一种面向高校图书馆的个性化图书推荐系统
2015-01-06王连喜
王连喜
(广东外语外贸大学图书馆,广东广州510420)
一种面向高校图书馆的个性化图书推荐系统
王连喜
(广东外语外贸大学图书馆,广东广州510420)
〔摘要〕个性化图书推荐主要是以用户特征和借阅行为为挖掘对象,通过获取用户的兴趣特征及隐含的需求模式,实现用户与图书相互关联的个性化图书推荐服务。本文通过挖掘用户的背景信息构建用户特征模型,然后在设计喜好值计算、用户相似度计算和内容相似度计算以及标签信息获取方法的基础上,研究多种不同的图书推荐方法,以挖掘用户的潜在信息需求。最后利用图书馆的真实数据设计面向高校图书馆的个性化图书推荐系统,同时以标准网络数据集通过实验验证来评估推荐方法的有效性。
〔关键词〕高校图书馆;推荐系统;个性化需求;图书推荐
随着网络技术与社交媒体的发展和普及,人们逐渐从信息匮乏的状态陷入了信息过载的困境。在这个信息爆炸的环境中,图书馆的信息消费者与信息生产者都在不同程度上出现了新的挑战:对于用户而言,如何从大量的馆藏资源中找到适合自己的图书资源是一件非常困难的事情;而对于图书馆从业人员以及电子资源的信息生产者而言,如何让其所拥有的资源找到合适的用户也是一件亟待解决问题。个性化推荐系统就是解决上述两种问题的重要工具。个性化图书推荐系统的最重要任务就是将用户兴趣和图书信息关联起来,一方面帮助用户发现对自己有价值的图书资源;另一方面让图书资源最大程度地展现在有需求或有潜在需求的用户面前,从而使用户和图书馆达到双赢的状态[1]。
目前流行的推荐系统大致是以3种方式实现用户与图书的关联。第一种方式是分析用户的借阅历史,为用户推荐与其借阅记录中相类似的图书。第二种方式是挖掘用户的借阅行为,通过建立兴趣模型为用户推荐具有相似借阅行为用户的借阅信息;第三种是关联用户与图书的特征信息,通过发现用户与图书之间的有趣关联特征或模式并生成关联规则,从而为用户推荐其可能感兴趣的图书。从技术层面来看,学者们针对3种关联方式提出了一些个性化的推荐技术,包括基于内容的个性化推荐、基于用户的个性化推荐、基于关联规则的个性化推荐以及混合推荐等[2-4]。虽然目前已经有多种推荐方法被应用到各个领域,但是不同的推荐技术有着不同的特性和不足:(1)基于内容和用户的推荐方法主要依靠目标特征的关系亲密度(兴趣度)来进行衡量目标之间的相似度。两种方法的推荐效果比较显著,但是容易受到稀疏问题和冷启动问题的影响[5];(2)基于关联规则的个性化推荐方法的核心是发现并建立内容与用户之间实际或潜在的关联规则[6]。该方法也会受到稀疏性问题和冷启动问题的影响,而且还需要消耗大量的建模时间,所以算法的复杂性比较高。
随着办学规模的扩大和办学水平的提高,国家对高校的支持力度越来越大,尤其重视高校学子的人均资源拥有量,所以使得当前高校的馆藏资源十分丰富,从而导致图书馆的部分图书的借阅量偏低,甚至出现零借阅现象。由于高校图书馆的服务对象主要是高校教职工和学生,其基本信息相对简单、容易获取且比较准确,所以高校的图书推荐与电子商务领域的个性化推荐有所不同。个性化图书推荐是以图书和用户的特征及行为为挖掘对象,通过分析用户对图书的喜好程度、用户之间的兴趣相似度、图书内容之间的相似的度以及用户的喜好标签等信息,研究并设计适合高校图书馆的个性化图书推荐系统。
1 个性化图书推荐方法
根据高校图书馆的图书及其用户的特点,从用户背景信息与知识结构识别、用户对图书的偏爱、用户的相似兴趣计算、内容相似度计算以及用户对喜好标签标注等入手,研究基于用户的协同过滤推荐、基于内容的协同过滤推荐、基于标签的推荐以及基于用户背景信息的图书推荐。
1.1基于用户的协同过滤推荐方法
基于用户的协同过滤推荐方法的主要思路是,首先计算用户之间的相似度并找到与目标用户兴趣相似的用户,然后选择与其最相似的前M个用户,最后从M个用户的借阅图书集合中依据“喜好值”找到用户喜欢的且目标用户并没有借阅过的图书,并将其推荐给目标用户。
为了能够更好的反映出用户对借阅图书的偏好程度,通常用喜好值来度量。假设某用户u所借阅的图书序列为BOOK={book1,book2,L,bookn},借阅起始时间为TB={TB1,TB2,L,TBn},每本图书的借阅时间为T={T1,T2,L,Tn},用户首次借阅图书的时间为TF,用户借阅图书的最短时间Tmin,用户借阅图书的最长时间Tmax,当前时间为TC,则用户u对图书booki的喜好值衰减率计算方式如下:

