汉语口语产生中音节和音段的促进和抑制效应*
2015-01-23张清芳
岳 源 张清芳,2
(1中国科学院心理研究所, 北京 100101) (2中国人民大学心理学系, 北京 100872)
1 引言
言语产生是将思想转化为具体言语的过程。一般认为言语产生包括三种类型的心理过程:首先是概念化过程, 即讲话者明确要用言语表达什么概念;第二是言语组织阶段, 即为所表达的概念选择适当的词汇, 建立词汇的语法结构和发音结构; 第三是发音阶段,即将选择的词汇通过一定的肌肉运动程序用外显的声音表达出来(Roelofs, 1992)。人类表达语言的过程是非常迅速的, 上述三个过程可以在大约600~700 ms之内完成(Levelt, Roelofs, Meyer,Helenius, & Salmelin, 1998)。言语组织阶段是口语产生中的核心, 又被称之为词汇通达, 包括了两个阶段:词条选择和单词形式编码。单词形式编码过程可进一步细分为词素音位编码、音韵编码和语音编码三个过程。在词素音位编码过程, 讲话者根据词条选择阶段所得到的词汇选择相应的词素及其句法特征。在音韵编码过程, 根据词素选择音段和节律结构, 并进行音节化, 将音段与节律结构中的音节节点联系起来。在语音编码过程选择音节程序节点为发音做好准备(Dell, 1986; Roelofs, 1997; Levelt,Roelofs, & Meyer, 1999)。音韵编码的单元和加工方式一直是言语产生研究的争论焦点之一。
口语产生的两大理论模型对于音韵编码的单元和加工方式提出了不同的看法。Dell (1986, 1988)根据语误分析的结果提出的单词形式编码模型认为:音韵编码的单元包括了音素、音节、音节的组成成分及其语音特征。音韵编码过程中音节的组成部分(首音、核心元音和尾音)同时得到激活后被插入音节框架结构。当一个词素包含多个音节时, 音节的加工是从左至右序列进行的。对于单个音节内部的编码方式, Dell未提出任何具体的假设。Roelofs(1997)提出的 WEAVER (Word-form Encoding by Activation and VERification)模型是目前为止最为详细的单词形式编码模型。在该模型框架中, 音韵编码的单元是音素, 单个音节内部的音韵编码是一个增长式的编码过程, 从音节的首音开始到核心元音最后到尾音(Levelt et al., 1999)。关于音韵编码的单元和加工方式, 两类模型之间存在激烈争论。Dell认为音韵编码的单元可以是音节或音素, 音节内部的音素可以同时被激活并插入音节框架; 而 Levelt等认为音韵编码的单元是音素, 音素以序列的方式从左至右被插入音节框架。
已有研究对于“音节是否是单词形式编码单元”的争论尤为激烈, 不同语言的研究对此问题也难以达成共识。已有研究在法语(Ferrand, Segui, &Grianger, 1996)和英语(Ferrand, Segui, & Humphreys,1997)口语词汇的产生中都发现了音节启动效应,表明音节是口语产生的功能单元。Schiller (1998,2000)利用相同的实验范式考察了荷兰语和英语中音节和音段的作用, 发现的却是音段重叠效应, 表明音段是口语产生中的功能单元, 得到了与 Ferrand等不一致的结果。根据上述结果, 研究者指出口语产生中音韵编码的单元与语言特点有关, 很多研究者认为在法语语言产生中, 音韵编码单元更有可能是音节。尽管如此, 也有研究结果与此假设相矛盾, 例如, 在法语非词命名中未发现音节启动效应(Mehler,Dommergues, Frauenfelder, & Segui, 1981), 因此研究者认为法语或许不是探测音节作用最适合的语言。根据Levelt等的观点, 重新音节化现象是他们认为不存在存储音节的主要原因, 毕竟在法语中也存在一些模糊音节和重新音节化现象。汉语作为一种非字母语言, 在音节结构上与法语类似, 但在口语产生过程中不存在模糊音节和重新音节化现象,这对探测音节和音段的作用非常有帮助。
最近, 汉语口语词汇产生中单词形式编码单元是音节还是音段的争论尤为引人注目。Chen, Chen和Dell (2002)利用内隐启动范式探索汉语双音节词汇产生中的音韵编码阶段, 发现无声调的音节在音韵水平上能作为一个独立的计划单元, 声调的作用则类似于字母语言中的重音和节律结构。Chen, Lin和 Ferrand (2003)利用掩蔽启动范式得到了同样的结果。张清芳和杨玉芳(2005)利用图画-词汇干扰实验范式探索了音韵编码过程的单元, 结果仅发现了音节或音节与声调的结合是音韵编码的单元, 而音素相关(首音、韵母或“韵母+声调”的结合)不能对图画命名产生显著的促进效应。Chen (2000)分析语误语料库发现音节交换错误的发生率显著高于音段交换错误, 表明音节在口语产生中的重要性高于音段。You, Zhang和Verdonschot (2012)利用图画命名和单词命名两种任务均发现了音节启动效应, 为汉语口语中音节是音韵编码单元提供了更强的证据。与此结果相对的是, 有一些研究发现了粤语口语产生中音段的促进效应。Wong和 Chen (2008,2009)采用图画-词汇干扰范式, 在粤语中发现当干扰词与目标词的韵母和声调相同时, 图画命名显著快于无关条件, 因此他们认为, 粤语口语产生中的音韵编码单元可能是音段(Segments) (多个音素结合形成的一个单元, 其音素个数少于音节)。Wong,Huang和 Chen (2012)采用内隐启动范式得到了类似的结果。Qu, Damian和Kazanina (2012)采用首音素重复范式, 在行为结果上未发现启动效应, 但是在事件相关电位的指标上发现了首音素重复条件下的波幅与非重复条件下存在显著差异。这些研究表明音段信息在汉语口语产生中似乎也起了一定作用。
