基于语法语义知识的维吾尔文机构名识别
2014-12-23麦合甫热提米日姑肉孜麦热哈巴艾力吐尔根依布拉音
麦合甫热提,米日姑·肉孜,麦热哈巴·艾力,吐尔根·依布拉音+
(1.新疆大学 教务处,新疆 乌鲁木齐830046;2.新疆大学 多语种信息技术重点实验室,新疆乌鲁木齐830046;3.新疆大学 信息科学与工程学院,新疆 乌鲁木齐830046)
0 引 言
维吾尔语中机构名的构建比较复杂,机构名又包括人名、地名,所以维吾尔语中机构名的自动识别还包括人名和地名的识别,表明机构名识别的难度。在中文机构名识别领域中,研究者进行了一系列的研究并取得了不错的成果,但还需要继续探讨和研究。维吾尔文机构名识别又是一个新的挑战,由于语义、语法上与汉语、英语等语言不同,维吾尔文机构名识别存在很大的难度。
目前为止所采用的命名实体识别方法也可以分为3个主要类别:基于规则 (rule-based)的方法[1](文献 [1]把机构名分为简单型机构名和复合型机构名,分别建立模板进行识别。);基于统计(statistic-based)的方法[2](如:最大熵 (ME)[3]、支持向量机 (SVM)[4]、条件随机场(CRF)[5]等)以及基于规则和统计相结合[6]的方法。
维吾尔语的命名实体识别具有独特的语法和语义特性,英语和汉语中广泛使用的算法和模型不能直接套用。另一方面,由于目前尚没有较大规模的人工标注语料库,基于统计模型的命名实体识别研究仍然难以开展。我们针对机构名识别任务,立足于维吾尔语命名实体识别的研究现状,设计了基于维吾尔语语法和语义知识的机构名识别系统。通过研究维吾尔语机构名的构成规律,我们设计了有效地识别规则和相应的知识库,包括特征词库、修饰词库和地名库;依据这些识别规则和知识库,系统采用基于关键词匹配和状态转移原理的识别算法,快速准确地识别出候选机构名实体。
为验证机构名识别系统的有效性,我们从天山网新闻数据中选取有代表性的数百个实例构建了机构名识别的测试集。实验结果显示,我们的机构名识别系统具有很高地处理速度和识别精度,取得了F值83.05%的好成绩。在下一步的工作中,我们将继续深入进行维吾尔语机构名以及其他命名实体的识别研究,特别是尝试采用无监督和半监督等先进的统计学习技术,以及统计技术和语法语义知识相结合的改进技术。我们希望通过本工作起到抛砖引玉的作用,推动学术界对维吾尔语命名实体识别的研究进展。
1 维吾尔文机构名识别的难点
维吾尔语是典型的黏着性语言,是阿尔泰语系突厥语族成员之一,其词的形态及句子结构与汉语、英语等具有很大不同的特点。现行维吾尔文有8个元音字母,24个辅音字母,并且有120 多个字符形式。书写方向是从右到左,行向从上到下。每个字母按出现在词首、词中、词末的位置有2到8种书写形式。构词和构形附加成分很丰富,句子中的单词一般由词干与多个 (可以是0 个)后缀结合。词干后面缀接附加成分的时候,按维吾尔语语音和谐规律有些语音会发生弱化、脱落、增音等现象[7]。比如:对机构名特征词mektep (学校)而言,mektep+im (第一人称单数)=mektipim (我的学校)这里发生了语音弱化现象,也就是说mektep当中的最后一个元音字母e弱化成了i,这些现象加大机构名特征词识别的难度。
机构名识别工作的另一个困难在于机构名包含了人名、地名,同时存在大量的未登录词[8],因此机构名识别本身部分涵盖了人名识别、地名识别等工作,使得机构名识别工作比识别未登录的人名、地名还复杂。
本文分析了大量语料中机构名的组成特点,我们总结了维吾尔语中机构名识别的特点和难点总结如下:
(1)维吾尔文机构名组成方式复杂,且含有大量的其他命名实体。在这些命名实体中,地名所占的比例最大。如:Dora Zawuti(西安制药厂)中Shi’an(西安)是地名;Til Terbiylesh Merkizi(艾力西尔语言培训中心)中Elishir是人名等。被嵌套在机构命中的实体名能否准确识别出,会影响组织机构名的识别效果。
