基于协议首部的字节频率统计特征发现方法
2015-01-06罗军勇
何 升,罗军勇,刘 琰
(数学工程与先进计算国家重点实验室,郑州450002)
基于协议首部的字节频率统计特征发现方法
何 升,罗军勇,刘 琰
(数学工程与先进计算国家重点实验室,郑州450002)
应用协议识别在网络安全领域具有极其广泛的应用,而如何发现协议特征是协议识别的核心问题。为此,提出一种高效准确的协议特征自动发现方法。利用协议自身的格式特点,将消息进行token化,并根据token序列对消息进行分类。由分类数的变化曲线大致判别协议的首部长度,从而确定字频统计的范围。对数据流中每个数据包的消息首部进行字节频率统计,并将字节频率进行归一化处理,得到字节频率特征向量。通过计算待测协议与样本协议的余弦相似度对协议进行分类和识别。实验结果表明,用该方法所提取的特征进行识别,准确率超过93.5%。
协议识别;token化;字节频率;特征向量;余弦相似度
1 概述
随着互联网技术的飞速发展,网络流量分类和应用协议识别对于复杂的网络活动来说越来越重要,例如入侵检测和防护系统、网络管理、流量建模仿真和流量监控等。传统的基于端口号的识别方法已经无法适用于现今的网络。而基于特征的识别方法可以避免由于基于端口的识别方法带来的不确定性,因此如何发现应用协议的特征得到了越来越广泛的关注。
现今主要的应用协议特征自动发现技术可以分为2类:一类是基于载荷的协议内容特征发现技术;另一类是基于流的协议统计特征发现技术。
基于载荷的协议内容特征发现技术准确性好,精度高,并且通常只需要较小的训练数据集和较短的训练时间就可以提取出精准的协议特征。但是,所提取的协议特征受协议名、版本号等因素影响,并不是所有的协议都能提取出区分度较高的协议特征。同样,该方法也无法提取加密协议的特征。
基于流的协议统计特征发现技术对同一个流中的包长度、包到达时间间隔和包数量等统计特征进行学习,从而训练出该协议的统计特征。该方法的优点在于不用关心协议具体的载荷内容,所提取的协议特征不受协议内容的变化而影响。但是由于训练数据的不稳定性和非广泛性,可能导致所提取的协议特征不具有代表性,精度不高。
结合上述2类方法的优点,本文提出一种协议统计特征自动发现方法。该方法利用协议报文格式的特点,估计协议首部的大致长度,对数据流中每个数据包的应用协议首部进行字节频率统计,得到字节频率特征向量,再通过余弦相似度对协议进行识别。
2 相关工作
在早期的基于载荷的手工提取特征方面,文献[1]将9种不同的特征应用到手工数据分类中,该方法包括端口号、数据包头和单个数据包载荷的前K个字节的特征等。这些工作都是通过深度分析数据包的应用层协议文档来获得协议特征的。
在基于协议载荷的内容特征方面,文献[2]通过有监督的机器学习方法来自动构建协议特征。采用Naïve Bayes,AdaBoost和RegularizedMaximum Entropy 3种机器学习算法提取7种应用协议特征,并将流量分类的特征发现范围缩小至64 Byte。但是随着协议版本的不断更新,重新训练特征又要付出高昂的代价。文献[3]提出了3种协议推理模型,基于统计的乘积分布模型、马尔科夫过和通用子串模图模型。协议模型用来捕获数据流交换过程中载荷内容的统计和结构化属性。这3种协议推理模型避免了训练集的预标记过程,可对原始多协议混杂并存的网络流数据进行聚类分析并输出协议特征。文献[4]采用基于内容的应用层最长公共子序列搜索来发现特征码,该算法尝试查找样本间最长公共子序列。