刑事案件的属性约简聚类算法研究
2015-03-02卢睿
卢 睿
(辽宁警察学院公安信息系, 辽宁大连 116036)
刑事案件的属性约简聚类算法研究
卢睿
(辽宁警察学院公安信息系, 辽宁大连116036)
摘要为发现刑事案件的发案规律与特点,从而及时预防和打击犯罪,提出了刑事案件的属性约简K-means聚类算法。该算法应用粗糙集的属性约简算法消除冗余属性,利用各属性的重要度确定其权值,并在此基础上以改进的K-means聚类算法进行聚类分析。最后应用某地区刑事案件相关数据对算法的正确性与有效性进行了验证,实验表明该方法的优势在于降低了数据规模,并获得较高且稳定的准确率。
关键词粗糙集; 属性约简; 属性重要度; 聚类; 刑事案件分析
0引言
公安机关积累了大量犯罪数据,为避免出现“数据丰富,知识贫乏”的现象,如何利用这些犯罪数据是公安机关迫切需要研究的课题。利用数据挖掘方法对公安机关积累的海量犯罪数据进行深入研究, 可以发现刑事案件中相似案件的发展趋势,探寻犯罪的规律与特点,对及时预防与打击犯罪行为具有重要的理论和现实意义。贝叶斯网络、粗糙集方法、决策树和神经网络等数据挖掘方法在零售业、保险业、制造业、电信、医学等领域得到了较好的应用,但在公安情报工作的研究中尚处于起步阶段,尤其是对公安系统刑事案件的侦查决策方面的深入应用还较少见[1-2]。
传统的K-means算法因具有高效快速的聚类效果而被广泛应用。但是传统的K-means算法也存在局限性:只能处理离散的数值型数据,不能很好地处理符号型数据以及连续型数据,对孤立点、噪声数据的处理效率较低,因而限制了K-means算法的应用范围;对于高维数据,K-means算法的正确性较低,所需时间大大增加;同等重要地看待每个属性,因此容易陷入“维数陷阱”[3];K-means算法得到的不是全局最优解,而是局部最优解。
针对K-means算法的以上不足,本文提出属性约简的刑事案件聚类算法,其核心思想是利用粗糙集中的属性约简理论去除冗余属性,并根据每个约简属性的重要度对属性赋予不同的权值,然后利用改进的K-means算法对刑事案件数据进行聚类分析。
1相关理论
粗糙集理论最早是由波兰的Z.Pawlak教授于20世纪80年代初提出,是一种研究不精确和不确定性知识的数学工具,在数据挖掘领域得到了成功应用。属性约简是粗糙集知识发现的核心内容之一,它描述了信息系统属性集中每个属性是否是必要的,以及如何删除不必要的知识。高效的属性约简算法是知识发现的基础,但研究表明求解属性的最小约简是NP-hard问题,因此要在有限的时间内获得约简,通常采用基于启发式知识的约简方法。作为一种信息量判断的手段,属性重要度度量了属性对信息系统的分类能力。基于属性重要度的约简算法以属性重要度作为启发信息,从而找到信息系统的某一个约简,此约简是最优解或次优解。
1.1 粗糙集理论[4]
