一种临时私有云中逻辑拓扑感知的作业调度算法
2015-01-06赵玉艳陈海宝赵生慧
赵玉艳,陈海宝,2,赵生慧
(1.滁州学院计算机与信息工程学院,安徽滁州239000;2.华中科技大学计算机科学与技术学院,武汉430074)
一种临时私有云中逻辑拓扑感知的作业调度算法
赵玉艳1,陈海宝1,2,赵生慧1
(1.滁州学院计算机与信息工程学院,安徽滁州239000;2.华中科技大学计算机科学与技术学院,武汉430074)
考虑到成本和灵活性等因素,利用公共云计算系统的资源构建临时私有云代替本地物理集群,已成为用户在特定时间段内处理大量并行作业的一种有效途径。然而现有作业调度算法不能感知并利用临时私有云的逻辑拓扑结构,容易降低紧耦合并行应用的性能。为解决该问题,提出一种逻辑拓扑感知的作业调度算法,根据私有云中虚拟机之间的带宽和延迟等信息构建逻辑拓扑关系,并综合考虑用户所提交作业的类型,进而产生对应的作业调度决策。实验结果表明,该算法在提高临时私有云中紧耦合并行应用性能方面优于开源云计算系统中常用的轮转算法和随机算法。
临时私有云;并行应用;虚拟机;拓扑结构;调度算法;网络性能
1 概述
随着虚拟化和云计算的快速普及和发展,在公共云计算系统中构建临时私有云(也称为虚拟集群)来替代本地物理集群,已成为用户在特定时间段内处理大量并行作业(如基于消息传递接口(Message Passing Interface,MPI[1])的并行应用程序)的有效途径。在创建临时私有云后,用户如同操作本地物理集群一般操作临时私有云,使用作业调度系统管理作业调度。临时私有云给用户带来的好处具体有:(1)不需要用户对基础设施进行前期投资和运维;(2)提供可定制的应用运行环境;(3)按使用付费。
在一般情况下,运行环境中的网络拓扑对紧耦合并行应用(也就是进程之间需要频繁通信和同步的并行应用)的性能有着重要影响[2-3]。传统的物理集群环境中,在网络基础设施建设完成后,计算节点之间的拓扑结构是固定的。然而,在临时私有云环境中,虚拟机之间的网络性能以及逻辑拓扑结构却是多变且未知的[4],这主要归因于云计算基础设施供应商(例如Amazon EC2,阿里云等)在为用户提供临时私有云时,根据供应商自身的调度策略来放置和迁移虚拟机,并且对用户屏蔽了上述信息。在这种情况下,已有的作业调度算法因不能够感知并利用临时私有云的逻辑拓扑结构,容易造成紧耦合并行应用(也就是进程之间需要频繁的通信和同步的并行应用)的性能降低。针对该问题,本文提出一种逻辑拓扑感知的作业调度算法以提高临时私有云中紧耦合并行应用的性能。
2 相关研究
在云计算环境中,当并行应用的进程与虚拟机之间存在一对一的映射关系时,并行应用的调度问题可以等价于虚拟机的调度问题。具体地,云计算系统中的虚拟机调度工作大致分为3类:(1)初始的虚拟机放置,研究的是如何把用户所请求的一个或多个虚拟机映射到可用的资源池中。(2)离线的虚拟机合并,研究的是如何把具有不同资源需求的虚拟机映射到物理资源中,它通过最小化活跃的物理服务器数量来节约能源。(3)在线迁移,研究的是如何制定在线虚拟机的重新映射决策。本文研究第(1)类问题。
对于虚拟机的初始放置问题,已有的云管理系统例如OpenStack[5]和OpenNebula[6]使用了轮转算法、随机算法、首次适应算法和最佳适应算法等策略。此外,研究者也提出了诸多解决方法。例如,文献[7]提出使用遗传算法来解决虚拟机的放置问题。文献[8]提出一种基于离散粒子群优化的调度算法。文献[9]提出一种融合遗传算法与蚁群算法的混合调度算法。文献[10]提出一种具备反馈机制的动态调度算法。然而,上述方法都忽略了多个虚拟机因运行同一个并行应用而产生的紧耦合性,并且未考虑临时私有云环境中虚拟机之间网络性能的不稳定性。
