我国各省市经济社会发展水平研究
2015-03-11汤琳
汤琳
【摘要】从改革开放到今天,虽然我国的经济有了快速与稳健的发展,但仍存在着各地区发展的不平衡。有研究表明,从全国来看,东、中、西部三大地带经济发展的差距不但没有缩小,而且还有不断扩大之势。因此,进一步清楚认识我国各个地区的经济社会发展的优势和障碍,采取适宜的措施,保证各地区经济社会快速发展,缩短与中、西、东部地区的差距是我们面临的一个紧迫的课题。本文根据《“十一五”时期经济社会发展的主要指标》为蓝本,建立我国地区经济社会综合评价指标体系,根据SPSS软件对指标数据进行主成份分析,把这些具有错综复杂的指标数据归纳为少数几个公共指标因子,然后运用线性回归法计算我国31个省、市、自治区在各共因子上的综合得分,再对这些公共因子得分和综合得分进行聚类分析,把各地区经济社会发展划分为几种经济社会发展类型,并用判别分析作为检测聚类分析效果的辅助方式。最后,提出了平衡各地区经济社会协调发展的若干对策。
【关键词】社会发展水平 综合评价 因子分析 聚类分析 判别分析
一、我国四大主要地区经济发展的现状
我国西部地区面积占全国国土的71.4%,人口占全国的28%,而地区生产总值仅占17%左右,人均地区生产总值约为全国平均值的59%,不足东部地区平均值的一半。西部地区尽管不乏经济科技较发达的大城市,但从广域上考察,属欠发达地区。东北地区是1950年代我国工业建设的重点,曾经为我国的经济建设做出很大贡献。但因体制与结构双重矛盾的困扰,改革开放后跟不上东部沿海地区的发展步伐,其存在的主要问题是:国有经济比重偏高、市场化程度偏低、企业设备技术老化,经济发展活力不足。中部地区面积占全国的10.7%,人口占全国28%,地区生产总值占全国的20%,人均地区生产总值相当于全国的80%,与东部发达地区发展水平有较大的差距。2004年以来促进中部地区崛起,加快了中部地区的发展步伐。东部地区是国民经济发展的引擎,其优势在于有利的区位条件和改革开放以来形成的制度创新的先发优势,在推进自主创新方面作用明显。
二、因子分析模型
因子分析的基本思想是根据相关性大小把原始变量分组,使得同组内的变量之间的相关性较高,而不同组的变量间相关性较低。每组变量代表一个基本结构,并用一个不可观测的变量表示,这个基本结构就是公共因子。一般因子分析模型:
■
其中εi(i=1,2,...p)是与Fi独立的,且E(εi)=0的与公共因子无关的特殊因子。
因子模型分Q型和R型两种,本文采取的是Q型因子分析。
(一)社会发展水平评价指标的选取数据的选择
在数据的选择上,我选择的是《中国统计年鉴》2009年版,分别考察这31个省、市、自治区在财政收入、人均可支配收入、生产总值、城镇单位就业人数、职工平均工资、固定资产投资、居民消费价格指数、商品价格销售指数、三废利用产品产值、教育经费及出院者平均住院日、城市人口密度这12个指标,以期能够通过居民生活水准、社会保护以及文化教育等方面全面反映该地区的社会发展水平。
(二)因子分析方法
由于年鉴中描述的指标是一系列相关的因素,并且选择的很多变量很多之间存在一定的相关性(如财政收入与生产总值GDP),所以我们不能采用简单的回归方法进行分析。通过因子分析则可以将系列相关因素综合为一个因子,因此,研究中我们首先采用因子分析来对这些指标进行分析。
第一,将所有变量做数据的标准化变换,以消除由于数据量纲不同导致的分析偏差(因子分析中SPSS软件可自动执行数据标准化,因此可不单独操作)。
第二,进行因子分析的适用性检验,以此确定因子我们所选择的变量是否适合进行因子分析,即,我们能否从中寻找阐释我国经济社会发展水平解释力度更高的因子。利用统计软件SPSS for windows 16.0对我们所选择的数据进行运算,从结果可以看出:KMO统计量为0.743>0.7,说明因子分析效果是适中的,再由Bartlett球形检验,可知各变量的各变量独立性假设不成立,故因子分析的适用性可通过。