该算法和文献[5]系统相似。最长公共子序列是从样本流中提取最长公共子序列作为协议特征的。该算法通过比较2个样本来获得最长公共子序列,然后再和其他样本循环比较来提纯特征。该方法受样本噪音和比较顺序影响。并且,当给定协议中存在多个公共子串时,生成特征将变得十分困难。文献[6]利用Apriori算法提取数据流前5个偏移数据包的应用层首部,自动提取9种应用协议特征,取得97%以上的字节识别精度,但是在处理方式上仍保留庞大的候选集和重复扫描数据等问题。
在基于统计属性的网络流量分类方面,文献[7]提出了使用EM算法,利用不同的特征将数据流分成簇。文献[8]提出了带核估计和FCBF的朴素贝叶斯分类器来分类流量。使用了一个巨大的包含248个特征的特征集,这些特征从TCP协议和数据包序列中统计获得。文献[9]使用贝叶斯定理训练的神经网络来提高准确率。文献[10]使用基于EM的AutoClass来学习训练数据集中内在的自然类别。文献[11]表明AutoClass的准确率高于有监督的贝叶斯,然而聚类能发现新的不明协议。文献[12]比较了3种聚类算法,而文献[13]提出了半监督学习的混合方法。这表明基于统计的流量分类器是可行而且有前途的。文献[14]提出了早期TCP流分类系统。核心思想是TCP三次握手后的带载荷的前几个数据包应该是应用协议的协商阶段,这几个包的载荷大小对于源协议也是很好的预测。文献[15]提出了统计的协议指纹,它利用高斯过滤的PDF来描述流的3个属性:包大小,内部包时间和到达顺序。
3 字节频率统计特征发现方法
3.1 方法描述
基于协议首部的字节频率统计特征发现方法主要分为5个部分:首先对消息载荷进行token化,利用token序列对消息进行分类,利用载荷长度与分类数的变化关系估计协议首部长度,然后对协议首部进行字节频率统计,将统计结果归一化处理生成特征向量,最后得到协议特征。
基于协议首部的字节频率统计特征发现流程如图1所示。

图1 特征发现流程
3.2 token化
对token给出相关定义如下:
定义1(token) 消息载荷中可能属于同一格式字段的,一个或多个连续的字节。
定义2(文本token) 满足一定长度的,位于2个ASCII码非可打印字符之间的,多个连续的ASCII码可打印字符组成的token。
定义3(二进制token) 单个的二进制字节,且不能和任何相邻的文本token组合成新的文本token。
消息载荷的token化过程,即将消息载荷切割成由token组成的序列,并且区分文本token和二进制token的过程。在执行消息载荷的token化过程时,需要将载荷中的字节进行逐个判定,若为ASCII码非可打印字符,则直接将该字节判定为二进制token,记为B;若为ASCII码可打印字符,则将该字符存入临时token,并继续扫描后续字符。当后续字符中出现ASCII码非可打印字符时,判断临时文本token的长度,如果满足最小文本token长度,则将临时文本token中的连续的ASCII码可打印字符判定为文本token,记为T,如果不满足最小文本token长度,则临时token中的所有ASCII码可打印字符均视为单个的二进制字符。
消息载荷的token化过程即将消息载荷的前K个字节切割成文本和二进制token的过程。消息载荷的token化过程结束后,每个消息被切割成了以B和T构成的token序列,例如:“{BTBTBBTB BTBT}”,为基于token序列的消息分类做准备。
3.3 消息分类
