基于Nagios的Hadoop集群性能监控
2015-02-18李建元
钱 涛,李建元
(1.浙江工业大学信息工程学院,浙江 杭州 310023;2.浙江银江股份有限公司,浙江 杭州 310030)
基于Nagios的Hadoop集群性能监控
钱涛1,李建元2
(1.浙江工业大学信息工程学院,浙江 杭州 310023;2.浙江银江股份有限公司,浙江 杭州 310030)
摘要:以Hadoop架构作为云平台的实现形式已经得到了广泛的应用。随着Hadoop集群内节点数量的增加,集群内部的复杂程度和故障率以几何级数增加,集群故障监控越来越重要。集群监控是云计算平台的重要组成部分,对提高云计算平台的稳定性发挥重要作用。文中提出一种可扩展集成化的云平台监控的实现,运维人员可以根据需求集成特定监控插件,通过一体化的监控界面,获取云平台的运行信息,确保云平台在Linux主机上的正常运行。
关键词:网络监控;云计算;分布式
0引言
Hadoop是一个高效、可靠、可扩展的开源分布式计算平台,能通过分布式的方式高效处理海量数据[1]。Hadoop集群运行时必须保证分布于各个节点的进程都能正常运行,当要确保节点上程序进程和硬件设备发生故障后能够及时发现并处理,这时就需要一款监控集群的网络监控软件,它采集Hadoop集群运行时的状态信息以及各个节点(数据节点和名称节点)所在的物理机硬件的状态信息。本文选取开源软件Nagios作为Hadoop集群的监控,它具有跨平台、接口标准化、高度扩展性、松散耦合等特点,可以集成多种监控功能并提供异常通知功能,满足对Hadoop云平台资源的监控需求。
1Hadoop云平台的介绍
云计算是随着计算、存储以及通信技术的快速发展而出现的一种崭新的共享基础资源的商业计算模型,被誉为“革命性的计算模型”[1]。Hadoop作为一种云计算的实现方式,其核心包括两个部分。
1)Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)。HDFS集群由一个负责集群管理的名称节点和若干个负责数据存储的数据节点构成。它具有高容错的特性,可以部署于价格低廉的硬件设备上,通过分布式的存储方式提高整个文件系统的IO性能,适合那些需要处理海量数据的程序。
2)MapReduce分布式计算模型。MapReduce是一种并行编程模式,MapReduce的计算模型概括而言,就是将海量数据集划分为许多个颗粒度较小数据集,分别由Hadoop集群中的数据节点进行并行处理生成中间数据,然后将数据节点中产生的中间数据进行合并处理,形成最终结果。计算模型的核心是两个由用户实现的框架,分别是Map框架和Reduce框架。首先在Map中实现任务的分配,将任务分发到各个数据节点进行计算,最后通过Reduce从各个节点进行汇总处理完成计算[2]。
