改进型TF-IDF算法在软件开发过程控制中的应用
2014-12-28张鲲
张 鲲
(闽江学院软件学院,福州 350011)
软件企业随着业务的积累与规模的增加,其所积累的领域知识与管理知识也变得愈加丰富。这些知识对于企业的发展有重要的意义,但由于内容庞大,难以转化为对当前工作的支持。为了解决这一问题,需要对文档的相似程度即对文本进行分类。
1 文本分类相关技术
文本分类是自然语言处理中的一大研究重点。在这一领域有许多的研究方法被应用于文本的分类。参考文献[1]中使用了向量空间模型,将文本内容转化为易于数学处理的向量形式。参考文献[2]提出将各种特征加权算法与朴素贝叶斯分类器相结合,对不同的特征根据其分类重要性赋予不同的权值,使朴素贝叶斯扩展为加权朴素贝叶斯,以提高分类器的性能。也有研究借助外部词典分析词项之间的语义相似度,使用词项相似度加权树及文本语义相似度来计算两篇文本之间的相似度[3]。
TF-IDF算法是文本分类中一个重要的方法,该方法相关概念定义如下。
TF:TF为词频,反映某个词(特征)在文本中出现的次数。由于一些高特征词出现的频率与反映文本特征的某些词在词频上相差较大。因此取对数减少少数高特征词对特征权重的影响。即:
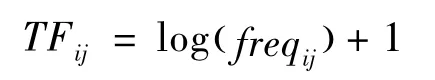
IDF:即逆向文档频度,指的是某一特征区别于其他文档的程度。根据统计结果,如果一个词在文档中大量出现,则该词并不能反映文档的特征。相反,若一个词在其他位置不怎么出现,而在某文档中虽然出现,但频率不高,反而有较大的可能是反映文档内容的重要词汇。因此IDF可表示为:

式中:n— 所有的训练样本数;ni— 出现特征词ti的训练样本数。
在获得TF与IDF后,TF-IDF算法描述如下:

为了避免词频受长文本的影响,通常需要对其做归一化处理:
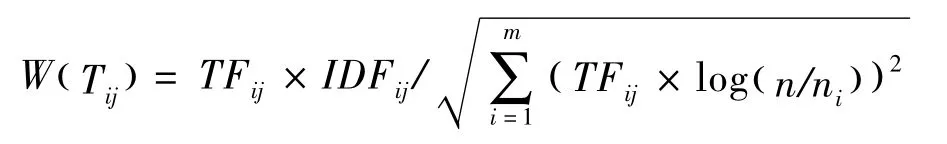
TF-IDF算法在文本分类领域应用较多,但也有其缺点。例如其无法真实反映某个特征的重要程度。在一些研究中,则采用信息熵增益、文本权重等方法对其进行了改进[4]。
2 文档搜索策略
软件企业中的相关文档有如下规律:
(1)长文本。开发性的文档一般都比较长,但内容相对简单,存在大量重复的描述语句。关键词出现的频率高。
(2)有限分类。与普通文本的多元分类不同的是在软件企业中,相关文档的类别相对清晰。开发类、管理类与市场类的文档可进一步分类,但类别较少。
对此,在相关规律的基础上可设计本研究的推理策略。
2.1 词典构建
词典构建是分词的前提。本研究中使用基于整词二分的分词词典机制(见图1)。
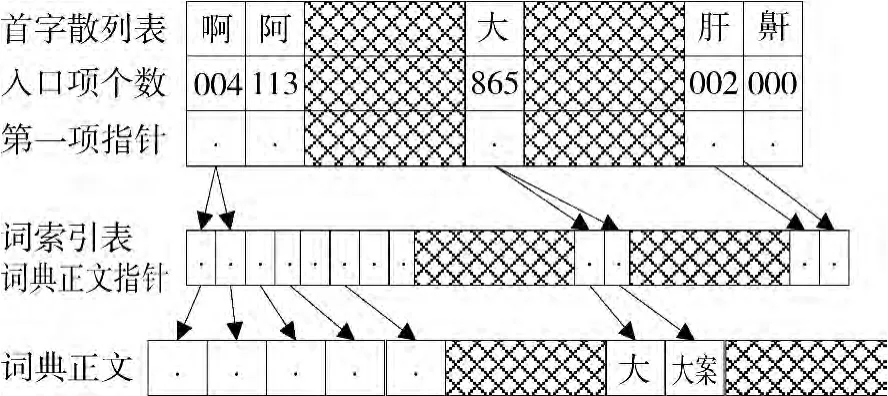
图1 整词二分的分词词典机制
整词二分法只能对一个字符串S是否是一个词进行判断,无法在扫描字符串的过程中判断S的一部分是否是可能的词。因此在查询过程中需要进行多次的试探。这种做法效率不高,但由于其原理简单,不需要复杂的构造过程与维护过程。
2.2 自动分词
