基于文本行重构的扭曲文档快速校正方法
2014-12-23曾凡锋吴飞飞
曾凡锋,王 晓,吴飞飞
(北方工业大学 信息工程学院,北京100144)
0 引 言
OCR 在识别扭曲的文本图像时,常常会因为自身版面分析算法的局限性而导致文字无法识别或者识别率很差,乱码很多,在一些对识别率要求高的应用中 (例如启视助视仪)使用受限,因而需要在OCR 识别之前将扭曲的图像校正,以提高其识别率。
为提高OCR 对扭曲文本图像的识别率,国外对英文扭曲文档校正做了很多研究,而国内对中文扭曲文档的研究很少。目前针英文扭曲文档图像的校正技术可分为3 类:①基于3D 技术的校正方法[1,2]。该类方法能很好的恢复扭曲的文档页面,但需要特殊的辅助设备,对于面向市场的各种阅读产品来说实用性不大。②基于模型的校正方法[3]。该类方法能对含有图表等非文本元素的文档图像进行校正,但其校正方法较为粗糙,检测与校正结果欠佳。③基于连通域的方法[4-6]。此方法在英文扭曲文档的研究很多,效果也很显著,文献 [5,6]采用了连通域的方法来处理中文扭曲文档,但是增加了很多限制规则,无疑增加了算法的复杂度,而且其采用的图像必须是特殊定制的,稍微改变扭曲图像,此方法便不再适用。中文字体有其自身的复杂性,分为上下结构和左右结构,单纯的移植处理英文扭曲文档的方法是无法校正中文扭曲文档的。文献 [7]提出了利用文本线校正中文文档的思想但没有给出实际的可行方案,文献 [8]采用了此种方法,使用的是机器人阅读设备,但是其使用前提是纸张大小必须固定,页面扭曲必须一致,对于在自然情况下采集的文本图像,由于书页本身的扭曲就不统一,利用此方法校正图像后的识别效果很差。
通过以上的分析总结,提出了一种新的扭曲中文文本图像校正方法,用于校正自然扭曲的图像,图像的大小不小于32开,字体大小不小于6号。首先将图像处理为二值图像,利用形态学膨胀的方法获取文本行轮廓,游程平滑来填补文本行轮廓内的空洞,然后提取每行的文本中心线,估计文本行的上下边缘,利用提出的模型和重构算法针对每一文本行进行校正。
1 基本概念介绍
1.1 二值膨胀
二值膨胀是形态学处理图像的基本操作,具有模糊图像细节和扩张图形的功能,适当结构元素的选取可以填平图形内部和边缘的不规则结构,采用二值膨胀能达到更好的处理效果。其定义如下

一副文本图像中往往存在汉字、数字、字母、标点这4项基本内容,这些字符的共同点是比划之间都存在大量细小的空洞,通过二值膨胀可以有效的填补这些细小空洞,而文字行与行之间的间隔相对来说是很大的,在对文字行进行二值膨胀的过程中对文字行之间的影响是很小的。因此,为减小误差、提高拟合曲线的精度,合适的结构元素b的选取十分重要,既要消除各行文字之间的差异,填补空洞,又要注意不能使行与行连通在一起,从而实验中采取2×5的结构元素使文字横向尽量延伸,纵向略微延伸,并重复3次以尽量突出各行轮廓和消除文字内的空洞,膨胀的局部效果图如图1所示,左侧大黑块和底部窄黑条都是噪声。

图1 膨胀效果局部
1.2 游程平滑处理
该算法的基本思想是将图像中水平或垂直长度小于设定的阈值T 的连续白像素转化为黑像素。经过二值膨胀后的文字行内依然会存在很多细小的空洞,利用游程平滑算法可以有效地填补这些细小空洞。假设图像中垂直方向有一段游程R= (L1,L2,…,Li,Li+1,…,Lj,…,Ln),R1= (L1,L2,…Li-1)和R3= (Lj,…,Ln)都是黑游程,R2= (Li+1,…,Lj-1)是白游程,当R2的长度值ji-1小于门限值T 时,就将黑游程R1和R3连通在一起即把白游程R2全部平滑为黑。图2所示的平滑过程中T=5,平滑前右侧两个1-游程之间的0-游程长度为4,按照以上的原理被平滑为1-游程,从而得到连通起来的1-游程为9,而对于中间的0-游程长度为5,等于T,则不做处理。