Amazon EC2推出了集群计算实例[11],并利用放置组策略来让同一个组内的所有实例(虚拟机)具有低延迟和高带宽。然而,由于Amazon EC2的非开源特性,研究者并不清楚Amazon EC2的放置组策略到底有多严格以及使用何种技术来提供上述保证。
由以上分析可以看出,目前在临时私有云中仍缺乏一种能够感知并利用虚拟机之间逻辑拓扑结构的作业调度算法。为了解决这个问题,本文提出了一种逻辑拓扑感知的作业调度算法。
3 逻辑拓扑构建与调度算法
下文介绍了临时私有云的逻辑拓扑构建算法,并以此为基础,给出了逻辑拓扑感知的作业调度算法。
3.1 临时私有云的逻辑拓扑
如前所述,受云计算基础设施供应商自身调度策略和资源供应策略的影响,临时私有云中虚拟机之间的网络性能并不稳定[4],为了能够在调度并行应用时充分利用虚拟机之间的网络性能信息,需要获取临时私有云在当前时间的一个逻辑拓扑结构。
在传统物理集群的树状网络拓扑中,计算节点之间的路径越长,它们之间的网络性能一般会越差。以图1中的物理集群为例,共有128个计算节点组成了一个树状网络拓扑结构。其中,编号为1~8的8个计算节点通过接入点A0互相通信,并通过A0与其余120个计算节点(编号为9~128)进行通信。在这个场景中,计算节点1和节点8之间的网络性能通常会优于计算节点1和节点128之间的网络性能。其主要原因分析如下:(1)计算节点1与节点8之间只需要通过A0进行通信,而计算节点1和节点128之间则需要经过A0-D0-C0-D3-A15等方可进行通信,因此,从通信延迟的角度来看,前者要优于后者;(2)随着树状层次的增加,共享高层线路的计算节点数量也在增加,这必然降低了共享同一条线路的节点所实际分到的可用带宽。因此,从可用带宽的角度来看,前者要优于后者。
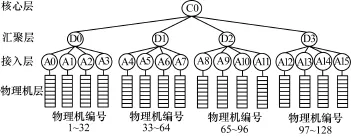
图1 集群树状网络拓扑
受到传统物理集群树状结构中节点之间网络性能的差异性所启发,本文利用虚拟机之间的网络性能,将临时私有云的拓扑构建为树状层次结构。实际上,构建树状层次结构就是对所有虚拟机进行划分的过程。然而,计算一个最优的分层结构是一个NP-hard问题(类似于装箱问题)[12]。由于指数级的复杂性,通常计算最优解决方法是不可行的,尤其是在虚拟机的数量很庞大时,因此本文采用贪心方法来构建层次结构。其基本思想是:设定一个网络性能阈值,然后根据虚拟机之间的网络性能,将所有虚拟机划分到彼此无交集的分组中。在同一个网络性能阈值下划分出的所有分组构成树状层次结构中的一个层次。增大网络性能阈值,重复之前的操作,从而形成一个新的层次。以此类推,直到满足树状结构的层数限制。
对于一个由N台虚拟机组成的临时私有云,本文首先定义了3个矩阵来记录虚拟机之间的网络信息,分别是延迟矩阵、带宽矩阵和网络性能矩阵。其中,延迟矩阵和带宽矩阵中的数据可以通过在每台虚拟机中安装测试代理的方式来获取。在构建临时私有云逻辑拓扑之前,需要利用延迟矩阵和带宽矩阵对虚拟机两两之间的网络性能进行建模,具体描述如下:
(1)延迟矩阵:Latency[0,1,…,N-1][0, 1,…,N-1],其中,Latency[i][j]表示虚拟机i到虚拟机j的平均延迟,其初始值为0。
(2)带宽矩阵:Bandwidth[0,1,…,N-1][0, 1,…,N-1],其中,Bandwidth[i][j]表示虚拟机i到虚拟机j的平均带宽,其初始值为∞。
(3)网络性能矩阵:Performance[0,1,…,N-1] [0,1,…,N-1],其中,Performance[i][j]=Latency[i][j]+1/Bandwidth[i][j]。在计算出网络性能矩阵后,需要对其进行离散化处理。
