一种基于语义的RESTful Web 服务匹配模型
2014-12-14朱建虎
程 方,朱建虎
(重庆邮电大学通信宽带网络测试技术研究所,重庆400065)
0 引言
目前,Web服务主要以简单对象访问(simple object access protocol,SOAP)协议为基础,将需要交互的信息和方法包装成SOAP协议,通过超文本传送(hypertext transfer protocol,HTTP)协议来传输,以此来完成信息的交互。但是这种基于SOAP协议的Web服务存在很多弊端,比如,会涉及大量的协议和标准(统称为WS-*标准栈),这些协议和标准的嵌套将给开发带来不必要的麻烦,一些自定义的方法也会使系统间的交互产生障碍,同时,庞大的SOAP负载通过HTTP协议传输,也违背了HTTP协议设计的本意[1]。所以,这种复杂、重量级的 Web服务已经不能满足某些系统开发的需要。
随着Web2.0的到来,RESTful Web服务开始大量出现。这种轻量级分布式的系统架构充分利用了HTTP的语法语义,通过统一资源标识符(uniform resource identifier,URI)来识别和定位资源[2],使系统具有可寻址性、连通性、无状态性、统一接口等特点,还可以低耦合其他分布式组件,使系统具有很好的交互性、伸缩性和可扩展性。目前,RESTful Web服务已经被一些大公司采用,比如谷歌、脸谱、雅虎等。
然而,对如何有效地匹配和发现RESTful Web服务,许多学者都提出了自己的观点,但目前还没有一个统一的标准[3]。文献[4]提出了一种从语法层面上来描述现有RESTful Web服务的微格式,可以被机器识别;文献[2]结合了Web应用程序描述语言(Web application description language,WADL)和学习本体机制,提出一种组合方法,从语法和语义上对RESTful Web服务进行了描述;文献[5]在文献[2]提供的语法和语义基础上,通过将资源定义为描述、请求和响应的集合来进行匹配;文献[6]从资源状态转换的角度,在功能层面上,提出了一种基于输入、输出、前提条件和效果(inputs,outputs,preconditions and effects,IOPE)的RESTful Web服务搜索匹配方法,该方法重点在于建立共同的资源模型和对资源状态的统一描述;文献[7]主要是提出了一种基于HTML文件,对RESTful Web服务进行语法层面描述的 hRESTS微格式语言,hRESTS较WADL更为简单。