(2)机构名的长度极其不固定,长度从2个词到十几个词的情况都存在。如:Shinjang Universiteti(新疆大学)是由两个词构成的机构名;Zhongguo Komunistik yashlar ittipaqi Xinjang Uyghur Aptonom rayunluq zmin bayliqi nazariti(国共产主义青年团新疆维吾尔自治区国土资源厅)的长度达到了11个词。很显然这种情况会导致机构名边界的确定[9,10]。
(3)机构名存在嵌套的情况,即机构名中包含另一机构名,这种复合机构名在实际语料中出现的较多。例如:Shinjang Uyghur Aptonom rayunluq qatnash nazariti tashyol qurulush süpitini nazaret qilish idarisi(新疆维吾尔自治区交通运输厅公路工程质量监督局)中虚下划线和实下划线标出的是2个独立的机构名,构成了一个完整的机构名。
(4)有些机构名习惯用简称,简称一般是由其全称中每个词的第一个字母构成。如:BDT(全程是:Birleshken Dletler Teshkilati)(联合国)等。机构名简称的出现,使得机构名识别更加困难。
(5)机构名用词非常广泛,除了名词,还包含形容词、副词、数词等。特别是表示军队、医院、学校类的机构名中,序数词占有相当大的比例。如: “Shinjang Tibbi univrsitti qarmiqidiki 2-Doxturxana”(新疆医科大学第二附属医院)。
2 基于语法语义知识的维吾尔文机构名识别
2.1 维吾尔文机构名的描述
根据以上维吾尔文机构名的结构特点,并分析了大量的机构名后发现,机构名的结构特点可归纳为表示机构名的特征词以及特征词前的修饰词,于是我们将维吾尔文机构名形式化描述为:w1+w2+…+wn+s,其中s表示机构名特征词,w 表示特征修饰词,n≥1。一般机构名由一个或一个以上机构名修饰词 (如:tibbi(医学)、pidagogika(师范)、lktiron (电子))加上机构名特征词(如“universitti”(大学),“guruhi”(集团),“zawuti”(厂),“etriti”(队))等组成。前者是后者的修饰语,而后者则是前者的中心语。
另外,机构名特征词作为名词可接的后缀 (维吾尔语名词构形后缀达到40多个)。对维吾尔文语料进行分析后发现,机构名中特征词后面出现的后缀也有一定的规律存在,特征词后面可能会出现的后缀总结见表1。若特征词后面出现这些后缀,则可视为机构名边界,从而进行修饰词的识别。例如,“Biz bille Shinjang universitetigha barduq.”(我们一起去了新疆大学),“biz mushu universitetning oqughuchilir.”(我们是这个大学的学生)当中,第一个句子存在高校名称 “xinjang universiteti”(新疆大学)而第二个句子虽然有特征词,但不是一个高校名称。
维吾尔文机构名中承担中心语的特征词为数也不是很多,例如 “univrsitti”(大学),“idarisi”(局),“bankisi”(银行)等。如果这些特征词后有表1中后缀出现,则仍将它视为特征词。我们对语料中出现的机构名进行分析后,总结出机构名中各成分的出现特征为如下几种:
(1)地名+特征词。如:“Shinjang univrsitti”(新疆大学)中,Shinjang (新疆)是地名。
(2)人名+特征词。如: “Amine xirkiti” (阿米娜公司)中amine(阿米娜)是人名。