图2 游程平滑过程
为确保准确的提取文本行中心线,利用此方法垂直遍历图像,连接膨胀处理遗漏的文本行空洞。
2 提出的方法
为了提高自然扭曲中文文本图像的OCR 识别率,校正是针对每一文本行进行的,这就面临两个基本问题,一是如何获取各行的文本线,二是如何将各行扭曲文本还原到正常的位置。针对这两个问题,提出的方法如图3所示。
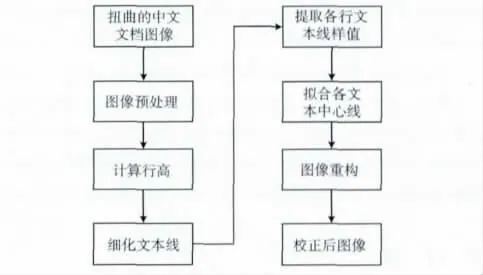
图3 扭曲文档校正流程
2.1 图像预处理
首先将图像处理为灰度图像,对于一个三分量为R,G,B的彩色图像,灰度值的计算采用如下公式
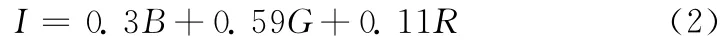
然后进行图像的二值化处理,本文采用文档图像前景色为黑色 (0),背景色为白色 (255),由于研究的重点是如何校正扭曲中文图像故采用OTSU 算法[9]而没有采用Niblack算法,OTSU 算法快速但没有Niblack算法效果优,但大津算法在光照均匀的条件下能很好的区分出前景和背景,即使二值化效果不理想,通过第三步的文本线样值提取算法可以很好的消除这种影响。
2.2 计算行高
行高值是一个关键值,后面文本线的细化,文本线样值提取和最终的校正都需要行高作为参照,而且利用行高可以有效地排除噪声。采用游程平滑的方法计算,由于图像中间部分的噪声比较少,影响游程平滑的因子少,故选取图像宽度的1/3,1/2,2/3 处的列进行遍历,取3 列是为了取平均值计算更精确的行高。具体的检测规则如下:
规则1:如果p(CheckPos)=0,则其相应的统计值count加1;如果p(CheckPos)=255,则先判断count是否为0,如果不为0,将count 值保存在链表LinkedList 中后置0。按此方法直到遍历结束。
记p(CheckPos)为当前检索位置CheckPos 处的像素值,count为黑像素统计个数,LinkedList 用于存储count。之后计算出LinkedList的平均值AverLineHeight。为消除图像中细微噪声和图片的影响,需要删除满足式 (3)的值

AverLineHeight*4是一个保守值,既是消除了大图片,也防止了标题字体被误删,如图6所示的标题字体就比正文字体三倍。
重新计算LinkedList的平均值,保存在AverLineHeight中,此时的AverLineHeight才是精确的行高。
2.3 细化文本线
为得到图像每行文本的实际中心线,遍历平滑后图像的每一列,分别得到各个联通黑像素的个数,记为Count,若Count满足式 (4),则在新图像的对应位置处置黑,否则将Count置0
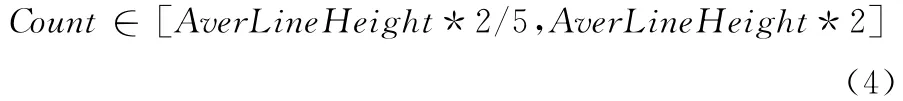
此范围是防止文字行高度过低和噪声区域膨胀过大。此时便得到了各行文本线,如图4 所示。利用此方法图1所示的大噪声都已全部被消除。