经过了消息载荷的token化的过程,同一个会话流中的每一个消息都得到了一个与之相对应的token序列。消息分类即根据消息的token序列来对同一会话流中的消息进行分类,将token序列相同的消息归为一类,这里称为簇(Cluster),簇中包含的消息个数即为簇的长度。由于token序列实际上反映的是协议格式的一种属性,而同种协议的格式是相对固定的,所以得到相同的token序列应该居多,即每个簇的长度应该较长。因此,对于每个簇的生成,用最小簇长进行限制,如果产生的簇中的消息数目小于最小簇长,那么丢弃该簇以及簇中的消息。这是由于token化时产生的误差可能得到并不能正确反映协议格式的token序列,而这样的token序列应该是较少的,且并不相同,因此通过最小簇长可以将这些误差产生的token序列进行过滤。
3.4 协议首部长度估计
通过对常见的应用协议格式进行分析,将应用协议按照格式的不同分为文本协议和二进制协议。文本协议的协议内容为文本类型,例如可读的ASCII可打印字符。文本协议一般没有固定的协议首部,协议内容是基于命令的文本段,因此各个字段也没有固定的偏移位置和长度。常见的文本协议有: HTTP,SMTP和FTP等。二进制协议区别于文本协议,其内容是不可读的二进制字符。二进制协议大多具有固定的协议首部,其协议首部中的内容符合协议文档的严格规定,因此,首部中各个字段的偏移位置和长度都应该是固定的。常见的二进制协议有:DNS,OICQ和SMB等。
对于二进制协议,由于同种协议的首部长度固定,首部长度以内的字节取值受协议格式的严格限制,字节取值范围较小。因此,当偏移长度的取值小于头部长度时,随着偏移长度的增大,根据token序列得到的簇数应该基本保持不变。当偏移长度的取值超过头部长度,进入消息的数据部分后,由于数据部分的内容由用户来决定,那么取值将变得多种多样,所得到的分类数将随着偏移长度的增加而急剧增加。通过偏移长度的取值和簇数的关系可以判别出该协议大致的首部长度。
图2显示了OICQ协议的偏移长度与簇数的关系。
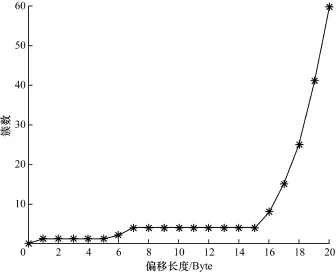
图2 OICQ的偏移长度与簇数的关系
对于文本协议,由于没有固定长度的首部,这里考虑文本协议的近似首部长度作为统计的范围。分类数的取值随偏移长度取值的增长而增长,而当偏移长度的取值接近于近似首部时,簇数的增长速率应该是最快的。对于同种文本类协议,利用不同的偏移长度取值和其对应的分类数作为二维坐标图上的离散点,将这些离散点相连并拟合成连续的曲线,得到曲线函数:

通过对曲线函数进行二次求导:

求出二阶导数的零点,并进一步分析判断得到一阶导数的极值点,进而得到簇数增长最快的点,从而判别出该协议的近似首部长度。图3显示了HTTP协议的偏移长度与簇数的关系以及拟合后得到的曲线函数。
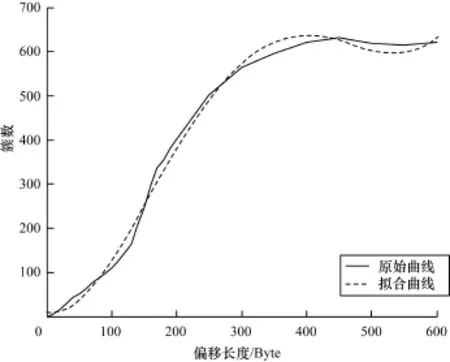
图3 HTTP的偏移长度与簇数的关系
3.5 字节频率统计
用于生成特征的训练数据是经过预先标注的数据流的集合。由于训练用到的都是已知协议的数据,因此利用数据包捕获软件wireshark,可以预先分类得到协议数据流。每个流中的数据包不仅应具有相同的五元组,即源IP、目的IP、源端口、目的端口和协议,还应该是在同一时间段内捕获到的,并且带有应用层的载荷数据。
