基于粗糙集的数据发布多约束匿名保护方法
2014-12-23邱桃荣段文影
刘 萍,邱桃荣,段文影
(南昌大学 信息工程学院,江西 南昌330031)
0 引 言
怎样发布既真实有效又能保护个人的隐私信息不被泄露的数据是亟需解决的重要问题。为了达到保护个人隐私的目的,最初的方法是仅删除个人信息中唯一能识别具体元组的身份属性,这个过程被称为匿名化。文献 [1]提出了K-anonymization规则来解决由于链接攻击造成的隐私泄露问题。然而K-anonymization存在一定的不足之处,对敏感数据,它没有做任何约束处理。为解决这个问题,在文献 [2]中提出了一种新的隐私规则l-diversity,l-diversity规则提高了匿名组内敏感属性多样性,降低了隐私泄露的风险,但是它并没解决K-anonymization规则会大量丢失原始数据大量信息的缺点。另一方面,l-diversity模型对相似性攻击没有比较好的解决办法。因此,依靠泛化技术文献[3]提出了一种可以抵御相似性攻击的匿名规则t-closeness,同样基于泛化技术的隐私规则还包括 (c,k)-safe-ty[4],privacy skyline[5]等。采用泛化技术的匿名规则在很大程度上降低了数据的精度和利用率。文献 [6]采用一种交换方法,实现高精度的数据发布规则anatomy,该规则采用一种被称为有损连接的方法。 (k,e)-anonymity[7]也是典型的采用交换来实现匿名化的模型。
由于传统的匿名算法都是把数据表所有的准标识符属性的重要度看成一致,采用相同的匿名强度实现k-划分,所设计的匿名规则属于单约束规则,所以采用这种传统匿名规则设计方法对所要发布的高维数据表进行隐私保护时会造成大量有用信息损失。文献 [8]提出多约束规则以适应多种约束条件,能够较好地实现发布数据的隐私保护程度与数据可用性之间的平衡。但是其并未给出对于每个约束集约束参数的设定方法。本文考虑到不同的准标识符属性对敏感属性产生的影响程度是不同的,提出基于粗糙集理论的准标识符属性维度划分的匿名规则设计方法。该方法不需要先验知识,而是根据待发布数据表的特点,即根据准标识符属性重要度的差别,对准标识符属性维度进行自动划分,实现多约束匿名参数的设计;对不同维度的划分进行相应的匿名化操作。另外,针对分类型数据的特点,基于粗糙集理论和信息熵理论,设计了一种分类型数据可用性评估模型。该模型从泛化后的信息损失与等价类对集合划分导致的信息熵改变两方面综合评估匿名化数据表的信息损失量。
1 相关概念
1.1 粗糙集基本概念简介
粗糙集理论是用于处理含糊性和不确定性的一种数学工具[9]。该理论主要从不完整的数据集中发现模式和规律,在短短20多年里,粗糙集理论已经在各个领域得到了广泛的应用。在数据发布中的隐私保护中,需要进行保护的数据往往有冗余及缺失,是一个不完整的信息系统。由于粗糙集在属性约简方面具有独特的优势,因此它在数据发布中隐私保护的应用也越来越得到重视。
DT =(U,C∪D,V,f)是一个决策表,参考文献 [10]中的定义。
定义1[10]DT =(U,C ∪D,V,f)是一个决策表,R表示等价关系,X U 是任一子集,则其下近似定义为(X)=∪{Y ∈U/R|Y X},上近似定义为(X)=∪{Y ∈U/R|Y ∩X ≠}。则其R-正区域记为:POSR(X)=R(X),R-负区域记为:NEGR(X)=U-(X)。
定义2[10]DT =(U,C ∪D,V,f)是一个决策表,其条件属性和决策属性分别是C 和D,称C 在D 中以程度k(0 ≤k ≤1)依赖于C,记成C →kD ,其中k =card(POSC(D))/card(U),POSC(D)是D 的C-正区域。

定义4[10]DT =(U,C ∪D,V,f)是一个决策表,其条件属性集为C,决策属性集为D,任一条件属性c∈C关于D 的属性重要度定义为:Sig(c)=I(D|(C-{c}))-I(D|C)+I(D|{c})。
1.2 多约束规则
用一个三元组T =(U,QI,SA)表示未经隐私保护的数据表,它实质上是一个决策表,QI 表示准标识符属性集,和信息系统中的条件属性集CA 相对应,敏感属性集用SA表示,和信息系统中的决策属性集D 相对应。数据表T 称为待发布数据表。
