大规模图数据可达性索引技术研究
2015-02-27赵星
赵星
(陕西财经职业技术学院 陕西 咸阳 712000)
大规模图数据可达性索引技术研究
赵星
(陕西财经职业技术学院 陕西 咸阳 712000)
针对当前SNS社区网络的的不断深入发展,大规模图数据可达索引技术开始被广泛的应用在社交网络中,从而提高对数据索引的精准度。本文针对可达索引技术应用的社交网络中,存在着确定性和不确定性的图数据。针对确定性查询中存在着很大的噪声,引入信息熵的方式,从而提高了图片检索的效率,使得语义表达更为的精确。
SNS;可达索引;不确定性;查询;信息熵
在实践应用中,给定图上的两个不同的顶点,其分别为u和v,通过可达性的查询(u→v),从而解决在图当中,存在着从u再到v的一条路径。因此,可达性查询是有向图上一类当中最为基本的查询,而当图的规模在非常小的时候,通常采用深度优先遍历算法,或者可达性传递闭包算法来处理。但是,随着现代社会信息的不断增加,传统的DFS算法查询效率已经不能满足现代人们的需求,其需要耗费大量的时间和空间。以此,可达性索引技术开始出现。该技术已经出现即被广泛的应用在了计算机的各个不同范围,如SNS社交、路由规划、软件工程等各个方面。通过加速图上的其他的算法,从而提高对图片检索的精准度,提高人们的搜索效率。而子图查询作为可达索引技术应用的一种,如何对其中的数据图进行精准的查询,对此,本文对子图查询在社交网络中的应用进行了深入的探讨。
1 社交网络与子图查询
1.1 社交网络
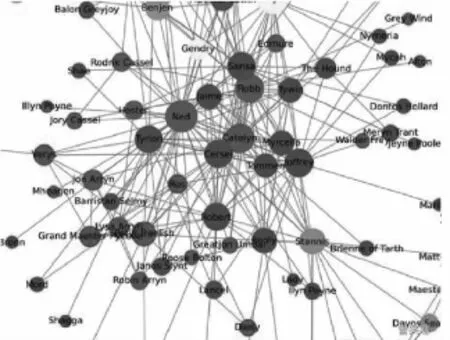
图1 社交网络Fig.1 Social networks
1.2 子图查询
所谓的子图查询就是定义一个图数据库D和一个查询图q,通过查询输出在该数据库当中包含q的所有图片的集合,也就是。而由于查询到的图q其在结构上通常是随机的。因此,针对子图查询处理,其最为重要的步骤则为如何在数据图当中找到同构图。由此,针对子图同构的检测,其本质就是一个NP的问题,对此,为解决这个问题,通常采用验证机制来完成,如通过特征或者是提取特定结构的方式。
2 基于信息熵的确定图子图匹配
2.1 信息熵
熵理论最早是由美国的数学家所提出,通过它来对信息的
不确定度进行测定,并根据信息源来对其不确定进行相关的计算。对此,熵的公式则可表示为:
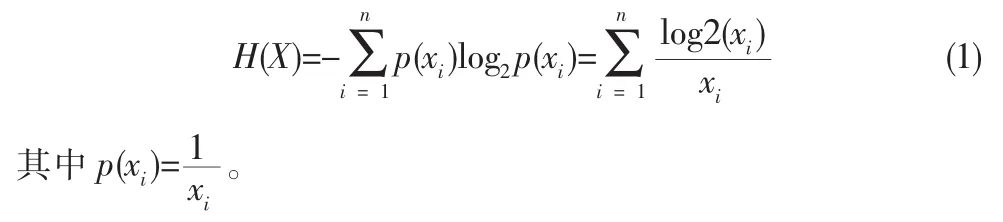
2.2 本文设计思路
传统针对数据的存储标准是以RDF作为标准,通过在语义web、信息网络等当中引入带标签的边表示节点之间的关系,形成结构更为复杂、信息量更为丰富的图数据结构,以此子图查询被广泛的应用在各个领域。而在RDF领域,针对子图匹配的算法和结构进行优化的方法很多,如在匹配算法上面,采用通过一种统计的启发式算法。但是很多的算法其主要都是集中在静态消耗测算方面,并因为需要对邻节点进行统计,而消耗了大量的时间,特别是当前一些图当中存在的大量的幂函数分布的图数据,更是需要耗费大量的时间遍历其邻节点,从而导致其查询的效率非常的低下。因此,结合相关的计算机知识,本文则借助信息熵在对信息进行度量当中的作用,将其中的信息熵作为启发式匹配的依据,提出了基于信息熵的子图匹配算法,将条件信息熵作为启发式匹配的依据,减少邻接点的匹配次数,提高子图查询的效率。其具体的思想为:1)将信息熵引入到当前的图数据的查询当中,并以此建立以信息熵作为基本标准的一个动态测算的模型了;2)通过该动态模型,提出本文的子图匹配算法;3)通过实验的对比,对该算法的有效性进行验。
2.3 信息熵的引入
页岩油又称“人造石油”,与天然石油相比,页岩油中含有较多的不饱和烃及硫、氮、氧等非烃类有机化合物。目前,页岩油只是作为燃料油直接销售,未经二次加工,从资源利用、环境保护和经济效益方面来看都不尽合理。通过分析页岩油及各馏分的性质发现,可对页岩油全馏分直接加氢精制,即在高温高压和催化剂存在的条件下,将页岩油馏分在氢压下除掉其中的硫、氮、氧等非烃类化合物及金属杂质,并将不饱和组分进行加氢饱和,以生产化工产品和清洁燃料。
在数据图当中,任何的事件其都存在着一定的信息量,并且在社交网络当中认为不相邻的节点是相互独立发生的。用x表示节点,而x1,x2,……,xm表示相邻节点当中其符合条件的相关的点。则有:
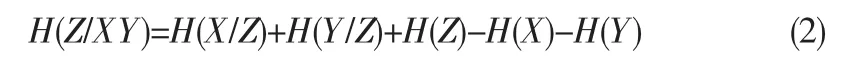
同理,根据公式(2)则有:

在数据图库D当中,任何的一个节点的信息熵:

其中,在数据图库D当中,节点是非常多的,因此,通过节点的数量x→∞,从而可以将公式(3)表示为:

3 算法设计
在对子图的查询中,其主要涉及到4个不同的函数的应用,包括EntropyMatch函数、Entropy函数、selectVertex函数和substituteVertex函数,其整体的算法设计则为:
在本算法设计中,EntropyMatch函数的作用是首先对数据图中的各个查询点的条件熵进行确定,从而在大量的节点中查找到可能匹配的点,用z,R(z)来表示其可能存在的查询的点。

图2 子图查询算法设计Fig.2 Algorithm design subgraph query
Entropy函数则主要是对上述集合z,R(z)中的点进行匹配,并通过调用函数retrieveNeighbors,从而可有效的遍历出相邻节点中符合条件的查询点,而其筛选的条件则是以平均信息熵作为标准,当小于该平均信息熵的时候,则retrieveNeighbors函数的值为空。
selectVertex函数则主要是从信息熵的结合中选出其中的信息熵最大的点m,并调用其中的算法substituteVertex函数。再将符合条件的点全部筛选到集合A当中。
4 算法验证
4.1 社交网络子图查询模型验证
本文以图3作为子图查询的模型,假如其中名叫做Francis尝试去搜索一个喜剧的名字,而该部电影的名字是通过该社交网络中Peter的一个朋友给推荐的。其中?表示为变量,?u表示主人公Francis在Peter的聚会之上所遇到的人。
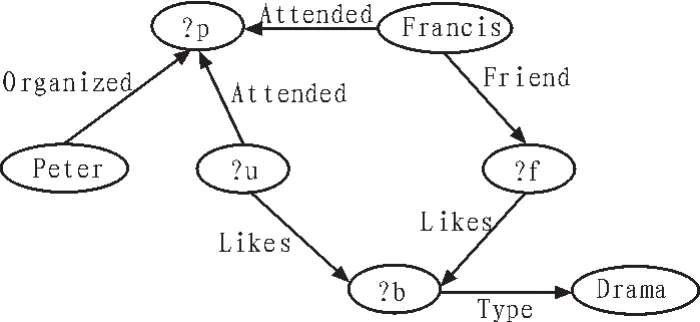
图3 子查询模型Fig.3 Sub query model
要找到该部喜剧,则通过Entropy函数对其中的可能的查询点进行搜索。则有图5的模型。

图4 遍历点FrancisFig.4 Traverse point Francis
由此通过上述对算法的运行,从而得到结果。
4.2 查询效率验证
为验证该算法在查询的速率,采用C语言作为开发语言。同时本文将该算法与传统的SubDue算法进行比较,从而可以得到如图5所示的在不同尺寸的子图查询结果。

图5 不同算法查询时间Fig.5 Different algorithms for query time
5 结束语
针对大规模数据图可达性索引技术在社交网络中的应用,就是一个NP问题,对此,本文结合对信息熵的定义,通过引入信息熵度量的方式,实现了对节点的度量,并通过实验验证其在查询效率方面的提高,由此可以看出该技术在大数据的应用方面具有非常广阔的空间,必将成为未来发展的一种趋势。
[1]富丽贞,孟小峰.大规模图数据可达性索引技术:现状与展望[J].计算机研究与发展,2015(1):116-129.
[2]包佳佳,田伟.大规模图上标签集约束路径的集合查询[J].计算机科学,2013(4):172-176,192.
[3]吴刚.RDF图数据管理的关键技术研究[D].北京:清华大学, 2008.
[4]刘勇,李建中,朱敬华.一种新的基于频繁闭显露模式的图分类方法[J].计算机研究与发展,2007,44(7):1169-1176.
[5]冯端,冯步云.熵[M].北京:科学出版社,1992.
[6]H Shang,Y Zhang,X Lin,et al.Taming Verification Hardness:An Efficient Algorithm for Testing Subgraph Isomorphism[C]. In Proceedings of the International Conference on Very Large Data Bases,2008:364-375.
[7]Matthias Brocheler,Andrea Pugliese,V.S.Subrahmanian.A budget-based algorithm for efficient subgraph matching on huge networks[C].International Conference on Data Engineering,2011:94-99.
[8]CE Shannon.Mathematical theory of communication[J].Bell System Technical Journal,1948(27):379-423.
Technical mass index study reachability graph data
ZHAO Xing
(1.Shannxi Technical College of Finance and Economics,Xianyang 712000,China)
In view of the current SNS-depth development of community networks,large-scale map data up indexing technology began to be widely used in the social network,thereby improving the accuracy of the data index.In this paper,indexing technology applications up to a social network,there is a certainty and uncertainty of map data.For deterministic queries exist in a loud noise,information entropy manner,thereby improving the efficiency of image retrieval,so that a more precise semantic representation.
SNS;up index;uncertainty;inquiry;information entropy
TN99
:A
:1674-6236(2015)23-0152-03
2015-03-12稿件编号:201503176
赵 星(1982—),男,陕西咸阳人,讲师。研究方向:计算机相关技术及教学。