对于一个特定的协议数据流的集合,利用判别出的协议近似首部长度,对这若干个流中的所有消息载荷的近似首部进行字节频率统计,统计256个字符出现的次数(ASCII码是从0x00~0xFF)。图4为HTTP协议的字节频率统计分布图。
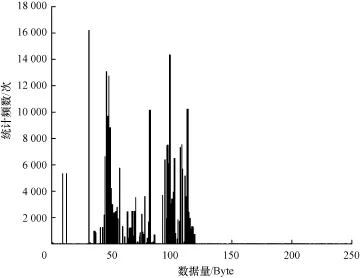
图4 HTTP协议字节频率统计分布
3.6 特征向量归一化
为了对字节频率分布的统计特征加以利用,这里采用向量的形式对其进行描述。因为向量具有方向特性,所以将每种协议的字节频率分布转化为相应的256维的字节频率向量,那么每种协议将各自呈现出不同的方向特征。为了方便计算,将向量进行归一化处理,每个分量同时除以向量的模长,向量的方向不变,得到的归一化后的向量即为协议的字节频率特征向量。
4 基于余弦相似度的应用协议识别
定义4(余弦相似度) 通过测量2个向量内积空间夹角的余弦值来度量的相似度。
余弦相似度可以用在任何维度的向量比较中,尤其在高维的正空间中的利用尤为频繁。例如在信息检索中,余弦相似度被广泛用于测量2个文本之间的相似度。
本文将余弦相似度应用于测量协议特征库中的已知协议与待测的目标协议的相似度,进而判断2个协议是否为同种协议。类似于文本相似度的计算,这里的词频向量即协议的字节频率特征向量。
余弦相似度计算公式如下:

其中,A代表已知协议的字节频率向量;B代表未知协议的字节频率向量;n表示向量的维数,n取256。判定未知协议和已知协议是否是同种协议,需要分别计算出2个协议的字节频率向量A,B,然后计算A和B的余弦相似度,如果计算出的余弦相似度达到了设定的相似度阈值,则认为未知协议与已知协议为同种协议。相似度阈值的设定通过训练得到。
5 实验结果与分析
特征提取过程将已知协议的字节频率向量进行提取并且保存入特征数据库。测试时对测试数据中的每个数据流进行字节频率向量提取,通过和特征数据库中的特征向量进行比对,如果2个特征向量的余弦相似度满足相似度阈值,则将测试协议判定为特征库中的已知协议。
5.1 数据集
本文实验所用数据一部分来自网上公开的网络流量数据集MACCDC 2012,另一部分从单机网络环境采集获得。实验数据共包含5种常见协议,其中3种为二进制类的协议(OICQ,DNS和SMB),另外2种为文本类的协议(HTTP和SMTP)。实验数据一共包含了7 022条数据流,共计1.6 GB的网络流量。将采集得到的数据集分为训练集和测试集2个部分。训练集用来进行特征提取和对相似度阈值进行训练,测试集则用来识别。
5.2 评价指标
对于识别结果的评价标准,本文采用漏报率(FNrate)、误报率(FPrate)和总准确率(Overall Accuracy)3项指标来综合评价所提取特征的质量。设数据总量为N,将数据分为目标协议与非目标协议2类,定义如表1所示。

表1 评价指标的定义
记漏报率为FNr,误报率为FPr,总准确率为OA,则有:

5.3 实验结果
5.3.1 协议首部长度
协议首部长度判别结果如表2所示。

表2 协议首部长度判别结果Byte
OICQ协议和DNS协议的估计首部长度都比实际首部长度多出了几个字节,那是因为OICQ和DNS的数据字段的开始部分都有几个固定的字节值,导致算法将这几个本属于数据字段的字节判定成了协议首部,因此估计的首部长度要比实际的首部长度略长。HTTP协议和SMTP协议没有固定的首部长度,用近似首部长度代替协议首部长度可以大大避免用户数据的随机性对实验结果的干扰。
5.3.2 Threshold的训练