匿名约束C 描述C =<QI,K >。其中QI ={attr1,…,attrm},QI 为约束的准标识符,由一组属性attri,i=1,2,…,m 组成。K 为约束C 的匿名参数,即有K 条元组上在QI 上相等。多约束规则有如下定义[8]:一个约束集被表示为CSet={C1,C2,…,Cr},其中Ci=<QIi,Ki>,i=1,2,…,r,ci表示第i个约束。r为约束集CSet中的约束数目,记作|CSet|。
2 基于属性重要度的多约束匿名参数的选择
2.1 基于属性重要度的匿名化参数K 值选择的数据模型
对于一个待发布数据表T,如果其所有元组满足经过匿名化处理得到表T′,划分得到若干个等价类,每个等价类中的元组数目不小于K,则称表T'满足K-匿名,K 为匿名化参数。
定义5 约束子集属性平均重要度:给定一个数据表T=(U,QI,SA),对任意约束Ci=<QIi,Ki>,QIiQI,i=1,2,…,r,设QIi={attri1,attri2,…,attris},则QIi子集的平均重要度记为kQIi,定义为,其中kattrij是属性attrij,j=1,2,…,s的属性重要度。
由于经典的K-匿名化将数据表看成单一约束,即C =<QI,K >,其中QI 为数据表的全部准标识符。本文将这个匿名参数K 视为属性集QI 的属性平均重要度下对应的匿名参数。
定义6 准标识符QI 的平均重要度及对应的匿名参数:给定数据表T =(U,QI,SA)和匿名参数K,准标识符QI 对应的平均重要度记为kQI,则定义数据表准标识符QI 的平均重要度所对应的匿名参数为K 。
本文根据约束子集属性平均重要度的不同,相应约束子集的匿名参数取值也不同,约束子集属性平均重要度与准标识符QI 的属性平均重要度及其它们多对应的匿名参数之间的关系定义如下。
定义7 约束子集属性平均重要度与对应匿名参数:给定一个数据表T =(U,QI,SA),对任意约束Ci=<QIi,Ki>,QIiQI,i=1,2,…,r,对应QIi的平均重要度记为kQIi。则定义Ki为:Ki=K*kQI/kQIi。
2.2 基于属性重要度的约束集划分算法
算法1:约束集划分算法
设T =(U,QI,SA)是一个待发布的数据表,准标识符集被记作QISet={attr1,…,attrm},准标识符attri,i=1,…,m 的属性重要度记为kattri,i=1,…,m。
输入:待发布数据表T,其有n个体,m 维准标识符属性,初始匿名参数K。
输出:约束集CSet={C1,…,Cr}
步骤1 根据定义4,计算所有准标识符属性重要度,其属性重要度集合kSet={kattr1,…,kattrm}。
步骤2 对kSet采用基于密度的聚类技术进行聚类,生成h个簇,即得到重要度子集subkSet1,…,subkSeth,将其对应的准标识符集划分为相应的h 个簇,即subQISet1,…,subQISeth。
步骤3 根据定义5求出每个重要度子集的平均属性重要度,得到相应的平均属性重要度集合={kQI1,kQI2,…,kQIh}。
步骤4 由初始的匿名参数K,根据定义6和定义7求得相应的每个约束的匿名化参数{K1,K2,…,Kh}。
步骤5 得到数据表的约束集CSet ={<subQISet1,K1>,<suQISet2,K2>,…,<subQISeth,Kh>}。
2.3 多约束条件的匿名化方法
基于上述分析,本文提出一种多约束条件的匿名化方法,描述如下:
算法2:多约束条件的匿名化算法
输入:待发布数据表T =(U,QI,SA)
输出:可发布数据表T′
步骤1 根据算法1,得到数据表的约束集CSet={<subQISet1,K1>,<suQISet2,K2>,…,<subQISeth,Kh>};
步骤2 根据约束集把表T 划分成h 个子表T1,T2,…,Th;
步骤3 对任意子表Ti,i=1,2,…,h,根据对应的属性子集subQISeti和匿名参数Ki进行Ki-匿名化;
步骤4 根据每个元素的ID 合并所有子表,重新生成所有元组,最终得到可发布数据表T′。
3 基于粗糙熵的分类型数据可用性评估模型
泛化其本质是对于等价类中的每个属性,用一个集合去代替,可以用粗糙集理论去度量其数据可用性。本文定义经过泛化后数据表中属性的粗糙度及近似精度如下:

由于数据类型分成分类型数据、连续型数据和混合型数据。为此,针对不同类型的数据集,要设计不同类型的数据可用性评估模型。针对分类型数据的特点,基于粗糙集理论和信息熵理论,本文设计了一种分类型数据可用性评估模型。
按照粗糙集观点,粗糙集的不确定性由两方面原因造成:
其一是知识性的粗糙性 (属性对论域的划分);
其二是粗糙集的边界。
于是根据上述定义,本文对粗糙熵定义提出改进如下:
定义9 设T′=(U,QI,SA)是一个有n个个体,m 维属性的经过匿名算法处理后的数据表,U 为其全域,设该数据表的族集U/QI ={X1,X2,…,Xg},则该数据表的粗糙熵定义为
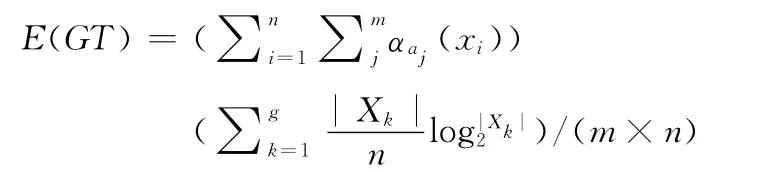
我们用此粗糙熵来衡量数据的分类型数据表经过泛化后的数据表的可用性或信息损失量。
4 测试与比较
4.1 实验环境
本实验平台的操作系统为Windows 7 (32位系统)。算法采用MATLAB 7.0 实现。运行的机器配置为处理器:Intel Core i3M380 2.53Ghz,内存:DDR3 2G。
4.2 实验数据集介绍
使用的数据集为UCI数据集中的Adult数据集作为测试数据 (删除所有连续型变量)测试分类型数据的微聚集算法,该数据是美国人口普查的信息结果。数据库元组个数452 22个,从中随机抽取1000个作为测试数据。
4.3 实验中的相关参数

4.4 实验比较结果
将本文采用智能约束集划分隐私保护规则实现的匿名化方法 (称本文算法)与传统k-匿名规则的微聚集算法(MDAV 算法)在数据集Adult上进行测试比较。
根据Adult数据集的特点,基于粗糙集属性重要度的计算,我们得到的约束集为:
C1={<education,marital-status>,K1};
C2={<occupation,relationship >,K2};
C3={<native-country,workclass>,K3};
而K1:K2:K3=5:3:1(取整后的近似比)。
4.4.1 泄密风险分析
实验中用于基于评估泄密方显的方式是基于元组链接的评估方法 (DLD)。比较了基于k-匿名规则的传统微聚集算法和本文算法的泄密风险。
表1是针对Adult数据集分别用2 种匿名算法生成的匿名表的风险评估测试结果。
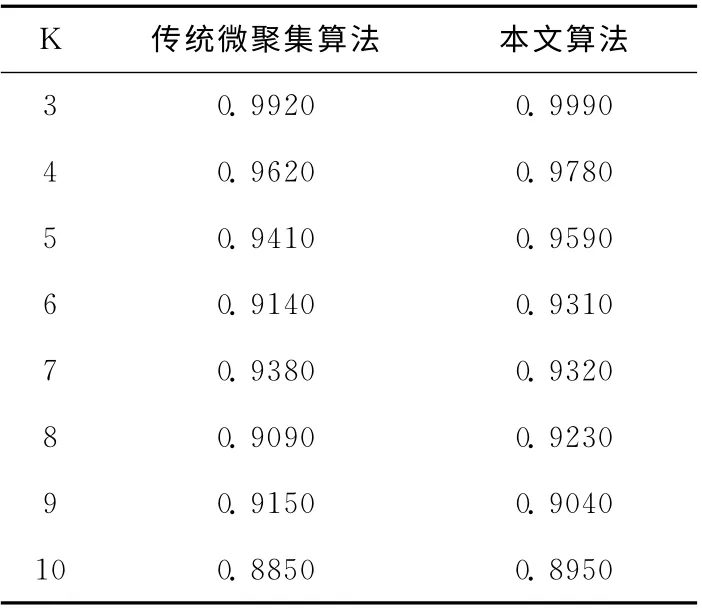
表1 Adult匿名表的风险评估结果
通过上述实验结果可以看出,在相同的k值上,本文风险泄露多一些。但差距不大。传统K-匿名模型把元组划分成若干等价类。但本文算法只在根据约束集划分的子表上成等价类。合并后得到的可发布数据表并不满足K-匿名条件,元组的失真度相对较小。每个元组距离原始元组的距离变小,所以链接到原始元组的概率增大。
4.4.2 数据可用性分析
表2是针对Adult数据集分别采用2 种匿名算法测试匿名化后数据可用性的测试结果。
由上述实验结果可以看出,本文提出的模型划分方法降低了原始数据表的维度,每个子表在较低的维度把元组划分成若干等价类,更好的保护了数据的真实性。而传统微聚集算法本文算法随着准标识符个数的增加,即维度增大,要付出更大的代价实现匿名化。本文算法可以通过选择更大的k值降低数据泄露的风险。如设置k=5时,本文算法的数据可用性要好于k=4时传统微聚集算法的数据可用性,泄露的风险也更低。

表2 Adult匿名表的信息损失量
5 结束语
不同的准标识符属性对敏感属性产生的影响程度是不同的,采用相同匿名参数进行的划分会造成不必要的信息损失。本文通过基于粗糙集方法研究和设计维度划分的匿名规则。所提出的规则所得到的可发布数据表并不是一个k-匿名划分,而是在相应的约束子集上具有不同k-划分,从而实现了对属性在不同层次上的概括。实验结果表明,所提出的多约束的匿名参数选择方法能平衡数据的保护程度与数据可用性之间的关系。下一步工作包括完善和优化所提出的方法,并进一步与其它优秀的匿名算法进行比较实验,同时进一步深入针对连续数据和混合的不同属性类型研究评价数据可用性的模型等。
[1]REN Yi,PENG Zhiyong,TANG Zukai,et al.Privacy databaseconcepts,development and challenge[J].Journal of Chinese Computer Systems,2008,29 (8):1467-1474(in Chinese).[任毅,彭智勇,唐祖锴,等.隐私数据库—概念、发展和挑战 [J].小型微型计算机系统,2008,29 (8):1467-1474.]
[2]Machanavajjhala A,Gehrke J,Kifer D,et al.l-diversity:Privacy beyond k-anonymity [C]//Proceedings of the 22nd International Conference on Data Enginee-ring.IEEE Computer Society,2006:24-35.
