边缘结构模型*
——一种控制时依性混杂的方法
2015-03-09第二军医大学卫生统计学教研室张天一叶小飞张新佶郭晓晶于菲菲
第二军医大学卫生统计学教研室 张天一 叶小飞 张新佶 郭晓晶 张 筱 李 慧 于菲菲 贺 佳
边缘结构模型*
——一种控制时依性混杂的方法
第二军医大学卫生统计学教研室 张天一 叶小飞 张新佶 郭晓晶 张 筱 李 慧 于菲菲 贺 佳Δ
在观察性研究中,暴露或处理因素常常会随时间的变化而变化,在分析其对结局的效应时,常会受到时依性混杂因素的影响。时依性混杂因素是指同时满足以下三个条件的因素:(1)随时间变化;(2)是结局的影响因素;(3)会影响到随后的暴露/处理,同时又会受到前次暴露/处理的影响[1-2]。可见,时依性混杂因素既可以看作暴露/处理与结局的混杂因素,也可以当成暴露/处理与结局之间的一个中间变量。在估计暴露/处理的效应时,采用传统的多因素回归模型可以校正混杂因素的影响。然而,当把中间变量纳入模型时,则会产生有偏的估计。由于时依性混杂因素同时具有混杂因素和中间变量的性质,因此传统的回归模型不能很好地解决纵向数据中时依性混杂的问题。针对传统方法在处理时依性混杂时面临的困境,Robins在1997年提出了边缘结构模型(marginal structural model,MSM)[3]这一新的方法。
方法概述
边缘结构模型的基本思想是:如果每个个体(i)都接受了暴露/处理的所有水平,则在不同水平上发生某一结局事件的概率分布差异就是暴露/处理的真实效应(不受混杂因素的影响)。而在现实中,这种假设是不存在的,因此需要通过逆概率加权的方法(inverse probability weighting,IPW)将每个观察个体都赋予相应的权重ωi(即将每个个体i都复制ωi个),从而构建出一个虚拟人群。在这个人群中,各暴露水平在不同协变量特征的亚组人群中具有相同的分布,从而消除了混杂因素的影响,同时,暴露/处理与结局之间的关系与原人群是一致的。因此,对这个虚拟人群进行回归模型的拟合,就可以无偏的估计暴露/处理的效应。
应用步骤
我们以一个前瞻性的观察性研究来解释MSM模型及其参数的IPW估计方法。如图1所示:为探索暴露因素对观察结局的效应,该研究对观察对象进行了基线和2次随访调查[4]。其中,A表示暴露因素(A=1,表示接受暴露;A=0,表示未接受暴露);Y代表结局(Y=1,表示阳性结局;Y=0,表示阴性结局);L表示一组向量,它随时间变化,受到之前暴露水平的影响,并且影响下一阶段的暴露水平,同时,L也是结局的影响因素,因此,L是一个时依性变量;此外,除图中显示的时依性混杂因素外,还存在一些不随时间变化的混杂因素(X),所有的混杂因素用Z表示(X,Z分别表示一组向量)。以此为例,对MSM模型的应用步骤进行介绍。