用户u对图书booki的喜好值计算方式如下:

基于用户的协同过滤推荐方法就是在已给定的喜好值计算方法之上,利用修正的余弦相似性公式计算与目标用户最为相似的Top-N用户作为与其在借阅兴趣上具有较大相似性的最近邻用户。任意两个用户u1和u2的相似度计算方法如下:

根据用户的相似性计算可以得出与用户ui具有近似相同兴趣的Top-N用户,记Top-N用户集合为SUi。基于用户的协同过滤推荐方法就是在汇总SUi中每个用户借阅图书序列的喜好值的基础上,根据喜好值总和进行降序排列后得到推荐图书集合RBi,然后根据用户ui的图书借阅集合BBi产生图书推荐集合FRBi。FRBi的计算如式(4)表示:

1.2基于内容的协同过滤推荐方法
基于内容的协同过滤推荐方法根据用户对相似图书的喜好值为用户进行图书推荐。该方法首先通过计算图书之间的相似度,并找到与目标图书相似的若干最近邻居,然后综合图书相似度和用户的历史借阅行为为用户生成图书推荐列表。在电子商务领域中,许多基于内容的协同过滤算法都是从内容角度以余弦相似度或皮尔森相关系数等作为相似度计算的依据,本文从图书馆用户的借阅行为特点及其与图书的关系特点出发,以用户对图书的喜好值作为相似度计算的依据,故而将图书之间的相似度表示为ri,j:

由式(5)可知,ri,j主要反映是图书的共现程度。在得到两本图书之间的相似度之后,根据用户的历史借阅记录,查找与用户所借阅过的图书最相似的Top-N本图书向用户进行推荐。
1.3基于标签的图书推荐方法
标签是一种无层次化结构的、用以描述信息的关键字。在社交网络平台上,用户可以根据自己的喜好为自己或物品打上合适的标签(用户的显式标签),系统就会根据用户的标签为用户推荐好友或其他事物。对于图书网站而言,系统会将用户对图书所标注的标签作为用户的喜好标签(用户的隐式标签),并根据此标签为用户推荐图书。但是对于图书馆来说,大部分图书都没有被用户标注标签,所以需要通过外部数据获取图书的隐式标签。基于标签的推荐方法主要是在获取用户的隐式标签的基础上,借鉴TFIDF方法计算用户对图书的喜好程度(如式(6)所示),选取喜好值高且目标用户没有借阅过的Top-N图书向目标用户推荐。