为了解释已有研究结果之间的不一致,O′Seaghdha, Chen和Chen (2010)提出了合适单元假设(Proximate unit Principle)来解释汉语口语词汇产生中的单词形式编码过程(如图1所示)。这一假设认为音韵编码单元中最先选择的单元存在语言上的差异, 印欧语系语言如英语或荷兰语中最先选择的单元是音素, 而在汉语中则为音节。在印欧语系语言中, 讲话者在选择音素后, 结合节律信息进行音节化过程, 从心理音节表中提取音节准备发音运动程序。汉语口语产生中讲话者则在选择音节后进一步分解为音素或音段信息(音韵编码阶段), 准备发音运动程序(语音编码过程), 最后进行发音输出口语产生的结果(发音阶段)。“合适单元”假设对于印欧语言的单词形式编码过程的阐述是符合WEAVER模型的观点的。从上述假设可以看到, 在印欧语言中首先提取音素再从心理音节表中提取音节, 而在汉语中是先提取音节再分解成音段(或音素)。
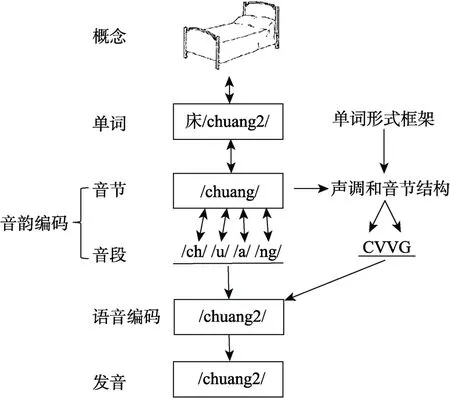
图1 O′Seaghdha等(2010)提出的汉语单音节词汇产生的示意图
目前尚未有研究直接探测汉语普通话口语产生中音节或音段起作用的认知机制, 汉语中认为“音段是音韵编码单元”的发现均来自对粤语口语产生过程的探索(Wong & Chen, 2008, 2009; Wong et al.,2012)。Wong等(2012)的研究(p.6)中认为粤语的口语产生可能与汉语普通话存在差异, 这是因为粤语的音韵体系比汉语普通话复杂:例如, 普通话中仅有两种尾音/n/和/ng/, 而粤语中包含六种尾音/p/,/t/, /k/, /m/, /n/和/ng/, 而且/ng/在粤语中还可以作为首音出现。粤语中包括了6个声调, 而普通话中仅包括4种声调。总结上述研究发现, 粤语口语词汇产生中的音段促进效应是在图画词汇干扰范式和内隐启动范式中发现的, 而音节效应是在图画词汇干扰任务、内隐启动范式或者掩蔽启动任务中发现的。基于上述比较, 我们认为图画-词汇干扰实验范式对音段启动效应更为敏感, 且图画命名任务是典型的口语产生任务, 包括了口语产生的完整过程,因此在本研究中我们采用这一经典范式探索音节和音段效应的认知机制。
口语产生中的单词形式编码过程中涉及到语音信息的加工, 包括了音韵编码和语音编码。依据合适单元假设, 在汉语口语产生的音韵编码过程中,讲话者提取音节后分解成音素或音段, 然后在语音编码阶段准备音素或音段的运动程序, 最后在发音阶段输出目标词。音节效应和音段效应可能出现在口语产生中的单词形式编码过程的哪一个阶段, 目前的研究都未对此进行考察(Levelt et al., 1999;O′Seaghdha et al., 2010)。基于已有研究, 本研究的目的是考察汉语普通话口语产生过程中音节效应和音段效应产生在哪个阶段。实验 1采取了图画-词汇干扰实验任务, 要求被试在看到图画和干扰字时, 忽略干扰字, 尽可能准确和迅速地说出图画的名称。这是一个即时命名任务, 包括了口语产生的所有过程, 从概念准备、词汇选择、单词形式编码(音韵编码和语音编码)到最后的发音阶段。实验 2采取了图画-词汇干扰范式与延迟命名结合的任务,要求被试看到图画后不能立刻进行命名, 而是要做好命名的准备, 在看到提示命名信号出现后尽快说出图画名称, 此时被试已经完成了发声前的所有准备, 即被试已经完成了概念准备、词汇选择、单词形式编码中的音韵编码和语音编码阶段的加工。在提示线索出现时, 被试只要立即开始执行发音程序即可, 反应时仅反映了发音阶段的加工特点。实验3采取了图画-词汇干扰任务与延迟命名和发音抑制任务的结合, 即在延迟命名的同时要求被试完成一个发声抑制任务, 在等待命名信号出现的过程中要求被试重复发出某个指定的特定语音或者数数,这会影响被试短时记忆中的操作, 使得被试不能进行语音编码阶段的加工(Baddeley, Lewis, & Vallar,1984)。因此在这一任务中当命名信号出现时, 被试完成了概念准备、词汇选择和单词形式编码中的音韵编码过程。命名信号出现时, 被试需要进行语音编码, 再进行发音, 所记录的反应时中包括了语音编码和发音两个阶段。通过比较三个实验中是否出现音节效应或音段效应, 可以推测这些效应发生在口语产生中单词形式编码(音韵编码或者语音编码)还是最后的发音输出阶段。
2 实验1:单词形式编码中的音节和音段促进效应
2.1 方法
2.1.1 被试
24名大学生和研究生(13名男性), 年龄19岁到25岁, 北方人, 普通话标准, 视力或矫正视力正常, 听力正常。实验后获得一定报酬。
2.1.2 材料
27幅黑白线条图片, 选自张清芳和杨玉芳(2003)建立的汉语图片命名的图片库。用于正式实验的图片为18幅, 填充图片9幅。图片名称均为单音节词, 每幅图片与4种类型的干扰字匹配。例如,图片名称为“铃” (/ling2/), 分别与 1)音节相关字“另” (/ling4/), 与目标图片名称音节完全相同, 声调不同; 2)首音段相关字“烈” (/lie4/), 与目标图片名称的第一个辅音和第一个元音相同, 声调不同,即与目标图片名称的头两个音素相同(CV相关, C表示辅音Consonant, V表示元音Vowel); 3)韵相关字“鼎” (/ding3/), 与目标图片名称的元音和结尾的辅音相同, 音调不同, 即与目标图片的韵相同(VC相关); 4)无关字“泡” (/pao4/), 与目标图没有语音重合。4种条件下干扰字的字频(王还, 刘杰, 常保儒, 1986)和笔画数匹配, 统计结果无显著差异, 字频:F
(3,68) = 0.001,p
= 1.00; 笔画数:F
