基于氨基酸特征的荞麦Fisher判别
2015-01-03李艳琴
张 强 李艳琴
(山西师范大学生命科学学院1,临汾 041004)
(化学生物学与分子工程教育部重点实验室山西大学生物技术研究所2,太原 030006)
基于氨基酸特征的荞麦Fisher判别
张 强1李艳琴2
(山西师范大学生命科学学院1,临汾 041004)
(化学生物学与分子工程教育部重点实验室山西大学生物技术研究所2,太原 030006)
根据甜荞和苦荞氨基酸的特点,筛选有效判别指标,建立判别准则。分别以氨基酸质量分数和相对含量为指标,采用逐步法构建Fisher判别模型,并进行试验验证。采用质量分数法建立的判别模型,以组氨酸、谷氨酸、丝氨酸、甘氨酸、苏氨酸和酪氨酸为变量,回判正确率为94.71%,交互验证正确率为93.27%;采用相对含量法建立的判别模型,以组氨酸、谷氨酸、甘氨酸、丝氨酸、苏氨酸和丙氨酸的相对含量为变量,回判和交互验证正确率均为95.19%;采用12份荞麦材料对模型进行试验验证正确率为100%。组氨酸、谷氨酸、甘氨酸、丝氨酸、苏氨酸的质量分数和相对含量在荞麦判别中均发挥重要作用,氨基酸指标与判别分析技术相结合,可作为荞麦种类鉴别和质量控制的一种有效、可行的方法。
甜荞 苦荞 氨基酸 Fisher判别 数据挖掘
荞麦为蓼科(Polygonaceae)荞麦属(Fagopyrum)双子叶植物,是药食兼用作物。中国是荞麦生产大国,也是荞麦出口大国[1]。荞麦有2个栽培种:甜荞(F.esculentum Moench,亦称普通荞麦)和苦荞(F.tartaricum L.Gaerth,亦称鞑靼荞麦)。随着人们对荞麦研究和开发的深入,苦荞的营养价值和药用价值[2]被了解得越来越清楚,由于市场需求加大和产量等因素的制约,苦荞市场价格也在持续走高,苦荞的价格达甜荞的2~3倍。目前荞麦粉的鉴别主要还是通过观察颜色等方法,依据直观经验进行。近年来,染色馒头、地沟油、欧洲马肉风波等侵犯消费者合法权益的事件层出不穷,因此,探寻多指标的荞麦判别方法,解决苦荞粉与甜荞粉鉴别、充伪等问题,对于荞麦产品质量控制、原料品种的验证鉴别,健全质量管理,保证荞麦产业的持续健康发展具有重要意义。芦丁虽可作为荞麦粉的标记物,但以单一指标成分评价产品品质已经引发多种问题[3],基于多指标的多元判别,既可以避免不同环境和品种单一指标的差异造成的不稳定影响,又难以伪造,比单一指标判别更具有优势。
食品、农产品的鉴别模型可以定性鉴别食品农产品的种类、品种、等级、产地[4],是进行食品农产品等质量控制的有力工具。已有学者利用产品中所蕴含的多组分多指标的特定信息,进行相关研究。氨基酸结合判别分析技术,近年来在食品农产品等的质量控制和安全监督方面得到广泛的应用,并取得了较好的效果。Concha-Herrera等[5]分析了7种植物油中的18种氨基酸,采用13个氨基酸比率作为预测变量,建立线性判别模型,正确分类的概率高于99%。Krishna Reddy等[6]研究发现6种游离氨基酸在判别印度鸦片来源中起重要作用。Helena等[7]利用游离氨基酸组分对19个扁桃品种进行分类研究。采用多种氨基酸为指标进行判别分析还应用在葡萄酒[8-10]、米酒[11]、药品[12]的品牌、产地、种类和厂家等的判别上。