为了将最大的复合词从语句中分离,本系统使用正向匹配算法(MM)来实现这一目标。正向匹配算法的思想是:设置k为一个滑动窗口,从文本中取出k个字符长度的字符串后将这字符串与词典进行比对。如果匹配不成功,则从k个字符中去除最后一个字符进行比对。如此反复,直到匹配切分出一个词或字符串长度为0为止。接着取k个长度的字符串进行分析,重复上述步骤直到文档被扫描完为止。正向最大匹配法流程见图2。
2.3 关键词提取
关键词的提取使用TF-IDF算法进行。此时需要计算TF值与IDF。即TF-IDF=(词频)TF×(逆向文档频度)IDF。由于TF-IDF与文档中出现的某个词成正比,文档中所有的词数成反比,所以计算出文档中每个TF-IDF值后按降序方式排列,并取出前N个词,这N个词则为自动提取的关键词。
由于TF-IDF算法存在一些不足,需进行较多的改进。此处根据应用目标的特征,对TF-IDF进行适当的改进。由于文档的类别较少,因此可在词库中设置每个词的权重。则:
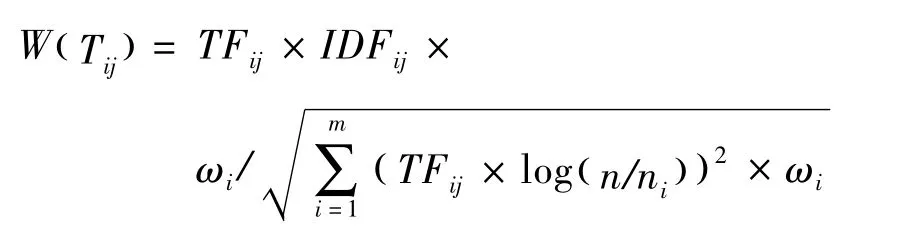
式中:ωi—特征i的权重。其值的计算在分词并统计词频后开始计算。在计算时需要进行同义词的合并。将得到的特征按词频降序排列后得如下序列:
A、B、C、D、E、F
若E与B是同义词,则将E的权重经一定的折算后加入B的权重。B的权重计算过程如下:
ωi=特征i的权重的权重*0.5)
j是在特征序列中B之后出现的B的同义词。
上述过程用伪代码描述如下:
Step 1:对文章进行分词,按TF-IDF统计并降序排列后得序列S。
Step 2:按顺序从S中取出一个特征T,并取其权重ω=0。
从词典中取得其权重ωi赋值给ω,查找T后的T的同义词T1,取其权重ωi*0.5加入ω。
删除T1,并查找后面的同义词,重复权重的加成,直到序列扫描完毕。
Step 3:对使用权重后的结果按降序重新排列,取前N个特征,达到关键词自动提取的目的。
在得到文章的自动关键字后,将该信息存储于文档的关联区域,后续进行文本相似度检索时不再重新计算。
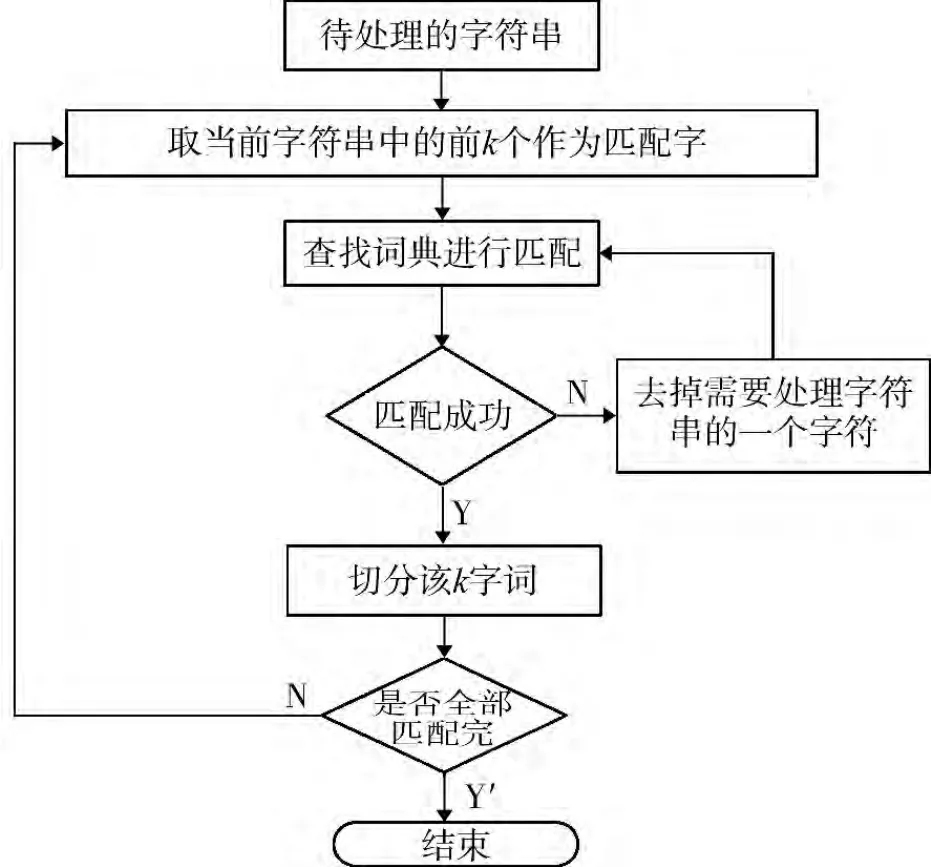
图2 正向最大匹配法流程图
2.4 相似文章的检索
当使用者输入检索条件时,可将检索条件看成一个n维的向量。相似文章的检索问题可以转化为计算方向角来求解。
设用户用以下顺序输入关键字进行检索:
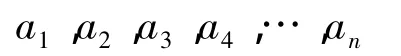
则对于a1,…,an可为每个关键字自动分配一个权重,可认为第一个输入的权重最高,第二个次之。则得到了一个n维向量,每个维度上的值使用词典的默认值。
而被搜索文档中被自动提取的关键字则组成了一个m维的向量。由于2个向量维度不一样,在计算前需要降维。一般而言,被搜索文档中的自动关键词维度大于用户输入的条件的维度,需要对文档中的自动关键词进行降维。即抛弃被搜索文档中不在用户输入的条件中的自动关键词,被搜索文档中的自动关键词是用户输入条件中的同义词,则该关键词的权重进行处理后可以保留。