(3,68) = 0.130,p
= 0.97。实验材料及其字频和笔画数见附录1。在Wong和Chen (2009)的研究中, 3/4的测试次中干扰字与图画名称之间存在语音相关, 仅有 1/4为无关条件, 被试更有可能觉察到语音相关条件从而影响到实验结果。因此实验1增加了9幅图片作为填充材料, 分别搭配 4个不同的无关干扰字, 与图片在语义、字形和语音上不相关, 被试接受的测试中干扰字与图画名称语音相关和无关试次各占一半。
2.1.3 设计
单因素被试内设计, 自变量为“图片名称与干扰字之间的关系”, 包括了 4个水平(音节相关, 首音段相关, 韵相关和无关)。各试次以伪随机方式呈现, 相同图片至少间隔2幅其它图片。首音段相同、韵相同或音节相同的干扰字不会连续呈现。每一名被试完成的试次顺序不同。
2.1.4 实验仪器
E-Prime 编写的程序, PST SRBOX反应盒, 麦克风和计算机。图片都呈现在PIII-667计算机屏幕中央。被试的反应通过 PSTSR-BOX连接的麦克风记录。实验材料的呈现、计时及被试反应时的收集由电脑过程控制。主试记录被试的反应正确与否。
2.1.5 程序
在正式实验开始之前, 在屏幕中央依次呈现每幅图片及图片对应的名称3 s, 共27幅图片, 包括18幅目标图片和9幅填充图片。告诉被试下面的正式实验会呈现这些图片, 要求被试记住图片及其对应的名称。如果被试对某一幅图片的命名出现错误时进行纠正, 并强调要记住图片下方呈现的目标名称。一般来说, 因为这些图片都是日常生活中常见的命名一致性很好的图片, 被试对图片的命名与程序中给出的名称是一致的。
正式实验时, 首先呈现注视点500 ms, 然后空屏300 ms, 接着同时呈现图画和干扰词。图片经过标准化形成大小为6 cm × 6 cm的图片并呈现在屏幕中央, 干扰字采用25号宋体, 呈现在图片中央。被试的任务是忽略出现的词语, 尽可能准确而迅速地说出图画的名字。被试做出反应的同时图片和干扰字消失, 呈现主试判断正误的提示符号。主试按键判断后, 间隔1000 ms后开始下一次测试。计算机记录被试的反应时间, 主试记录被试的命名并判断正确与否。正式实验前有4次练习, 使被试熟悉实验任务。正式实验包含填充材料在内, 共有 108个试次。整个实验的完成大约需要15 min。
2.2 结果
删除命名错误的数据(1.60%), 其它声音比如“嗯”或“啊”引起的反应(1.70%), 以及偏离平均值2.5个标准差以外的数据(2.08%)。
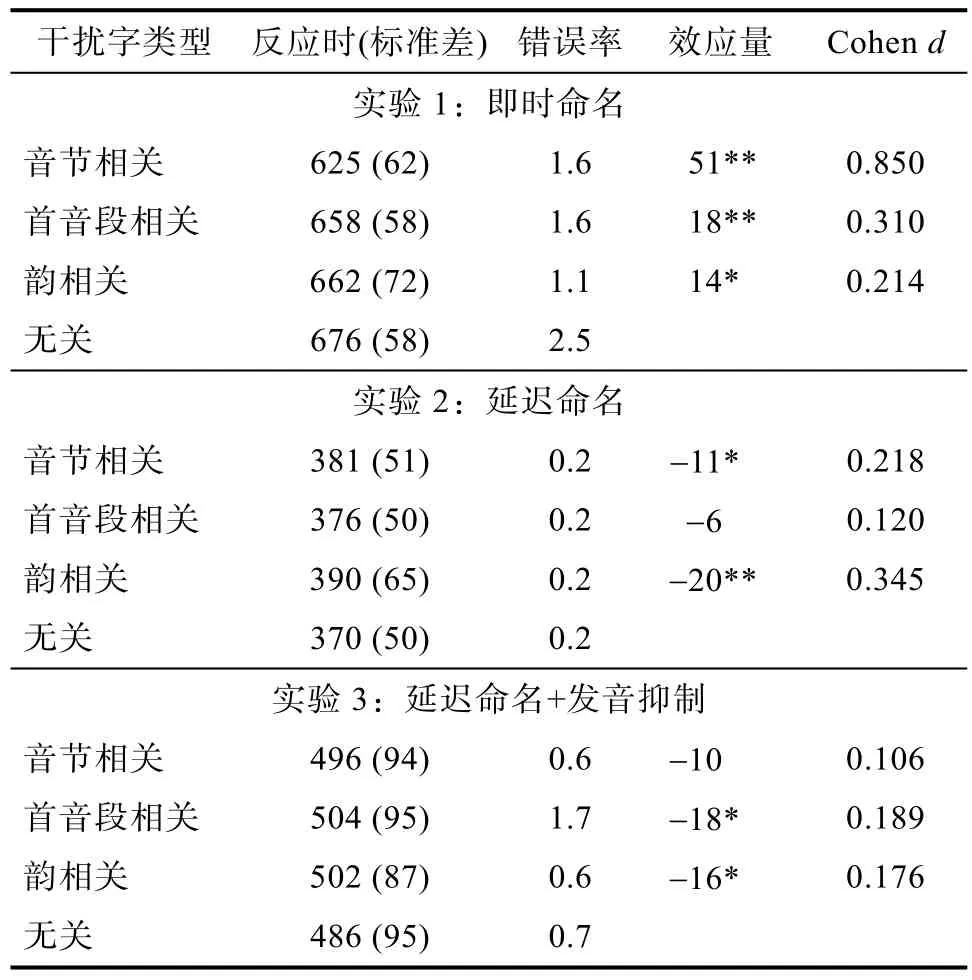
表1 不同干扰条件下的平均反应时(ms)和错误率(%)
表1第一部分所示为实验1中4种不同条件下被试的平均命名反应时。利用R分析软件(2013)进行混合线性模型拟合分析, 结果表明拟合最优的模型包括了干扰词类型这一因素。进一步的比较发现,音节相关条件下的反应时显著快于无关条件,t
(1609) = -7.60,p
= 0.001; 首音段相关条件反应时显著快于无关条件,t
(1609) = -2.70,p
= 0.007; 韵相关条件下反应时显著快于无关条件,t
(1609) = -2.07,p
= 0.043。我们进一步采用效果量Cohend
评估了各相关条件与无关条件下平均数差异的效果量大小。Cohend
值是衡量统计检验效果大小(效应量)的指标之一, 效果量是表示实验效应强度或者变量关联强度的指标(Snyder & Lawson, 1993), 它不受样本容量大小的影响(或者影响较小) (郑昊敏, 温忠麟, 吴艳, 2011)。0.2 < Cohend
< 0.5 表示效果量大小弱, 0.5 < Cohend
< 0.8 表示效果量大小中等, Cohend
> 0.8表示效果量大小强(Cohen, 1988)。4种条件下的错误率都很低, 因此未对错误率进行分析。2.3 讨论
采用图画-词汇干扰实验范式, 实验 1发现了音节促进效应和音段促进效应(首音段相关和韵相关), 而且音节相关条件下产生的促进效应量显著地大于音段相关条件。与Wong和Chen (2009)的实验结果类似, 实验1发现了首音段和韵相关条件下的语音促进效应, 表明对音段的准备促进了口语产生过程。Wong等的实验中三种相关条件所产生的效应量无显著差异, 他们认为音节与音段促进效应都发生在音韵编码阶段。与Wong的实验结果不同,实验1发现音节相关条件下的效应量与音段相关条件下的效应量之间差异显著(p < 0.05), 而且效果量Cohen d值的评估表明, 音节促进效应是一个可靠的强效应, 而首音段促进效应和韵相关促进效应的效果量Cohen d值很小, 这提示我们音节和音段促进效应的产生机制可能存在差异。
根据O′Seaghdha等(2010)提出的汉语口语产生模型(如图1所示), 音节是词汇选择阶段之后最先选择的单元, 之后音节分解为音段进行编码为发音做好准备。根据其假设, 音段促进效应可以发生在音韵编码阶段中的音节提取之后, 亦可发生在语音编码或发音阶段。语音编码的主要任务是编码运动程序, 发音阶段执行准备好的语音运动程序, 输出口语产生的结果。实验2和3的主要目的是考察图画-词汇干扰实验范式中音段效应的发生阶段。
3 实验 2 发声阶段的音节和音段抑制效应
延迟命名任务中, 被试在看到图片时不能立即说出图片名称, 而是要等到反应提示出现时才能命名图片。由于在发声前有足够长的延迟, 且要求被试在看到提示线索后尽快命名, 当提示线索出现时,被试已经完成了音韵编码和语音编码过程, 只需要执行发音程序即可, 因此所记录到的反应时反映了发音阶段的特点(Levelt et al., 1999; Laganaro &Alario, 2006)。如果在延迟命名中发现了音节或音段促进效应, 表明实验1中的效应可能发生在最后的发音阶段(Laganaro & Alario, 2006)。实验结果的另一种可能性是:实验1中发现的促进效应发生在音韵编码阶段, 在延迟命名任务中不会发现促进效应; 抑或发现抑制效应, 因为对干扰词的发音准备可能对目标词的发音产生干扰(Mahon, Costa, Peterson,Vargas, & Caramazza, 2007)。