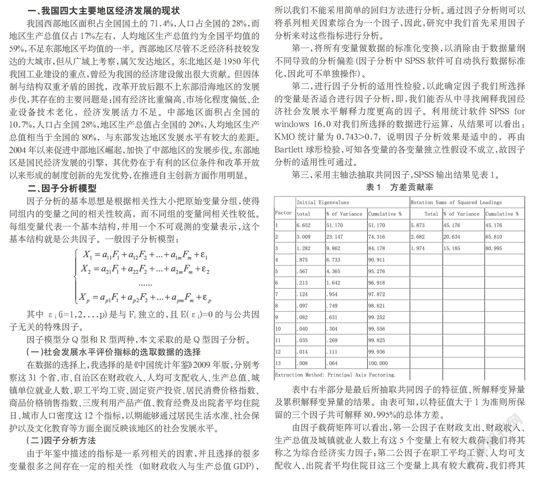
第三,采用主轴法抽取共同因子,SPSS输出结果见表1。
表1 方差贡献率
表中右半部分是最后所抽取共同因子的特征值、所解释变异量及累积解释变异量的结果。由表可知,以特征值大于1为准则所保留的三个因子共可解释80.995%的总体方差。
由因子载荷矩阵可以看出,第一公因子在财政支出、财政收入、生产总值及城镇就业人数上有这5个变量上有较大载荷,我们将其称之为综合经济实力因子;第二公因子在职工平均工资、人均可支配收入、出院者平均住院日这三个变量上具有较大载荷,我们将其称之为生活品质因子;第三公因子在居民消费价格指数和商品零售价格指数上有较大载荷,我们称之为物价水平因子。
通过上述分析,最终确定社会经济发展水平收到三类因子影响,分别为综合经济实力、居民生活品质①以及物价水平。
三、发展水平的细分——聚类分析方法
为了进一步研究我国各省市发展水平的情况,现将上述的三个主要评价因子作为自变量,我国31个省、市、自治区作为因变量,对其发展水平作探索性聚类分析。
由于聚类分析中描述省市的变量(地区)只能使用字符格式,故将这31个省市在数据文件中的标签。
(一)聚类方法
在聚类时,采用了多种聚类方法,发现当采用ward最小变异法时,聚类结果能够很好揭示我国现阶段各省市的经济发展水平。
由于采用的是探索性聚类分析,又考虑到我国四大经济板块,故在聚类时选取4类,则我国31个省市的发展水平可分为:
Ⅰ:北京、天津、上海、西藏
Ⅱ:河北、江苏、浙江、山东、河南、广东
Ⅲ:内蒙古、辽宁、吉林、黑龙江、安徽、福建、江西、湖北、湖南、海南、重庆、四川、云南
IV:山西、广西、贵州、陕西、甘肃、宁夏、青海、新疆
这四类省市按社会发展水平由高到低排序。其中除了第一类中西藏的聚类稍有争议外,其余三类的划分与我国现实经济情况较吻合。
聚类分析小结:
Centroid方法和Ward方法给出的结果比较相似,但Ward方法似乎是最适宜的,因为它得到的样本聚类结果对比度最好。在聚类时发现,采用不同的聚类分析方法,得到的结果会不同,有时甚至差异很大,由此来看,聚类分析存在一定的不稳定性,在使用时要结合实际,选取较为恰当的聚类结果。
(二)聚类分析效度的检验——判别分析
用已分类的分组结果,进行判别分析。选择聚类结果Club_4作为因变量,提取的三大因子作为自变量进行判别分析。
SPSS输出的Box多变量齐性检验结果。由结果可知,BOX M值为40.26,p值为0.057,勉强可以认为满足显著性水平。
SPSS所输出的个别观测值重新分类结果请参见“判别分析.spv”。其中只有1组被错判,因而判对率为96.7%。其中被错判的是西藏,在聚类分析中,西藏被划分到第一组,这显然是与实际情况不符的。
四、平衡各省市社会发展的建议
由上述的分析可以看出,我国各省市的经济社会发展水平很不平衡,这可以归结为区域经济发展的不平衡。有评论指出,我国东、中、西部的不平衡发展是一个长期性的问题,有其客观必然性。问题的关键在于各个区域间形成合理的经济发展圈,即把全局性的发展不平衡转化为区域间经济圈的均衡发展,形成区域间优势互补,再由区域经济的合理分工走向全国经济战略的合理布局。
因此,要提高经济区域市场化、科技化、规模化和外向化的程度,推动经济区域联合开发向高水平、深层次、宽领域、全方位的方向发展。要进一步打破地区之间、部门之间、行业之间仍然存在着的程度不等的分割封闭状态,充分利用国内国外、区内区外两个市场、两种资源,真正实现资源配置优化,优势互补,共同发展,增加区域协调。
注释
①这里的生活品质包含居民的实际购买力以及居民的医疗保障情况。
参考文献
[1]王保进.多变量分析:统计软件与数据分析[M].北京.北京大学出版社.
[2]于秀林,任雪松.多元统计分析[M].北京.中国统计出版社.
[3]《2009中国可持续发展战略报告》.国家统计局.
[4]柯冰,钱省三.聚类分析和因子分析在股票研究中的应用[J].上海理工大学学报,2002,4(24).