在荞麦判别方面,张萍等[13]采用近红外光谱技术对荞麦等样品进行了鉴别分析,研究显示甜荞、苦荞的原始光谱图差别不明显,经过一阶导数处理主成分提取后进行聚类才能看出较显著的差异。关于荞麦氨基酸方面的研究主要集中在成分分析、营养评价方面[14-17]。采用氨基酸作为判别指标的荞麦种类鉴别模型研究,国内外鲜见报道。不同产品中各种成分含量的变化规律不一,有效判别指标也不尽一致,同时农产品品种的多样性和来源的复杂性,也使得进行全面检测和管理变得非常困难,因此利用各种研究成果、专家知识和历史数据,借助各种分析模型,通过对检测数据进行深度挖掘,使检测指标项目等更加具有代表性,具有非常重要的意义[18-19]。本研究从荞麦的18种氨基酸入手,根据甜荞和苦荞在氨基酸含量、比例方面的差异,筛选鉴别荞麦的有效指标,建立有效的判别模型,并检验模型的判别效果,为荞麦质量监控和判别提供新方法。
1 数据来源与方法
1.1 数据来源
数据来源于中国作物种质资源信息网(http://icgr.caas.net.cn),该网站为国家作物科学数据共享数据库。数据信息检索时间截止2012年6月9日,采用数据库中氨基酸数据完整的甜荞品种142个,苦荞品种66个,种质来源地列于表1。品质测定由各省区农业科学院作物品质分析中心按规定分析方法进行(http://icgr.caas.net.cn/cgris数据采集.html.)。
1.2 统计方法
Fisher判别,亦称典则判别,其基本思想是投影,即将原来在R维空间的自变量组合投影到维度较低的D维空间,然后在D维空间再行分类。投影的原则是使得每类内的离差尽可能小,不同类间的离差尽可能大。对于两类的Fisher判别可看作是把所有的样本都投影到一个方向上,然后在这个一维空间中确定一个分类的阈值,通过这个阈值点并且与投影方向垂直的平面就是两类的分类面。Fisher判别的原理如下:设有2个总体G1和G2,其均值分别为μ1和 μ2,协方差矩阵分布为 Σ1和 Σ2,并假定 Σ1=Σ2=Σ,考虑线性组合y=L′x。通过寻找合适的L向量,使得来自2个总体的类间距离较大,类内距离较小。可证明,当取 L=cΣ-1(μ1-μ2),c≠0时,所得投影即满足要求。c=1时的线性函数y=L′x=(μ1-μ2)′Σ-1x,称为 Fisher判别函数。判别规则为 y≥m,则 x∈G1;y<m,则 x∈G2。其中 m=(L′μ1+L′μ2)/2=[(μ1-μ2)′Σ-1(μ1+μ2)]/2,m为 2个总体均值在投影方向上的中点。
Fisher判别的优势在于对分布、方差等都没有什么限制,应用范围较广,且依此法建立的判别方程可直接用手工计算的方法进行新观察对象的判别,非常方便[20]。
数据用Microsoft Excel软件整理、制表,分别采用氨基酸的质量分数和氨基酸在总氨基酸中的相对含量为变量,使用SPSS13.0统计软件中的Analyze→Classify→Discriminant进行分析。采用Wilks'lambda(即 Wilks'λ法)和 stepwise method(逐步法),其判别准则是:进入模型的F值大于3.84,从模型中剔除变量的F值小于2.71,建立Fisher判别方程。验证方法采用回判验证和交互验证法。回判验证是根据判别准则将样本逐一代入,评价判别效果。交互验证是近年来逐渐发展起来的一种非常重要的判别效果验证技术,是在建立判别准则时逐一去掉一例,再用建立的判别准则对该例进行判别,交互验证与回判验证相比错分率可能会增加,但结果更真实、客观,是评价判别准则效能的可靠指标[21-23]。正确率=正确分组的样本个数/总样本的个数,错误率=错误分组的样本个数/总样本的个数。

表1 种质编号及来源
1.3 验证试验的材料与方法
1.3.1 主要仪器与试剂
Biochrom 30型氨基酸自动分析仪:英国 Biochrom公司;真空干燥器:上海博迅实业公司;氨基酸标准品:Sigma公司;盐酸(优级纯):国药集团化学试剂北京公司。
