一种面向海量中文文本的典型类属关系识别方法
2015-01-06肖仰华
刘 琦,肖仰华,汪 卫
(复旦大学计算机科学技术学院,上海201203)
一种面向海量中文文本的典型类属关系识别方法
刘 琦,肖仰华,汪 卫
(复旦大学计算机科学技术学院,上海201203)
传统基于文本的类属关系自动抽取算法只简单记录关系出现的位置、频次等信息,而忽略了大量上下文信息,不能有效辨识典型类属关系。为此,提出一种面向互联网文本典型类属关系的识别方法。通过提取实体概念的语言学特征和上下文语义特征构成实体特征集,基于朴素贝叶斯分类器,计算任意实体属于不同概念的可能性,从而识别典型类属关系。实验结果证明,与基于频率的识别方法相比,该方法能将典型类属关系的识别准确率提高5%以上。
中文知识库;类属关系;关系抽取;典型性;模式识别;朴素贝叶斯
1 概述
构建知识库是理解中文语义的前提,其中类属关系是最基本的关系之一。在知识库中,一个实体通常会属于多个概念。在实际使用时,需要给出一个实体最合理的概念,因此对这些概念加以排序是十分必要的。比如,对于“中国”,它类属于“国家”、“市场”和“古国”这3个概念的典型性逐渐减小。基于海量互联网文本抽取的类属关系具有频次信息,通常用来衡量该类属关系是否较同一个实体的其他类属关系更典型。本文通过综合考虑类属关系的多维特征,结合语言学特征和实际上下文特征来辨识典型类属关系。
2 相关工作
类属关系的抽取是一种典型的关系抽取任务,相关方法分为:(1)人工抽取,如WordNet[1], HowNet[2];(2)基于百科网页中的结构化[3]、半结构化文本抽取[4-5];(3)基于非结构化文本使用模式识别[6-7]的方法抽取[8]。众多国内外基于文本自动构建的知识库YAGO[9],Probase[10]等都把实体概念的共现频率作为类属关系是否准确的一个重要指标。Probase中提出类属关系的合理性和典型性。利用类属关系出现的多种信息(比如网页的Pagerank值、模式的可靠性等)来推断其合理性,而用类属关系的频率和层次性来判断其典型性。
通过考查汉语的构词法和概念的形成过程,笔者认为影响类属关系典型性的因素,除了实际使用语境中的统计规律之外,还包含类属关系自身的语言学特征。本文将结合语言学特征和实际上下文来识别典型类属关系。
3 类属关系识别算法框架
图1给出中文类属关系的识别算法框架:从互联网文本中抽取类属关系和实体特征,利用朴素贝叶斯模型计算类属关系的典型性。互联网文本经过Html解析、断句等预处理被加入到语料库中。从语料库中利用顿等模式抽取同类词集,利用类属模式同时抽取类属关系集和背景词集。同类词集、类属关系集和背景词集共同构成实体的上下文特征集。从类属关系集中解析出实体集和概念集。提取全部实体的语言学特征,和上下文特征一起构成实体的特征集。如图1中虚线部分所示,利用朴素贝叶斯分类器的思想,计算任意实体属于每个概念的可能性,提取典型的类属关系。

图1 类属关系识别算法框架
4 特征提取
对实体进行特征提取,是为了建立实体到特征再到概念的映射。特征分为2类:一类是语言学特征;另一类是上下文特征。
4.1 语言学特征
实体的语言学特征主要包含4个特征,分别是字特征、偏旁特征、词特征和词性特征。
(1)字特征是实体用字构成的集合。汉语中一些概念会形成特有的用字习惯。比如“学校”的命名中包含“小”、“中”、“大”,分别表示小学、初中、大学等。
(2)偏旁特征是由构成实体的每个字的偏旁构成。比如“苹果”的偏旁特征就是{艹,木}。现代汉语超过80%的字是形声字,而形声字的偏旁(义符)能够揭示其本身概念的比例占83%[11]。
算法1 实体用字特征和偏旁特征的获取算法
输入实体库,部首对照表
输出实体对应的字特征和偏旁特征

(3)词特征是实体最细粒度的分词结果。比如“红苹果”的词特征就是{红苹果}。复合名词通常包含表示重要语义特征的词。比如“番茄炒蛋”中的“炒”字就与菜名具有很强的关联。很多复杂的专业术语(比如化合物名字等)同样具有明显的词特征。
(4)词性特征是对词特征的词性标注。复合名词在命名时遵循一定规则,如在命名公司、酒店等机构时,常会包含地名ns、人名nr等词性。上海[/地名]某科技有限公司、北京[/地名]宋庆龄[/人名]基金会。地名、人名等词性与机构等实体的关联性很强。
算法2 实体用词特征和词性特征的获取算法
输入实体库,分词词典
输出实体对应的词特征和词性特征