在公式(6)中,UB表示用户u的隐式标签集合,nu,b表示用户u使用标签b的次数,nb,i表示图书i被标注为标签b的次数,nb表示使用标签b的用户数量,ni表示图书i被标注的用户数量。
1.4基于用户背景信息的图书推荐方法
高校用户由于背景信息的不同,用户对图书的借阅偏好也可能会不一样。一般来说,相同或相近专业的用户,其借阅的图书类型会比较类似,而且可能更多地是偏向与专业相关的图书。基于用户背景信息的图书推荐方法的基本思路是先获取相似背景信息的所有用户的借阅记录,然后计算用户对图书的喜好值总和,并根据喜好值总和进行排序,选取喜好值总和最大的且没有被目标用户借阅过的图书向目标读者进行推荐。
2 推荐方法评估
由于当前图书馆的数据基本上没有被规范处理过,也没有被评测过,所以不能利用标准的数据集来评估推荐方法的效果。为了方便测试,采用来自互联网上的MovieLens数据集和CiteULike数据集对推荐方法进行测试与评估。
MovieLens是GroupLens项目组开发的一个基于Web的研究型推荐系统,用于接收用户对电影的评分并提供相应的电影推荐列表。该数据集中包含了943个用户对1 682部电影的100 000条评分数据,其中每个用户至少对20部电影进行了评分。
CiteULike数据集包含了网站从2004年11月-2010年3月所有的用户操作数据,每条数据都包括文章号、用户名(MD5值)、收藏时间、收藏时用的标签等4个字段(如表1所示)。若用户在标注一篇文章时使用了多个标签,则这些标签分别存入多条数据中,如表1中的前3行。
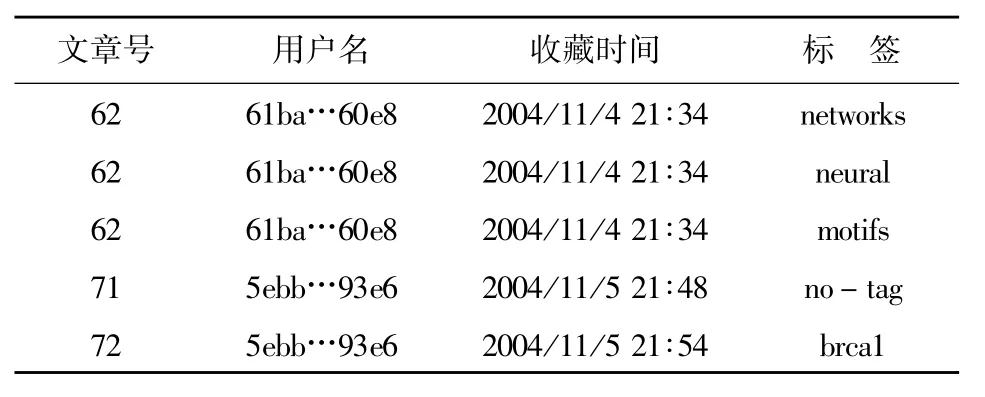
表1 CiteULike 数据(部分)
由两个数据集的具体描述可知,MovieLens数据集可用于测试基于用户的协同过滤推荐方法和基于内容的协同过滤推荐方法,CiteULike数据集可用于测试基于标签的推荐方法。在实验测试过程中,采用五折交叉验证方式对3种推荐算法进行测试,评估指标包括准确度、召回率、覆盖率及平均热门程度。

表2 基于用户的协同过滤推荐方法测试结果

表3 基于内容的协同过滤推荐方法测试结果
表2和表3分别给出了基于用户的协同过滤推荐方法和基于物品的协同过滤推荐方法测试结果。在两个表中,N和M分别为每个用户选出相似用户的数量和为每本图书推荐的图书数量。从表2可以看出,N值只与流行度指标成正相关。当N取80时,基于用户的协同过滤推荐方法达到较为理想的效果。从表3的结果可以看出,M值与准确度、召回率、流行度既不成正相关,也不成负相关,但是与覆盖率成负相关。当M取10时,基于内容的协同推荐方法的各项指标达到最佳。
从表4给出的基于标签的推荐方法测试结果可以看出,该方法也可以得到较好的效果。