3.1 方法
3.1.1 被试
24名大学生和研究生(3名男性), 年龄19岁到28岁。与实验1中的被试来自同一群体, 且没有参加过实验1。实验后支付一定报酬。
3.1.2 材料、设计、仪器
与实验1相同。
3.1.3 程序
实验时, 首先呈现 500 ms的注视点(+), 注视点消失后呈现空白屏 300 ms, 之后屏幕中央同时呈现目标图片及干扰字 600 ms, 接着呈现空白屏幕, 其呈现时间在600 ms到1000 ms之间随机, 目的是防止对被试对反应提示的出现有所准备; 空白屏幕后呈现红色叹号, 要求被试在看到这一提示符号后尽可能正确而迅速地说出图画名称。在正式实验开始前有4次练习, 被试熟悉整个实验流程。程序其它部分与实验1完全相同。
3.2 结果
删除提前反应的试次 53个(0.03%), 删除 2.5个标准差以外的试次56个(0.03%)。
表1的第二部分表示了延迟命名中4种不同条件下被试的平均反应时、平均错误率以及Cohen d值。混合线性模型拟合分析发现最优模型中包括了干扰词的类型这一自变量。进一步分析发现, 音节相关条件下反应时显著慢于无关条件, t(1617) =2.03, p = 0.042。首音段相关条件与无关条件反应时没有显著差异, t(1617) = 1.01, p = 0.310。韵相关条件下被试反应显著慢于无关条件, t(1617) = 3.34, p =0.0006。4种条件下的错误率都很低, 因此未对错误率进行分析。
3.3 讨论
实验 2发现, 与无关条件相比, 图画与名称之间存在韵或音节相关时, 对干扰词的发音准备会对目标名称的发音产生抑制作用, 表明目标词和干扰词之间韵或音节的重叠阻碍了目标词口语产生中的发声执行过程。值得注意的是, 实验2发现的是抑制效应, 而非实验 1观察到的促进效应。实验 1和实验2的结果表明音节或音段相关在音韵编码阶段和发音阶段产生了不同的效应。
实验2发现了韵相关产生的抑制效应量大于音节相关, 但两者之间的差异未达到显著差异的水平。在音节相关条件下, 也存在目标词与干扰词在韵上的重合, 我们猜测音节相关条件下的抑制效应可能是由于韵相关引起的。首音段相关条件与无关条件相比未达到显著差异, 这可能是由于被试对韵相关信息可能更为敏感引起的, 对干扰词韵相关信息的准备阻碍了目标词的发声。Wong和Chen (2008)的研究中发现了干扰词和目标词共享韵母和声调时产生了促进效应, 而未发现首音段和声调重合时的促进效应, 这表明粤语被试对韵相关的信息更为敏感。在对韵信息比对首音段信息更为敏感这一点上, 我们的发现与 Wong和 Chen (2008)的发现一致。效果量大小Cohen d值表明音节抑制和音段抑制效果量都很弱。
4 实验 3 语音编码阶段的音节和音段抑制效应
为了进一步确定实验1中发现的音段促进效应是否发生在口语产生中的语音编码阶段, 实验3采取了图画命名与延时命名和发音抑制相结合的任务, 在等待命名信号出现的过程中要求被试重复发出某个指定的特定语音或者数数, 这会影响被试短时记忆中的操作, 使得被试不能进行语音编码阶段的加工(Baddeley et al., 1984)。当提示线索出现时,要求被试说出目标图画的名称。已有研究表明延时命名和发音抑制任务的结合可以探测口语产生中的语音编码和发音阶段的特点(Laganaro & Alario,2006; Wheeldon & Levelt, 1995)。如果在延迟命名和发音抑制结合的任务中发现了音段促进效应, 表明实验1中的效应可能发生语音编码阶段。与实验2类似, 实验结果的另一种可能性是:实验 1中发现的促进效应发生在音韵编码阶段, 在延迟命名任务中不会发现促进效应; 抑或发现抑制效应, 因为对干扰词的发音准备可能对目标词的发音产生干扰。
4.1 方法
4.1.1 被试
30名大学生和研究生(7名男性), 年龄19岁到25岁, 与实验1和2来自同一群体。均未参加过实验1和2, 实验后支付一定报酬。
4.1.2 材料、设计、仪器
与实验2相同。
4.1.3 程序
实验程序与实验2基本相同, 只是从目标图片呈现开始, 要求被试立刻开始不停重复说“1”直到反应提示符号(红色叹号)出现时, 立即停止发声任务, 然后尽量准确而迅速的说出之前所呈现目标图片的名称。
4.2 结果
实验中被试所犯错误极少, 多数错误为被试在看到反应提示时不能立刻停止发声而造成的错误记录, 包含标准差 2.5个标准差以外的极值数据,共删除数据98个, 占总数据4.5%。
表1第三部分所示为实验3中4种不同条件下被试的平均反应时、平均错误率和效果量Cohen d值。利用R分析软件对反应时数据进行混合线性模型拟合分析, 最优的模型包括了干扰类型因素。进一步分析发现, 音节相关条件与无关条件之间无显著差异, t(2061) = 1.37, p = 0.171。首音段相关条件下反应时显著慢于无关条件, t(2061) = 2.37, p =0.021。韵相关条件下反应时显著慢于无关条件,t(2061) = 2.13, p = 0.037。效果量Cohen d的评估表明音节相关、首音段相关和韵相关的抑制效应量均很弱。
4.3 讨论