为了选取合适的Threshold,使得漏报率和误报率都能得到较为理想的值,这里通过训练得到相似度阈值与准确率的关系,如图5所示。

图5 相似度阈值与准确率的关系
如图5所示,随着相似度阈值的增大,5种协议的总准确率均呈现先上升后下降的趋势。如图中竖虚线处所示,当相似度阈值取0.86时,5种协议的总准确率较高。
5.3.3 协议识别结果
协议识别结果如表3所示。
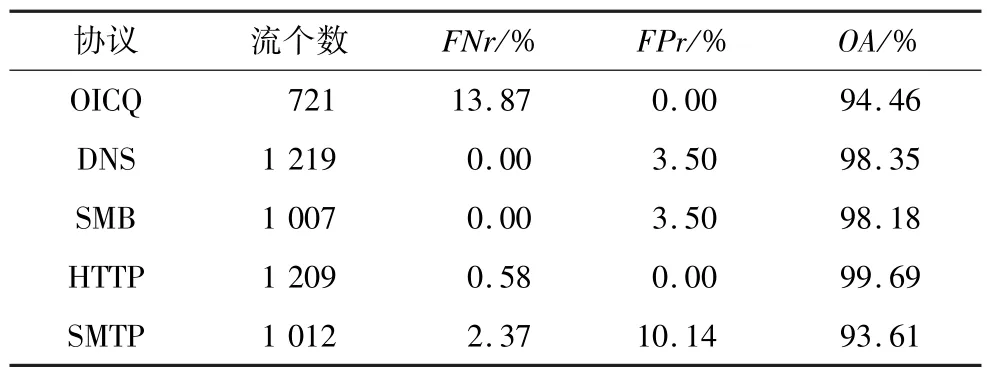
表3 协议识别结果
从实验结果可以看出,DNS,SMB和HTTP的总准确率均在98%以上,结果较为理想。OICQ的漏报率较高,是由于OICQ的协议数据是单机环境人工采集获得,所以协议数据可能由于人工采集的失误导致纯度不高,致使漏报率较高。SMTP协议由于其自身的协议规范要求,协议中带有大量的用户邮件内容,导致了误报率较高。总体来看,5种协议的总准确率均在93.5%以上,这也说明了本文方法的有效性和准确性。
6 结束语
协议识别在入侵检测、网络防火墙和网络监控等领域具有越来越广泛的应用,而协议特征发现作为协议识别的核心问题也倍受关注。本文提出了一种高效准确的协议流统计特征自动发现方法。利用协议自身的格式特点,通过对报文进行token化得到token序列,利用token序列进行分类后,根据分类数和所截取载荷长度的关系判别出协议首部的大致长度;通过对数据流中每个数据包的应用协议首部进行字节频率统计,得到字节频率特征向量;再通过计算已知协议与未知协议特征向量的余弦相似度进行协议识别。通过对OICQ,DNS, SMB,HTTP和SMTP 5种协议进行实验验证,识别准确率均超过了93.5%,实验结果验证了该方法的有效性和准确性。
[1] Moore A W,PapagiannakiK.TowardtheAccurate IdentificationofNetworkApplications[C]// Proceedings ofthe 6thInternationalWorkshopon PassiveandActiveNetworkMeasurement.Berlin, Germany:Springer,2005:41-54.
[2] Haffner P,Sen S,Spatscheck O,et al.ACAS:Automated ConstructionofApplicationSignatures[C]// Proceedings of ACM SIGCOMM Workshop on Mining Network Data.[S.l.]:ACM Press,2005:197-202.
[3] Ma J,Levchenko K,Kreibich C,et al.Unexpected Means of Protocol Inference[C]//Proceedings of the 6thACMSIGCOMMConferenceonInternet Measurement.[S.l.]:ACM Press,2006:313-326.
[4] Park B C,Won Y J,Kim M S,et al.Towards Automated ApplicationSignatureGenerationforTraffic Identification[C]//Proceedings of Network Operations and Management Symposium.[S.l.]:IEEE Press, 2008:160-167.
