基于马尔可夫模型的新闻事件抽取方法
2015-01-04黄廷磊刘久云华绿绿
夏 威,黄廷磊,刘久云,华绿绿
(桂林电子科技大学计算机科学与工程学院,广西桂林 541004)
基于马尔可夫模型的新闻事件抽取方法
夏 威,黄廷磊,刘久云,华绿绿
(桂林电子科技大学计算机科学与工程学院,广西桂林 541004)
针对目前事件抽取方法普遍存在正反例子不平衡的问题,提出一种基于实例驱动的事件抽取方法。该方法采用二元分类器过滤非事件句子,通过聚类事件句子完成事件抽取过程,利用马尔可夫模型对文档句子的位置信息进行描述。实验结果表明,该方法能有效解决正反例不平衡的问题,提高事件抽取的整体性能。
事件抽取;新闻文本;分类;事件序列;聚类
随着Internet的发展,在线新闻数量呈指数增长,其中大部分为非结构化的信息,结构凌乱、松散、数据量大以及冗余量大是这类信息的共同特点。如何挖掘潜在有价值的信息,仍是一大难题。在这样的背景下,事件抽取技术应运而生。一般认为,事件是发生在特定时间和地点的具体事情。事件抽取作为信息抽取领域的一个重要分支,其目的是从非结构化的信息中抽取用户感兴趣的事件,并以结构化的形式呈现给用户。事件抽取涉及自然语言处理、数据挖掘等多个领域,在自动摘要[1]、信息检索[2]、情报学[3]等领域均有广泛的应用。
目前,事件抽取的方法主要有2种:1)基于模式匹配[4]的方法。该方法的主要思想是应用已建立的模式指导事件的识别和抽取,即用待抽取的句子匹配已建立的模式,如系统Ex Disco[5]、Gen PAM[6]等均采用此类方法建立,但模式的创建通常需要工程师手工完成,工作量大且可移植性差。2)基于机器学习的方法。该方法借鉴文本分类的思想,利用分类器识别事件元素以及事件类别,其事件分类通常是句子级的,一般为短文本。如Llorens等[7]利用CRF模型对语义角色进行标注,并将其应用于Time ML的事件抽取。
机器学习方法可分为3类[8]:基于事件元素驱动方法、基于事件触发词驱动方法以及基于事件实例驱动的方法。目前,国内外的研究大多基于前2类方法,需要对所有相关词语进行判定。然而,在实际应用中,非事件元素在句子中占有很大比例,且目前仍无高效的算法来完成过滤工作,这就引入了大量的反例,使得正反例严重不平衡。为此,基于事件实例驱动的事件抽取算法,将一个事件句子看作一个实例,很好地解决了正反例不平衡的问题,具有较好的抽取效果。
1 算法框架
算法的基本框架为:利用支持向量机(SVM)过滤非事件语句,对来自不同新闻文档的句子集合进行聚类,聚类阶段利用马尔可夫模型模拟事件在文档中的顺序结构,并使用轮廓系数[9](silhouette coefficient)确定聚类的最终簇个数,作为聚类的终止条件。事件抽取流程如图1所示,主要包括事件句子的识别和聚类2个过程。

图1 新闻事件抽取流程图Fig.1 The flow chart of news event extraction
1.1 事件句子的识别
新闻文档一般包含大量的非事件句子,影响事件抽取的准确率。要提高事件抽取的效率,需对事件句子进行识别,过滤非事件句子。事件句子识别的具体步骤如下:
1)预处理。着重进行句子切分、中文分词、词性标注、停用词过滤等工作,完成对文本语料的初步处理。
2)特征提取。基于预处理结果选取相关事件特征:词语数量、句子位置、句子长度、停用词频率、实体数量、时间数量、数值数量等,利用向量空间模型(VSM)对预处理结果中的所有句子进行向量表示。
3)事件识别。识别事件句子的实质为一个二分类问题,支持向量机[10]分类器具有良好的可移植性、较高分类精度以及分类速度快等特点,因此,采用SVM作为分类器进行事件句子识别。
1.2 事件抽取
目前,聚类算法的研究已相当成熟,主要分为层次聚类和非层次聚类,其中层次聚类方法应用较为广泛。凝聚的层次聚类应用一种自底向上的方法,首先把每个数据点看作是一个簇,然后每次迭代合并最相似的2个簇形成更大的簇,直到满足指定的终止条件为止。这一过程涉及簇之间的相似度度量,传统相似度计算一般采用基于向量空间模型(VSM模型)的文本表示方法,将特征词的TFIDF值应用到VSM模型中,特征词权重为

