程序向量化中非规则访存问题研究
2015-01-01徐金龙赵荣彩李晓亮
徐金龙,赵荣彩,刘 鹏,李晓亮
(1.数学工程与先进计算国家重点实验室,郑州450001;2.解放军93010部队,沈阳110000)
1 概述
目前多数通用处理器上已经集成了SIMD(Single Instruction Multiple Data)扩展[1-4]。为了方便有效地使用这种向量并行部件,大部分编译器也都集成了自动向量化模块[5-7]。为了实现更多程序的向量化,出现了很多面向向量化的分析方法,这些方法基本原理是依据数据依赖关系寻找可并行的语句,然后将可并行的语句用向量方式并行执行[8]。
向量化是一种细粒度的并行化,不仅需要依赖关系满足并行需求,对访存模式也有较苛刻的要求。目前,多数编译器自动向量化模块仅支持连续访存模式。大量访存模式较复杂的循环,编译器直接放弃对其进行向量化。GCC(GUN Compiler)和ICC(Intel C++Compiler)的向量化模块都尝试支持某些不太复杂的访存模式。GCC最初向量化模块只支持loop-based向量化方法,某些伪跨幅访存不能被正确识别,伪跨幅访存是指:语句被孤立分析时,访存不连续,但考虑迭代内并行其访存是连续的,因此,GCC引入了SLP算法发掘迭代内并行,解决了伪跨幅访存的问题[9]。ICC提供了一种高效的向量化方法来专门处理访存跨幅为2的幂的情况[10],并改进了数据重组方式,可以充分利用Intel处理器提供的跨幅访存指令。需要指出的是,GCC实际上并未支持跨幅访存的向量化,它仅仅是在迭代内发现了连续的访存,ICC真正支持了跨幅访存,但它支持的模式过于单一,难以支持较复杂的跨幅访存,不具有通用性,也不能支持程序中普遍存在的非规则访存。
本文提出一种面向向量化的非规则访存识别及处理方法,以消除非规则的访存对向量并行带来的不利影响。
2 访存特征的分类及检测
2.1 访存特征分类
本文提到的访存特征是指:对程序中多条访存指令访问的内存位置进行总结后体现出来的性质。本文概述中介绍了ICC和GCC的相关工作,对访存特征进行简单分类为4种情况,例1是最简单的连续访存模式,例2是GCC可处理的伪跨幅访存模式,例3是ICC可处理的简单跨幅访存,例4属于不规则访存模式。
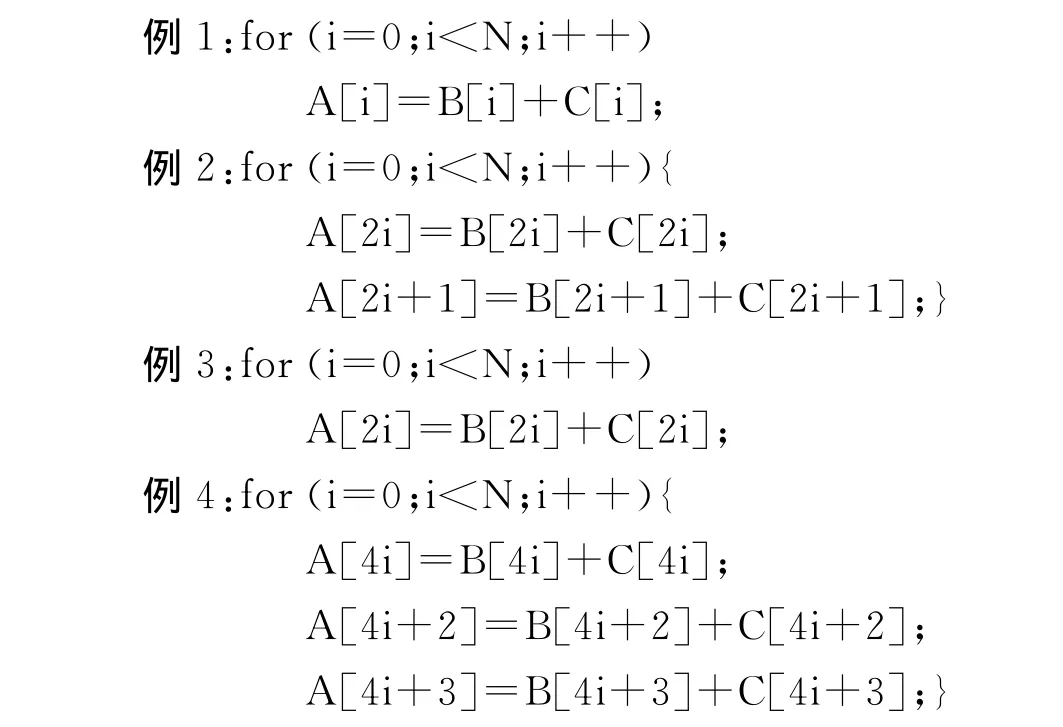
本节提供一种更细致的分类方法。由于经过向量化之后,数组的访存通常会变换为向量访存,而访存指令一般对应较大的执行代价,因此向量化主要关注循环中数组的访存特征,包括普通数组访存和结构体数组访存。本文假定不同数组名之间不存在别名关系,因此,对同一数组的多次引用进行分析才是有意义的。以普通数组访存为例来介绍一种访存特征分类方法。
数组访存具有以下3个性质:
(1)冗余性,即访存是否存在冗余,对同一内存位置的连续2次读或写显然是冗余的。冗余与非冗余的区别如图1(a)所示。