贪心算法用到的符号和函数具体如下:group表示分组,由网络性能满足条件的虚拟机组成,如group={vm1,vm2,vm3};setcounter表示在第counter次迭代中产生的全部分组所组成的集合;|setcounter|表示集合中的分组数量;set0表示集合set的初始值,每个分组只包含一个虚拟机,即set0={{vm1},{vm2},…, {vmn}};partition(set)表示划分函数,对集合set的分组进行划分,返回值为新的一个集合set’,集合中分组数量小于集合set中的分组数量;distance(v,group)表示距离函数,返回虚拟机v与分组group之间的网络性能值;logicHierarchy表示临时私有云的逻辑层次。逻辑拓扑构建算法的具体步骤如下:
算法1逻辑拓扑构建算法
输入网络性能矩阵Performance[0,1,…,N-1] [0,1,…,N-1]
输出临时私有云的逻辑拓扑


在算法1中,根据设定的虚拟机之间的距离阈值(如partition()函数中的第5行所示)将所有虚拟机划分为一些不重叠的分组(group),每个分组之间具有类似的网络性能(即每个分组内任一对虚拟机之间的距离不大于设定的阈值)。随着逐渐放松距离阈值(如partition()函数中的第8行所示),小的分组(子分组)会随之组成大的分组(父分组)。而分组之间的父子关系形成了一个树形层次结构(如算法1中的第6行所示)。
为了清楚地展示算法具体流程,此处以5个虚拟机(vm1~vm5)为例来进行说明,如图2所示。

图2 逻辑拓扑构建算法
在初始化阶段,集合set0中共有5个分组,其中,每个分组中包含1个虚拟机,即{vm1},{vm2}, {vm3},{vm4}和{vm5}。
在第1次调用partition()函数对集合set0进行划分时,将set0中的5个分组重新划分为2个分组,即{vm1,vm2,vm3}和{vm4,vm5},并保存在集合set1中。
在第2次调用partition()函数对集合set1进行划分时,将set1中的2个分组划分为一个分组,并保存在集合set2中。
经过上述2次划分后,得到树形层次的逻辑拓扑结构logicHierarchy={set0,set1,set2}。
3.2 逻辑拓扑感知的作业调度算法
在获得了临时私有云的逻辑拓扑结构信息后,本文设计一个基于逻辑拓扑感知的作业调度算法(如算法2所示)。针对不同类型的并行应用(紧耦合并行应用和松耦合并行应用)分别做出不同的调度决策。由构建逻辑拓扑结构的算法1可知,在树状层次结构里,同一层中各分组内的虚拟机网络性能相似。
算法2 逻辑拓扑感知的作业调度算法
输入作业的资源需求,临时私有云逻辑拓扑结构logicTopology
输出作业放置策略

算法2的基本思想是:当用户提交紧耦合并行应用时,算法首先在每层中把分组按照所含空闲虚拟机的数量进行升序排列(算法2中的第1行),然后从网络性能最好的层次(算法2中的第4行~第7行)开始,从排列好的分组中选择大小合适的分组(即分组中空闲虚拟机的数量略大于或等于紧耦合并行应用所需要的虚拟机数量),找到这样的分组后,将所需数量的虚拟机分配给上述紧耦合并行应用(算法2中的第8行~第10行)。若在性能最好的层次中没有找到可以放置紧耦合并行应用的分组,则在性能次好的层次中寻找。依此类推,直到找到合适的分组为止,或者因系统中没有足够数量的空闲虚拟机而返回空集(算法2中的第15行)。
当用户提交松耦合并行应用时,因松耦合并行应用对虚拟机之间的网络性能要求不高,所以算法只需在网络性能最好的层次,从按升序排列的分组中依此收集每个分组中的空闲虚拟机(算法2中的第18行~第21行),直到收集的空闲虚拟机数量满足松耦合并行应用的需求为止(算法2中的第22行~第24行),或者因系统中没有足够数量的空闲虚拟机而返回空集(算法2中的第27行)。
4 实验结果与分析