其中:ωij为特征项ti在句子sj中的权值;fij为特征词ti在句子sj中出现的频数;∑fkj为句子sj中所有特
k∈sj征词出现次数之和;nk为含有特征词tk的句子数;N为句子总数。
利用标准余弦结合特征项权值计算句子之间的相似度。传统方法虽然简单,但没有很好地利用文档内部结构信息,因而效果不佳。为此,将句子在文本中的位置信息以及句子包含的时间信息加入到相似度度量中。
1.2.1 轮廓系数
轮廓系数实际上是对凝聚度和分离度的改进,它将数据集中的任一对象与本簇中其他对象以及其他簇中对象的相似性分别进行量化,然后将2种相似性量化后的结果以一定的形式组合起来,从而获得聚类方法优劣的综合评价标准。对于簇中第i个对象,其轮廓系数为
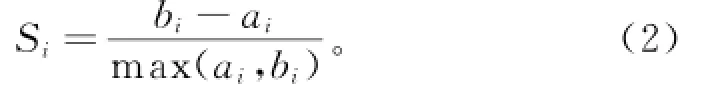
其中:ai为数据点i与其所属簇内所有其他点距离的平均值;bi为数据点i距离其他簇中任意点的最小距离。对所有点轮廓系数进行计算,然后求平均值,得到聚类结果的总体轮廓系数S,取值范围为[―1,1],负值表示类的半径比2个簇之间的距离大,即簇是重叠的,表明这个聚类结果不理想。S的值越大,聚类结果的效果越好。
1.2.2 事件位置信息
马尔可夫模型描述了一个状态序列。假设随机过程中指定状态qt的概率分布只与前一个状态qt―1有关,即p(qtq1,q2,…,qt―1)=p(qt qt―1),且不同状态之间以一定的概率相互转换。
文档一般可认为是一系列线性排列的句子,文献[11]论证了位置相近的句子描述同一事件的可能性更大,后来的句子更可能引入新的事件。因此,包含不同事件的句子间一般存在一种先后顺序关系,这种链式关系可使用马尔可夫模型[12]进行描述。将文档中所有事件句子作为状态集合,利用状态集合对马尔可夫模型进行训练,得到某个状态qi的出现次数以及qi转移到qj的次数,从而得到qi到qj的转移概率。测试过程中,定义第一个包含事件的句子为初始状态,最后一个包含事件的句子为最终状态,不同的状态根据一定的概率相互转化。
上述过程可形式化描述为:设Q={q1,q2,…,qn}为n个事件的标签序列,p(S(q1))为以事件标签q1开始的文档的概率,p(E(qn))为以事件标签qn结束的文档的概率,p(qi|qi―1)为事件标签qi标记的句子跟随事件标签qi―1标记的句子的概率,p(Q)为由马尔可夫模型生成指定事件序列Q的概率,

根据式(3)可计算期望序列的概率,此过程假设每个句子最多提到一个事件。
1.2.3 事件时间信息
新闻文档中的时间表示通常比较模糊,如:10月12日上午、上周五、去年、昨天等,文档定位不够精确,因此将时间与文档发布时间进行对比,以得到标准时间。对于不含时间信息的事件句子默认其时间与报道时间相同,且假定时间接近的事件句子更可能描述同一事件。时间相似度

其中λ为系数,实验中取值为10。
1.2.4 事件抽取
设Q(C1,C2)为通过合并2个簇C1、C2而产生的标签的序列,p(Q(C1,C2))为生成序列Q(C1,C2)的概率。C1、C2之间的相似度其中α为可变参数,实验中取值为0.7。

假设剩余簇的个数为d,则有d(d―1)/2对簇。在每次迭代中,对每对簇(Ci,Cj)进行预合并,得到结果标签序列,利用经训练的马尔可夫模型计算结果序列的概率。根据式(5)计算簇之间的相似度,合并相似度最大的一对簇,直到剩余簇个数为k时聚类结束,此时数据集获得最大的轮廓系数。图2为聚类过程,其中概率p为生成结果序列的概率。

图2 聚类过程Fig.2 Clustering process
2 实验分析
2.1 实验方案
2.1.1 数据准备
实验以昆明“3·01”暴恐案相关新闻为例,将来自6个不同来源的约300篇新闻报道作为信息集合对算法进行评估。这些新闻文档大小不同、包含事件量也不同。每篇文档所含事件平均量为3.02,每个句子所含事件平均量为1.03。首先对文档进行句子切分得到句子集合,然后利用SVM对其进行过滤,获得事件句子集合。对于集合中的每一个事件句子,依次手动分配唯一整数标签。对于来自同一篇文档且描述同一事件的句子,分配相同的标签。句子可涉及多个事件,例如“昆明暴案一审三人获无期,二审高院驳回上诉”,这句话需分配2个标签,每次审判分配1个标签。
2.1.2 评价指标
采用准确率P、召回率R和综合指标F值对算法的性能进行评估:

其中:a为属于该类且被正确归为该类的事件个数;b为不属于该类但错误归为该类的事件个数;c为属于该类但被错误归为其他类的事件个数。
2.2 实验结果及分析
利用不同的k值对上述实验数据集多次运行k均值算法,计算每次聚类结果的整体轮廓系数,当轮廓系数最大时,对应的k值即为最佳簇个数。不同k值所对应的轮廓系数如图3所示。从图3可看出,在k值取7时,可获得最大的轮廓系数,则最佳簇个数为7。
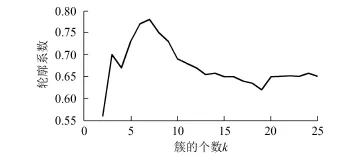
图3 不同k值对应的轮廓系数Fig.3 Silhouette coefficient in the different k
将改进方法与基于事件元素驱动方法、基于触发词驱动方法以及基线方法进行对比,其中基线方法在聚类过程中仅使用传统相似度度量,实验结果如表1所示。

表1 实验结果Tab.1 The experimental results%
从表1可看出,改进方法取得了较好的结果,准确率有了一定的提升,特别是召回率有了较大的提高,说明改进方法能较好地完成事件抽取任务。最重要的是改进方法解决了传统基于触发词驱动、事件元素驱动模型在训练过程中引入太多反例以及造成数据稀疏问题,从而在召回率方面有了一定的突破。此外,由于改进方法引入了对句子在文档中位置的描述,使得抽取结果的整体性能高于基线方法。
3 结束语
在分析事件抽取现状的基础上,提出一种基于事件实例的事件抽取模型,完成了非事件过滤的任务,有效解决了非事件句子对事件抽取过程的干扰,通过聚类事件实例完成事件抽取任务,解决了传统方法必须预定义抽取的事件类型问题。实验结果表明,改进方法较好地解决了正反例不平衡的问题,提高了事件抽取的整体性能。
[1] Fattah M A.A hybrid machine learning model for multidocument summarization[J].Applied Intelligence,2014, 40(4):592-600.
[2] Janowicz K,Raubal M,Kuhn W.The semantics of similarity in geographic information retrieval[J].Journal of Spatial Information Science,2014,33(2):29-57.
[3] 高强,游宏梁.事件抽取技术研究综述[J].情报理论与实践,2013,36(4):114-117,128.
[4] 韩敏,唐常杰,段磊,等.基于TF-IDF相似度的标签聚类方法[J].计算机科学与探索,2010,4(3):240-246.
[5] Yangarber R.Scenario customization for information extracrion[D].New York:New York University,2001:30-33.
[6] 姜吉发.自由文本的信息抽取模式获取的研究[D].北京:中国科学院,2004:27-29.
[7] Llorens H,Saquete E,Navarro-Colorado B.TimeML events recognition and classification:learning CRF models with semantic roles[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Association for Computational Linguistics,2010:725-733.
[8] 许旭阳,韩永峰,宋文政.事件抽取技术的回顾与展望[J].信息工程大学学报,2011,3(1):113-118.
[9] Aranganayagi S,Thangavel K.Clustering categorical data using silhouette coefficient as a relocating measure [C]//Conference on Computational Intelligence and Multimedia Applications,2007:13-17.
[10] 丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].电子科技大学学报,2011,40(1):2-10.
[11] Zha Hongyuan.Generic summarization and keyphrase extraction using mutual reinforcement principle and sentence clustering[C]//Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 2002:113-120.
[12] Singh R S,Patel C,Yadav M K,et al.Weekly rainfall analysis and Markov chain model probability of dry and wet weeks at Varanasi in Uttar Pradesh[J].Environment and Ecology,2014,32(3):885-890.
编辑:梁王欢
News event extraction based on Markov model
Xia Wei,Huang Tinglei,Liu Jiuyun,Hua Lülü
(School of Computer Science and Engineering,Guilin University of Electronic Technology,Guilin 541004,China)
Due to most of the existing approaches for event extraction generally cause an imbalance between positive and negative samples,a new extraction method driven by event instance is presented.The method removes the non-event sentences with support vector machine,and then a novel distance metric is presented which uses Markov model to describe the location of the sentences in documents.Experimental results indicate that the imbalance problem can be solved and the overall performance of event extraction is improved.
event extraction;news text;classify;event sequence;cluster
TP391
:A
:1673-808X(2015)04-0325-04
2015-03-26
国家863计划(2012AA011005)
黄廷磊(1971―),男,安徽肥东人,教授,博士,研究方向为数据挖掘、无线Mesh网络等。E-mail:tlhuang@guet.edu.cn
夏威,黄廷磊,刘久云,等.基于马尔可夫模型的新闻事件抽取方法[J].桂林电子科技大学学报,2015,35(4):325-328.