(3)学科及专业名+特征词。如:“liktiron pen-texnika univrsitti” (电子科技大学)中 liktiron pen-texnika(电子科技)是学科及专业名。
(4)地名+学科及专业名+特征词。如: “Zhongguo siyasi qanun univrsitti”(中国政法大学)。
(5)人名+研究、生产、经营等的对象+特征词。如:“Arman soda cheklik xirkiti”(阿尔曼实业有限公司)。
(6)方位词+特征词。如: “Sherqiy shimal univrsitti”(东北大学)中sherqiy,shimal都是方位词。
(7)专造名词+特征词。如: “Chinghua univrsitti”(清华大学)中Chinghua(清华)是专造词。
(8)有不少机构名包含民族名称,比如: “Shinjang uyghur aptonom rayunluq sayahet idarisi”,“Ili qazaq aptonom oblastliq ormanchiliq idarisi”等,其中uyghur,qazaq是民族名称。
2.2 系统设计与实现
2.2.1 知识库的设计
为了正确地识别机构名,需要准备相关的知识库。本文使用新疆维吾尔自治区广播电台的新闻语料 (20.6 M),手工标注出了11500个真是机构名。怎样组织并保存机构名是我们值得考虑的问题之一。合理地构建知识库不仅关系到识别效率,也影响系统的空间复杂度和时间复杂度。经过观察和分析得到,一个机构名的生成可以看出是地名/人名、修饰词及特征词的动态组合,如图1所示。
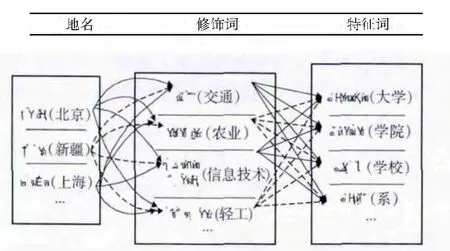
图1 机构名组合示例
根据上述示例图易得,对于一个机构名可将其各组成部分分开存贮,不仅可以避免创建庞大的机构名库,而且其扩展性高,只要加一个关键词,如地名,即可识别所有可能相关的机构名。于是,本文提出建立以下3个知识库:
(1)特征词库:机构名特征词指的是机构名末尾具有一定象征意义的词,如 “univrsitti(大学),idarisi(局),bankisi(银行)”。建立特征词库是将它作为触发条件,得到机构名左边界。
(2)修饰词库:修饰词是指一个机构名中除特征词和地名之外的其余词。比如:Shinjang ilim-pen uchuri inistitoti(新疆科信学院)当中的ilim-pen和uchur是修饰词。我们总共收集了3574个机构名修饰词,并建立了机构名修饰词库。
(3)地名/人名库:由于大多数机构由地名开头,我们也建立了地名库。这对维吾尔文机构名右边界的识别起很大的作用。建立的地名库总共包含4517个地名,里面有国外的和国内的地名。其中,疆内的地名占的比例最高。另外,还增加了常见人名576个。
2.2.2 整体架构
我们根据维吾尔文机构名的组织结构特点,设计并构建了机构名的识别规则和相应的知识库。依据这些识别规则和知识库,我们设计了基于关键词匹配和状态转移原理的识别算法,能够快速准确地识别出机构名实体。
机构名称识别系统的整体结构如图2所示。
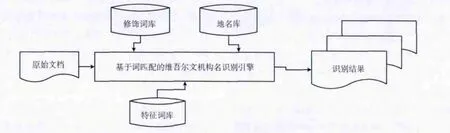
图2 机构名识别系统结构
2.2.3 基于词匹配的识别流程
系统中识别引擎的识别流程如图3 所示,其识别步骤如下:
步骤1 读语料;
步骤2 若语料为空,则结束;否则取当前词;
步骤3 找到机构名特征词,获取候选机构名位置;
步骤4 以机构名特征词作为触发点,向前开始匹配;
步骤5 判断当前词是否为修饰词,若匹配成功,则保存,并去下一个词,再转到步骤5;否则,转到步骤6;
步骤6 若当前词为地名/人名,认为是机构名,标记并输出,转到步骤2;若不是,则转到步骤2。
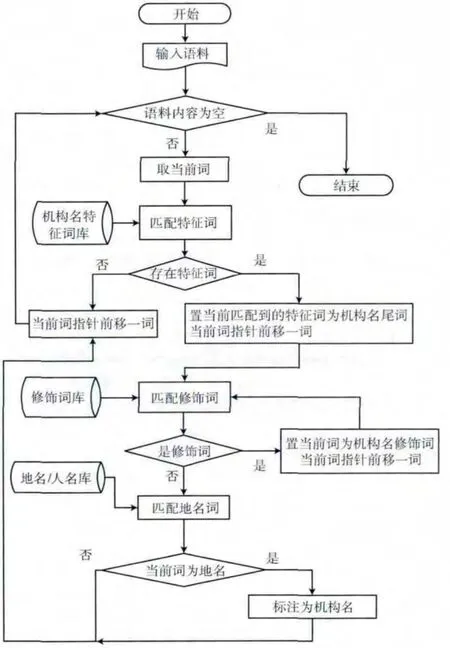
图3 机构名匹配过程流程
