基于K-Medoids聚类的改进KNN 文本分类算法
2014-12-20罗贤锋祝胜林陈泽健袁玉强
罗贤锋,祝胜林,陈泽健,袁玉强
(华南农业大学 信息学院,广东 广州510642)
0 引 言
文本分类的主要任务是在预先给定的类别标记下,根据文本内容来判断其类别归属。目前文本分类算法包括朴素贝叶斯 (NB)[1]、支持向量机 (SVM)[2]、K 最近邻算法(KNN)[3]等。KNN 算法是由Cover和Hart于1967年提出的,有着稳定性、鲁棒性、高准确率等优点[4]。但正如文献 [4]中指出KNN 算法作为一种惰性算法,在分类阶段,每个待分类文本都需要与所有训练样本做相似度计算,从而找出K 个最近邻,其时间复杂度与训练集的样本数量成正比,因此在大样本集下,分类速度会严重降低,缺少实用性。针对这一问题,目前主要在减小计算量方面做了一些相关研究[5-8],但它们在面对大数据时,效果不是很理想。针对此现状,提出了基于K-Medoids聚类的改进KNN算法。实验结果表明,该改进算法不仅能够提高运行效率,还能够提高分类能力。
承认、接纳消极情绪的存在,与之好好相处,不要试图将其赶走,不要一味地对抗,把消极情绪当成来你家做客的人,好好招待它。当它受到友好的接待,自然会满意而安静地离开。
1 K 最近邻算法
KNN 算法以其简单性、有效性而成为基于向量空间模型 (VSM)[9]的最好分类算法之一。文献 [9]指出VSM的主要思想是:假设文档中的词条是相互独立的,跟词条出现的位置无关,将文档映射为一组词条相量 (T1,W1,T2,W2,……,T3,W3),其中,Ti为特征向量词条,Wi为Ti的 权 重。
假定文本训练集为S,S 有N 个类别C1,C2,……,CN,S 的总文本数为M。在KNN 分类算法的训练阶段,首先对文本训练集S 进行分词,接着对特征维数进行降维,最后把训练集文本表示为特征向量:Di= {X1,X2,……,Xn}T(0<i≤M);在KNN 算法的分类阶段,首先需要按照训练阶段的过程将待分类文本D 表示为特征向量:D={X1,X2,……,Xn}T,再在文本训练集S 中找出与待分类文本D 最相似的K 个文本Di= {X1,X2,……,Xn}T(0<i≤K),以这K 个最近邻文本的类别作为候选类别,最后计算待分类文本D 在这些类别里的隶属度,从而把待分类文本D 归属到隶属度最大的类别。KNN 算法的具体步聚如下:
步骤1 对文本训练集进行分词。
步骤2 对训练集文本的特征项进行降维。
2) 目前,高职院校会展英语教材的语言和专业知识没有达到有机结合:交际任务不切合实际,缺乏时效性;教材难度控制不够;重难点不突出;缺少必要的语言技能练习;没有开发多媒体资源;内容不适应当前经济发展的需要;中西方文化差异在工作流程中没有体现。
1.以间质结缔组织增生为主。肝呈灰白色,发硬。由于间质结缔组织增生,使肝细胞受压后呈现增生,形成结节状隆起,肝脏表面不平整。
步骤5 利用向量夹角余弦公式来计算待分类文本D与训练集文本Di的相似度,公式为
步骤4 对待分类文本进行步骤1 到步骤3 的处理工作。