(2)饱和性,某段连续内存如果全被访问到,那么就称对这段内存的访问是饱和。饱和余非饱和的区别如图1(b)所示。
(3)顺序性,如果访存的地址是邻接递增(递减),或者通过合法的代码变换可使访存地址也具有这种性质,则称访存是顺序的,否则访存是乱序的。顺序与乱序的区别如图1(c)所示。

图1 数组访存性质示意图
向量并行化分析过程中对访存的上述3个性质最为敏感,本文依据访存是否冗余、是否饱和、是否顺序将访存进行详细分类,结果如表1所示,其中,T表示TRUE;F表示FALSE。
2.2 访存特征检测
显然,2.1节的访存特征都是基于多条语句所涉及内存的位置关系来确定的。访存特征的检测不仅要考虑统同一访存语句在不同迭代(相邻迭代)的内存位置关系,也要考虑不同访存语句在同一迭代中的内存位置关系。这是因为,仅对迭代内基本块进行分析只能得到局部访存特征,仅考虑迭代间又会忽略掉迭代内的访存特征,例如不能正确分析如例2所示的伪跨幅访存。
访存特征的检测较复杂,为便于检测,本文提出基于循环展开的访存模式检测方法:即先将目标循环展开,分析被展开循环的访存特征。本文方法的设计思想是,通过循环展开将迭代间访存特征检测转移到迭代内,然后在迭代内实施统一检测。
图2展示了访存模式检测的详细流程。
所谓西学之用,实为清廷应对日趋严峻的外交局面,有限度地变更旧制势在必行,被压抑的入侵文化的声音也因此得以显现于译文,现代法律意识的雏形伴随着殖民权力的扩张悄然扎根。尽管如此,中学为体的理念根深蒂固。洋务运动的中坚两江总督张之洞在《劝学篇》中甚至将三纲五常提升到国家民族生死存亡的高度:“保种必先保教,保教必先保国”(2002:1)。即便到了十九世纪末,维新变法的代表康有为依然鼓吹:“必有宋学义理之体,而讲西学政艺之用,然后收其用也。”
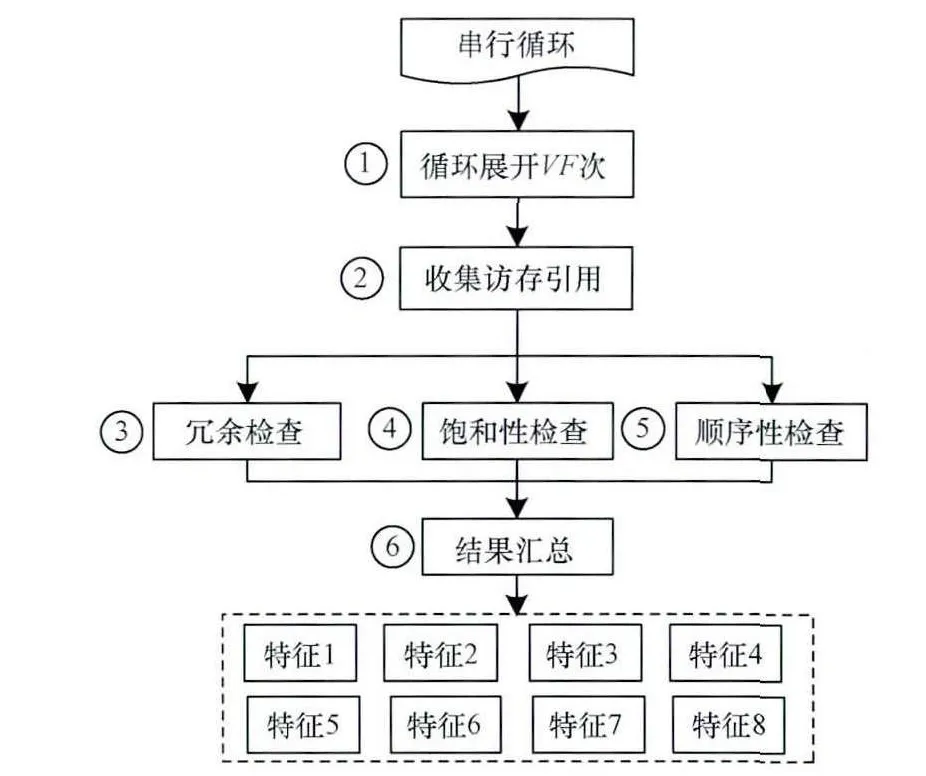
图2 访存特征检测流程
具体包括以下步骤:
(1)循环展开:SIMD向量并行实际上是一种全局串行,局部并行的并行方式。因此,面向SIMD的向量化只关注局部并行的几次迭代,向量局部并行的迭代次数最多为VF,因此,将循环展开因子设置为VF,可将充足的迭代间访存特征暴露在迭代内。后续的讨论中,假定VF=4。针对例1~例4所示程序做循环展开可得到如下结果,显然,例1和例2是无冗余饱和顺序的,而例3和例4是无冗余非饱和顺序的。

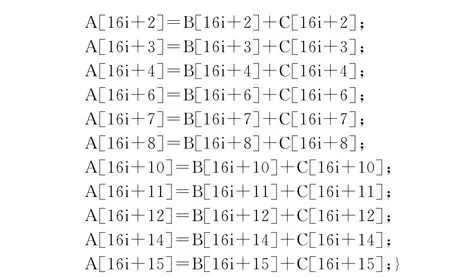
(2)访存收集及分组:遍历展开后的循环体基本块,收集其中所有内存引用,并为它们分组,依据分别为:读写类型、数组名称、数组访问索引系数。举例来讲,收集例1的展开版本中循环体中的引用,可得到3个分组:
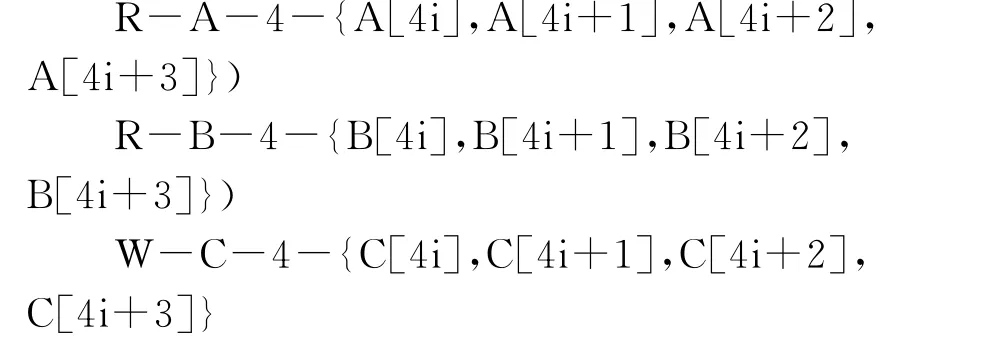
其中,第1项是读写类型(R代表内存读,W代表内存写);第2项为数组名称;第3项为索引系数,最后一项为符合前3项的访存对应的内存集合。