为评估本文提出的逻辑拓扑感知算法,在不同数量的紧耦合并行应用实验和不同的网络性能标准差实验下,对其进行性能测试,并对实验结果进行分析。
4.1 实验设置
实验设置具体如下:
(1)模拟环境
本文使用CloudSim[13]模拟了一个云计算环境。本文选择CloudSim作为云模拟器主要考虑到以下2个原因:1)CloudSim能够有效模拟云计算环境,并受到了国内外研究者的广泛认可;2)文献[14]通过扩展CloudSim的功能已使其具备了对紧耦合并行应用进行模拟的能力。
(2)算法比较对象
如在第1节的相关研究中所述,为了解决虚拟机的初始放置问题,研究者们已提出了诸多方法(如基于粒子群的方法、基于遗传算法的方法等)。然而,它们主要关注的是如何解决装箱问题(即如何在一台物理机中装入更多的虚拟机)来提高云计算系统的资源利用率。上述方法在制定放置决策时,都忽略了多个虚拟机因运行同一个并行应用而产生的紧耦合关系,并且未考虑和利用在临时私有云环境中虚拟机之间的逻辑拓扑关系。而本文算法关注于通过合理放置虚拟机来提升虚拟机中并行应用的性能,并且充分考虑和利用临时私有云中虚拟机之间的逻辑拓扑关系。
由此可以看出,本文算法与上述几种方法在关注点以及评价指标方面有所不同,所以,不适合与它们进行比较。基于以上考虑,本文选取了开源云计算系统(OpenStack和OpenNebula)采用的2种通用方法(轮转算法和随机算法)作为对比对象。
(3)系统并行应用
在实验中模拟了100个并行应用,为了简单明了地对算法进行评估,不失一般性,本文实验假设每个应用包含4个并行进程。其中,每个进程运行在一个单核虚拟机中。
4.2 紧耦合并行应用实验
实验1不同数量的紧耦合并行应用实验。模拟了400台虚拟机,并根据文献[4]对Amazon EC2网络性能的测试数据模拟生成了400台虚拟机之间的网络性能矩阵,取值范围在400~650之间,相对标准差为13.7%。
本文实验中的100个并行应用包括了X个紧耦合并行应用(如NPB benchmark[15]中的BT,SP,IS, CG,LU和MG)以及Y个松耦合并行应用(如NPB benchmark中的EP),其中,X+Y=100,X的初始值为10,并以10为单位递增,最大值为90。例如在X=10,Y=90时进行一轮实验(运行5次求平均值),获取10个紧耦合并行应用在不同算法(逻辑拓扑感知算法、轮转算法、随机算法)下的平均执行时间,并根据理想状态下10个紧耦合并行应用的平均运行时间进行规格化处理。其中,理想状态是指网络性能矩阵中数据的标准偏差为0且能完全满足紧耦合并行应用对网络性能的需求。
在X=20,30,…,90时,分别进行一轮上述实验,规格化实验数据如图3所示。
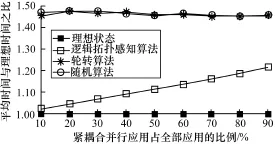
图3 不同数量紧耦合并行应用下的性能比较
具体分析如下:
(1)逻辑拓扑感知算法的性能明显优于轮转算法和随机算法。原因在于:相对于轮转算法和随机算法,逻辑拓扑感知算法能够利用临时私有云中虚拟机之间的网络拓扑关系,选择网络性能好的多个虚拟机来运行紧耦合并行应用,从而达到提高紧耦合并行应用性能的目的,而轮转算法和随机算法并不考虑虚拟机之间的逻辑拓扑关系。
(2)在临时私有云环境中,轮转算法与随机算法的性能相近,并且比较稳定。具体地,在上述2种算法下,紧耦合并行应用的平均执行时间在规格化后介于1.45~1.50之间。原因在于:临时私有云中每个虚拟机的位置是受到云计算基础设施供应商调度算法和负载均衡算法的控制,并且这种控制对临时私有云的所有者来说是不透明的。因此,在临时私有云中轮转和随机算法的性能是相当地。在这种情况下,轮转算法退化为随机算法。