3.2.2 严密观察患者 护士应经常巡视病房,早发现、早防范有精神异动患者,采取外紧内松的管理模式,做好患者的心理疏导,鼓励患者参加适度的体育锻炼、文娱活动分散患者注意力,不让患者存在自卑;精神异常发作时及时采取约束带和暂时性的保护性隔离措施。

步骤6 选出与待分类文本D 最相似即sim (D,Di)最大的K 个文本作为文本D 的最近邻。
步骤7 根据这K 个最近邻,计算待分类文本D 在各个类别里的隶属度。计算公式为

式中:δ(D,Cm)表示若待分类文本D 属于类别Cm则值为1,否则为0,δ(D,Cm)的计算公式为

步骤8 选出隶属度最大的类别Cm,并将待分类文本D 归入到该类别Cm中。
今年复合肥总体价格高于去年同期,而且还高了不少。以45%硫基复合肥为例,较去年同期增长14%,原料尿素同比增长28%,磷酸一铵同比增长14%左右,氯化钾同比增长6.4%,硫酸钾同比增长17.6%。是什么原因导致今年复合肥价格如此之高?其主要原因有以下几个方面:
2 基于K-Medoids聚类的改进KNN 算法
虽然KNN 算法是一种经典的文本分类算法,但它是一种懒惰算法,在分类阶段具有明显的缺点:需要计算每个待分类文本与训练集所有样本的相似度,时间复杂度与训练集样本数成正比,当面对着海量的训练样本时,KNN 算法的运行速度将大幅下降,失去实用性。针对这个问题,提出使用聚类方法对训练集进行删减以减少计算开销。在对训练集进行裁剪的方法中,有利用K-means聚类算法来获取簇心,从而实现对训练样本进行裁剪的方法[10];也有利用DBSCAN 聚类算法来确定类内样本分布,并根据样本分布密度来进行裁剪的方法[11]。但在K-means算法中,用均值方法来更新簇的中心值时,会导致其产生的族类大小相差不大、对噪声和孤立点数据非常敏感等缺点[12];在DBSCAN 算法中,需要多个参数,这些参数的设置通常是依靠个人经验,难以确定。针对K-means和DBSCAN 聚类算法裁剪的不足,提出了一种基于K-Medoids聚类算法的KNN 分类器训练集裁剪方法。该方法首先利用K-Medoids聚类算法对训练集进行聚类,从而得到类别分布结构,再根据待分类文本与各个簇心的距离来对训练集进行裁剪,从而减少K 最近邻算法的相似度计算量。
我国高铁走出国家的形势虽然良好,有着很大的潜力,但一些挑战是不可避免的,激烈的竞争、国际形势、未知的不利因素都是阻碍高铁发展的重要因素。
2.1 K-Medoids聚类算法
聚类是一种把相似度较高的个体归为一簇的方法,使得簇内的个体相似度较高,簇间的个体相似度较低。基于划分的聚类算法具有简单、准确等优点,其中K-Means和K-Medoids是经典的基于划分的聚类算法,文献 [13]指出K-Means算法本身的特点不适合多数生产实践的聚类分析,因此基于K-Medoids算法的样本裁剪研究很有必要。
(4)使用2.2节所讲的裁剪方法对文本训练集S进行裁剪,得到新的训练集Snew。