2开源监控软件Nagios原理
监控软件既要尽量减少系统开销、又要保证监控能力,满足一定用户的监控需求。因此,监控软件的选取需要考虑以下几个方面:
1)低干扰、低开销,系统监控应不以牺牲过多的系统资源为代价,监控进程的优先级设置为较低,保证被监控系统的资源的较少占用。
2)可扩展性,监控软件能及时加载或卸载相应的监控模块,动态扩展其监控能力。
3)实时性,监控软件需要实时获取系统的运行信息,反映被监控端的状态变化,在故障发生后能及时通知相关人员。
4)数据采集频率可控,监控软件可以根据不同用户监控需求灵活配置系统信息的采集频率。
5)安装、配置简单。为方便用户使用,监控软件的部署、配置、运行需简单易行。
Nagios是一个监控系统运行状态和网络信息的监控软件,能监控所指定的本地或远程主机以及服务,同时提供异常通知功能。Nagios运行在Linux平台之上,同时提供基于Web浏览器显示功能方便维护人员查看系统日志,网络状态问题等[3]。
Nagios的功能是监控服务和主机,作为一个插件化的软件,它可以通过编写插件的方式来完成特定的监控和检测功能[4]。Nagios通过Nagios远程执行插件(Nagios Remote Plugin Executor,NRPE)的方式获取远程主机的信息。
当系统启动Nagios后,Nagios的运行原理如图1所示,Nagios core执行check_nrpe 插件,并通过配置文件配置check_nrpe所需检测的服务(如disk,load),通过安全套接层(Secure Sockets Layer,SSL),check_nrpe与远程被监控端的5666端口进行通信,在被监控主机NRPE daemon运行本地的插件去轮询本机的状态和服务,通过5666端口将相关监控参数发送给监控主机的check_nrpe,监控主机将返回信息添加到Nagios状态队列,Nagios可以识别4种返回的状态信息,即0(OK)、1(WARNING)、2(CRITICAL、3(UNKNOWN),分别表示状态正常、出现可控异常,出现严重错误,出现未知错误或监控停止。Nagios core根据被监控端返回来的运行参数,判断监控对象的状态,处理后通过Web显示出来,以供管理员及时发现[5]。
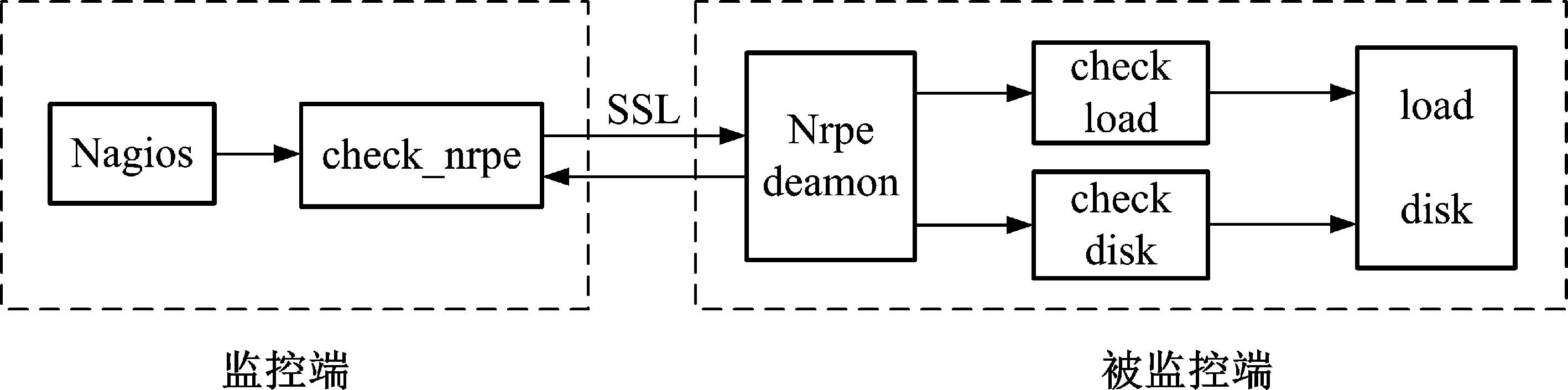
图1 Nagios NRPE基本原理
3监控平台的搭建
3.1 Hadoop集群的搭建

