下。
PREFIX foaf:〈http://xmlns.com/foaf/1.0〉
SELECT ?题目 ?摘要 ?时间 ?网址
WHERE {?论文 foaf:class “智能检索”.
?论文 foaf:title ?题目.
?论文 foaf:abstract ?摘要.
?论文 foaf:time ?时间.
?论文 foaf:url ?网址.
}ORDER BY DESC[?时间]
由于自然语言在使用中具有语义上下文相关、模糊、语法不准确等特点,这导致计算机对自然语言理解困难。但强制使用者学习使用语义检索语言(例如SPARQL等)进行检索,会很大程度降低系统的易用性。在具体领域应用中,一方面通过培训和锻炼可以提高使用者的表达能力,另一方面使用自然语言识别技术提高计算机对自然语言的理解能力。
4.4 基于自然语言的智能信息检索流程
本文设计基于语义网的智能信息检索系统的流程,如图3所示。由于自然语言识别技术不能做到100%的准确识别,为防止自然语言理解的歧义,将检索语句转换为SPARQL语句后,再次逆向生成自然语言,并与查询结果一起返回给用户作为参考。
4.5 检索应用技术
智能信息检索系统为上层的应用提供信息的组织、表示和检索功能,为应用提供信息保障。本文体系结构中的应用层为基本应用,为更高层的应用提供基本的接口模块。其中典型的应用为搜索引擎、订阅、信息呈现等。
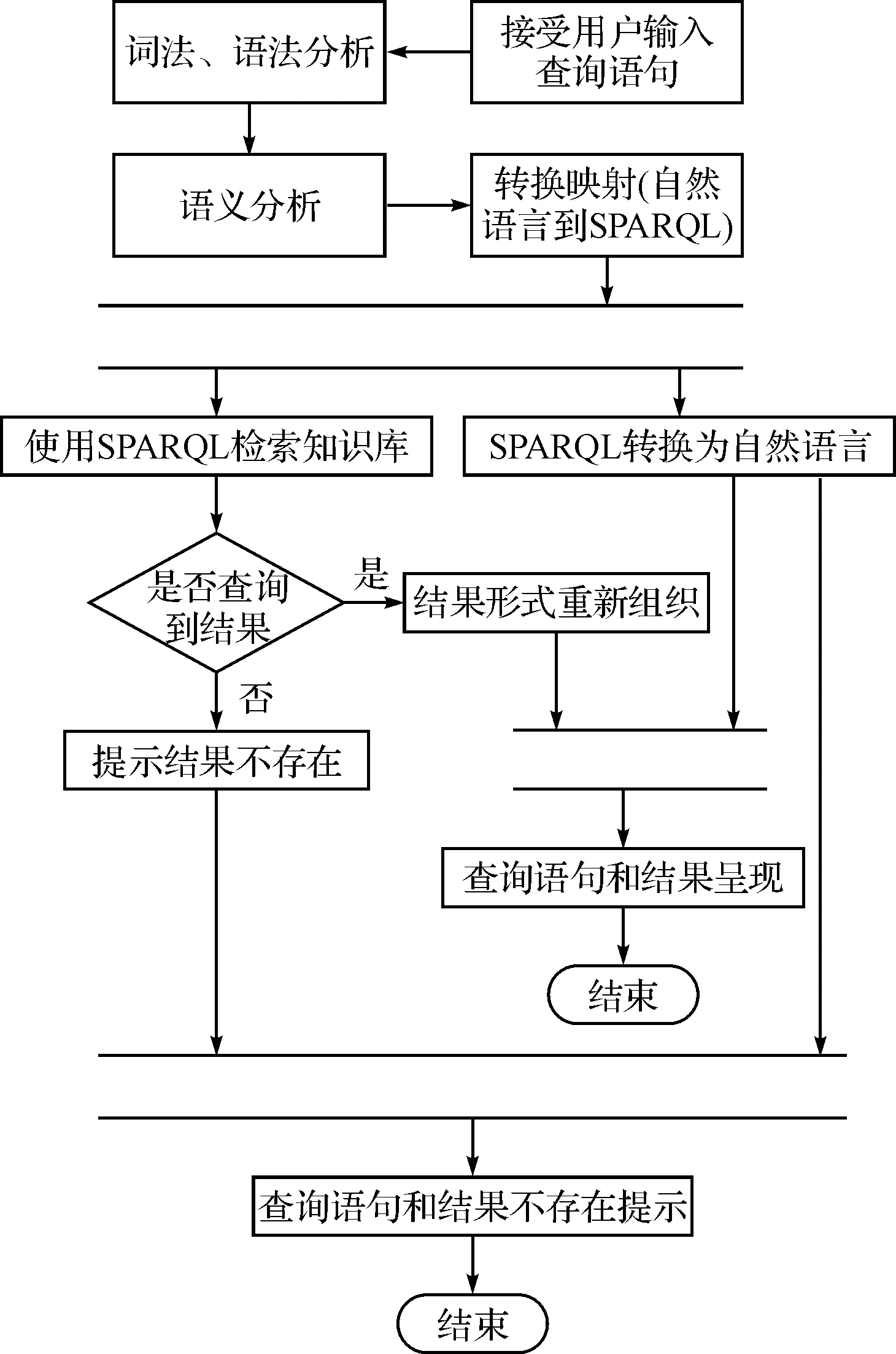
图3 基于自然语言的语义检索流程
搜索引擎是使用自然语言进行信息检索的接口。根据搜索引擎的检索方式和范围可以分为全文检索引擎和目录式搜索引擎。全文检索引擎通过对整个知识库的检索来实现知识发现。目录式搜索引擎是针对专门的领域或主题,采用树状结构建立索引,检索时实际是对已建立好的索引的分层式浏览。两种检索方式都是基于知识库中已形成的信息,相比目录式搜索引擎,全文检索引擎的检索范围广,信息更新快,但是检索效率和准确度低。
订阅主要是针对领域内一些基于订制或者主动推动的业务。互联网中的订阅应用往往基于SOAP协议实现。典型的应用有RSS订阅,信息实时订阅反馈等。基于语义网的智能体系结构为支持模糊订阅和基于用户特性的订阅提供支撑,通过机器学习和智能代理等技术的引入,实现订阅内容的智能化组织、订阅条件自动生成、信息及时更新等。订阅服务为用户查看信息提供了个性化的选择。
根据体系结构的不同,信息呈现主要分为B/S结构和C/S结构。特别是Web 2.0等技术的引入,使得B/S结构的展现形式更丰富多样化,文档、多媒体等多种信息的显示都提供了很好的支持。B/S虽然广泛支持信息的呈现,但对于具体应用的信息呈现缺少针对性,具体业务领域的理解无法深入。C/S结构解决了B/S的这个问题,它面向具体的业务应用,信息呈现的专业化程度更高,更符合用户使用习惯等。
5 结语
基于语义网的智能信息检索技术为解决信息的表示、组织和检索提供了一种解决方案。在未来应用中,智能信息检索技术将结合其他智能技术共同在智能判断、辅助决策、综合分析等多个应用领域发挥重要作用。智能信息检索系统将推动数据中心向知识中心的转变。
[1] 曹强,黄建忠,万继光,等.海量网络存储系统原理与设计[M].武汉:华中科技大学出版社,2014:1-5.