综合以上观点,为了能够自动有效地发现用户所需要的RESTful Web服务,本文在hRESTS和MicroWSMO微格式的基础上,通过一种有效算法,构建了一套RESTful Web服务匹配模型,该模型可以将服务请求方的请求条件和服务提供方提供的参数进行语义上的匹配来发现服务,实验证明,该服务匹配模型较现有匹配模型在效率指标方面有较大提高。
1 语义RESTful Web服务
基于SOAP协议的Web服务,通常是使用WSDLs(Web service description languages)来描述操作,而RESTful Web服务往往是由人们可以阅读的非规范文件来进行描述,比如网页[8]。对于SUN Microsystems提出的WADL,虽然为RESTful Web服务的操作定义了生成URI的方式,使用XML结构定义(XML schema,XSD)描述服务的输入和输出信息,但是,WADL提供的描述只是语法层面的,不能进行语义标注。相对于WADL来说,hRESTS提供了一种轻量级描述RESTful Web服务的机制,能够把RESTful Web服务的文本信息,用HTML网页的形式来描述,包括服务的一系列操作(operation)及与这些操作相关的输入(inputs)、输出(outputs)、方法(method)等信息[9],这些描述既可以让人理解,也可以让机器识别。
但是,hRESTS仅能够对Web服务提供语法层面的描述,无法涉及到语义层面,会严重影响服务的查全率和查准率,故本文引入了MicroWSMO微格式[10]。MicroWSMO 是在SAWSDL的基础上对hRESTS的扩展,对RESTful Web服务进行了4个语义层面的描述。
2 匹配思想
图1给出了基于本体的RESTful Web服务发现框架,该方法的基本思想是提取互联网中RESTful Web服务的HTML文档,通过hRESTS微格式处理,生成服务语法层面的描述,之后用MicroWSMO微格式对服务中的资源进行语义标注。而服务请求者输入的请求条件,经过用户查询处理,抽取其中与服务操作相关的概念,如输入、输出、操作方法等。二者通过匹配引擎来匹配,发现满足请求条件的REST-ful Web服务,通过提取器提取满足匹配要求的服务,提供给用户。