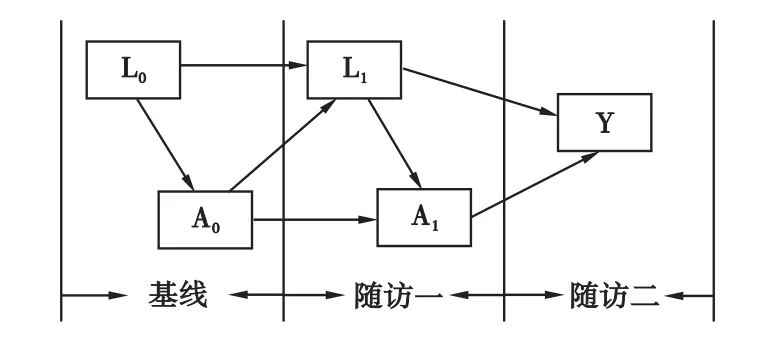
图1 存在时依性混杂因素的病因关系图
1.构建边缘结构(MSM)模型,估计暴露/处理效应
设定暴露因素A与结局Y的关系符合如下线性logistic MSM模型:
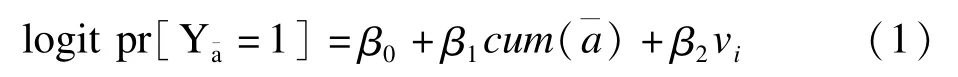
vi代表一组向量,表示基线混杂因素的实际观测值;
β0的意义是所有观察对象从基线到第一次随访都没有接受暴露的情况下,出现阳性结局的概率;
β1可解读为每增加一次暴露,logit pr的改变值。因此,eβ1就表示相应的OR值。
2.逆概率加权(IPW)
构建出边缘结构模型后,可利用逆概率加权的方法实现参数的无偏估计。在进行模型拟合及参数估计之前,需要采用逆概率加权的方法对每个观察对象进行加权处理,通过加权,构建一个虚拟人群,使得在不同协变量特征的亚组人群中,各个暴露水平的分布相同,从而消除了混杂因素的影响。再通过模型(1)对参数进行估计,从而无偏地估计暴露对于结局的效应。
该方法可以通过SAS软件实现,即利用Proc Genmod程序的SCWGT选项(见附录),对每个观察对象(i)赋予一个权重ωi,其表达式如下:

其中,
j表示随访次数,j=0,1;
Aj表示第j次随访时的暴露,aij为实际观测值;
式中分母表示在给定观察对象从基线到第j-1次随访暴露历史以及从基线到第j次随访的混杂因素的条件下,该对象在第j次随访时接受暴露水平是实际观测值的条件概率。
尽管由公式(2)算出的权重可以去除混杂因素和暴露之间的关联,解决了混杂偏倚的问题。但是,由此估计出的权重可能存在极端异常值,进而导致参数的估计值变异较大。因此,Hernan等提出了稳定化权重(stabilized weight)的方法,一定程度上缓解了参数估计的变异程度。具体表达式如下:
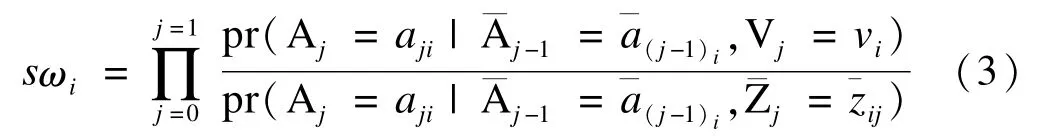
式中,
Vj表示基线混杂,vji为其实际观测值;
该方法又称为IPTW(inverse probability of treatment weighting);
该方法与公式(2)的区别在于分子部分,其分子表示:在给定观察对象基线混杂及从基线到第j-1次随访暴露历史的条件下,该对象在第j次随访时接收暴露水平是实际观测值的条件概率。
显然,与未稳定化权重相比,稳定化权重的取值更接近1,分布更加集中,变异程度更小。因此,稳定化权重可以减少极端权重对参数估计的影响。
但是,由于稳定化权重将给定基线混杂条件概率作为分子,所以并没有去除基线混杂的影响,也就是说基线协变量与暴露方式之间仍存在关联性。因此,还应采用模型(1)对效应进行估计,即将基线混杂因素作为自变量纳入模型中,用以校正基线混杂的影响。