表4 基于标签的推荐方法测试结果
3 实验与系统设计
3.1数据来源
以广东某高校图书馆所提供的2010年4月至5月的39 544条借阅记录(读者ID,ISBN、借阅时间、实际归还时间等)以及437 623本图书的信息(书名、作者、出版社、出版年、ISBN、单价、索书号等)作为实验数据。经初步统计发现,实验数据中有借阅行为的用户有1 978人,详细的用户借阅情况及图书被借阅情况分别如图1和图2所示。

图1 读者借阅书籍情况
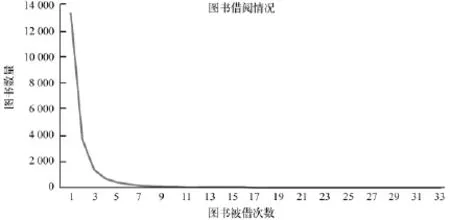
图2 图书被借阅情况
由图1和图2所示,该图书馆中借阅频次较高的图书数量呈递减趋势,而且有大部分图书没有被借阅过。
3.2数据预处理
由于原始数据中有许多脏数据,不方便用户理解和建模。为了增强数据的可理解性和降低系统的时间开销,有必要对实验数据进行清理和预处理使其能够满足推荐方法的数据要求,并提高其效率和性能。由于基于用户和内容的协同过滤推荐方法以及基于用户背景信息的推荐方法都是重点分析用户和图书的基本特征与行为特征,而基于标注的推荐算法则重点挖掘图书的内容信息、书评信息、购买信息以及标签记录等。为此,我们手动编写爬虫算法从豆瓣读书网上全自动抓取了实验数据中20 574本图书的内容信息、20 055条书评信息、57 643条图书购买信息及89 632条图书标签记录。
与此同时,由于该实验数据所提供的特征信息比较复杂,所以在实现推荐算法之前需对数据进行预处理,包括提取用户借阅信息和获取用户的隐式标签(如表5和表6所示)。在获取用户的隐式标签时主要基于以下假设:用户只对其感兴趣的图书打标签,所以其预处理过程即获取用户使用过的标签及使用的次数。
3.3系统逻辑结构设计
本系统使用PHP与MYSQL实现。在PHP的应用方面采用MVC设计模式,其目的是更好地实现系统的功能。MVC设计模式将系统分为3层:Model层实现系统中的业务逻辑;View层用于与用户的交互;Controller层是Model与View之间沟通的桥梁,它可以响应用户的请求并选择恰当的视图以用于显示,同时它也可以理解用户的输入并将它们映射为模型层可执行的操作。

表5 用户借阅信息表

表6 用户标签表
在功能设计方面,本系统主要包括图书模块、用户模块、搜索模块和推荐模块4个部分。图书模块主要负责完成与图书相关的业务逻辑,需要从各个与图书相关的表中通过模型的操作来提取信息,并将信息提交给控制器,然后在由控制器补充必要的信息之后再传递数据给视图,最后再将信息展示给用户。
用户模块主要负责完成与用户相关的业务逻辑,包括用户的登陆、关注、查看粉丝、查看书评、查看其它用户的信息以及个人信息管理等功能。用户模块是一个非常核心的模块。
搜索模块主要负责完成与搜索相关的业务逻辑,主要包括图书搜索、用户搜索及其结果排序和搜索关键词的优化。
推荐模块负责从数据库的推荐表中提取推荐的信息进行组织和排序,并按照不同的要求将数据传递给控制器。
3.4系统实现关键技术
本系统主要实现基于用户的协同过滤推荐算法(User -Based Collaborative Filter Algorithm)、基于内容的协同过滤推荐算法(Item-Based Collaborative Filter Algorithm)、基于标签的推荐算法(Tag-Based Recommend Algorithm)、基于用户背景信息的推荐算法(Major Feature-Based Recommend Algorithm)。根据前面描述的推荐算法过程可知,本系统主要在实现用户对图书的喜好值计算、用户相似度计算和图书相似度计算的基础上产生推荐结果列表。表7~表9分别是基于内容的协同过滤推荐、基于用户的协同过滤推荐和基于标签的推荐算法的主要数据库表设计。