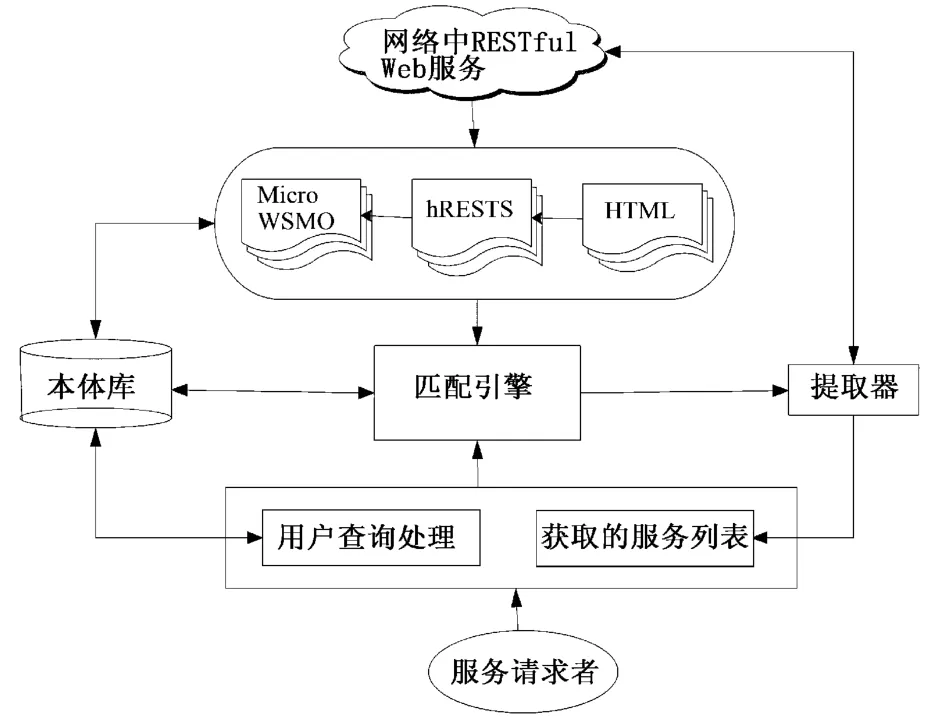
图1 RESTful Web服务匹配模型Fig.1 Matching model for RESTful Web services
3 匹配算法
通过hRESTS微格式对RESTful Web服务的HTML文档信息进行描述,包括了服务的名称、操作及操作的输入、输出和方法等信息。RESTful Web服务是面向资源的服务,主要依靠HTTP提供的方法对资源进行操作,所以,对RESTful Web服务的匹配可以理解为对服务操作的匹配。
3.1 操作相似度的计算
网络中提供的RESTful Web服务的操作定义为Sp=〈In,Ou,Op,Rws,Mt〉,In,Ou,Op,Rws,Mt分别表示操作的输入、输出、内容、所在服务和操作方法。与之对应,服务请求者输入的请求操作可以描述为Sr=〈In',Ou',Op',Rws',Mt'〉,2 个操作的相似度可以定义为
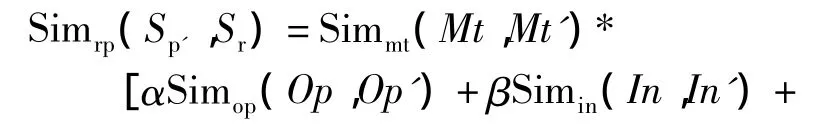
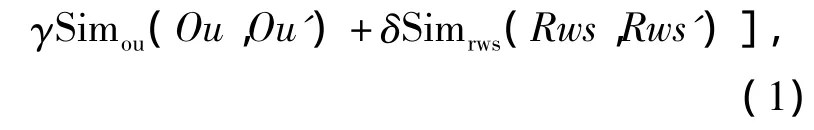
(1)式中:Simop,Simin,Simou,Simrws,Simmt分别为计算操作内容、输入、输出、所在服务和操作方法相似度。α,β,γ,δ为可调节的权重,权重的大小根据该参数的相似度对匹配影响的大小决定,且,α+β+γ+δ =1,0 ≤ α,β,γ,δ≤1。
3.2 本体与分类树
由于本体分类较为广泛,本文只涉及其中的领域本体,领域本体是特定领域内的一组术语及其关系的定义,开发比较复杂,需要相关领域专家的参与[11],本文将不会涉及领域本体库的开发内容,只关注本体概念在服务发现中的应用。在本体的基础上,RESTful Web服务经过MicroWSMO微格式的描述,服务中的参数有了语义解释,服务请求者输入的请求条件经过解析,也有了相应的语义概念。通过领域本体中2个概念之间的语义匹配度来计算操作的相似度。
根据领域本体的概念,可以将某领域中的概念描述成分类树,图2给出了一个由WoT(Web of things)中的资源概念描述成的分类树。图2中,树上的每个节点表示一个概念,概念之间的关系距离表示路径。