实验3发现, 当图片名称与干扰字的首音段或韵相同时, 反应时显著慢于无关条件下图片命名的反应时, 出现了首音段和韵相关的抑制效应, 其效果量Cohen d值弱。另一方面, 音节相关条件与无关条件相比仅有 10ms的差异, 其效果量 Cohen d值小于音段相关条件。实验3的反应时中包含了语音编码和发音阶段, 而实验2中的反应时只包含发音阶段, 实验3中发现了首音段抑制效应而实验2未出现这一效应, 这表明首音段所产生的效应可能发生在语音编码阶段(Levelt et al., 1999; Laganaro& Alario, 2006)。实验2和实验3均包含发音阶段,且都发现了韵的抑制效应且效应量大小相当, 表明韵的抑制效应可能发生于发音阶段(Laganaro &Alario, 2006; Mahon et al., 2007)。
5 总讨论
采用图画-词汇干扰实验范式, 通过比较即时命名、延迟命名以及延迟命名与发音抑制任务的结合, 我们考察了汉语口语产生中音节和音段在单词形式编码的不同阶段所产生的不同效应。主要发现包括:在包含有音韵编码、语音编码和发音阶段的即时命名中, 发现了音节的促进效应以及首音段和尾音段的促进效应; 在仅包含发音阶段的延迟命名任务中, 发现了音段抑制效应和音节的抑制效应;在包含有语音编码和发音阶段的延迟命名和发音抑制结合的任务中, 发现了首音段相关和韵相关的抑制效应。上述结果综合表明:在口语词汇产生的单词形式编码过程中, 音节和音段促进效应发生在音韵编码阶段, 而音节和音段的抑制效应发生在语音编码和发音阶段。效果量大小(Cohen d)的分析表明, 音节的促进效应是可靠的强效应, 而其它差异的效果量均较弱。不同的认知阶段, 音节和音段起作用的方式可能存在不同。我们第一次在汉语普通话中发现了音段促进效应、音节和音段的抑制效应,更为重要的是, 我们确定了音节和音段促进效应在口语产生过程中的发生阶段。下面将在O′Seaghdha等(2010)提出的汉语口语产生的单词形式编码模型的框架中讨论本研究的实验结果。
音节的促进效应与抑制效应。根据O′Seaghdha等(2010)提出的汉语口语产生中单词形式编码模型(如图1所示)的合适单元假设, 在汉语的口语产生中, 音节(与目标词的声调不同)是合适的单元, 且音节的促进效应来自于对音韵信息的事先提取; 另一方面, 与目标词不同声调的干扰字在语音编码阶段不能对发音产生促进效应。与此假设一致, 我们在实验1发现了音节的促进效应, 即对干扰词的音节准备促进了目标词的产生, 该效应发生在音韵编码阶段(张清芳, 杨玉芳, 2005; 张清芳, 2008; Chen et al., 2002; O′Seaghdha et al., 2010; Wong et al.,2012); 同时, 我们在语音编码和发音阶段发现了干扰词与目标词音节相关时的抑制效应。这些发现表明音节的促进效应确实发生在音韵编码阶段, 而非语音编码或者发音阶段。
音段的促进效应与抑制效应。根据O′Seaghdha等(2010)提出的合适单元假设, 在提取音节后分解成首音、韵等音段信息, 与节律信息(包括声调和音节结构等)结合, 进行语音编码为发音做好准备。实验1发现的音段促进效应为此提供了支持证据, 表明在汉语口语产生过程中干扰字和目标名称之间存在音段相关时, 音段信息对目标名称的命名产生了促进效应(Wong & Chen, 2008, 2009; Wong et al.,2012)。同时, 实验2和3发现的音段抑制效应则从相反的角度证实了:音段促进效应发生在音韵编码阶段, 而非语音编码和发音阶段。
比较音节和音段在不同任务中的效应, 我们发现:音节信息和音段信息在音韵编码和语音编码、发音阶段产生了不同方向的效应。音节相同而声调不同时在语音编码和发音阶段不能产生促进效应,这表明在口语产生的这两个阶段, 讲话者是综合考虑音段信息和节律信息(如声调和音节结构)对发音进行准备。在口语产生中的语音编码和发音两个阶段, 提供部分信息不能产生促进效应, 反而会阻碍口语产生结果的输出。另一方面, 在音韵编码阶段,音节的效果量Cohen d值大; 相比而言, 在语音编码和发音阶段, 音段相关的效果量Cohen d值大于音节相关的效果量, 这表明在音韵编码阶段音节的作用大于音段, 而在语音编码和发音阶段, 音段的作用大于音节。在音韵编码阶段需要从心理词典中首先提取整体音节, 之后再分解为音段, 因此音节效应强于音段效应(O’Seaghdha et al., 2010); 在语音编码和发音阶段, 被试需要根据音段信息而非音节信息来进行发音运动程序的准备, 因此音段相关的效应显著。
在口语产生研究领域, 一些研究者提出了前运动(Pre-motor)和运动加工过程的分离假设(Eickhoff,Heim, Zilles, & Amunts, 2009; Hickok & Poeppel,2007), 该假设认为对词汇表征的准备与其执行过程是独立的。音韵编码过程是对词汇音韵表征的提取, 属于词汇表征的准备过程, 而语音编码和发音过程则属于对运动执行过程的准备。与此观点一致,我们的结果发现了音节和音段信息的准备效应与随后运动执行过程中所产生的效应方向不同, 支持了前运动过程与运动执行过程分离的假设。需要注意的是, 实验2和3中效果量的Cohen d值都较小,表明无论是音节还是音段在语音编码和发音执行阶段所起作用都较小, 这有可能是由于图画-词汇干扰实验范式与延迟命名和发音抑制的结合任务是一个程序上相对较为复杂的任务, 对音节或音段的作用不够敏感, 进一步的研究可以采用掩蔽启动范式或者是重复启动范式与发音抑制任务的结合来探测音节和音段在运动执行阶段的作用。研究者更进一步提出需要整合心理语言学和运动控制的研究方法来考察口语产生过程中词汇准备和运动执行过程之间的关系(Hickok, 2012, 2014; Roelofs, 2014)。