[3]Li N,Li T,Venkatasubramanian S.T-closeness:Privacy beyond k-anonymity and l-diversity [C]//Proceedings of the 23rd International Conference on Data Engineering.IEEE,2007:106-115.
[4]Zhang Q,Koudas N,Srivastava D,et al.Aggregate query answering on anonymized tables[C]//Proceedings of the 23rd International Conference on Data Engineering.IEEE,2007:116-125.
[5]Chen B C,Ramkrishnan R,LeFevre K.Privacy skyline:Privacy with multidimensional adversarial knowledge [C]//Proceedings of the 33rd International Conference on Very Large Data Bases.ACM,2007:770-781.
[6]LIU Yubao,HUANG Zhilan,Fu Ada Wai Chee,et al.A data privacy preservation method based on lossy decomposition[J].Journal of Computer Research and Development,2009,46 (7):1217-1225 (in Chinese).[刘玉葆,黄志兰,傅慰慈,等.基于有损分解的数据隐私保护方法 [J].计算机研究与发展,2009,46 (7):1217-1225.]
[7]Martin D,Kifer D,Machanavajjhala A,et al.Worst-case background knowledge in privacy [C]//Proceedings of the 23rd International Conference on Data Engineering.IEEE,2007:116-125.
[8]LIU Ming,YE Xiaojun.Personalized K-anonymity [J].Computer Engineering and Design,2008,29 (2):282-286(in Chinese).[刘明,叶晓俊.个性化K-匿名模型 [J].计算机工程与设计,2008,29 (2):282-286.]
[9]WANG Lu,QIU Taorong,HE Niu,et al.A method for feature selection based on rough sets and ant colony optimization algorithm [J].Journal of Nanjing University (Natural Sciences),2010,46 (5):487-493 (in Chinese).[王璐,邱桃荣,何妞,等.基于粗糙集和蚁群优化算法的特征选择方法[J].南京大学学报 (自然科学),2010,46 (5):487-493.]
[10]MIAO Duoqian.Rough sets theory algorithms and application[M].Beijing:Tsinghua University Press,2008:174-180(in Chinese).[苗夺谦.粗糙集理论、算法与应用 [M].北京:清华大学出版社,2008:174-180.]
[11]CHEN Jianming,HAN Jianming.Evaluation model for quality of k-anonymity data oriented tom icroaggregation [J].Application Research of Computers,2010,27 (6):2345-2347(in Chinese).[陈建明,韩建明.面向微聚集技术的k-匿名数据质量评估模型 [J].计算机应用研究,2010,27 (6):2345-2347.]