用一实例说明系统的识别过程:Shinjang Pidagogika univrsitti(新疆师范大学)的识别过程是,首先在特征词库里进行匹配 (如:univrisitti)如果找到了就从特征词往右 (维吾尔语是从右往左写)进行前部词匹配 (跟修饰词库和地名库进行匹配,如果有就不断地进行匹配等到没有匹配为止);再往前进行地名匹配 (从地名库进行匹配,如:Shinjang)匹配成功后标记为机构名。
3 实验及分析
最近,在维吾尔文信息处理方面进行了一些有关专有名的研究与分析,但是在机构名这一部分的研究相对少,在本论文中,通过研究与分析,并进行实验,讨论在论文中提到的有关规则在维吾尔文机构名识别中的研究及分析中的作用。
在测试中采用自然语言处理中使用最广泛的3个性能评测指标,即准确率P、召回率R 和F值,定义如下

其中,β是准确率P 和召回率R 之间的权衡因子。β取为1,因此方程简成
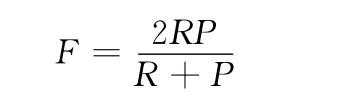
为了评估基于语法语义知识的维吾尔文机构名识别系统的识别效果,我们下载天山网的新闻,随机抽取了178篇文章 (提取包含机构名的616个句子,总共有727 个机构名)进行测试。
系统识别出来的有648 个,其中正确识别出的有571个。正确率:88.11%,召回率:78.54%,F值:83.05%。
测试程序界面如图4所示。

图4 测试程序界面
通过实验结果我们可以看出大多数机构名都被正确的识别出来了,但是由于知识库包含的内容不完备,造成识别不完整,漏识别等现象。因为基于知识库的机构名识别方法中系统依赖于特征词库,修饰词库和地名库的完备程度,3个库中任意一个不完备,都可能导致识别错误和遗漏的情况。下面举2个例子,如:besh aliy mektep(五所高校)、ottura bashlanghuch mektep (中小学)不是机构名,但是由于它们包含的单词在特征词库和修饰词库里面存在,系统把它们错误的识别为机构名。另外算法的缺陷导致误识别,比如:erkin yza igilik univrsittida oquydu.(艾尔肯在农业大学上学)当系统识别这一句时,把erkin yza igilik univrsitti错误的识别为机构名。其中erkin (艾尔肯)是人名,但这个词有另外一个意思 (自由),有第二种意思时,能当修饰词,比如机构名:erkin dimikuratlar partiyisi“自由民主党”。这种有歧义的人名也会导致系统的识别错误。要是刚才的句子改成erkin Shinjang univrsittida oquydu.(阿里木在新疆农业大学上学。)的话,其识别结果是正确的。因为erkin后面有一个机构名首位边界词 (地名)Shinjang (新疆),没有必要判断前面一个单词,这样就避免了识别错误。只要能够尽可能地完善这些知识库,就能进一步提高系统的识别效率。
4 结束语
本文根据维吾尔语的语法和语义特性设计出有效地识别规则和相应的知识库 (这些规则不仅能够在维吾尔语文机构名识别中应用到,也可以在其它的命名实体识别,如:人名、地名等),并设计了基于状态转移原理的高效的识别算法。实验结果表明,我们的机构名识别系统具有较高地处理速度和精度。在今后的工作中我们打算用统计的方法和规则的方法相结合,改进我们的识别系统并提高识别效率。
[1]LI Jun,WANG Ding,WANG Xin.Chinese organization name recognition based on template matching [J].Information Technology,2008(6):97-99(in Chinese).[李军,王丁,王鑫.基于模板匹配的中文机构名识别[J].信息技术,2008(6):97-99.]