计算和报告效果量不仅能够区分统计显著性和实际显著性(Kirk, 1996), 而且可以通过元分析方法比较同一效应在不同研究中的实验结果(Hunter & Schmidt, 1990)来估计统计检验力(Cohen,1988)。根据已有文献的报告数据(Wong & Chen,2008, 2009; Wong et al., 2012), 我们计算了Wong等研究中所得到的音节效应和音段效应的效果量Cohen d值。如表2所示, 音节效应的Cohen d均大于0.8, 效果量强, 而韵促进效应的Cohen d值均较小, 效果量很弱。本研究实验1所发现的音节促进效应与音段促进效应的 Cohen d值与已有研究相当。综合本研究以及已有研究的统计检验效果量Cohen d值的分析表明:音节确实在音韵编码中扮演了重要角色, 而音段(首音和韵)的促进效应虽然在统计上显著, 但效果量Cohen d值很小, 表明音段在汉语口语词汇产生中音韵编码阶段的作用可能相对较弱, 或者难以探测到。已有研究(Qu et al.,2012; Wong & Chen, 2008, 2009; Wong et al., 2012)所得出“音段可能是在汉语口语产生中音韵编码单元”的结论需要谨慎对待, 关于音段在口语产生中的作用及其机制需要进一步探索。

表2 粤语口语产生研究中的效果量Cohen d值
综上, 采用经典的图画-词汇干扰实验范式以及其与延迟命名和发音抑制任务的结合, 研究发现了音节和音段促进效应, 这些效应发生在口语产生中的音韵编码阶段; 在图画命名与延迟命名以及其与发音抑制结合的任务中发现了音节和音段抑制效应, 这些抑制效应可能发生在口语产生中的语音编码或发音阶段。音节和音段在音韵编码、语音编码和发音阶段的效应方向不同, 出现了分离的模式:在音韵编码阶段, 音节的促进效应强而音段的促进效应弱, 因此音节更可能是音韵编码过程加工的合适单元, 为合适单元假设提供了支持证据; 在语音编码和发音阶段, 音段的效应强而音节的效应弱, 这表明音段在运动执行过程可能起了相对重要的作用, 支持了口语产生中词汇表征准备阶段与运动阶段分离的观点。关于音段在口语产生中的作用及其机制需要进一步探索。
Baddeley, A. D., Lewis, V., & Vallar, G. (1984). Exploring the articulatory loop.Quarterly Journal of Experimental Psychology, 36A
, 233-252.Chen, J.-Y. (2000). Syllable errors from naturalistic slips of the tongue in Mandarin Chinese.Psychologia: An International Journal of Psychology in the Orient,43
(1), 15-26.Chen, J.-Y., Lin, W.-C., & Ferrand, L. (2003). Masked priming of the syllable in Mandarin Chinese speech production.Chinese Journal of Psychology, 45
(1), 107-120.Chen, J.-Y., Chen, T.-M., & Dell, G. S. (2002). Word-Form encoding in Mandarin Chinese as assessed by the implicit priming task.Journal of Memory and Language, 46
(4),751-781.Cohen, J. (1988).Statistical power analysis for the behavioral sciences
(2nd ed.). Hillsdale, NJ: Erlbaum.Dell, G. S. (1986). A spreading-activation theory of retrieval in sentence production.Psychological Review, 93
(3), 283-321.Dell, G. S. (1988). The retrieval of phonological forms in prodution: Tests of predictions from a connectionist model.Journal of Memory and Language, 27
, 124-142.Eickhoff, S. B., Heim, S., Zilles, K., & Amunts, K. (2009). A systems perspective on the effective connectivity of overt speech production.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences,367
(1896), 2399-2421.Ferrand, L., Segui, J., & Grainger, J. (1996). Masked priming of word and picture naming: The role of syllabic units.Journal of Memory and Language, 35
(5), 708-723.Ferrand, L., Segui, J., & Humphreys, G. W. (1997). The syllable’s role in word naming.Memory & Cognition, 25