1.3.2 样品来源
荞麦样品由山西省农科院农产品加工研究所提供,12份(与表1中品种无重复),其中甜荞,苦荞各6份,荞麦样品材料经脱壳,磨粉,过40目筛,备用。1.3.3 氨基酸成分分析
准确称取约40 mg的荞麦粉于试管,充氮气,密封,用12 mL 6 mol/L HCl在110℃水解22 h后(色氨酸用4 mol/L NaOH溶液,110℃水解20 h),定容至25 mL,取1 mL水解液在40℃真空旋转蒸干,然后用pH 2.2柠檬酸盐缓冲液定容至50 mL,用0.45 μm有机微孔滤膜过滤,采用Biochrom 30型氨基酸自动分析仪进行测定:钠离子交换柱(8μm,4.6 mm×200 mm),进样体积20μL,运行时间50 min。
2 结果与讨论
2.1 质量分数法判别结果
荞麦含有18种氨基酸(见表2),其中8种人体必需氨基酸含量丰富。甜荞氨基酸质量分数最高的是:谷氨酸>天冬氨酸>精氨酸,苦荞氨基酸质量分数最高的是:谷氨酸>天冬氨酸和精氨酸,二者基本一致。甜荞氨基酸质量分数平均为11.08%,苦荞氨基酸质量分数平均为10.99%,二者差异不显著(t=0.359,P>0.05)。氨基酸的平均变异系数甜荞为25.68%,苦荞为19.99%,甜荞的氨基酸平均变异系数高于苦荞。

表2 荞麦氨基酸质量分数/%
氨基酸是构成生物体蛋白质分子的基本单位,在生物体内具有特殊的生理功能,是生物体内不可缺少的营养成分之一,其含量也是评价荞麦品质的重要指标。分析表明,苦荞与甜荞在氨基酸总量上无显著性差异,其中含量最高的氨基酸都是谷氨酸,这与王丽娟[24]的研究结果相同。从下面筛选出的6种氨基酸(见表3)含量的变异(见表2)显示,对于判别起重要作用的前5种氨基酸,甜荞的含量变异系数均大于苦荞的含量变异系数。这可能和种内的遗传多样性有关,甜荞属于虫媒花,异花授粉作物,而苦荞属于自花授粉作物。由于甜荞异花授粉,造成品种生物学混杂而出现品种内的遗传差异,而苦荞为自花授粉,一般不会出现品种内的遗传差异[25]。Deng等[26]对甜荞和苦荞品种遗传多样性进行RAPD分析所得结果:甜荞和苦荞种内均有一定的遗传多样性,并且甜荞种内的遗传多样性较苦荞大。高冬丽等[27]用SDS-PAGE研究亦显示甜荞籽粒总蛋白及蛋白质各组分的谱带具有丰富的多态性,而苦荞籽粒总蛋白及蛋白质各组分谱带的多态性有限。对荞麦氨基酸的分析结果显示,与二者研究结果具有一致性。
利用18种氨基酸,经8步(见表3),筛选出6种氨基酸作为判别指标,根据软件计算的标准化判别函数系数的绝对值(列于氨基酸后的括号中)大小,其判别效果依次为:组氨酸(3.037 0)>谷氨酸(2.115 2)>丝氨酸(2.069 7)>甘氨酸(1.998 1)>苏氨酸(1.265 3)>酪氨酸(0.360 1)。
采用质量分数法,由SPSS13.0软件计算得到Fisher判别函数 YA=-0.342 6-17.692 8Thr+19.052 1Ser-4.952 9Glu-19.632 5Gly+6.157 4Tyr+69.348 4His。函数中 Thr、Ser、Glu、Gly、Tyr和 His分别表示苏氨酸、色氨酸、谷氨酸、甘氨酸、酪氨酸和组氨酸的质量分数,甜荞的类中心为=-0.783 22,苦荞的类中心为:=1.685 11;判别的临界值为:Y1c=()/2=0.450 944。当 YA<Y1c时,判别为甜荞;当YA>Y1c时,判别为苦荞;当YA=Y1c时,待判。
采用质量分数法的判别结果(见表4),回判验证正确率为94.71%,错判率为5.29%;交互验证正确率为93.27%,错判率为6.73%。