图4 细化文本线局部
2.4 文本线样值提取
由于二值图像边界处噪声多,对于起始点很难判断出其属于哪一条文本线,如果具体分析的话会费时费力,而图像中心处噪声少,即使噪声多,利用模板提取的方法和后期的二乘拟合完全可以忽略这些影响,所以为避开从两头开始提取样值时的困难,并且考虑到纸张大小和文字大小的影响,故选择AverLineHeight*AverLineHeight 大小的模板,基于行高的搜索模板可以很好的自动适应不同样张,利用该模板从图像的中心向两边提取中心线样值,如果在该方向的模板内发现目标像素,则以此像素为起点继续利用该模板在该方向检索,直到模板内无目标像素为止,此时需要的样值就是各个模板内的目标像素。在实际的实验过程中,利用这种方法提取的样本值拟合后的曲线经常与原曲线相差很大,这是因为原文本线的长度短,样本个数不足以保证还原为原曲线,经常发生在一段结束的最后一行,文字太少,所以在提取文本线样值的过程中需遵循以下规则。
规则2:检索完一条线之后,若采集的样值数量大于imgWidth/3,保存这些样值,并为这些样值标号i(i=1,2,3,… ),否则删除这些样值。对于这种太短的文本线,本算法会将其删除掉。
规则3:检索完一条线之后,若采集的样值数量大于imgWidth/3,小于imgWidth*2/3,则复制向右搜索的最后一个样本值来延长这条曲线。这种文本线的样值拟合后的曲线往往出现甩尾的现象,影响上下行边界处文字的校正。
检索完所有曲线样值后,获取不同标号i的样值的左端点,连同i 一起记录在链表Point中,以备最后校正使用。
2.5 最小二乘拟合
文本线样值提取之后需要用曲线来拟合这些文本行,本文采用最小二乘拟合[10],利用式 (5)
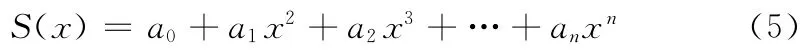
式中,a0,a1,a2,…,an——待 得 到 的 曲 线 系 数,n——曲线的幂值,此处取正整数4,基本能达到复原曲线的效果,而对于幂值能达到5以上的曲线,拍摄到的原图像已经是不完整的了,没有进行校正的必要。
2.6 图像重构
由于以上得到的文本线都是文本中心线,对整行文字的重构需要知道文字行的高度,虽然已得到文字行的平均高度AverLineHeight,但文本文档中字体的大小也有不同,例如标题比正文文字要大很多,如果单纯的依赖AverLineHeight来估计文本行的上下位置的话,对于字体大小不统一的文本图像,校正的中心会脱离文本行,校正后的图像识别率也会大打折扣。本文采用的估计行高的方法为如式 (6)
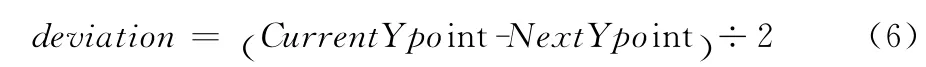
CurrentYpoint 为当前曲线的左端点垂直坐标值,NextYpoint为下一条曲线的左端点垂直坐标值,即记录在Point中的纵坐标值。采用的校正模型如图5所示。

图5 文本行重构模型
图5中1号线为拟合后的文本中心线,2,3号线是根据1号线加减deviation 得到的文本行上下边界线,(X0,Y0)和(Xn,Yn)为中心线的起点和终点,拟在将图5中2,3包络的扭曲文本行区域重构为图5下半部分的矩形区域。文本行的重构体现在垂直方向的像素如何正确的分布在所示的矩形区域内,因而采用式 (7)

式中,CurrentHeight——新图像中预重构像素的垂直位置,AutoReviseHeight——原图像对应CurrentHeight 应取像素的垂直位置,OriginalHeight——图5中2,3包络的垂直位置,计算式如下
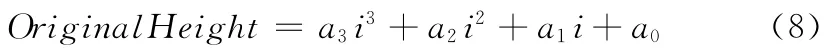
式中:i——文本行 区 域 的 横 坐 标,a3,a2,a1,a0——拟合曲线的系数。

式中:X——矩形区域内横坐标,a3,a2,a1,a0——拟合曲线的系数。
在矩形区域内,按照式 (10)在包络区域内查找此处应取的像素点,便可很好地校正文本行

其中,F(X,Y)为新图像中X =i处的像素值,f(i,j)为原图像中(i,j)处的像素值,此处令X =i。deviation 和AutoReviseHeight为动态可变的,可以根据后期图像处理的需要制定新的规则作出改变。
3 算法测试和分析
3.1 测试环境
VS2005环境下采用C++语言实现,测试环境为:Inter(R)Core(TM)2Duo CPU E7400@2.80GHz;内存2GB;操作系统Windows XP。实验采用的书籍为486 页,采集图像的设备为数码相机,OCR 采用汉王OCR2.0 版本,图像版面内容为纯文本,采集的图像为正对书面垂直拍摄自然扭曲书页。采集到的图像大小均为1000*1667像素,测试的样张数为80张。
3.2 校正效果图对比
观察图6内各图可见,对于扭曲不统一的图像,文献[8]的校正效果差强人意,按最优曲线校正只校正了其中几行文字,有些位置反而更加扭曲,该种方法只能在限定条件的情况下才可达到理想效果,而本文的算法在实验中的有很好的适应性,在所有的测试样张中只有4张校正效果不理想,也只是发生在局部校正错误,对纯文本自然扭曲图像的校正成功率能达到95%,由此可见本方法更优。