[2]XIA Yun,LI Zhishu.Chinese organization automatic recognition based on statistical method [J].Journal of Sichuan University (Natural Science Edition),2009,46 (3):613-617 (in Chinese).[夏赟,李志蜀.基于统计的中文机构名自动识别[J].四川大学学报(自然科学版),2009,46 (3) :613-617.]
[3]Bender O,Och FJ,Ney H.Maximum entropy models for named entity recognition [C]//Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL,2003:148-151.
[4]CHEN Xiao,LIU Hui,CHEN Yuquan.Chinese organization names recognition based on SVM [J].Application Research of Computers,2008,25 (2):362-364 (in Chinese). [陈霄,刘慧,陈玉泉.基于支持向量机方法的中文组织机构名的识别[J].计算机应用研究,2008,25 (2):362-364.]
[5]HUANG Degen,LI Zezhong,WAN Ru.Chinese organization name recognition using cascaded model based on SVM and CRF[J].Journal of Dalian University of Technology,2010,50(5):782-787 (in Chinese).[黄德根,李泽中,万如基于SVM 和CRF的双层模型中文机构名识别 [J].大连理工大学学报,2010,50 (5):782-787.]
[6]YAN Ping.Research on the identifiction for chinese named entity based on combination of rules and statistic analysis [J].Computer & Digital Engineering,2011,39 (9):88-91 (in Chinese).[闫萍.基于规则和概率统计相结合的中文命名实体识别研究[J].计算机与数字工程,2011,39 (9):88-91.]
[7]Mairehaba·Aili,JIANG Wenbin,Tuergen·Yibulayin.Lemmatization of Uyghur inflectional words[J].Journal of Chinese Information Processing,2012,26 (1):91-96 (in Chinese).[麦热哈巴·艾力,姜文斌,吐尔根·依布拉音.维吾尔语词法中音变现象的自动还原模型 [J].中文信息学报,2012,26(1):91-96.]
[8]ZHOU Lei,ZHU Qiaoming.Research on recognition method of unknown chinese words based on statistic and regulation [J].Computer Engineering,2007,33 (8):196-198 (in Chinese).[周蕾,朱巧明.基于统计和规则的未登录词识别方法研究[J].计算机工程,2007,33 (8):196-198.]
[9]SHEN Jiayi,LI Fang,XU Feiyu,et al.Recognition of Chinese organization mames and abbreviations [J].Journal of Chinese Information Processing,2007,21 (6):17-21 (in Chinese).[沈嘉懿,李芳,徐飞玉,等.中文组织机构名称与简称的识别[J].中文信息学报,2007,21 (6):17-21.]
[10]ZHOU Junsheng,DAI Xinyu,YIN Cunyan,et al.Automatic recognition of Chinese organization name based on cascaded conditional random fields[J].Acta Electronica Sinica,2006,34 (5):804-809 (in Chinese).[周俊生,戴新宇,尹存燕,等.基于层叠条件随机场模型的中文机构名自动识别 [J].电子学报,2006,34 (5):804-809.]
[11]Dimitra F,Vangelis K,John K,et al.Rule-based named entity recognition for greek financial texts[C]//Proceedings of the International Conference on Computational Lexicography and Multimedia Dictionaries,2000:75-78.
[12]HU Wanting,YANG Yan,YIN Hongfeng,et al.Organization name recognition based on word frequency statistics[J].Application Research of Computers,2013,30 (7):2014-2016 (in Chinese).[胡万亭,杨燕,尹红风,等.一种基于词频统计的组织机构名识别方法 [J].计算机应用研究,2013,30 (7):2014-2016.]
[13]FENG Jinghua,Guma·Altenbek,Mayra·Hapar.Kazakh organization name recognition based on N-gram model[J].Computer Engineering and Applications,2010,46 (31):135-138 (in Chinese).[冯鲸华,古丽拉·阿东别克,玛依来·哈帕尔.基于N-gram 语言模型的哈萨克文机构名识别[J].计算机工程与应用,2010,46 (31):135-138.]
[14]Kurex·Mahmutjan·Raisi.Modern Uyghur language[M].Xinjiang:Xinjiang People’s Publishing House(in Uyghur),2003(in Chinese).[库热西· 买合木提江·热义思.现代维吾尔语[M].新疆:新疆人民出版社(维吾尔文),2003.]