(4),458-470.Hickok, G. (2012). Computational neuroanatomy of speech production.Nature Reviews Neuroscience, 13
, 135-145.Hickok, G. (2014). The architecture of speech production and the role of the phoneme in speech processing.Language,Cognition and Neuroscience, 29
(1), 2-20.Hickok, G., & Poeppel, D. (2007). The cortical organization of speech processing.Nature Reviews Neuroscience, 8
(5),393-402.Hunter, J. E., & Schmidt, F. L. (1990).Methods of meta-analysis:Correcting error and bias in research findings
. Newbury Park, CA: Sage.Kirk, R. E. (1996). Practical significance: A concept whose time has come.Educational and Psychological Measurement,56
(5), 746-759.Laganaro, M., & Alario, F. (2006). On the locus of the syllable frequency effect in speech production.Journal of Memory and Language, 55
(2), 178-196.Levelt, W. J. M., Roelofs, A., & Meyer, A. S. (1999). A theory of lexical access in speech production.Behaviroal and Brain Sciences,22
, 1-75.Levelt, W. J. M., Roelofs, A., Meyer, A. S., Helenius, P., &Salmelin, R. (1998). An MEG study of picture naming.Journal of Cognitive Neuroscience, 10
(5), 553-567Mahon, B. Z., Costa, A., Peterson, R., Vargas, K. A., &Caramazza, A. (2007). Lexical selection is not by competition:A reinterpretation of semantic interference and facilitation effects in the picture-word interference paradigm.Journal of Experimental Psychology: Learning, Memory, and Cognition, 33
, 503-535.Mehler, J., Dommergues, J. Y., Frauenfelder, U., & Segui, J.(1981). The syllable's role in speech segmentation.Journal of Verbal Learning and Verbal Behavior, 20
(3), 298-305.O'Seaghdha, P. G., Chen, J. -Y., & Chen, T. -M. (2010). Proximate units in word production: Phonological encoding begins with syllables in Mandarin Chinese but with segments in English.Cognition, 115
(2), 282-302.Qu, Q., Damian, M. F., & Kazanina, N. (2012). Sound-sized segments are significant for Mandarin speakers.Proceeding of the National Acadamy of Science of the United States of America, 109
(35), 14265-14270.R Core Team. (2013).R: A Language and Environment for Statistical Coputing
. R Foundation for Stastical Computing,Vienna, Austria, www.R-project.org.Roelofs, A. (1992). A spreading-activation theory of lemma retrieval in speaking.Cognition, 42
, 107-142.Roelofs, A. (1997). The WEAVER model of word-form encoding in speech production.Cognition, 64
(3), 249-284.Roelofs, A. (2014). Integrating psycholinguistic and motor control approaches to speech production: Where do they meet?Language, Cognition and Neurosicence, 29