图6 校正效果对比
3.3 校正速度和OCR 识别效果
实验利用采集的80张样张进行测试,总结的实验数据见表1。

表1 校正时间和OCR 识别率
平均识别率未达到95%以上,是由于采集的图像自然,很多图像出现了光照不均的现象;还有些图像中书脊处的文字本身就未拍照完全,OCR 根本无法识别;再加上OTSU 算法的没有广泛的适应性,这都很大程度上影响了OCR 识别率。对于那些光照均匀,书脊处拍照清晰的图像,校正后识别率能够达到95%以上。
本算法在时间上相比其它算法速度提高很多,对于1000*1667像素的图像,平均校正时间只需430ms。文献[11]提出的快速校正算法校正600*800像素的图像所需时间大于2s,如果用于校正本实验的样张,所需时间必大于4s。相比于文献 [4-6,11]的基于连通域的方法,本方法更是大幅提高了校正速度,连通域本身就是一个复杂的搜索方法,在原二值图像各像素被标记完之后一般会用到递归的方法进行分析等价对,这无疑是最耗费时间的过程,而本文算法只是利用了各行文本中心线的少量样值而已,处理的数据量大大减少,而且中文不同于英文,连通域搜索需要更多的规则进行分析,而本文算法中英文通用。图像的获取比较自然,不依赖于特殊设备,适合实时性的需求。
4 结束语
本文为解决OCR 识别扭曲文档图像识别率低的问题,提出了基于文本行重构图像的方法。首先运用形态学膨胀的原理获取图像行的轮廓,而后估计出文本行上下轮廓曲线,利用给出的模型进行图像重构,并针对各行分别进行校正。该算法已经可以保证在500ms之内校正1000*1667像素的图像,极大地提高了运行效率,而且校正效果良好,OCR 识别率显著提高,相信经过后续的改进,该算法校正图像的OCR 平均识别率会达到95%。该算法的适应性广,经过进一步的测试,对扭曲英文文档同样具有良好的适应性,对于含有图片的简单版式扭曲文档同样可以无误校正。
由于OCR 进行图像识别时,内部也是首先进行了二值化,故下一阶段的目标是在灰度图像上实现校正,以避免与OCR 进行重复的二值化操作。
[1]Lilienblum Erik,Michaelis Bernd.Book scanner dewarping with weak 3d measurements and a simplified surface model[G].LNCS 4992:Discrete Geometry for Computer Imagery.Berlin:Springer Berlin Heidelberg,2008:529-540.
[2]Lilienblum Erik,Niese Robert,Al-Hamadi Ayoub,et al.A stereo vision system for top view book scanners[J].International Journal of Computer Science,2010,5 (1):32-37.
[3]Fu Bin,Wu Minghui,Li Rongfeng,et al.A model-based book dewarping method using text line detection [C]//Proc of the 2nd International Workshop on Camera-based Document Analysis and Recognition,2007:421-425.
[4]Gatos B,Pratikakis I,Ntirogiannis I.Segmentation based recovery of arbitrarily warped document images [C]//International Conference on Document Analysis and Recognition,2007:989-993.
[5]Hong Liu,Ye Lu.A method to restore Chinese warped document images based on binding characters and building curved lines[C]//IEEE International Conference on Systems,Man,and Cybernetics,2009:984-988.
[6]Hong Liu,Runwei Ding.Restoring Chinese documents images based on text boundary lines [C]//IEEE International Conference on Systems,Man,and Cybernetics,2009:571-575.
[7]TIAN Xuedong,MA Xingjie,HAN Lei,et al.Geometric rectification for camera-captured document images [J].Computer Applications,2007,27 (12):3045-3047 (in Chinese).[田学东,马兴杰,韩磊,等.视觉文档图像的几何校正[J].计算机应用,2007,27 (12):3045-3047.]
[8]ZHANG Weiye,ZHAO Qunfei.The layout analysis and document image preprocessing algorithm of reading robot[J].Microcomputer Applications,2011,27 (1):58-61 (in Chinese).[张伟业,赵群飞.读书机器人的版面分析及文字图像预处理算法 [J].微型电脑应用,2011,27 (1):58-61.]
[9]Xue JingHao,Titterington D Michael.T-Tests,F-Tests and Otsu's methods for image thresholding [J].IEEE Transactions on Image Processing,2011,20 (8):2392-2396.
[10]LONG Huiping,XI Shengfeng,HOU Xinhua.The algorithm and analysis from experiment data by means of minimum double mutilplication [J].Computing Technology and Automation,2008,27 (3):20-23 (in Chinese).[龙辉平,习胜丰,侯新华.实验数据的最小二乘拟合算法与分析 [J].计算技术与自动化,2008,27 (3):20-23.]
[11]SONG Lili,WU Yadong.New document image distortion correction method [J].Journal of Computer Applications,2010,30 (12):3317-3320 (in Chinese). [宋丽丽,吴亚东.文档图像几何畸变快速校正的新方法 [J].计算机应用,2010,30 (12):3317-3320.]