表7 基于内容的协同过滤推荐表

表8 基于用户的协同过滤推荐表

表9 基于标签的推荐表
3.5系统效果展示
本系统自用户登陆开始,从目标搜索到图书查看的过程中都会产生推荐结果。具体来说,在用户通过身份识别登陆后,系统根据用户的专业、年级、学习身份等背景信息以及用户的隐式标签和相似用户等信息通过基于用户的协同过滤推荐方法、基于用户背景信息的推荐方法和基于标签的推荐方法产生推荐结果(如图3和图4所示)。

图3 登陆后推荐页面(上)

图4 登陆后推荐页面(下)
如果登陆用户在搜索框内通过目标关键词进行检索后(如图5所示),并在得到的返回结果中查看任何一本图书的信息(如图6所示),系统将会通过基于内容的协同过滤推荐方法在页面下方产生相应的推荐结果(如图7所示)。

图5 搜索结果返回页面(部分)

图6 图书详细信息页面(基本信息及购买信息)

图7 图书的详细信息页面(基于内容的协同过滤推荐)
4 结论
本文首先介绍当前图书推荐系统的基本情况及其各自的特性的不足,然后对喜好值计算、相似度计算以及四种推荐方法的思路及原理进行详细阐述,最后构建系统实现面向高校图书馆的个性化图书推荐系统。
当然,本系统还有很大的完善空间,例如:可以改进基于标签的推荐算法以提高推荐的效率;实现基于图的推荐算法、如Random Walk等,使本系统的推荐方式实现多样化。
参考文献
[1]Hwang S Y,Lim E P.A data mining approach to new library book recommendations[J].Digital Libraries:People,Knowledge,and Technology,2002:229-240.
[2]丁雪.基于数据挖掘的图书智能推荐系统研究[J].情报理论与实践,2010,(5):107-110.
[3]安德智,刘光明,章恒.基于协同过滤的图书推荐模型[J].图书情报工作,2011,55(1):35-38.
[4]邵志峰,李荣陆,胡运发.基于中图分类法的用户兴趣模型研究[J].计算机应用与软件,2007,(8):85-87.
[5]罗喜军,王韬丞,杜小勇,等.基于类别的推荐——一种解决协同推荐中冷启动问题的方法[J].计算机研究与发展,2007,(3).
[6]苏玉召,赵妍.个性化关键技术研究综述[J].图书与情报,2011,137(1):59-65.
(本文责任编辑:孙国雷)
Personalized Books Recommender System for University Library
Wang Lianxi
(Library,Guangdong University of Foreign Studies,Guangzhou 510420,China)
〔Abstract〕Personalized books recommend methods are worked by getting the user's interest features and implicit demand patterns,so as to mining users'borrowing behaviors and achieving the personalized book recommendation service by associating the user and the books.This paper built a profile of the user model with the background information,and then designed the methods of user preference,user similarity and content similarity,as well as the acquisition of label information,to tap the latent user information demand.Finally,a personalized book recommendation system for Univerity library was developed,and the experimental results with the standard network data sets showed that the proposed recommend methods are effective.
〔Key words〕university library;recommend system;personalized demand;books recommender
作者简介:王连喜(1985-),男,馆员,硕士,研究方向:数据挖掘与自然语言处理,发表论文20余篇。
基金项目:教育部人文社会科学研究青年项目“微博热点事件发现及其内容自动摘要研究”(项目编号:14YJC870021)、广东省科技计划项目“广东省企业竞争情报信息提取及态势推理机制研究——以汽车行业为例”(项目编号:2015A030401093)、广东外语外贸大学校级教学研究项目“英语学习平台的个性化资源推荐研究”(项目编号:GWJYQN14010)的研究成果。
收稿日期:2015-10-15
〔中图分类号〕G252.62
〔文献标识码〕B
〔文章编号〕1008-0821(2015)12-0041-06
DOI:10.3969/j.issn.1008-0821.2015.12.007
