大气颗粒物的源解析技术
2015-03-10张秀张君李鹏
张秀 张君 李鹏
(重庆市环境监测中心 重庆 401147)
1 大气颗粒物及其危害
悬浮在大气中的颗粒物俗称大气颗粒物,大气颗粒物是一个物理形态与化学组成均非常复杂的集合物质名称,是大气中的不定组分之一。按照空气动力学直径不同可将大气颗粒物分为总悬浮颗粒物TSP、降尘(和飘尘。飘尘可分为PM10和PM2.5,由于粒径小,能被人直接吸入呼吸道内造成伤害,近年来倍受社会关注。
大气颗粒物会对人类健康及所生存的环境造成危害。研究表明PM10经过呼吸可以入人体内,而PM2.5还甚至能进入肺泡里,调查显示3到15岁儿童的呼吸道发病率上升与PM10有显著的关系。大气颗粒物可影响气候效应,研究发现PM2.5与能见度的关系很密切,可以降低能见度,大气颗粒物降低能见度主要通过其对光的散射和吸收来减弱光的信号。大气颗粒物对温度也有一定的影响,有研究表明它的危害程度是温室效应的2倍多。大气颗粒物会影响降雨,大气中的这些颗粒物会与水汽结合形成降雨,随之也影响了降雨的酸碱度,这些颗粒物的酸碱度进而成了酸化还是碱化的主导因子。大气颗粒物还会通过各种方式影响农作物的生发育减少产量等,大气颗粒物形成的酸雨会毁坏我们的各种建筑物,这些都直接影响到了社会经济效应。
因此,环境空气质量与我们生活息息相关,空气质量的好坏是影响我们健康生活的一个重要原因。治理大气污染、制定大气污染防治规划的核心问题是确定大气中的污染物以及其来源,只有了解大气污染来源情况才能做好防护治理措施,这是个十分复杂关系。大气污染源解析技术就是区分和识别大气污染物的复杂来源并定量分析其源贡献率的一种科学技术方法,是确定各种排放源与环境空气质量之间响应关系的枢纽,是控制和治理大气污染的一个十分重要而又非常复杂的课题。
2 源解析技术
大气污染来源解析技术的数学模型主要指扩散模型和受体模型。扩散模型(源模型)是一开始的以污染源排放清单的分析和以污染源排放清单为基层的模型。受体模型于20世纪60年代末首先被Blifford和Meeker提出[2]。受体模型之后被广泛应用,是因为其具有使用该模型分析不需要追踪污染物迁移过程,并且不受局部区域的气象、气候及地形等条件的限制等优点。受体模型的主要研究方法包括:显微镜法、物理法和化学法3类。其中化学法发展最成熟,主要有化学质量平衡法(CMB)、二重源解析法、因子分析法(FA)和富集因子法(EF)等。
2.1 CMB 模型
化学质量平衡法是根据多种排放源的颗粒物组成浓度分解为一组由各类源贡献的组合的方法,遵守质量守恒定律利用有效方差最小二乘法解出各类源对颗粒物浓度的贡献。最早于1972年被Miller等提出,一开始命名为化学元素平衡法(CEB),后来由Cooper和Watson在1980年改名为化学质量质量平衡法。目前CMB在PM10、PAHs、VOCs等的来源解析中得到广泛的应用。CMB模型的假设:(1)污染源种类小于或等于化学组分种类;(2)各种排放源类排放的颗粒物化学元素有明显的差别;(3)各种排放源类所排放的颗粒物的化学组分相对稳定,它们之间没有相互影响;(4)各源类颗粒物之间没有相互作用,且在可以忽略其传输过程中的变化;(5)所有成分谱是线性无关的;(6)测量的不确定度是随机的、符合正态分布。那么可以认为化学组分的浓度等于每种源类的化学组分的含量值和源贡献值的线性加和。用公式写成:
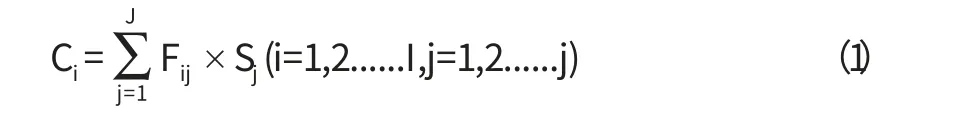
式中:Ci代表颗粒物化学组分i的浓度测量值,ug/m3
Fij代表第j类源的化学组分i的含量测量值,ug/ug
Sj代表第j类源贡献的浓度计算值,ug/m3
I代表化学组分的数目,
J代表源类的种数,
化学质量平衡模型的算法主要有有效方差最小二乘法、普通加权最小二乘法、示踪元素法、线性程序法和岭回归加权最小二乘法等。其中有效方差最小二乘法是最常采用的算法。CBM模型是国内外研究最多、应用最广泛的受体模型,是因为其发展成熟原理简单通俗易懂,解析结果符合实际、且可以分析多种来源体系。苏国鑫[3]详细介绍了CMB模型应用于大气颗粒物PM2.5源解析的原理、过程,以便于分析PM2.5的源。CMB模型的缺点有:(1)用此方法分析过程需要收集详细的污染源成分谱,这就常常需要消耗大量人力和财力;(2)解析过程中如果污染物的化学性质不稳定得出的结果可能会有很大误差;(3)如果污染源的成分相似,得出的成分谱则可能出现共线现象。