(3)冗余性检查:遍历步骤(2)所得到的所有分组,对每一个分组,遍历组内的访存语句,对比任意2个访存语句的内存位置,若相同,那么存在冗余读或写,标记这2条语句。
(4)饱和性检查:遍历步骤(2)所得到的所有分组,对每一个分组,遍历组内的访存语句,寻找组内语句访存位置的顶端和底端,如果这之间的任何一个内存位置都存在对应的访存语句,那么访存是饱和的,否则,非饱和。
(5)顺序性检查:遍历步骤(2)所得到的所有分组,对每一个分组,遍历组内的访存语句,判断访存语句访问的内存位置是否为递增或递减的。
(6)结果汇总:根据冗余性-饱和性-顺序性的检测结果得到综合特征。对某一循环进行上述3个性质综合后能够确定该循环的访存特征属于表1中的哪一类。
3 面向向量化的非规则访存处理
(1)无冗余饱和顺序模式是理想的访存模式,如例1和例3,足够的多次数组访存可直接用向量访存指令来代替。例1的对应向量化代码如图3所示。显然,向量化后的代码将会带来明显的效率提升。
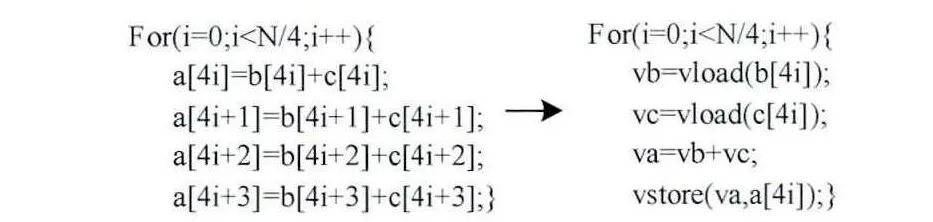
图3 无冗余饱和顺序模式代码的向量化
(2)对于无冗余饱和乱序模式,从整体来观察,多条语句的操作数访存顺序不对应,如图4所示,对数组a和数组b的访问顺序是一致的,数组c的访问顺序与前者不一致。将数组c读进向量寄存器后,需要调整数据的排序。通常数组访存顺序不一致的情况下,对其进行向量化需要用向量访存指令和混洗指令联合实现。
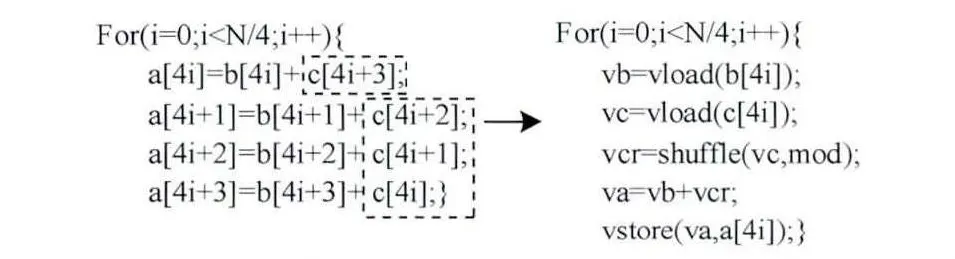
图4 无冗余饱和乱序模式代码的向量化
(3)对于无冗余非饱和顺序模式,相对于理想访存模式的不同点在于非饱和,这意味着需要将不连续内存中的数据装载到向量寄存器中并保证内存中不连续的数据在寄存器中是相邻的。具体方法为:采用普通向量装载指令装载不连续的数据,使用混洗指令在向量寄存器中组成相邻的数据。向量化结果如图5所示。

图5 无冗余非饱和顺序模式代码的向量化
(4)无冗余非饱和乱序模式,相对于模式3的不同点在于其乱序特性。由于可以采用数据混洗的方法来将乱序访存调整为顺序访存,因此它的向量化方法类似于模式3对应的方法,不同点在于混洗模式的配置,如图6所示。
(5)上文已经给出了表1中1~4的无冗余模式处理方法,对于存在冗余的情况,首先需要进行冗余删除,再按照上述的4种方法进行向量化,如图7所示。

图7 存在冗余模式的向量化
4 非规则访存向量化收益分析
4.1 必要性分析
第3节介绍了各种访存模式的向量化方式,从中可知,非规则的访存主要是通过规则向量访存与向量混洗结合的的方法来实现向量化。向量化后生成的混洗指令数目是不同的,不同平台的向量混洗的指令代价也是不同的,因此,向量化带来并行收益的同时,也需要付出多余的向量重组代价,并不是所有的向量化都能带来正收益,综合收益可能为0或为负。因此,必须通过精确的收益分析来指导向量化,若无收益或负收益,目标循环保持串行执行。