Hadoop运行格式化分布式文件系统的脚本hdFs namenode -Format格式化完成后,运行启动Hadoop集群脚本start-all.sh,将会在master节点启动NameNode、Resource Manager、Secondary NameNode进程,在slave节点上将会出现DataNode NodeManager进程。通过浏览器访问:http://master:50070和http://master:8080页面,web页面将会分别显示HDFS的状态信息和MapReduce的情况。
3.2 Nagios的安装配置
在监控端中Nagios的基本组件的运行依赖于httpd,gcc和gd通过yum安装所需的依赖包,添加nagios运行所需的组(nagioscmd)和用户(nagios),将apache和nagios用户加入到nagioscmd用户组,编译安装nagios核心安装包nagios-4.0.6.tar.gz,nagios插件包nagios-plugins-2.0.2.tar.gz和Nagios NRPE插件包nrpe-2.12.tar.gz。
被监控端只需编译安装nagios plugin和nagios nrpe,安装编译完毕后,被监控端开启nrpe deamon守护进程监听5666端口,与远程的监控主机通信,配置监控端nagios.cFg和被监控端nrpe.cFg配置文件,使用shell指令nagios-v /etc/nagios.cFg校验etc目录下的配置文件,无误后使用service nagios start命令在监控端启动Nagios,至此nagios安装完毕。
4实验结果分析
安装完毕后,访问http://master/nagios,将从web端监控Hadoop各个节点硬件信息和状态。
Nagios自身不具备监控Hadoop集群的功能,但Nagios作为一个高度插件化软件,用户可以通过编写插件的方式实现所需的监控目标,Nagios的插件可以用Perl,Python等语言进行编写,但必须满足以下两个条件:
1)插件的返回值为Nagios可检测到的4种状态中的1种;
2)插件至少向标准输出设备(STDOUT)输出性能数据(perFdata)描述状态。
本文通过编写shell脚本作为插件获取Hadoop集群运行情况,脚本首先定义4种状态常量(OK、WARNING、CRITICAL、UNKOWN),通过hdFs dFsadmin -report获得整个集群的状态信息的文本,后通过shell脚本中管道(pipe)、grep、sed、awk等脚本命令对文本进行筛选、匹配和截取,获得Hadoop集群的状态信息如capacity(集群的容量)、totalnode(集群的节点数)、livingnode(集群正在运行的节点数)、usage(集群的使用状况)等,通过echo方式返回性能数据(perFdata),并通过条件判断语句比较性能数据(perdata)与预设阈值的大小,从4种输出的状态确认1种作为脚本退出代码。shell脚本的简化代码如图2所示。