[5] Newsome J,Karp B,Song D.Polygraph:Automatically Generating Signatures for Polymorphic Worms[C]// ProceedingsofIEEESymposiumonSecurityand Privacy.[S.l.]:IEEE Press,2005:226-241.
[6] 刘兴彬,杨建华,谢高岗,等.基于Apriori算法的流量识别特征自动提取方法[J].通信学报,2009,29(12): 51-59.
[7] McGregor A,Hall M,Lorier P,et al.Flow Clustering Using MachineLearningTechniques[M].Berlin, Germany:Springer,2004:205-214.
[8] Moore A W,Zuev D.InternetTrafficClassification UsingBayesianAnalysisTechniques[J].ACM SIGMETRICS Performance Evaluation Review,2005, 33(1):50-60.
[9] Auld T,MooreAW,GullSF.BayesianNeural Networks for Internet Traffic Classification[J].IEEE Transactions on Neural Networks,2007,18(1):223-239.
[10] Zander S,Nguyen T,Armitage G.Automated Traffic ClassificationandApplicationIdentificationUsing MachineLearning[C]//Proceedingsofthe30th Anniversary Conference on Local Computer Networks. [S.l.]:IEEE Press,2005:250-257.
[11] Erman J,Mahanti A,Arlitt M.Qrp05-4:Internet Traffic Identification Using Machine Learning[C]//Proceedings of Global Telecommunications Conference.[S.l.]:IEEE Press,2006:1-6.
[12] Erman J,Arlitt M,Mahanti A.Traffic Classification UsingClusteringAlgorithms[C]//Proceedingsof SIGCOMM Workshop on Mining Network Data.ACM Press,2006:281-286.
[13] Erman J,Mahanti A,Arlitt M,et al.Semi-supervised Network Traffic Classification[J].ACM SIGMETRICS Performance Evaluation Review,2007,35(1):369-370.
[14] Bernaille L,Teixeira R,Akodkenou I,et al.Traffic Classification on the Fly[J].ACM SIGCOMM Computer Communication Review,2006,36(2):23-26.
[15] Crotti M,Dusi M,Gringoli F,et al.Traffic Classification Through Simple Statistical Fingerprinting[J].ACM SIGCOMM Computer Communication Review,2007, 37(1):5-16.
编辑 顾逸斐
Feature Discovering Method of Byte Frequency Statistics Based on Protocol Header
HE Sheng,LUO Junyong,LIU Yan
(State Key Laboratory of Mathematical Engineering and Advanced Computing,Zhengzhou 450002,China)
Application protocol identification is widely applied in network security and the key problem of the protocol is how to discover the protocol feature.This paper proposes an efficient and precise method to automatically discover the protocol feature.The method takes advantage of the feature of protocol format to token the message,classify the messages according to the token sequence,and generally discriminate the protocol header length by change curve of classification number.Thus determine the scope of the word frequency statistics.The byte frequency of each data packet message header in data stream is counted and dealt under normalization.It gets the byte frequency vector of the protocol header,and utilizes the cosine similarity by calculating measured protocol and sample protocol to classify and identify the protocol. Experimental result shows that it has a high accuracy over 93.5%using the signature extracted by this method.
protocol identification;tokenization;byte frequency;feature vector;cosine similarity
何 升,罗军勇,刘 琰.基于协议首部的字节频率统计特征发现方法[J].计算机工程,2015,41(2): 272-277.
英文引用格式:He Sheng,Luo Junyong,Liu Yan.Feature Discovering Method of Byte Frequency Statistics Based on Protocol Header[J].Computer Engineering,2015,41(2):272-277.
1000-3428(2015)02-0272-06
:A
:TP301.6
10.3969/j.issn.1000-3428.2015.02.052
国家自然科学基金资助项目(61309007);国家“863”计划基金资助项目(2012AA012902)。
何 升(1989-),男,硕士研究生,主研方向:信息安全;罗军勇,教授;刘 琰,副教授、博士。
2014-03-13
:2014-04-14E-mail:sniperhs@sina.com