表3 采用质量分数法的变量筛选过程

表4 采用质量分数法的荞麦判别结果
2.2 相对含量法判别结果
荞麦18种氨基酸的质量分数根据其在总氨基酸中所占相对含量转换后,变异系数大幅降低(见表5),甜荞降低57.28%,苦荞降低42.97%。经过6步(见表6),筛选出6种氨基酸作为判别指标,根据软件计算的标准化判别函数系数的绝对值(列于氨基酸后的括号中)的大小,其判别效果依次为:组氨酸/总和(0.852)>谷氨酸/总和(0.725)>甘氨酸/总和(0.712)>丝氨酸/总和(0.606)>苏氨酸/总和(0.481)>丙氨酸/总和(0.222)。

表5 荞麦氨基酸相对含量/%
采用相对含量法得到的Fisher判别函数YB=-13.071+228.937Thr/T-192.687Ser/T+66.249Glu/T+226.969Gly/T+77.689Ala/T-653.152His/T。函数中Thr/T、Ser/T、Glu/T、Gly/T、Ala/T和 His/T分别表示苏氨酸、色氨酸、谷氨酸、甘氨酸、丙氨酸和组氨酸的相对含量,甜荞的类中心为:y-21=0.776 6,苦荞的类中心为:y-22=-1.670 9;判别的临界值为:Y2c=(y-21+y-22)/2=-0.894 3。当 YB>Y2c时,判别为甜荞;当YB<Y2c时,判别为苦荞,当 YB=Y2c时,待判。
采用相对含量法结果见表7,回判验证和交互验证一致,正确率均为95.19%,错判率为4.81%,错判率小于采用质量分数法的6.73%。
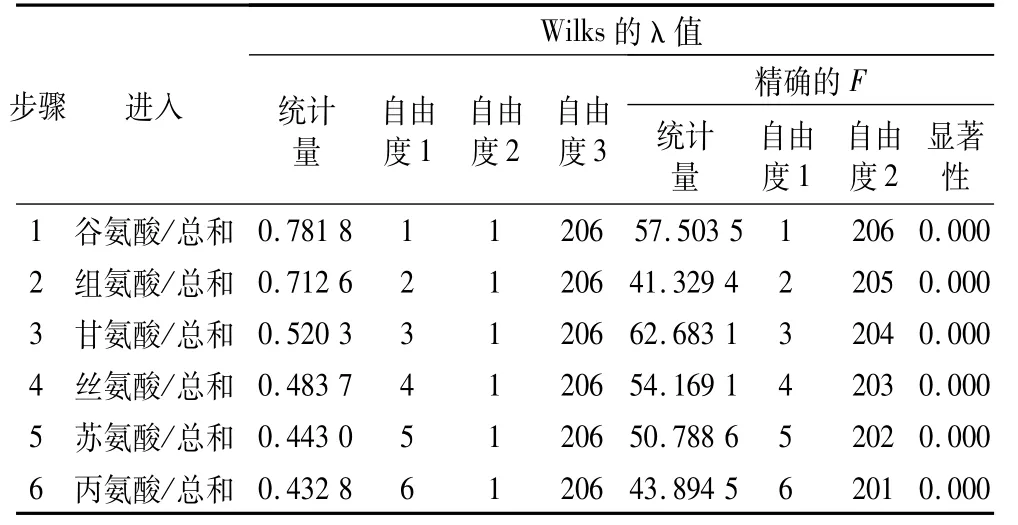
表6 采用相对含量法的变量筛选过程

表7 采用相对含量法的荞麦判别结果
2.3 验证试验结果
表8为12个荞麦样品中的氨基酸组分含量。将组氨酸、谷氨酸、丝氨酸、甘氨酸、苏氨酸、酪氨酸的值代入氨基酸质量分数法建立的判别模型A,所得函数值,根据YA<Y1c=0.450 99时,判别为甜荞;YA>Y1c时,判别为苦荞的原则,预测的全部结果与实际类别一致。
将氨基酸组分含量与总氨基酸含量的比值:组氨酸/总和、谷氨酸/总和、甘氨酸/总和、丝氨酸/总和、苏氨酸/总和、丙氨酸/总和,代入采用相对含量法建立的判别模型B,所得函数值,根据YB>Y2c=-0.894 3时,判别为甜荞;YB<Y2c时,判别为苦荞的原则,预测结果亦全部正确,结果见表8。研究表明2个判别模型高效、可行。
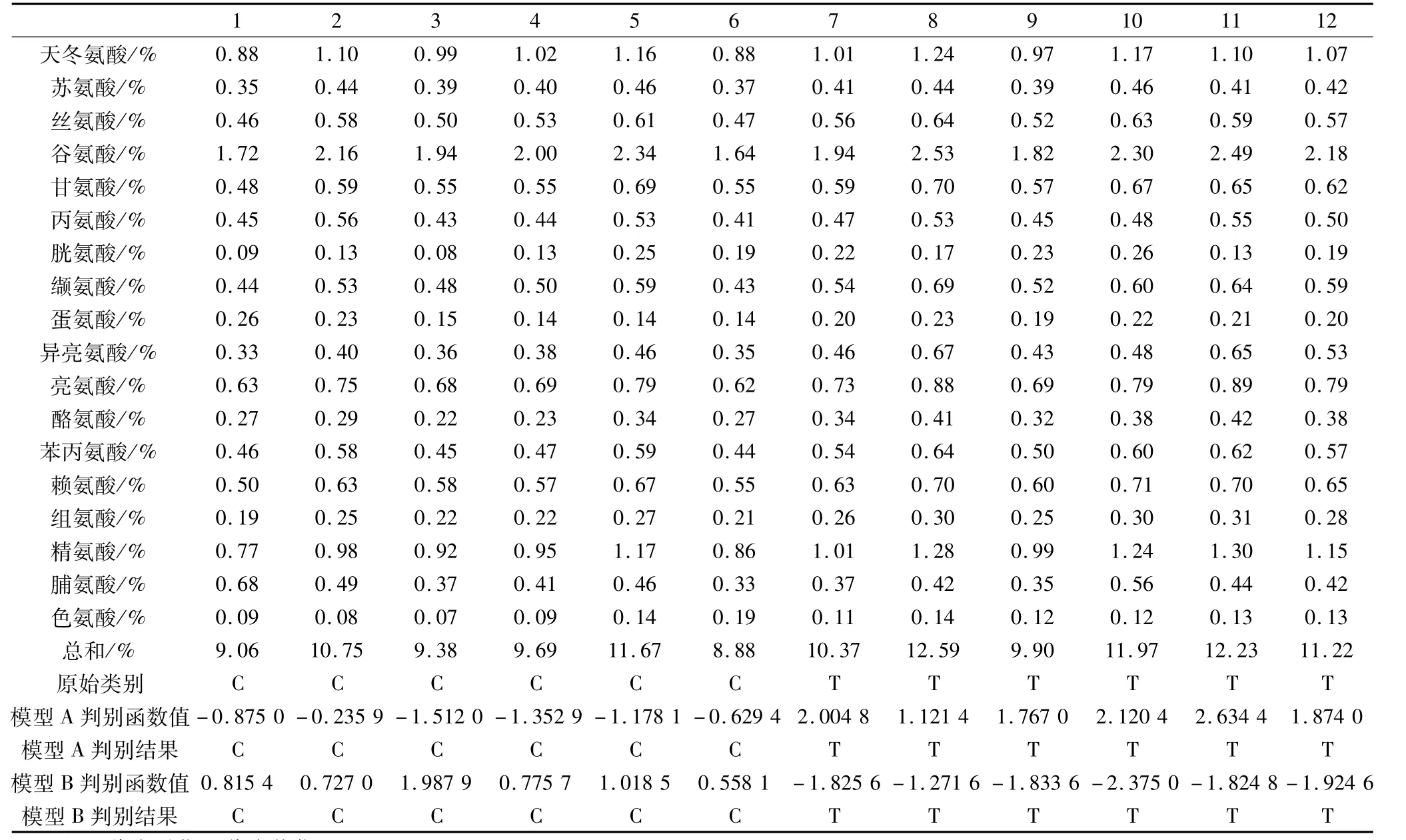
表8 荞麦材料中氨基酸含量及判别结果
相对含量法的正确率和稳定性高的原因是:相对含量法处理可以消除氨基酸总和波动对氨基酸含量的影响,起到一定的降噪作用,处理后甜荞和苦荞种内品种间的变异系数均不同程度减小,而种间的差异显著性不同程度加大,这与Fisher判别的投影原则是一致的,从而提高了判别的正确率和稳定性。判别效果一般用误判率来衡量,并要求误判率小于10%或20%才有应用价值[28]。因此根据氨基酸特点建立的2个Fisher判别模型均具有一定的应用价值,而且采用相对含量法建立的判别模型YB要优于采用质量分数法建立的模型YA。
3 结论
荞麦含有18种氨基酸,富含人体必需的8种氨基酸。甜荞与苦荞的氨基酸平均变异系数:甜荞(25.68%)大于苦荞(19.99%),但氨基酸质量分数总和差异不显著。