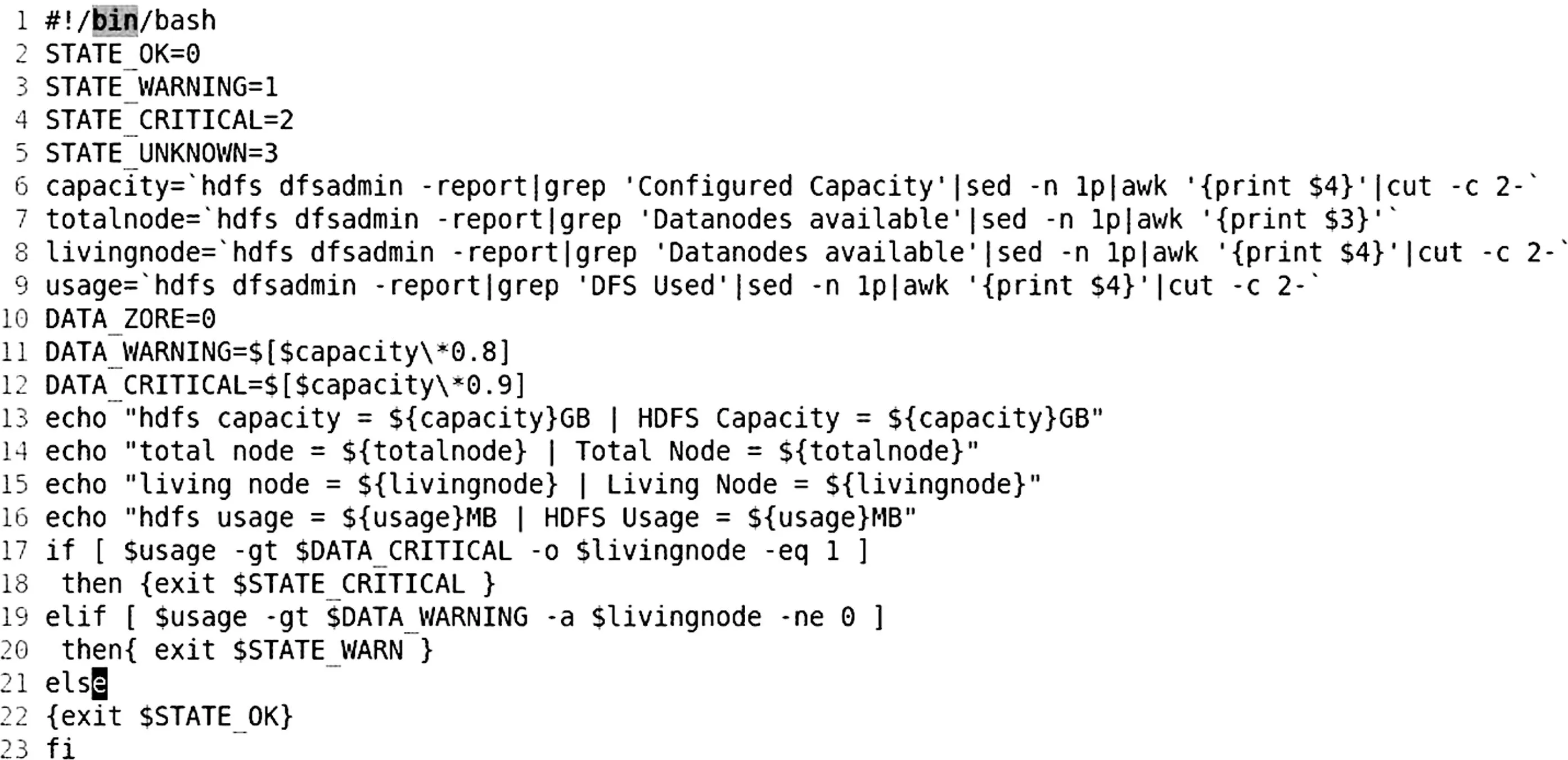
图2 shell脚本的简化代码
当Nagios集成pnp4nagios插件后,Nagios从插件上传中选择符合一定规则的输出性能数据(perFdata)通过rrdtool处理,之后pnp就会以图表的形式在web端展现。Hadoop集群中文件系统的使用状况如图3所示,图3中,横坐标表示时间,纵坐标表示HDFS_USAGE(文件系统的使用情况),在2:05和3:40左右,分别将数据导入HDFS中后,纵坐标HDFS_USAGE随即从最初的462.02 MB上升至986.72 MB最后直至1.52 GB,能够准确监控文件系统使用情况。
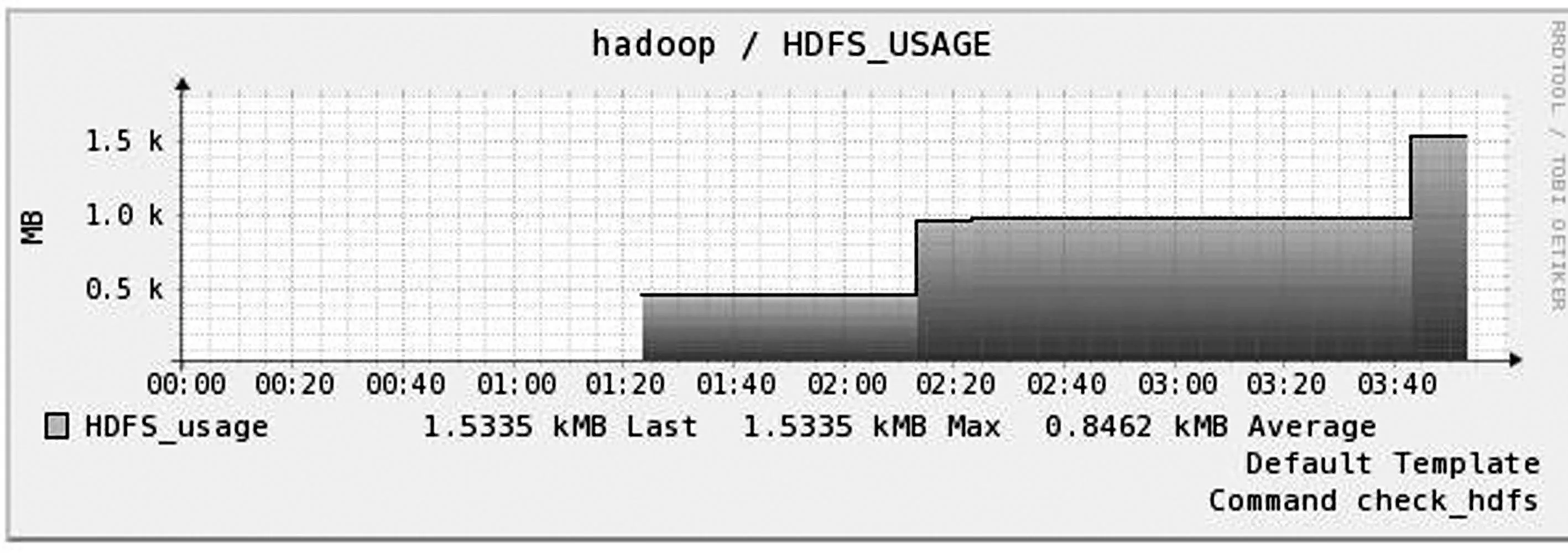
图3 HDFS文件系统的使用状况
5结束语
本文给出了一种良好的Hadoop集群监控方案,发挥Nagios作为一种插件化监控软件优势,不仅可以利用Nagios进行故障监控,包括集群节点的监控,同时通过Nagios和pnp4nagios插件相结合,可以将抽象数字化的状态信息变为直观的图表样式。下一步工作是将Nagios和MySQL等相结合,将Nagios历史数据存入MySQL数据库中,通过对历史数据进行分析,预测被监控端的远程主机下一步的状态信息,在出现故障之前进行预警和修复,保证整个集群的稳定性和可靠性。
参考文献
[1] 匡胜徽,李勃.云计算体系结构及应用实例分析[J].计算机与数字工程.2010(03):60-63.
[2]孙广中,肖锋,熊曦.MapReduce模型的调度及容错机制研究[J].微电子学与计算机.2007,24(9):178-180.
[3]刘东君.基于Nagios的综合监视系统设计与实现[J].网络安全技术与应用.2013,(8):18-20.
[4]魏根芽.基于Linux的Nagios服务器监控系统的研究与实现[J].计算机与现代化.2010,(6):170-172.
[5]王帆.基于Nagios的服务器监控平台构建与实现[J].实验室研究与探索.2010,(12):51-57.
Hadoop Cluster PerFormance Monitoring Based on Nagios
Qian Tao1, Li Jianyuan2
(1.InstituteoFInFormation,ZhejiangUniversityoFTechnology,HangzhouZhejiang310023,China;
2.ResearchInstituteoFEnjoyorCo.LTD,HangzhouZhejiang310030,China)
Abstract:In the Form oF Hadoop architecture as the realization oF the cloud platForm has been widely used. With an increase in the number oF nodes within the Hadoop cluster, the cluster oF internal complexity and Failure rate increase in geometric series. Cluster monitoring is an important part oF the cloud computing platForm, to improve the stability oF cloud computing platForms play an important role.This paper presents a scalable integrated cloud platForm monitoring methods, operation and maintenance personnel can be integrated with speciFic monitoring plugin complete demand. Through the integration oF monitoring interFace, maintenance personnel obtain the operating state oF cloud platForms, to ensure normal operation oF Hadoop cluster in Linux hosts.
Key words:network monitoring; cloud computing; distributed
中图分类号:TP277
文献标识码:A
文章编号:1001-9146(2015)03-0064-04
作者简介:钱涛(1989-),男,浙江绍兴人,在读研究生,信息与通信工程.
收稿日期:2014-11-06
DOI:10.13954/j.cnki.hdu.2015.03.013