在做一些练习题的时候,教师可以引入竞争的机制,充分调动学生的参与积极性。(1)扩大练习面,要照顾到每一位学生。在学生练习过程中教师要不断了解情况,根据不同层次的学生采取有针对性的措施,调动他们的学习积极性,提高练习效率。(2)经过一段时间的练习,教师要筛选出有代表性的题目,做成卡片或结合实际,加强巩固学生的知识,使其能够稳步提高。(3)对于计算有一些困难的学生,教师要弄清楚他们的问题出在哪里,要帮助他们有效地解决困难,努力消除学生心理上的负担,提高他们的自信心。
2.2 基于K-Medoids聚类的样本裁剪方法
步骤4 在每个簇内部顺序选择一个非簇心的文本对象Otmp,计算以Otmp为簇心的消耗代价Etmp,若Etmp<Ei,则表明聚类在收敛,用Otmp更新簇心Oi,继续迭代,直到Ei小于Etmp且各个簇心不再发生变化为止,此时聚类结束。
步骤3 把训练集文本表示为特征向量。
假定文本训练集为S,S 有N 个类别C1,C2,……,CN,S 的总文本数为M。S 首先被K-Medoids聚类算法分为r个簇,记X 为各个簇的簇心,X∈S,sim(Di,Dj)为训练样本Di和Dj的相似度,Simmin代表簇内的各个样本与簇心X 之间的相似度的最小值。则文本训练集S 就可以表示为以簇心X 为球心,Simmin为半径的r个球体。
步骤1 对于文本训练集S,指定需要划分成r个簇,r=3×N。
患侧手肿胀是脑卒中偏瘫患者的常见并发症之一,其发生率约为12.5%~70.0%[1]。水肿以手背部最为明显,常波及手指和手掌[2]。如不及时干预不仅导致粘连、挛缩等手部功能障碍,且降低患者本人的生活自理能力、增加其与家人的生活负担。康复治疗早期干预有利于手肿胀的快速消退、减少并发症,促进手功能恢复,提高患者的生活质量。目前,针对脑卒中患手肿胀的报道大多针对中后期肩手综合征导致的手肿治疗[3],而对于其早期康复干预的报道较少。同时因气压治疗及神经肌肉电刺激治疗水肿的机理不同,本研究将两种治疗方案叠加使用,探讨其对改善重症监护室脑卒中患侧手肿胀的患者肢体肿胀是否有叠加效果。
步骤2 为每个簇随机选择一个簇心Oi(0<i≤r)。
步骤3 计算文本训练集S 中的其它非簇心文本与这r个簇心的相似度,把它们归给相似度最大的簇,同时统计以Oi为簇心的消耗代价Ei和每个簇的最小相似度Simmin。
在KNN 算法的分类过程中,对于每个待分类文本D,它的类别C 是确定的,根据相似度计算公式得到的K 个最近邻文本,一般也是属于类别C 的,如果不是,也应该是在类别C 的周围。故可以假设如果只让D 与类别C 的文本(包括类别C 附近的文本)计算相似度的话,则可以大大地减少计算量。基于此,提出了基于K-Medoids聚类的样本裁剪方法。
步骤5 计算待分类文本与每个簇心的相似度Sim(D,Oi),若Sim(D,Oi)<Simmin,表明这个待分类文本与这个簇内的文本的相似度很低,所以把这个簇内的文本裁剪掉,否则把这个簇内的文本加入到分类运算中去,从而得到新的训练集Snew。
2.3 基于K-Medoids聚类的改进KNN 算法