定义1信息系统可用四元组S=(U,A,V,f)表示,其中:U={x1,x2,…,xn}表示研究对象的集合,即论域;A=C∪D,A是属性的集合,C表示条件属性集,D表示决策属性集;V=∪va,∀a∈A,va表示属性的值域;f=U×A→V是信息函数,对x∈U,a∈A有f(x,a)∈va。
定义2等价关系IND(B)={(x,y)∈U×U:∀b∈B,b(x)=b(y)},其中B⊆A,x,y∈U,称x和y关于B是不可分辨的。
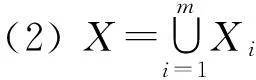
定义4给定一个知识库K=(U,S)和知识库中的一个等价关系族P⊆S,∀R∈P,若IND(P)=IND(p-{R})成立,则称知识R为P中必要的,P中所有必要的知识组成的集合称P的核,记为CORE(P)。可以证明核是所有约简的交集,且核具有唯一性。
定义5给定一个知识库K=(U,S)和知识库中的一个等价关系族P⊆S,对任意的G⊆P,若G满足以下两条:(1)G是独立的;(2)IND(G)=IND(P),则称G是P的一个约简,记为G∈RED(P),其中RED(P)表示P的全体约简的集合。
属性约简是不含多余属性并保证分类正确的最小条件属性集,一般而言,属性的约简是不唯一的。

1.2 K-means聚类算法
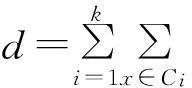
利用K-means聚类算法对刑事案件数据进行分析研究,其主要工作是将详细记录加以整理归类,对刑事案件的内容、情节等进行挖掘, 把具有相似特征的案件从海量数据库分中拣出来,单独形成特征类型数据库,即类案数据库。找出每一类案件中大部分犯罪含有的特征信息,根据不同分类,将犯罪特征应用到该类其它案件的侦破中去,为犯罪案件的串并及破案提供有益帮助[5]。
2刑事案件的属性约简聚类算法
本算法的核心思想是利用粗糙集中的属性约简理论去除冗余属性,并根据每个约简属性的重要度对赋予其不同的权值,再利用改进的K-means算法进行聚类分析,分析描述如下。
(1)在改进的算法中, 首先利用粗糙集对数据对象进行预处理。在公安刑事案件源数据库中,很多记录不完整、不一致,还有一些错误的信息,因此在预处理阶段要清理所有聚类分析的相关属性值。对于空值和不一致数据,可以采取忽略元组、人工填写及填充均值等方法进行处理。在数据大致完整后,将案件属性值根据其类型定义为二值变量、整型变量和区间型变量, 使其转化为K-means算法应用条件中离散的数值型数据,从而有利于算法的实现[6]。
(2)刑事案件数据的某些冗余属性和干扰属性与犯罪倾向的关联性小,保留它们会增加聚类算法的复杂度,结果准确率也较低。本算法中利用粗糙集的属性约简算法删除了冗余属性,降低了运算时间,并赋予各属性不同的权值,使不同的属性发挥不同的作用,使聚类结果更具客观性,更符合公安情报分析的实际需要。