3.权重的计算
公式(3)的分子和分母都可以采用合并logistic回归(pooled logistic regression,PLR)模型[5]进行计算。
与传统logistic回归不同的是,PLR模型将人时作为观测,即考虑到了每个对象每一次随访的结局,而不是仅仅分析随访终点时的结局,具体如下:
分母的计算:
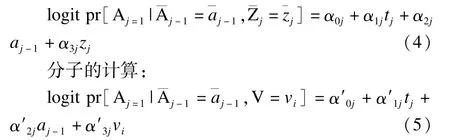
式(4)(5)中,tj表示第j次随访的时间。
MSM模型在其他方面的应用
利用MSM模型可以解决由于失访而导致的数据缺失问题。其基本思想是假设观察对象中没有发生失访事件,则该人群中某一结局事件的频率分布就可真实代表该人群中这一事件的发生率。具体处理的思路与第二部分介绍的方法基本一致,不同之处在于应用IPW计算权重时,除需考虑接受实际暴露水平的条件概率,还要估计失访事件的条件概率。具体如下:
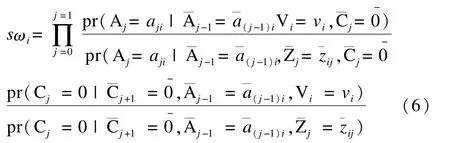
其中,C表示失访情况(C=0,表示未失访;C=1,表示失访)表示从基线到第j次随访的失访情况表示从未失访);该公式第二个分式又称为IPCW(inverse probability of censoring weighting)。
通过对人群进行加权处理,使得暴露水平与随访事件在具有不同协变量特征的亚组人群中,分布相同。再通过模型(1)进行拟合,即可无偏的估计出暴露因素对结局的效应。
此外,MSM模型还可用来解决随机对照实验中的非随机转组问题。
MSM模型的实际应用
Robin等人通过采用MSM模型来估计齐多夫定对于HIV阳性人群生存率的影响,首次实现了MSM模型的实际应用[6]。齐多夫定对于HIV阳性患者生存率的效应受到多个时依性混杂因素的影响,如CD4淋巴细胞水平,它是:(1)一个随时间变化的指标;(2)上一阶段齐多夫定的治疗会直接影响当前CD4细胞水平,而当前的CD4水平又关系到下一阶段是否使用齐多夫定治疗;(3)CD4淋巴细胞水平是HIV患者生存或死亡的影响因素之一。由于时依性混杂因素的特殊性质,采用传统的模型不能很好地校正该类混杂因素的影响,因此该研究应用采用MSM模型对齐多夫定的效应进行估计。该研究表明齐多夫定可以增加HIV阳性患者的死亡风险,RR值为3.6,而应用传统模型进行估计时,其RR值仅为2.3。
MSM模型的优势与局限性
MSM模型可以解决纵向数据中时依性混杂的问题,与同能处理时依性混杂问题的SNM(structural nested model)模型相比(表1),MSM模型与传统模型十分相像(如本文中的介绍logistic MSM模型和实例中的COX—MSM模型),因此,不管是操作,还是对于结果的解释都较为简单和直观。与此同时,当结局变量为二分类时,MSM模型仍能够解决SNM模型通常不能处理的时依性混杂问题。