(3)随着紧耦合并行应用数量的增加,逻辑拓扑感知算法的性能逐渐变差,但是仍优于轮转算法和随机算法。原因在于:本文实验中网络性能矩阵中的数值介于400~650之间,相对标准差为13.7%,也就是说,所有虚拟机之间的网络性能数据并非全部相同(有的网络性能好,有的网络性能差)。因此,随着紧耦合并行应用数量的增加,网络性能差的虚拟机会被用来执行紧耦合并行应用,从而导致紧耦合并行应用的平均执行时间也变长。但是由于逻辑拓扑感知算法能够有效利用虚拟机之间的逻辑拓扑,其性能仍优于轮转和随机算法。
4.3 网络性能实验
实验2不同的网络性能实验。虚拟机数量与实验1中的数量相同。因为实验1中已经比较了算法在系统中有不同数量紧耦合并行应用时的性能,得出了相应结论。因此,实验2固定了紧耦合并行应用的数量(即X=10),通过改变虚拟机之间网络性能矩阵的取值范围来评估算法在不同相对标准差情况下的性能表现。虚拟机之间网络性能矩阵的取值范围以及相对标准差如表1所示。
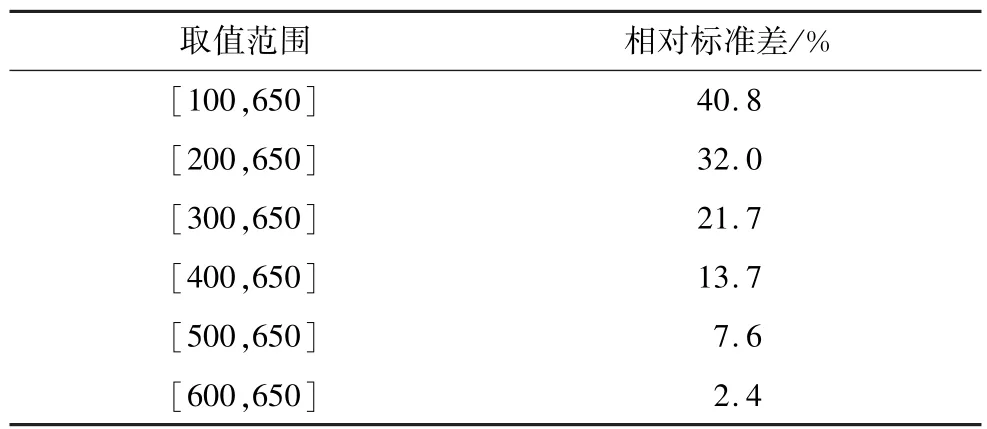
表1 虚拟机间网络性能矩阵的取值范围及相对标准差
实验结果如图4所示,具体分析如下:
(1)在系统中有10个紧耦合并行应用的情况下(即X=10),逻辑拓扑感知算法在不同的网络性能标准差下与理想状态的性能相近。这说明在不同的网络性能相对标准差下,模拟系统中至少有40个虚拟机(10×4)的网络性能与理想状态下的网络性能相当。逻辑拓扑感知算法能够有效利用这些网络性最好的虚拟机来运行上述10个紧耦合并行应用。
(2)轮转算法与随机算法性能相近,并且性能随着相对标准差的降低而变好,尤其是在相对标准差为2.4%时,轮转算法与随机算法的性能接近于逻辑拓扑感知算法以及理想状态下的性能。原因在于:随着相对标准差的降低,虚拟机网络性能越来越接近于理想状态。此时,不同算法对紧耦合并行应用的性能影响不断减弱。因此,逻辑拓扑感知算法、轮转算法和随机算法的性能都开始接近于理想状态下的性能。

图4 各虚拟机间网络性能的相对标准差比较
在真实的云计算系统中虚拟机之间的网络性能一般会随着时间而呈现出波动现象,因此,在算法应用于实际临时私有云时,需要每隔一定的时间(需要根据不同的云计算系统设定不同值)重新构建临时私有云的逻辑拓扑结构。不失一般性,实验1和实验2评估了一次逻辑拓扑构建完成后的算法性能。从实验结果可以看出,逻辑拓扑感知调度算法更适合于临时私有云环境。
5 结束语
本文研究在创建临时私有云后,如何利用逻辑拓扑信息来优化紧耦合并行应用性能的问题。为获取逻辑拓扑信息,提出一个逻辑拓扑构建算法,并基于此设计一种逻辑拓扑感知的作业调度算法。实验结果表明,逻辑拓扑感知的调度算法比轮转算法和随机算法性能更好。在真实环境中构建原型系统以进一步测试和优化逻辑拓扑感知的调度算法是后续研究的重点。
[1] ANL Mathematics and Computer Science Division.The MessagePassingInterfaceStandard[EB/OL]. [2014-07-19].http://www.mcs.anl.gov/research/ projects/mpi/.
[2] Expósito R R,TaboadaGL,RamosS,etal. Performance AnalysisofHPCApplicationsinthe Cloud[J].Future Generation Computer Systems,2013, 29(1):218-229.
[3] Gupta A,Kalé L V,Milojicic D,et al.HPC-aware VM Placement in Infrastructure Clouds[C]//Proceedings of 2013 International Conference on Cloud Engineering. [S.l.]:IEEE Press,2013:11-20.