设用户输入的为{a,b,c,d,f},而某文档中的自动关键词及权重为:{a,c,d,e,f},{0.9,0.81,0.80,0.79,0.66},则自动关键词在用户输入维度上的向量为{0.9,0,0.81,0.80,0.66}。
当2个向量具有相同维度后,可计算2个向量的相似性。根据向量代数的性质,两模相等的向量同向时两向量相等,则可把两向量的相似度转化为求向量的夹角。
由向量数量积的概念可知:
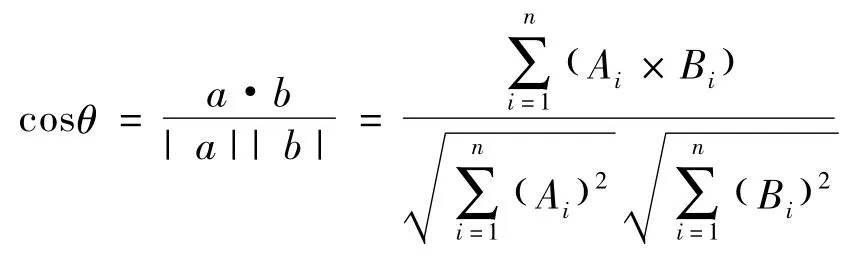
式中:Ai,Bi是向量a,b在向量维度上的分量。
根据一定的阀值,过滤小于cosθ的查询结果,就可得到与检索条件接近的文档。
在具体实施中还对查询的结果进行一定的排序,排序策略为:所有关键词全部匹配检索条件的文章首选,部分匹配检索关键词和部分匹配检索关键词的同义词的文章排第二,部分匹配检索关键词的文章排第三,全部匹配检索关键词的同义词的文章排第四,部分匹配检索关键词的同义词的文章排第五。处理完毕后则可将结果呈现给查询者。
2.5 关键词纠错与词库的管理
由于用户输入的不一定是分割后的关键词,更有可能是包含多个关键字的句子,对于关键词也需要进行分词处理。然而用户的输出也存在众多错误的可能,最常见的是使用拼音输入法造成的同音不同词,因此需要对用户的输入进行纠错。针对这一问题,在词库中设立混淆集,即将同拼音的词存放在一个集合中。当扫描到一特征时,要从混淆集中查找是否有更为合适的特征。
词库维护时,词库中需要记录混淆集中出现的特征的句子,并计算与其组合的其他特征的关联程度。这是从混淆集中查找是否有更为合适特征的依据。
另外,词库还需要提供对新词、同义词的管理,此处不进行介绍。
3 实验及结果
在本研究中对TF-IDF算法进行了局部的改进,在使用前要用实验来检验算法的结果。检验的文档从公司的文档服务器中提取共计1 762篇,其中公司治理文档121篇,客户资料208篇,开发技术文档591篇、市场文本299篇,行业新闻543篇。采用以下方法选择训练集和测试集:在543篇行业新闻中选取501篇作为训练文本集。在其他类别的文档中各抽取10篇,并与行业新闻中剩余的文档组成测试集,自动提取的关键词与人工给出的结果见表1。

表1 实验结果
使用改进式得到的结果与使用TF-IDF算法相比,关键词提取的效果有了明显的改进。
4 结语
本研究目前已被应用于一家软件企业的日常管理。在人事管理、开发管理、客户管理等多个领域均发挥了重要作用。
[1]韩家炜.数据挖掘技术与概念[M].北京:机械工业出版社,2007:223,258.
[2]秦锋,任诗流,程泽凯,等.基于属性加权的朴素贝叶斯分类算法[J].计算机工程与应用,2008(6):111-113.
[3]黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011(5):98-106.
[4]陆玉昌,鲁明羽,李凡,等.向量空间法中单词权重函数的分析和构造[J].计算机研究与发展,2002(10):55-60.