2.2FA模型
因子分析法是从研究变量内部之间的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。该方法的基本思想是直接分析受体样品化学成分,根据它们之间的相互关系,综合总结得出公因子,并且计算出每个因子载荷,通过分析各因子载荷情况以及结合现有元素知识来简化数据得出结果,从而推断出污染源类型。FA模型应用于大气颗粒物污染来源解析在国内外都有较多的研究,且得到了较好的结果。
FA模型也是建立在质量守恒基础上。FA模型有3个假设:(1)污染物从排放源到采样点之间的传输途中质量变化可以忽略;(2)污染物中某种元素是由多个互不相关的污染源贡献率的线性组合;(3)由各个污染源贡献的某元素的量差别较大,采样和分析期间的变化较小。
假设每个化学组分是各种源类贡献的代数和,可将源贡献分为两个因子的乘积:分别是污染源对采样点处颗粒物贡献的质量浓度和污染源排放的单位质量颗粒物中所含的该元素的量。公试表示如下:
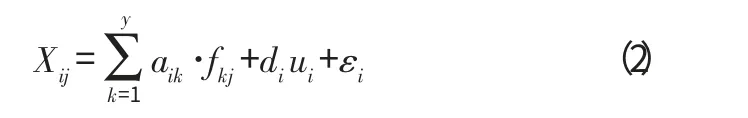
式中:Xij代表的是元素的浓度,单位是ug/m3
αij代表的是因子载荷,单位ug/mg
fkj代表的是公共因子,单位mg/m3
di代表唯一因子系数,单位ug/mg
ui代表的是唯一因子,单位mg/m3
εi代表的是元素i的测量过程或其他产生的误差用矩阵可以表示为:

因子分析法就是从实际数据出发,根据它们之间相互关系,从全部变量中归纳总结出最少数目的公因子,并且计算出各个因子载荷。
2.4 Unmix 模型
Unmix模型是一种解决混合问题的多元线性模型,通常运用于混合物或对多元受体建模时不能识别的情况下。对这些问题假设一些附加条件,得到单一解。Unmix的工作原理就是找到边缘点(指在多维空间里一些数据的贡献源不存在或比其他来源贡献小的点),并且找寻与这些点拟合的一个超平面,把这个超平面称为一个边。每个边限定了对单一源没有贡献的点,即这是一个只有一个贡献源的点,这个点是各个源的混合体。根据这种方法我们可以计算源的最适贡献值。
2.5 EF 模型
富集因子法是用于研究大气颗粒物中元素的富集程度,定量分析污染物某元素状况,判断和评价元素的自然来源和人为来源的一种分析方法,通常有固定的参比元素作为指标,如国际上常用的Fe、Al或Si元素。分析大气污染状况的一种源分析模型。其公式计算如下:
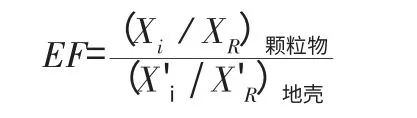
式中;R代表参比元素;
i代表颗粒物中待考察元素;
Xi、XR分别为颗粒物中元素i、R的浓度;
X'i、X'R为i和R的地壳丰富度。
EF值越大,富集程度就越高,说明人为源的贡献越大。根据富集因子的大小可以将元素分为两类:(1)当富集因子小于10时,则认为是自然源,没有富集成分;(2)当富集因子为10~104时,则认为是被富集,来源于人为污染源。于令达[5]等人用此方法对2008年北京采暖前后大气颗粒物的化学成分进行了分析研究,用富集因子进行分析对比,结果表明该法能很好的分析各元素的富集值。
3 展望
我国在大气颗粒物源解析技术上面起步较国外晚,对大气颗粒物的解析也大多停留在单一源解析方面。而环境空气质量问题是关乎我们生存、健康的一个重要关键性所在,如近几年各大城市所出现的与可吸入颗粒物息息相关的雾霾天气,这也是我们现在关注较多的一个问题。近年来我国的源解析技术取得了一定的成绩,但也存在一些问题亟待我们去解决,才能更好的解析大气颗粒物、空气的污染,做好相应的防治治理措施。
[1]王平利,戴春雷,张成江.城市大气中颗粒物的研究现状及健康效应[J].中国环境监测,2005,21(1):83-87.
[2]戴树桂,朱坦,白志鹏.受体模型在大气颗粒物源解析中的应用和进展[J].中国环境科学,1995,15(4):252-257.
[3]苏国鑫.化学质量平衡受体模型在大气细颗粒物PM2.5源解析中的应用[J].环境,2011:97.
[4]冯银厂,白志鹏,朱坦,等.大气颗粒物二重源解析技术原理与应用.环境科学,2002,23(增).