从国内外208个荞麦品种(其中甜荞品种142个,苦荞品种66个)的18种氨基酸中,通过逐步筛选发现在荞麦粉种类判别中,组氨酸、谷氨酸、丝氨酸、甘氨酸、苏氨酸、酪氨酸的质量分数,组氨酸、谷氨酸、甘氨酸、丝氨酸、苏氨酸、丙氨酸的相对含量可分别作为判别指标,根据质量分数法和相对含量法,所建立的2个Fisher判别模型,交互验证正确率分别为93.27%和95.19%,相对含量法比质量分数法判别正确率高1.82%,12个样本的实证正确率100%,表明2个Fisher判别模型能够较好的鉴别荞麦粉的属性类别,精度较高、易于掌握,具有实用性和方便性的特点,可作为荞麦粉种类鉴别和质量控制的一种有效、可行的方法。
[1]林汝法,周小理,任贵兴,等.中国荞麦的生产与贸易、营养与食品[J].食品科学,2005,26(1):259-263
[2]周小理,李宗杰,周一鸣.荞麦治疗糖尿病化学成分的研究进展[J].中国粮油学报,2011,26(5):119-121
[3]刘海静,孙素琴,李安,等.基于红外光谱三级鉴别技术的螺旋藻产品品质分析[J].中国农业科学,2012,45(22):4738-4748
[4]魏益民,郭波莉,魏帅,等.食品产地溯源及确证技术研究和应用方法探析[J].中国农业科学,2012,45(24):5073-5081
[5]Concha-Herrera V,Lerma-García M J,Herrero-Martínez JM,et al.Classification of vegetable oils according to their botanical origin using amino acid profiles established by high performance liquid chromatography with UV-vis detection:a first approach[J].Food Chemistry,2010,120(4):1149-1154
[6]Krishna Reddy M M,Ghosh P,Rasool SN,et al.Source identification of Indian opium based on chromatographic fingerprinting of amino acids[J].Journal of Chromatography A,2005,1088(1-2):158-168
[7]Helena SL,Poveda E G,Moya M SP,et al.Characterisation of 19 almond cultivars on the basis of their free amino acids composition[J].Food Chemistry,1998,61(4):455-459
[8]Kim K R,Kim JH,Cheong E J,et al.Gas chromatographic amino acid profiling of wine samples for pattern recognition[J].Journal of Chromatography A,1996,722(1-2):303-309
[9]张颖,张健,史珅.氨基酸含量分析判别梅鹿辄葡萄原酒产地[J].食品研究与开发,2011,32(5):9-12
[10]Soufleros E H,Bouloumpasi E,Tsarchopoulos C,et al.Primary amino acid profiles of Greek white wines and their use in classification according to variety,origin and vintage[J].Food Chemistry,2003,80(2):261-273