根据以上分析,该算法的主要步骤描述如下:
输入:信息系统S=(U,A,V,f)和簇数k
输出:簇集N={N1,N2,…,Nk}
Step1:设R=∅;
Step2:∀a∈A,如果IND(A{a})≠IND(A),R⟸R∪{a},CORE(A)=R;
Step3:令B=CORE(A),如果IND(B)=IND(A),输出B∈RED(A),转Step5,否则转Step4;
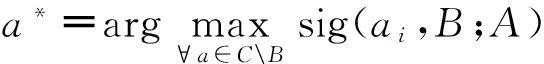
Step5: 取约简后的样本数据集X={x1,x2,…,xm},计算X中每个属性对应的wi,随机选择k个样本作为初始聚类中心;
Step6:数据集X中剩下的其他样本点,根据样本点与初始聚类中心的距离,分别将它们分配给与其最相似的中心所在的类别;
Step7:计算每个新类的聚类中心;
Step8:不断重复Step6和Step7,直到所有样本点的分布不再改变或类中心不再改变,即直到加权距离d(xk,ci)值不再变化为止。
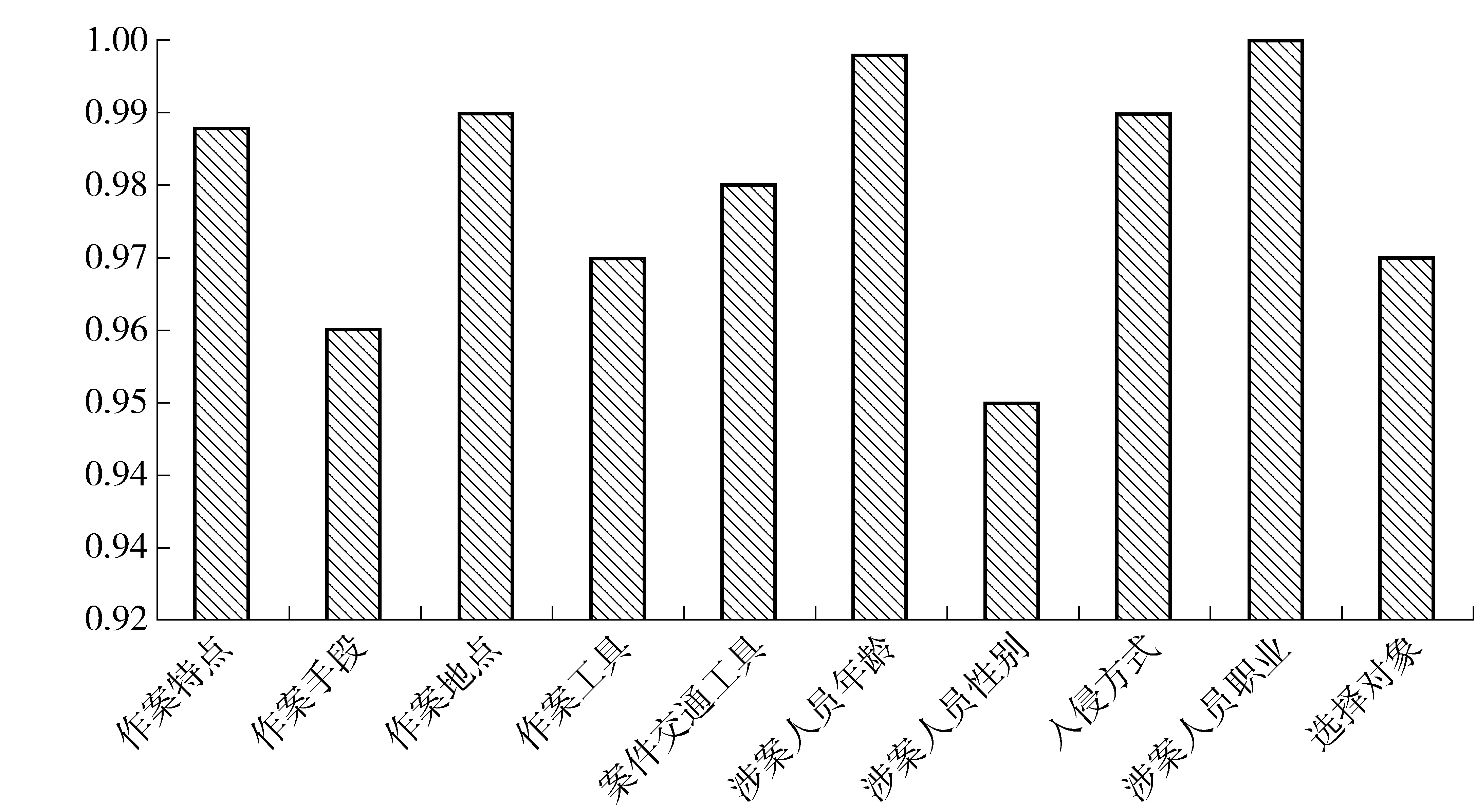
图1 属性约简后重要性百分比
对一个大小为n的数据集, 指定的聚类数为k,d是数据对象的属性个数,则一次迭代的时间耗费由三部分组成: 将每一个数据对象归到离它最近的聚类中心所在的类,需要时间O(ndk);新类产生以后计算新的聚类中心所需的时间O(nd);计算聚类准则函数值所需时间O(nd)。 而迭代次数则由数据集大小、聚类数以及数据分布情况决定,算法总的时间复杂度为O(ndk)。由于在决策分类能力不变的情况下对条件属性进行了适当的约简,因此算法具有较好的时间和空间特性。
3实验分析
从刑事案例库中抽取200例入室抢劫案件的数据,该数据包括10个属性,分别为作案特点、作案手段、作案地点、作案工具、案件交通工具、涉案人员年龄、涉案人员性别、入侵方式、涉案人员职业和选择对象,如表1所示。利用本文算法对10个属性{A1, A2, A3, A4, A5, A6, A7, A8, A9, A10}的重要性程度进行计算与约简,得出{A1, A2, A6, A8, A9, A10}为重要属性。将约简结果中的重要属性值分别除以其最大值处理后如图1所示。
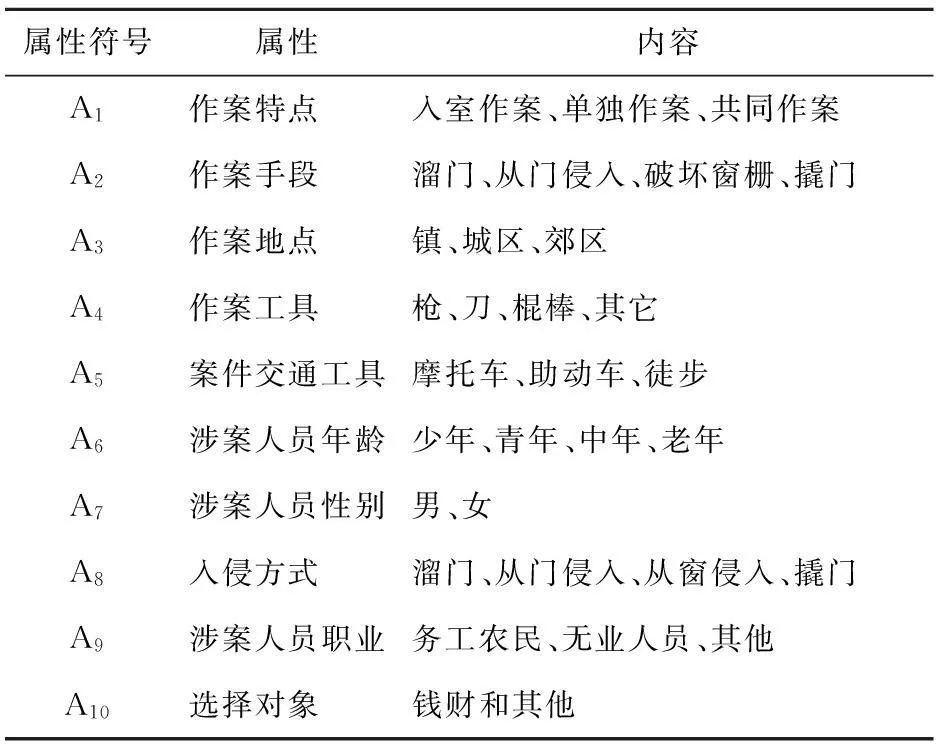
表1 刑事案件属性
所抽取的200例刑事案件数据集中的60%作为训练集,其余40%作为测试集,训练后,训练集中120条数据被分为5类,每类中聚合数量分别为22条、24条、45条、16条和13条。根据训练集所得模型,对测试集中80条数据进行聚类划分,得到前3类所占的比重偏大,如表2所示。

表2 刑事案件聚类结果
表2表明涉案人员职业与犯罪具有一定的相关关系,即在犯罪分子中,无业人员或务工农民发生入室抢劫的概率较大,而这种现象与事实情况相符。