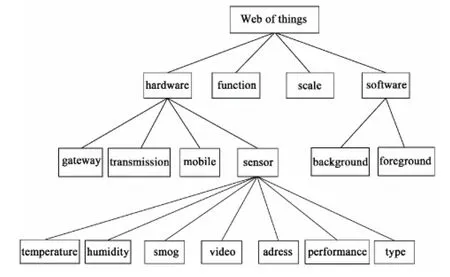
图2 WoT资源概念分类树Fig.2 WoT resources concept classification tree
3.3 概念相似度的计算
分类树中相邻2个节点(Ci,C'i)之间的距离值Dis〈Ci,C'i〉=1 - Sim〈Ci,C'i〉。相邻概念(Ci,C'i)的相似度 Sim〈Ci,C'i〉需根据概念的类型确定,例如:如果(Ci,C'i)为2个数值属性概念,相似度定义为[12]
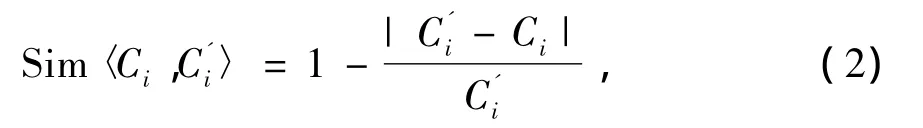
(Ci,C'i)为2个区间属性概念,则定义为[13]
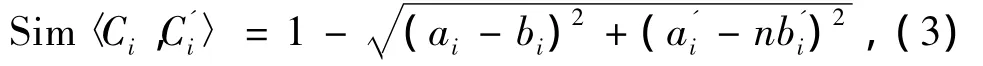
(3)式中:Ci=[ai,a'i],C'i=[bi,b'i]是描述第i个区间型属性规范化后的区间值,ai,bi分别为 Ci,C'i第i个区间型属性规范化后区间值的下限,a'i,b'i为该区间值的上限。
根据领域本体,在分类树中寻找请求本体概念和目标本体概念的流程如图3所示。
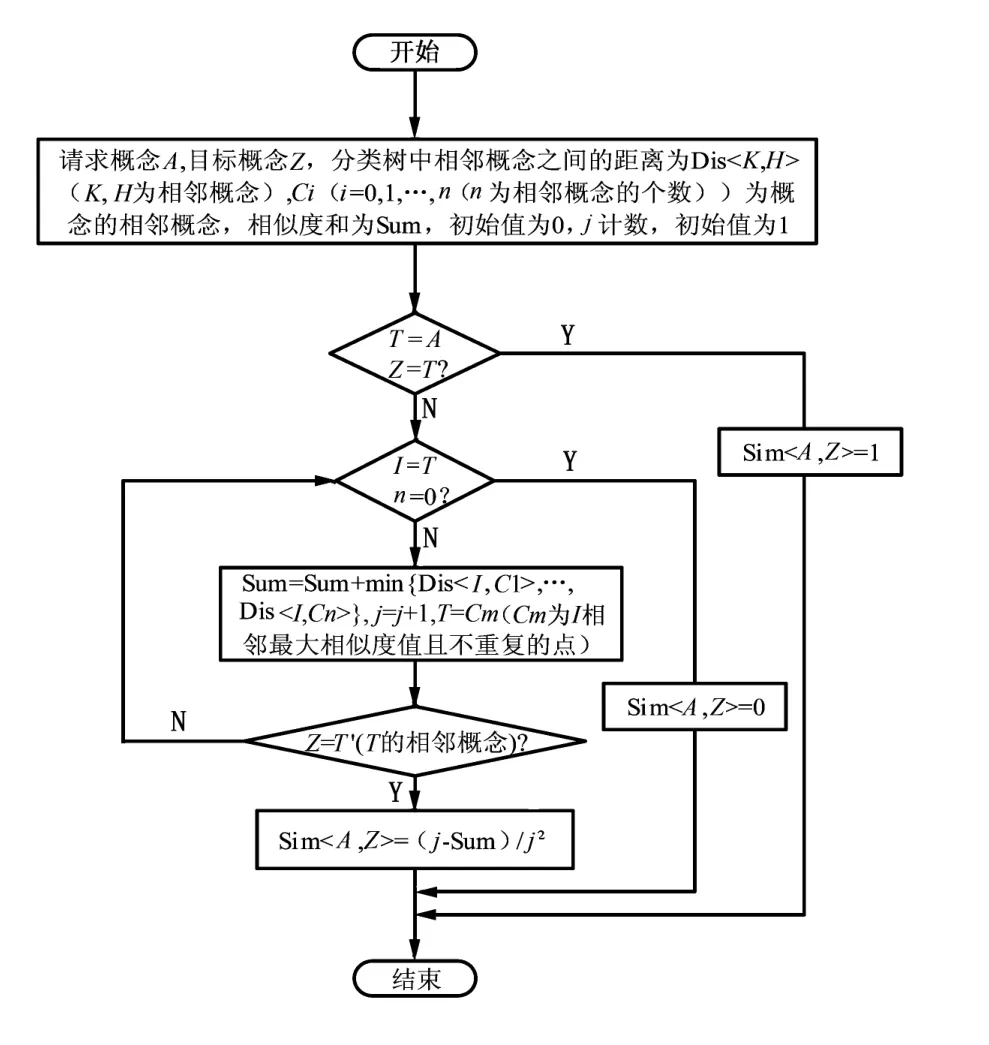
图3 计算分类树中概念相似度的流程图Fig.3 Flowchart about computing similarity between concepts in classification tree
3.4 方法相似度的设定
RESTful Web服务充分利用了HTTP操作方法(GET,PUT,POST,DELETE),但由于服务开发者和服务请求者对这些操作方法上理解不同,会给服务匹配造成误导。所以,为了能够更加全面地发现用户所需要的RESTful Web服务,预先对服务请求用户的要求Ma和服务操作方法Mb的相似度做了定义,如表1所示。
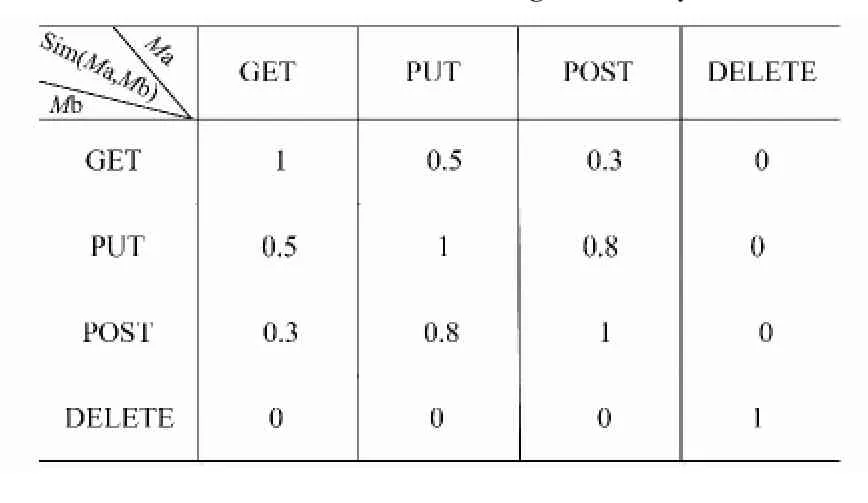
表1 方法匹配相似度Tab.1 Method matching similarity
3.5 服务总体相似度的计算
每个RESTful Web服务都包含一个或多个操作,所以对服务整体的相似度定义为