[11]Shen F,Ying Y B,Li B B,et al.Multivariate classification of rice wines according to ageing time and brand based on amino acid profiles[J].Food Chemistry,2011,129(2):565-569
[12]柯雪红,花汝凤,陈锦富,等.不同药厂补中益气丸中氨基酸类成分指纹图谱比对研究[J].中国实验方剂学杂志,2012,18(14):71-75
[13]张萍,闫继红,朱志华,等.近红外光谱技术在食品品质鉴别中的应用研究[J].现代科学仪器,2006(1):60-62
[14]严伟,张本能.甜荞部分营养成份分析及评价[J].四川师范大学学报:自然科学版,1995,18(4):93-96
[15]王丽娟.荞麦中氨基酸含量的分析[J].氨基酸和生物资源,1995,17(3):48-50
[16]韩梅.苦荞麦的氨基酸含量与营养评价[J].天然产物研究与开发,2000,12(1):39-41
[17]魏益民,张国权,胡新中,等.荞麦蛋白质组分中氨基酸和矿物质研究[J].中国农业科学,2000,22(6):101-103
[18]杨海东,丘慧澄.农产品质量安全检测管理决策支持系统及其应用[J].计算机工程与设计,2009,30(22):5229-5232
[19]张强,李艳琴.基于矿质元素的苦荞产地判别研究[J].中国农业科学,2011,44(22):4653-4659
[20]张文彤.SPSS11统计分析教程(高级篇)[M].北京:北京希望电子出版社,2002
[21]杜强,贾丽艳.SAS统计分析标准教程[M].北京:人民邮电出版社,2010
[22]黄晓韵,曹波,杨跃.基于 SAS的多元统计方法实现芯片数据挖掘[J].生物信息学,2010,8(2):147-149
[23]刘娟,崔树起,吕曼,等.基于非参数交叉证实判别分析法建社区脑膜炎诊断模型[J].数理医药学杂志,2010,23(1):8-10
[24]王丽娟.荞麦中氨基酸含量的分析[J].氨基酸和生物资源,1995,17(3):48-50
[25]王忠景,冯佰利,柴岩,等.甜荞品种内与品种间的遗传多样性研究[J].西北植物学报,2009,29(7):1314-1319
[26]Deng L Q,Zhang K,Huang K F,et al.RAPD Analysis for genetic diversity of nineteen common and tartary buckwheat varieties[J].Agricultural Science&Technology,2011,12(1):65-69
[27]高冬丽,高金锋,党根友,等.荞麦籽粒蛋白质组分特性研究[J].华北农学报,2008,23(2):68-71
[28]孙振球.医学统计学[M].北京:人民卫生出版社,2010.
The Fisher Discrimination of Buckwheat Based on the Amino Acids Characteristics
Zhang Qiang1Li Yanqin2
(College of Life Sciences,Shanxi Normal University1,Linfen 041004)