为验证本文算法的性能,采用以上刑事案件数据,将文献[7]的k-means算法与本文算法的结果进行比较,均采用运算10次后所得的平均残差平方和来判断聚类结果的准确程度,所得的平均残差平方和数值越小,说明同一类中的距离越小,聚类的准确程度越高。

表3 刑事案件数据的算法效果比较
由表3可见,本文算法的平均残差平方相比文献[7]的算法具有较大优势,可以得到较高且稳定的准确率,其原因去除属性集中的冗余属性后聚类结果变得更为清晰,而且利用粗糙集对数据进行预处理,精简了数据结构,降低了数据规模,便于聚类算法实现,有利于提高聚类质量。
为了验证算法的准确性和一般性,从国际通用机器学习数据库UCI选取了Iris和Wine两组样本数据,仍然以表3的两类算法进行比较,所求的结果为10次运算后的准确率均值。表4的比较结果说明本文提出的算法有效地提高了聚类性能,并得到了较高的准确率。

表4 通用数据库数据的算法效果比较
4结语
本文把粗糙集中的属性约简和属性重要度思想与K-means聚类算法相结合, 提出了一种有效的改进方法,经实验后证明该算法符合公安犯罪分析的实际情况。在算法应用中,公安机关可从大量不同犯罪特征中找出相似点,并对具有相同特征的案件进行串并,可为公安机关对相似案件的调查侦破提供一定帮助。
参考文献
[1]王春雨,王雪华,张旭娟,等. 刑事案件的多层关联分析模型研究[J]. 情报学报, 2011,30(1):44-50.
[2]卢睿,米佳.互联网公安情报工作标准化流程研究[J].中国人民公安大学学报:自然科学版,2012,18(4):29-32
[3]徐丽,丁世飞,郭锋锋. 基于改进属性约简的粗核聚类算法[J]. 广西师范大学学报,2011,29(3):105-109.
[4]Pang Ping Tan. 数据挖掘导论[M]. 北京:人民邮电出版社,2011.
[5]张扬,陈亮,张番栋. 一种基于聚类的情报分析程序的设计与实现[J]. 情报学报, 2013, 32(8):27-30.
[6]夏颖,王哲,程琳. 聚类分析在犯罪数据分析中的应用[J], 合肥工业大学学报,2009, 32(12):1924-1927.
[7]KRISHNAMUTHY R, KUMAR J S. Survey of data mining techniques on crime data analysis[J]. International Journal of Data Mining Techniques and Applications, 2012, 1(2):117-120.
(责任编辑陈小明)
作者简介卢睿(1978—),女,辽宁大连人,讲师,博士。
基金项目本文为公安部软科学项目(2011LLYJLNST049)和辽宁省高等学校优秀人才支持计划(LJQ2011132)的阶段性研究成果。
中图分类号D918.2