4.2 收益计算方法
向量化收益是指向量并行执行相对于标量串行执行所带来的性能提升,可以用串行标量执行代价(CS)减去并行向量执行代价(CV)来刻画,即:

并行向量执行代价CS是指用标量的方法将整个循环执行完毕所需要的时间,即每条标量指令执行时间的叠加,如式(2)所示,其中,ITER为迭代次数;CSi为每条指令的执行代价;m为基本块内标量操作的数量。
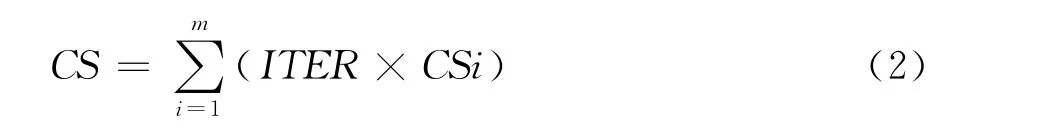
并行向量执行代价CV是指用向量的方法将整个循环执行完毕所需要的时间,即每条向量指令执行时间的叠,加如式(3)所示,其中,ITERV为向量化后的迭代次数;CVi为每条向量指令的执行代价;n为基本块内向量操作的数量。
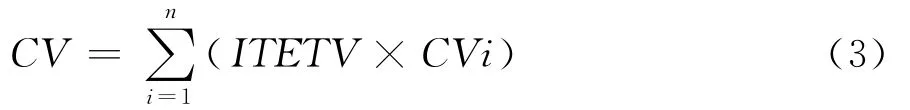
通过上述方法获得向量化收益B,若B>0,那么循环将被向量化,否则将保持串行执行。
5 功能验证
本文选取了gcc的testsuite测试集中符合条件的测试用例,包括vect-10.c,slp-8.c,slp-11b.c。另外根据测试需要对上述用例作调整产生新的版本,例如,vect-2的核心循环为:
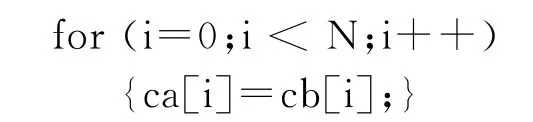
稍作改动即可产生“非饱和版本”:
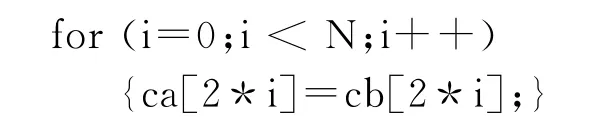
利用上述测试用例对本文提出的算法和GCC自动向量化进行测试得到如表2所示的结果。结果表明,本文方法可以处理文中提到的各类访存类型的向量化,而GCC只能处理“非冗余-饱和-顺序”的情况。显然本文方法在面向复杂访存类型处理方面强于GCC,达到了预期目标。

表2 功能验证结果
需要指出的是,本文方法目前主要应用于访存类型比较明确的小循环,存在很多更复杂的访存模式将影响本方法的使用,例如,代码中既存在饱和访存又存在非饱和访存。这属于需要进一步研究的内容,目前将直接跳过向量化阶段。
6 结束语
目前多数自动向量化算法的设计思路是:依据数据依赖关系寻找可并行的语句,通过循环变换使依赖关系符合向量化需求,然后将可并行的语句用向量方式并行执行。然而,对于非规则的访存研究者却没有提出统一的处理方法,非规则的访存成为制约自动向量化的关键因素之一。针对此情况,本文从访存特征入手,提出对访存特征的分类及检测方法,并最终给出了面向不同特征的向量化方法。
本文主要针对程序中的访存特征方面进行讨论,未将其他特征纳入到考虑范围,对此需要进一步深入分析研究。此外文中提供的向量化收益分析的前提是整个循环全部被向量化,对于部分向量化的程序并不适用,后续工作将继续完善非规则访存的向量化收益分析模块,使其具有更广泛的适用性。