4.2 上下文特征
上下文特征是从文本中提取的特征,包括同类词特征、概念集。
(1)同类词特征是指在实体在某一概念上的同位词,在语言学中叫做对义词。在汉语中,顿号的最主要用法是罗列某一概念下的同类词。同类词属于同一概念的可能性很大。比如,“中国、美国、法国等联合国常任理事国”中的“中国”、“美国”和“法国”。定义这种由顿号和等连接的句子模式叫“顿等模式”(见表1中的ID1和ID2对应的模式)。表1中的匹配模式借鉴英文中的Hearst Patterns[12]。匹配模式中E,Ei(i=1,2,…)表示实体,是一个名词词组;C表示概念,一般为一个简单名词,也可以是名词词组;“[]”中的内容表示任选一项;“∗,”和“?”为正则表达式的常见符号。

表1 匹配模式
(2)概念集特征是指实体所属的所有概念。概念之间具有包含、相似、等同等多种联系,这种联系表现在同一个实体可以属于多种概念。这些概念组成的集合本身也是这个实体的特征。
比如兰花的所属概念集为{花卉植物花}。当要判断“兰花是植物”的典型性时,{花卉花}这个特征可以增强这种典型性。因为从兰花到花卉(花)再到植物存在一个很强的关联关系,类属关系的典型性因为这种关联而得以增强。
背景词特征是指类属关系存在的句子中其他名词构成的集合。利用与类属关系经常出现的名词特征可以更好地识别典型类属关系。比如“中国是世界上最大的发展中国家”。<中国国家>是一个类属关系,背景词特征就是{世界}。在提及“世界”的语境中,“国家”这个概念出现的频率要比没有提及“世界”的语境中高得多。
算法3 实体上下文特征的获取算法
输入中文数据集,中文类属关系模式
输出类属关系集,同类词集,背景词集

由于互联网文本数据巨大,一个实体的上下文特征中会有大量同类词、背景词等,导致特征抽取效率不高,而且噪音信息很多。因此,每个实体的上下文相关的3种特征中,只选取其中频率最高的100项。
5 概率模型
问题定义令P(C|E)表示实体E属于概念C的可能性。给定类属关系集G。求典型类属关系可以表示为:
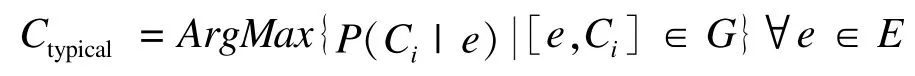
根据朴素贝叶斯分类器的原理,在只考虑一维特征F的情况下,判断给定实体E属于概念C的可能性为:

其中,实体E具有特征F;P(C|F)表示根据实体具有的特征F判断实体属于概念C的概率;P(C)表示概念出现的先验概率;P(F)表示特征出现的先验概率,与实体概念的共现没有任何关系,在实体概念对中,把实体用相应的特征序列替换,那么就构建了一个特征-概念的联合分布空间;P(F|C)表示在这个联合空间中,特征对概念的条件分布。
本文使用证据叠加的方法来融合各特征对类属典型性关系的影响。每个特征对典型性的影响用后验概率来表示。第4节中针对每个实体提出两大类七小类特征。对于一个概念下的所有实体,可以提取一个很大的特征集,这个特征集同样包含七小类特征。

对于概念C和小类特征Fi,设,利用证据叠加的方法,采用式(3)确定小类特征对E属于C的典型性。

如果按照顺序把七小类特征编号为F1~F7,则得到式(4):

采用概率相加而不是相乘的主要原因有3个: (1)由于概率本身很小,7(n个概率相乘容易导致计算机中结果为0,使得结果不具有可比性。(2)从直观上来说,证据越多,概率越大,而相乘使得特征越多,绝对大小反而越小。(3)相乘容易受特殊情况影响,一个极小值导致最终概率很小。而相加的模型对异常情况就很稳定。由于最后比较的是相对值,因此式(3)中无需对概率归一化。
算法4 最典型类属关系的获取算法
输入类属关系集EC,实体特征集EF
输出最典型的类属关系集

算法4中的F_top(Ci,n)是从每个小类特征中选出topn作为该概念的典型特征。最后的融合结果P(Ci|E)按照式(4)进行计算。本节中的P(C|E)不是严格的概率,而是基于概率的一种度量。
6 实验结果与分析
6.1 实验语料
实验采用3个数据集card,full和mcr,它们分别来自百度百科的百科名片、百科正文和从互联网上爬取的富文本网页,其大小和提取的候选类属关系数量如表2所示。每条类属关系都统计了在数据集中出现的次数。实验目的是比较用不同方法从全部的类属关系中识别出最典型类属关系的准确率。