在KNN 文本分类算法中,通过K-Medoids聚类将训练集分为多个簇,再挖掘文本训练集的类别分布结构,最后计算每个待分类文本与簇心的相似度,若得到的相似度小于该簇内的最小相似度,则不把这个簇内的训练集文本加入计算范围,减少样本数量,从而降低计算开销。综上所述,提出的基于K-Medoids聚类的改进KNN 文本分类算法流程如下和流程如图1所示。
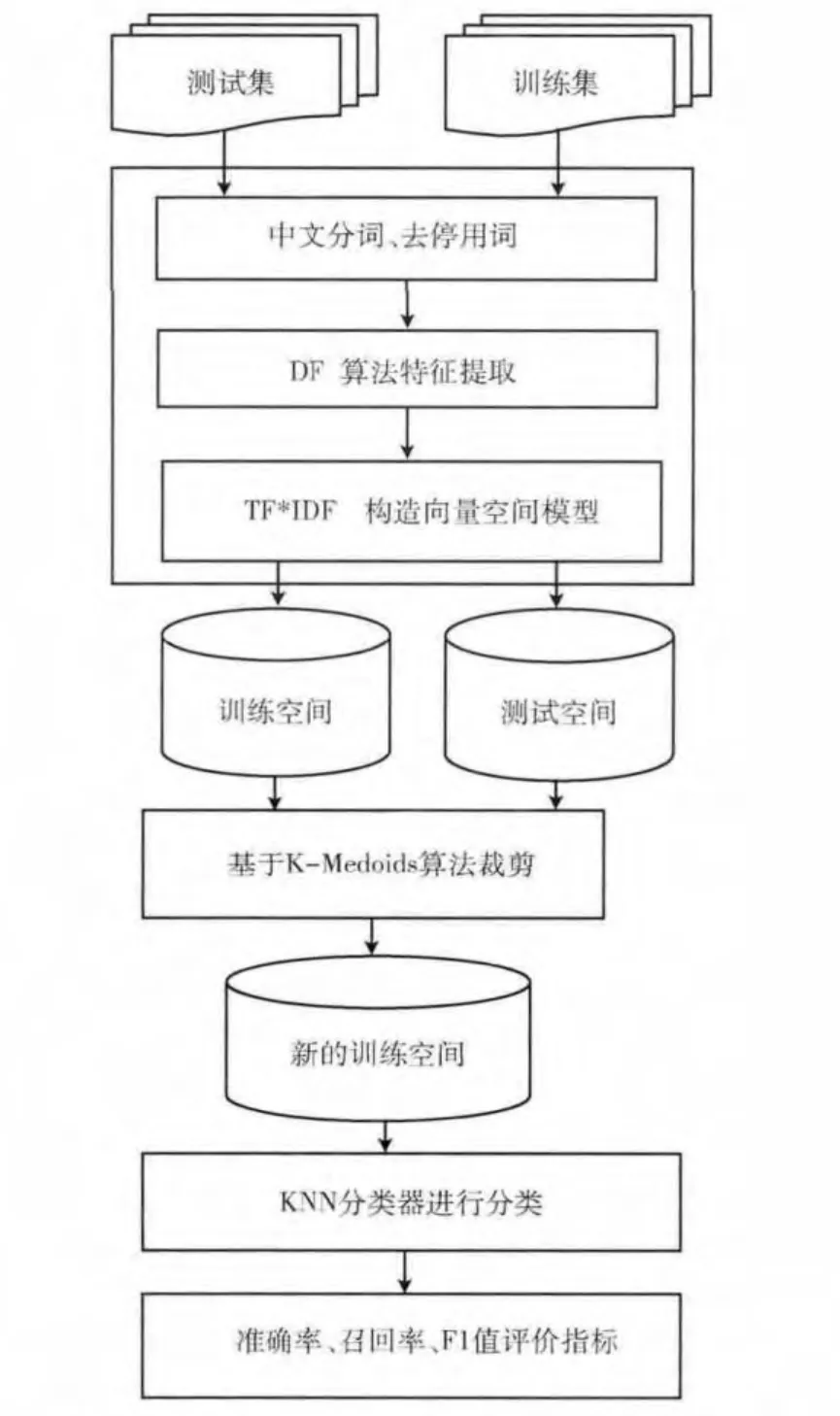
图1 基于K-Medoids算法的KNN 分类流程
(1)首先采用开源工具IKAnalyzer对中文文本进行分词、去停用词等预处理。
(2)采用文档频率方法对特征维数进行降维,设置最低文档频阀值为200。
(3)采用权重计算公式TFIDF来计算文本特征项的权重,从而得到文本的向量空间模型即特征向量,权重计算公式为:Wik=tfik×idfk,其中tfik表示特征项Tk在文本Di的词频,idfk表示特征项Tk出现的文档频率的反比。
K-Medoids算法[13]的思想是:对于数据集,首先需要指定划分成多少个簇,即任意选择K 个不同数据对象作为初始簇心Oi(0<i≤K),接着根据其它对象与每个簇心的相似度,把它们分配给相似度最大的簇,最后在每个簇内部顺序选择一个非簇心的样本对象Otmp,计算以Otmp为簇心的消耗代价Etmp,若Etmp<Ei,则表明聚类在收敛,用Otmp更新簇心Oi,继续迭代,直到Ei小于Etmp且各个簇心不再发生变化为止,此时聚类结束。
(5)对于每个待分类文本D,根据第一节所讲的KNN分类流程,对待分类文本D 进行分类,实验中设置KNN算法中的参数K=20。
3 实验结果及分析
对提出的改进方法进行了实验,设计如下实验:实验环境 为Windows 7 64 位 操 作 系 统、CPU 为AMD A8-5600K、内存为8G 和Eclipse集成开发工具,实验数据全部来自于复旦大学发布的分类语料库,从中我们选取了一组一定规模的训练集及其对应的测试集,它们的类别包括艺术、历史、计算机、环境、农业、经济和政治。训练集最小类别为历史类,文本数为350篇,最大类别为环境类,文本数为450篇,文档总数为2905;测试集最小类别为艺术类,文本数为280 篇,最大类别为环境类文本数为450篇,测试集文档总数为2525篇。分类效果的评价指标采用准确率 (precision)、召回率 (recall)和F1 值,时间采用多次实验的平均值。
准确率是指使用文本自动分类算法分类的所有文本中与人工分类结果一致的文本所占的比率,其数学公式为

召回率是指用人工分类的所有文本中与使用文本自动分类算法分类的文本一致所占的比率,其数学公式为

通常情况下准确率和召回率两者呈互补状态,单纯提高一个指标会导致另一个指标下降。所以,需要一个指标综合考虑这2个因素,这就是F1值,其数学公式为

分别与传统的KNN 算法和基于K-Means的改进KNN算法进行了比较,数据统计实验结果见表1。