[1]Intel Corporation.Intel®64and IA-32Architectures Software Developer’s Manual[EB/OL].[2014-11-15].http://www.intel.com/Assets/PDF/manual/252046.pdf.
[2]Stewart J.An Investigation of SIMD Instruction Sets[D].Ballarat,Australia:University of Ballarat,2005.
[3]Kahle J A,Day M N,Hofstee H P,et al.Introduction to the Cell Multiprocessor[J].IBM Journal of Research and Development,2005,49(4):589-604.
[4]D’Arcy P,Beach S.StarCore SC140:A New DSP Architecture for Portable Devices[Z].1999.
[5]Amarasinghe S P,Anderson J A M,Lam M S,et al.An Overview of the SUIF Compiler for Scalable Parallel Machines[C]//Proceedings of the 7th SIAM Con-ference on Parallel Processing for Scientific Computing.Philadelphia,USA:SIAM,1995:662-667.
[6]Naishlos D.Autovectorization in GCC[C]//Proceedings of 2004GCC Developers Summit.Ottawa,Canada:[s.n.],2004:105-118.
[7]Open64.Overview of the Open64Compiler Infrastructure[EB/OL].[2014-11-15].http://open64.source forge.net.
[8]Allen R,Kennedy K.现代体系结构的优化编译器[M].张兆庆,乔如良,冯晓兵,等,译.北京:机械工业出版社,2004.
[9]Rosen I,Nuzman D,Zaks A.Loop-aware SLP in GCC[C]//Proceedings of 2007GCC Summit.New York,USA:[s.n.],2007:131-142.
[10]Nuzman D,Rosen I,Zaks A.Auto-vectorization of Inter-leaved Data for SIMD[J].ACM SIGPLAN Notices,2006,41(6):132-143.