表2 数据集
6.2 评测方法
实验的目的是比较4种方法,分别是按照出现频次的基本方法(Fq)、基于语言学特征的概率方法(M1)、基于上下文特征的概率方法(M2)和融合两大类特征的方法(M3)辨识典型常识关系的准确率。
Fq方法是直接从算法3的类属关系中选出与某个实体相关的频次最高的概念作为最典型类属关系。其他3种方法均按完整的算法框架计算,不同的是在选择小类特征上,M1只选取F1~F4,M2只选取F5~F7,而M3选取了全部的F1~F7。
为研究模型受参数n值变化的影响,选取n= 10,20,50,100,200,500,1000,1000 000。n= 1000 000时的情况相当于采用所有特征,不预先做任何特征筛选。
为比较4种方法的差异,实验中选取满足下面条件的类属关系<E,C>作为测试集:
(1)在4种方法的结果中E都有对应的典型类属关系;
(2)并且E对应的概念C在4种方法中不完全相同。
根据实验目的,对每个测试集,选取1000条类属关系进行人工标注。实验数据统计如表3所示。
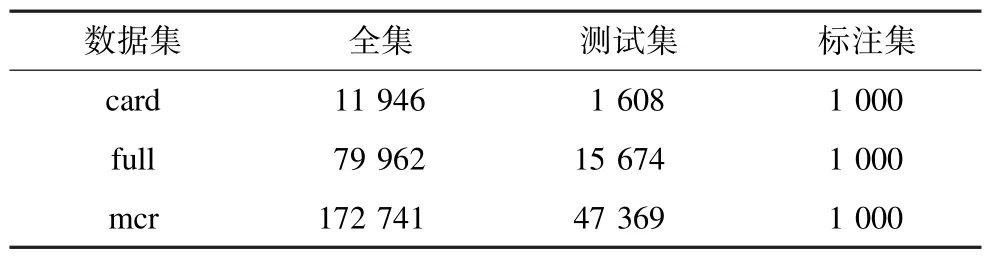
表3 标注集
在标注过程中采用以下原则:
(1)按照通用性来标注,只有最通用的类属才认为符合常识。比如,<上海,城市>是常识,而<上海,地区>不是。因为城市更符合常识,而地区不是。
(2)不能对概念进行任意扩展。比如<上海,车站>就不是常识。虽然上海经常出现在车站列表中,而实际上它只是“上海站”的一个缩写。
(3)概念不能具有相对性。“原料”、“代表作”等相对概念不能成为典型类属关系的概念部分。例如,在常识知识库中,<《八骏全图》,画作>是正确的。而<《八骏全图》,代表画作>就不准确,因为“代表画作”是一个相对概念,<《八骏全图》,代表画作>是一个不准确的类属关系。
这样符合常识的类属关系得分为1,不符合的得分为0。每个模型的最后得分为1000条类属关系的平均分。
6.3 结果分析
图2对比了各种模型在3个数据集下的实验结果。横轴表示模型参数n,纵轴表示典型类属关系准确率。对比Fq方法,可以看到M1,M2和M3都有明显的提升效果,这证明在取适当n的情况下,语言学特征的应用和上下文特征都是有效的。在最好的情况下,M1,M2和M3都有约5%的提升。
对比图2(a)、图2(b)、图2(c)中的M1方法发现,语言学特征的作用随着n值得增大先增加后趋缓,而且在n很小时都很差,说明语言学特征分布比较均匀,需要考虑尽可能多的语言学特征。