[2] W3C. Linked Open Data[EB/OL]. [2014-6-20]. http://www.w3c.it/events/2014/lod2014/.
[3] 陈沈焰,吴军华.基于本体的智能信息检索系统研究[J].微处理机,2009,5:89-91.
[4] 陈晓金,王兵.信息检索技术研究与实践[J].情报资料工作,2008,3:33-35.
[5] 许鑫,黄仲清.垂直搜索引擎应用中的若干策略探讨——以12580餐饮垂直搜索为例[J].知识组织与知识管理,2009,175(2):62-70.
[6] 张玥杰,连理,吴立德.一种新型的跨语言信息检索技术[J].计算机科学,2002,29(8):66-72.
[7] 贾宏.基于搜索引擎的数字图书馆智能信息检索[J].图书馆学研究,2006,3:28-31.
[8] 谢圣献,谢光.语义检索在电子商务中的应用研究[J].微计算机信息,2008,12:135-136.
[9] 韩娇红.我国智能化信息检索发展及研究现状[J].图书馆学刊,2012,1:49-51.
[10] Grigoris Antonios, Frankvan Harmelen: A Sematic Web Primer(Cooperative Information Systems)[M]. Cambridge: The MIT Press,2008:204-218.
[11] 田万鹏,王建民.一种基于特征的非结构数据演变管理建模框架[J].计算机研究与发展,2010,47(suppl):394-399.
A Study of Intelligent Information Retrieval Technology
SONG Wenbin QIAN Xinghua LIU Peng
(China Ship Research and Development Academy, Beijing 100192)
Intelligent information retrieval is a composite retrieval technology which is an advance stage of information retrieval technology. Firstly, the technology and the application are introduced. Secondly, the architecture of intelligent information retrieval based on ontology is designed. Finally, the key technologies and the flow are given.
intelligent information retrieval, ontology, semantic web
2015年1月4日,
2015年2月28日 作者简介:宋文宾,男,硕士研究生,研究方向:舰船电子工程技术。钱兴华,女,博士生导师,研究方向:系统总体设计。刘鹏,男,高级工程师,研究方向:系统体系结构。
TP393
10.3969/j.issn1672-9730.2015.07.036