根据上述基础地理单元划分、点位风险评价、水稻产地土壤风险评价、稻米风险评价、水稻富集系数及土壤-稻米协同风险评价结果划分风险评价单元,将研究区域内稻田划分成125个风险评价单元,其中,优先保护类、安全利用类和严格管控类的评价单元分别有85个、38个和2个。按风险等级划分,区域内无、低、中、高风险单元分别有85个、30个、8个和2个,未出现极高风险单元(图5)。
表1可以看出,基于K-Medoids算法改进的KNN 算法与传统KNN 算法相比,不仅在分类速度上有所提高,而且在准确率、召回率和F1 值上也有所提高,在各个类别的F1值下全面提高,平均提高了0.92;在各个类别的查准率上只有在历史类别上有所下降,平均提高了0.99%;在各个类别的查全率上,只在历史、环境、农业和经济这4 个类别上有所提高,平均提高了0.86%;但是在分类速度上提高了将近一倍,这样的改进效果是令人非常满意的。从表1可以看出,基于K-Medoids算法改进的KNN 算法与基于K-Means算法改进的KNN 算法相比,不仅在平均查全率和平均F1值上表现得更好,也在速度上有所提升,原因是K-Means算法形成的簇类大小相差不大,导致平均裁剪数较多,比K-Medoids算法多出了2 3 1个文本,误删的机会也就更大。虽然K-Means算法裁剪的训练文本数较多,但K-Means算法在收敛时所花费的时间比K-Medoids要长,所以在分类速度上K-Mediods 算法的表现要比KMeans算法上少花费了99S。

表1 实验结果
4 结束语
针对KNN 算法的分类阶段,需要计算待分类文本与文本训练集中所有文本的相似度,计算量大的特点,提出了基于K-Medoids聚类算法的改进KNN 方法,利用K-Medoids聚类算法来形成簇,再根据待分类文本与簇心的相似度来对训练集进行合理裁剪以减少计算开销。虽然样本裁剪方法可以减少计算开销,但不可避免地带来了样本信息的损失。如何更有针对性和更有效率地对样本进行裁剪,是我们今后需要进行研究的方向。
[1]DAI Lei,MA Weidong,WANG Lingnan,et al.Weightbased naive Bayes classifier design and implementation [J].Information Studies:Theory & Application,2008,31 (3):440-442 (in Chinese).[代磊,马卫东,王凌楠,等.基于权重的朴素贝叶斯分类器设计与实现 [J].情报理论与实践,2008,31 (3):440-442.]
[2]QIN Yuping,AI Qing,WANG Xiukun,et al.Study on multi-subject text classification algorithm based on support vector machines [J].Computer Engineering and Design,2008,29 (2):408-410 (in Chinese). [秦玉平,艾青,王 秀 坤,等.基于支持向量机的兼类文本分类算法研究 [J].计算机工程与设计,2008,29 (2):408-410.]