(Key Laboratory of Chemical Biology and Molecular Engineering of Ministry of Education Institute of Biotechnology,Shanxi University2,Taiyuan 030006)
According to the amino acid characteristics of common buckwheat and tartary buckwheat,this paper screened effective discrimination indexes and established a discrimination criterion.The mass fraction and relative content of amino acids were taken as indexes to establish a fisher discrimination model through stepwise method and verify the model.In the discrimination model established by the mass frastion method,the accuracy of discrimination was 94.71%and the accuracy of cross-validated was 93.27%taking histidine,glutamic,serine,glyeine,threonine and tyrosine as variables.In the discrimination model,which was established through the relative content method with the relative content of histidine,glutamic,serine,glycine,threonine and alanine for variables,the accuracy of discrimination was 95.19%and the accuracy of cross-validated was also 95.19%.The accuracy of the model adopting 12 buckwheat samples was 100%.The mass fraction and the relative content of histidine,glutamic,serine,glycine and threonine played an important role in the discrimination of buckwheat.The combination of amino acid index and modern statistical techniques should be a useful and feasible method for the discrimination and quality control of buckwheat.
common buckwheat,tartary buckwheat,amino acid,fisher discrimination,data mining
TS211.7
A
1003-0174(2015)02-0026-07
国家自然科学基金(30771300),山西省科技攻关(20 120311006-1)
2013-11-05
张强,男,1968年出生,讲师,植物资源开发利用