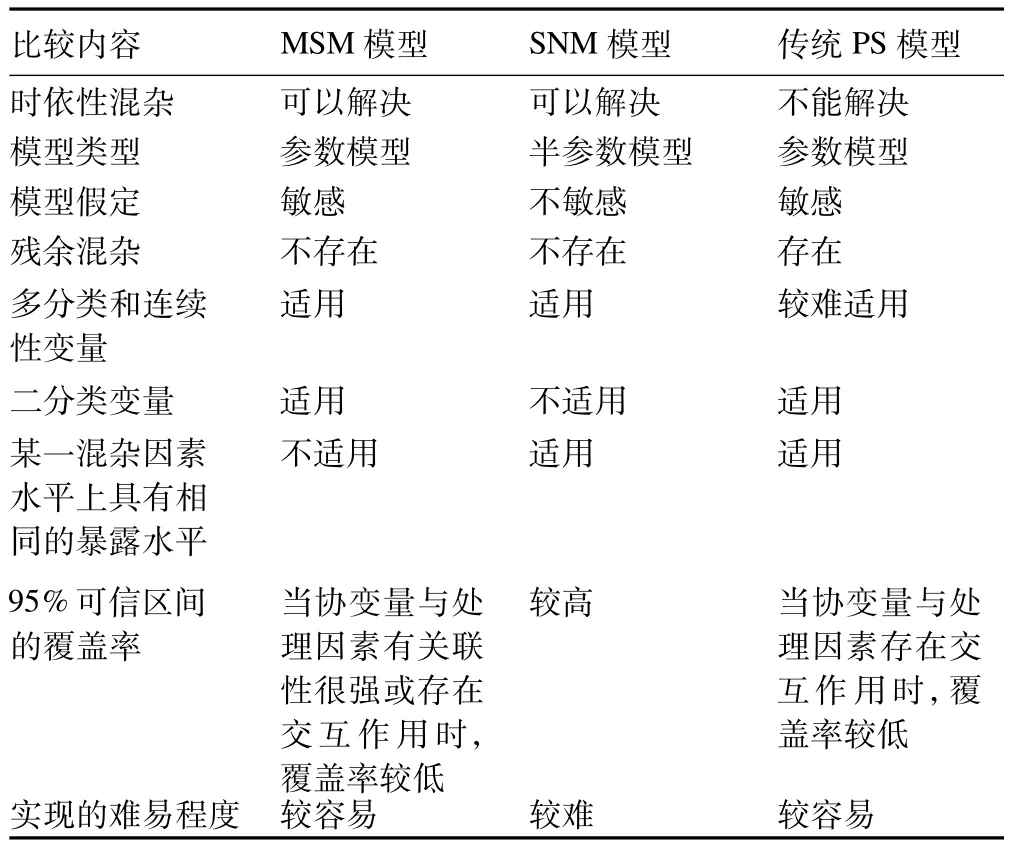
表1 MSM模型、SNM模型、传统PS模型之间的比较
此外,MSM模型也可以用来解决非时依性混杂问题,与传统倾向性评分(propensity score,PS)模型相比(表1),MSM模型可以克服常规倾向性评分中存在的残余混杂问题,并可解决当存在缺失数据和暴露因素不是二分类变量时倾向性评分不易实现的问题[1]。
然而,MSM模型也存在一定的局限性:
1.当在某一混杂因素的水平上,所有的观察对象都接受了相同的暴露水平,即在给定某一混杂因素的条件下,接受当前暴露水平的条件概率为1时,MSM模型就不再适用了[1]。
2.采用MSM模型进行效应估计时,只有正确的设定混杂因素与暴露/处理水平间的模型,才能计算出准确的权重,进而得到暴露/处理效应的无偏估计。因此,MSM模型对于模型的设定较为敏感[7]。
3.当协变量与暴露/处理因素之间存在很强的关联时,稳定化的权重也会存在较大的变异,这将导致95%可信区间较宽,95%可信区间的覆盖率较低。
4.当协变量与暴露/处理因素间存在交互作用时,95%可信区间的覆盖率较低。
展 望
MSM模型通过采用IPW的参数估计方法构建出一个虚拟人群,均衡了各组间混杂因素的分布,排除了混杂因素的影响,进而实现了效应的无偏估计,为流行病学研究中广泛存在的时依性混杂问题提供了一个切实有效的解决方法。自2000年以来,采用MSM模型对效应进行估计的文章呈现逐年增加的趋势[7-8],但是MSM模型的应用范围的还不够广泛,报道的规范性仍有待提高。例如在使用MSM模型进行效应估计的文章中,有关HIV的疗法研究占据了近50%的比例,并且只有60%的研究采用了稳定化的权重方法[8]。因此,今后还需对MSM模型加以重视,扩大MSM模型的应用范围,加强MSM模型报道的规范性。
附录:SAS实现
在应用SAS软件进行分析前,需要将数据集进行整理,即将数据集整理成每行观测为一个人时的形式,以便使用PLR方法进行分析,设定该数据集为data。
此外,在使用PLR模型计算每一随访节点的权重时,需保证各个时间点间的截距相等,即公式(4)、(5)中的α0j、α′0j在各个随访期间应保持不变。这需要应用限制性立方样条的方法进行计算,可参见http://jse.stat.ncsu.edu:70/1s/software/sas
SAS程序的具体代码如下:

国家自然科学基金(No.81072388,No.81202285,No.81373105);上海市循证公共卫生重点学科(12GWZX0602)
△通信作者:贺佳,E-mail:hejia63@yeah.net