(1), 35-37.Schiller, N. O. (1998). The effect of visually masked syllable primes on the naming latencies of words and pictures.Journal of Memory and Language, 39
(3), 484-507.Schiller, N. O. (2000). Single word production in English: The role of subsyllabic units during phonological encoding.Journal of Experimental Psychology: Learning, Memory,and Cognition, 26
(2), 512-528.Snyder, P., & Lawson, S. (1993). Evaluating results using corrected and uncorrected effect size estimates.Journal of Experimental Education,61
, 334-349.Wang, H., Liu, J., & Chang, B. R. (1986).Modern Chinese frequency dictionary
. Beijing, China: Beijing Language Institute Publisher.[王还, 刘杰, 常宝儒. (1986).现代汉语频率词典
. 北京: 北京语言出版社.]Wheeldon, L. R., & Levelt, W. J. M. (1995). Monitoring the time course of phonological encoding.Journal of Memory and Language, 34
(3), 311-334.Wong, A. W., & Chen, H. -C. (2008). Processing segmental and prosodic information in Cantonese word production.Journal of Experimental Psychology: Learning, Memory,and Cogntion, 34
(5), 1172-1190.Wong, A. W., & Chen, H. -C. (2009). What are effective phonological units in Cantonese spoken word planning?.Psychonomic Bulletin & Review, 16
(5), 888-892.Wong, A. W., Huang, J., & Chen, H. -C. (2012). Phonological units in spoken word production: Insights from Cantonese.PloS One, 7
(11), e48776.You, W. P., Zhang, Q. F., & Verdonschot, R. G. (2012). Masked syllable priming effects in word and picture naming in Chinese.PloS One, 7
(10), e46595.Zhang, Q. F. (2008). Phonological encoding in monosyllabic and bisyllabic Mandarin word production: Implicit priming paradigm study.Acta Psychologica Sinica, 40
(3), 253-262.[张清芳. (2008). 汉语单音节和双音节词汇产生中的音韵编码过程: 内隐启动范式研究.心理学报, 40
(3), 253-262.]Zhang, Q. F., & Yang, Y. F. (2003). The determiners of picturenaming latency.Acta Psychologica Sinica,35
(4), 447-454.[张清芳, 杨玉芳. (2003). 影响图画命名时间的因素.心理学报, 35
(4), 447-454.]Zhang, Q. F., & Yang, Y. F. (2005). The phonological planning unit in Chinese monosyllabic word production.Psychological Science, 28
(2), 374-378.[张清芳, 杨玉芳. (2005). 汉语单音节词汇产生中音韵编码的单元.心理科学, 28
(2), 374-378.]Zheng, H. M., Wen, Z. L., & Wu, Y. (2011). The appropriate effect sizes and their calculations in psychological research.Advances in Psychological Science, 19
(12), 1868-1878.[郑昊敏, 温忠麟, 吴艳. (2011). 心理学常用效应量的选用与分析.心理科学进展, 19
(12), 1868-1878.]
附录1:实验1-3中所使用目标图片的各项指标