[3]Zhang Minling,Zhou Zhihua.ML-KNN:A lazy learning approach to multi-label learning [J].Pattern Recognition,2007,40 (7):2038-2048.
[4]FENG Guohe,WU Jingxue.A literature review on the im-provement of KNN algorithm [J].Library and Information Service,2012,56 (21):97-100 (in Chinese).[奉国和,吴敬学.KNN 分类算法改进研究进展 [J].图书情报工作,2012,56 (21):97-100.]
[5]LI Kaiqi,DIAO Xingchun,CAO Jianjun,et al.High precision method for text feature selection based on improved ant colony optimization algorithm [J].Journal of PLA University of Science and Technology (Natural Science Edition),2010,11 (6):634-639 (in Chinese). [李凯齐,刁兴春,曹建军,等.基于改进蚁群算法的高精度文本特征选择方法 [J].解放军理工大学学报 (自然科学版),2010,11 (6):634-639.]
[6]YAN Peng,ZHENG Xuefeng,LI Mingxiang,et al.Feature selection method based on Bayes reasoning in two-class text classification [J].Computer Science,2008,35 (7):173-176 (in Chinese).[闫鹏,郑雪峰,李明祥,等.二值文本分类中基于Bayes 推理的特征选择方法 [J].计算机科学,2008,35 (7):173-176.]
[7]WU Chunying,WANG Shitong.Improved KNN Web text classification method [J].Application Research of Computers,2008,25 (11):3275-3277 (in Chinese).[吴春颖,王士同.一种改进的KNN Web文本分类方法 [J]计算机应用研究,2008,25 (11):3275-3277.]
[8]ZHANG Xiaofei,HUANG Heyan.An improved KNN text categorization algorithm by adopting cluster technology [J].Pattern Recognition and Artificial Intelligence,2009,22 (6):936-940 (in Chinese).[张孝飞,黄河燕.一种采用聚类技术改进的KN 文本分类方法 [J].模式识别与人工智能,2009,22 (6):936-940.]
[9]YAO Qingyun,LIU Gongshen,LI Xiang.VSM-based text clustering algorithm [J].Computer Engineering,2008,34(18):39-44 (in Chinese).[姚清耘,刘功申,李翔.基于向量空间模型的文本聚类算法 [J].计算机工程,2008,34(18):39-44.]
[10]LIU Haifeng,YAO Zeqing,SU Zhan,et al.A clusteringbased method for reducing the amount of sample in KNN text categorization on the category deflection [J].Microelectronics&Computer,2012,29 (5):24-28 (in Chinese).[刘海峰,姚泽清,苏展,等.文本分类中基于K-means的类偏斜KNN样本剪裁 [J].微电子学与计算机,2012,29 (5):24-28.]
[11]GOU Heping,JING Yongxia,FENG Baiming,et al.An improved KNN text categorization algorithm based on DBSCAN [J].Science Technology and Engineering,2013,13(1):1671-1815 (in Chinese). [苟和平,景永霞,冯百明,等.基于DBSCAN 聚类的改进KNN 文本分类算法 [J].科学技术与工程,2013,13 (1):1671-1815.]
[12]HAN Xiaohong,HU Yu.Research of K-means algorithm[J].Journal of Taiyuan University of Technology,2009,40(3):236-239 (in Chinese).[韩晓红,胡彧.K-means聚类算 法 的 研 究 [J].太 原 理 工 大 学 学 报,2009,40 (3):236-239.]
[13]ZHANG Xueping,GONG Kangli,ZHAO Guangcai.Parallel KMedoids algorithm based on MapReduce[J].Journal of Computer Applications,2013,33 (4):1023-1025 (in Chinese). [张雪萍,龚康莉,赵广才.基于MapReduce的K-Medoids并行算法[J].计算机应用,2013,33 (4):1023-1025.]