图2 各方法在不同数据集上的准确率比较
在图2(a)中,M2方法在n值增大的情况下准确率开始下降,说明在数据量较小的情况下上下文特征不稳定且容易产生噪声,这时n应该取较小的10。而在图2(b)、图2(c)中M2都在n=100附近取得较大值,说明在数据量较大的情况下,并非利用的上下文特征越多越好,而是需要根据数据量选定适当的n值(如100)。
而当综合利用语言学特征和上下文特征后,可以看到M3的表现是比较稳定的,而且最优值也是M3取得的。随着n值的增加,准确率逐步增加,直到趋稳,数据集对它性能的扰动较小。
综合来看,特征属性并不是越多越好,而要与数据集相适应,在实际应用中可以通过实验确定最佳n值。随着知识库的体量增大和数据集的增加,语言学特征会逐渐增多,这时选择适当数量的属性就很必要,因为很多特征并不具有代表性。而且选择适当大小的n值可以提高算法效率。
7 结束语
本文在典型类属关系的识别过程中,利用实体本身的语言学特征以及类属关系所处的上下文特征,提高识别准确率。在选取特征时,需要选取分布相对松散的语言学特征以及分布集中的上下文特征。下一步工作重点是添加更丰富的特征到识别模型中以提高模型识别性能。
[1] Fellbaum C.WordNet:AnElectronicLexicalDatabase[M].[S.l.]:MIT Press,1988.
[2] Dong Z,Dong Q.HowNet[EB/OL].[2013-12-17]. http://www.keenage.com/zhiwang/e_zhiwang.html.
[3] Yan Yulan,Okazaki N,Matsuo Y,et al.Unsupervised Relation Extraction by Mining Wikipedia Texts Using Information from the Web[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4thInternationalJointConferenceonNatural Language Processing of the AFNLP.Stroudsburg,USA: Association for Computational Linguistics,2009:1021-1029.
[4] Wang Jingjing,Wang Haixun,Wang Zhongyuan,et al. Understanding Tables on the Web[C]//Proceedings of the31stInternationalConferenceonConceptual Modeling.Berlin,Germany:Springer-Verlag,2012: 141-155.
[5] Niu Xing,Sun Xinruo,Wang Haofen,et al.Zhishi. me——Weaving Chinese Linking Open Data[C]// Proceedings of the10th International Semantic Web Conference.Bonn,Germany:Springer-Verlag,2011: 205-220.
[6] Ramakrishnan C,Kochut K J,Sheth A P.A Framework for Schema-driven Relationship Discovery from Unstructured Text[C]//Proceedings of International Semantic WebConference.Berlin,Germany:Springer-Verlag, 2006:583-596.
[7] Wong W,Liu Wei,Bennamoun M.Acquiring Semantic Relations Using the Web for Constructing Lightweight Ontologies[C]//Proceedings of the13th Pacific-Asia Conference on Knowledge Discovery and Data Mining. Berlin,Germany:Springer-Verlag,2009:266-277.
[8] Miner G,Elder J,Hill T,et al.Practical Text Mining and StatisticalAnalysisforNon-structuredTextData Applications[M].[S.l.]:Academic Press,2012.
[9] Suchanek F M,Kasneci G,Weikum G.Yago:A Core of Semantic Knowledge[C]//Proceedings of the16th International Conference on World Wide Web.New York, USA:ACM Press,2007:697-706.
[10] Wu Wentao,Li Hongsong,Wang Haixun,et al.Probase: A Probabilistic Taxonomy for Text Understanding[C]// Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data.New York,USA: ACM Press,2012:481-492.
[11] 王 宁.汉语字词的结构与意义[M].济南:山东教育出版社,1997.
[12] Hearst M A.Automatic Acquisition of Hyponyms from Large Text Corpora[C]//Proceedings of the14th Conference on Computational Linguistics.Stroudsburg, USA:Association for Computational Linguistics,1992: 539-545.
编辑 陆燕菲
A Recognition Approach of Typical Generic Relationship for Massive Chinese Text
LIU Qi,XIAO Yanghua,WANG Wei
(School of Computer Science,Fudan University,Shanghai 201203,China)
In a usual way for automatic generic relation extraction from texts,only some simple information,such as positions and frequency are recorded.And enormous context information is ignored,which is very helpful to recognize typical relationship.A new approach is proposed to recognize typical generic relationship from candidates extracted Internet texts.Abundant semantic information is kept while relations are captured.It integrates both natural language features of entities and concepts to constitute a entity feature set,calculates the possibility of any entities belong to different concepts based on naïve Bayesian,and recognizes typical generic relationship.Experimental result proves,as for judging whether a generic relation is typical,compared with the frequency-based recognizing method,the method improves the recognition accuracy by more than 5%.
Chinese knowledge base;generic relationship;relationship extraction;typicality;pattern recognition; naive Bayesian
刘 琦,肖仰华,汪 卫.一种面向海量中文文本的典型类属关系识别方法[J].计算机工程, 2015,41(2):26-30.
英文引用格式:Liu Qi,Xiao Yanghua,Wang Wei.A Recognition Approach of Typical Generic Relationship for Massive Chinese Text[J].Computer Engineering,2015,41(2):26-30.
1000-3428(2015)02-0026-05
:A
:TP391
10.3969/j.issn.1000-3428.2015.02.006
国家自然科学基金资助项目(61003001,61170006,6117132,61033010)。
刘 琦(1988-),男,硕士研究生,主研方向:数据抽取,自然语言处理;肖仰华,副教授;汪 卫,教授、博士生导师。
2014-03-11
:2014-04-05E-mail:zerup123@gmail.com