[4] Wang Guohui,Ng T S E.The Impact of Virtualization onNetworkPerformanceofAmazonEC2Data Center[C]//Proceedings of INFOCOM’10.[S.l.]: IEEE Press,2010:1-9.
[5] OpenStack.Open Source Software for Building Private and Public Clouds[EB/OL].[2014-07-19].https:// www.openstack.org/.
[6] OpenNebula.Cloud and Data Center Virtual Infrastructure Management[EB/OL].[2014-07-19].https://www. opennebula.org/.
[7] Xu J,Fortes J.A Multi-objective Approach to Virtual Machine Management in Datacenters[C]//Proceedings of the 8th ACM International Conference on Autonomic Computing.[S.l.]:ACM Press,2011:225-234.
[8] 邬开俊,鲁怀伟.云环境下基于DPSO的任务调度算法[J].计算机工程,2014,40(1):59-62.
[9] 张 雨,李 芳,周 涛.云计算环境下基于遗传蚁群算法的任务调度研究[J].计算机工程与应用,2014, 50(6):51-55.
[10] 马 莉,唐善成,王 静,等.云计算环境下的动态反馈作业调度算法[J].西安交通大学学报,2014, 48(7):77-82.
[11] 亚马逊公司.AWS产品与解决方案[EB/OL].(2014-03-01).http://aws.amazon.com/cn/ec2/.
[12] Gong Yifan,He Bingsheng,Zhong Jianlang.Network PerformanceAwareMPICollectiveCommunication Operations in the Cloud[J].IEEE Transactions on Parallel Distributed Systems,2013,96(1):1-9.
[13] Calheiros R N,RanjanR,BeloglazovA,etal. CloudSim:A Toolkit for Modeling and Simulation of CloudComputingEnvironmentsandEvaluationof Resource Provisioning Algorithms[J].Software:Practice and Experience,2011,41(1):23-50.
[14] Garg S K,Buyya R.An Environment for Modeling and Simulation of Message——Passing Parallel Applications for CloudComputing[J].Software:Practiceand Experience,2013,43(11):1359-1375.
[15] NASA.NPB Benchmark[EB/OL].[2014-07-19]. http://www.nas.nasa.gov/publications/npb.html/.
编辑 陆燕菲
A Logic-topology-aware Job Scheduling Algorithm in Temporary Private Cloud
ZHAO Yuyan1,CHEN Haibao1,2,ZHAO Shenghui1
(1.School of Computer and Information Engineering,Chuzhou University,Chuzhou 239000,China;
2.School of Computer Science&Technology,Huazhong University of Science and Technology,Wuhan 430074,China)
Considering the cost and flexibility,building a temporary private cloud in public cloud to replace the local physical cluster is an effective way for users to run a large number of parallel jobs during a particular period.However,the existing scheduling algorithms are not suitable for temporary private cloud hosting tightly coupled parallel applications, because they can not use the logic topology information of temporary private cloud,which probably results in the performance degradation of such type of applications.To mitigate such impact,a logic-topology-aware scheduling algorithm is presented.It builds the logic topology of virtual machines according to bandwidth and latency among them, makes scheduling decisions based on the logic topology and the information of applications.Experimental results show that compared with Round Robin and Random algorithms of open-source cloud software,logic-topology-aware scheduling algorithm improves the performance of tightly coupled parallel applications.
temporary private cloud;parallel application;virtual machine;topology structure;scheduling algorithm; network performance
赵玉艳,陈海宝,赵生慧.一种临时私有云中逻辑拓扑感知的作业调度算法[J].计算机工程, 2015,41(2):1-6.
英文引用格式:Zhao Yuyan,Chen Haibao,Zhao Shenghui.A Logic-topology-aware Job Scheduling Algorithm in Temporary Private Cloud[J].Computer Engineering,2015,41(2):1-6.
1000-3428(2015)02-0001-06
:A
:TP393.09
10.3969/j.issn.1000-3428.2015.02.001
安徽省自然科学基金资助面上项目(1408085MF126);安徽省教育厅自然科学研究基金资助重大项目(KJ2011ZD06);滁州学院优秀青年人才基金资助重点项目(2013RC006);滁州学院科研启动基金资助项目(2014qd016)。
赵玉艳(1982-),女,讲师、硕士,主研方向:数据挖掘,云计算;陈海宝,讲师、博士研究生;赵生慧,教授、博士。
2014-08-20
:2014-10-03E-mail:zhyy@chzu.edu.cn