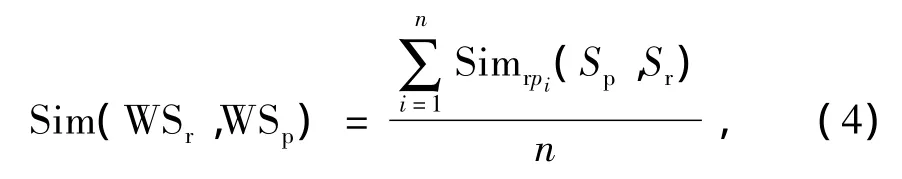
为了能够保证匹配效率,对操作匹配相似度设定一个阀值θ,如果Simrp(Sp,Sr)<θ将直接去除,n为满足要求的RESTful Web服务操作数。
4 模拟实验
为了验证该匹配模型,在实验室开发的REST-ful Web服务基础上,模拟26个类似RESTful Web服务,其中,有104个操作。通过 hRESTS和MicroWSMO描述,获取其中的操作输入、输出,内容、所在服务和操作方法信息,并将信息存入数据库中。表2和表3分别为hRESTS和MicroWSMO描述RESTful Web服务的简单例子。

表2 hRESTS服务实例Tab.2 Service instance of hRESTS

表3 MicroWSMO服务实例Tab.3 Service instance of MicroWSMO
由于没有查找到与本实验相关的领域本体库,所以,需要人为建立领域本体库。为了尽量避免建库过程中的主观因素,需综合考虑目前建立领域本体库的主流方法和服务开发中参数的特点。之后,将建好的领域本体库映射到分类树中,对分类树的相邻节点按照类别根据不同的方法来计算相似度,进而确定节点之间的距离,对于现在还没有很好的方法来计算相似度的相邻节点,就人为确定其距离。再把分类树存储到数据库,每个概念由该节点编号、层编号和父节点编号唯一确定。
输入查询信息,统计本文模型的查全率和查准率,默认 α,β,γ,δ值均为0.25,阀值为0.04。
在Visual Studio 2010开发平台上,通过C#语言编程,将查询条件中的概念和服务中概念对应到分类树,计算相似度,最后将匹配服务提取出来。本实验同时也模拟设计了基于关键字和基于WADL的匹配模型,此处不再详细描述。
图4和图5分别是基于操作相似度和服务整体相似度统计而来,由于现有模型匹配的特点,没有进行操作相似度的比较。从图4可以看出,在查全率方面,本文模型比关键字模型有较大的提高,而查准率方面不及关键字模型,从图5中看出,在查全率方面,本文模型最高;而在查准率方面,基于WADL模型和本文模型都比关键字模型低。无论是操作相似度,还是服务整体相似度,本文模型都比关键字模型低的原因是前者主要关注的是语法、语义上的匹配,而不是概念之间的精确匹配,所以,在提高查全率的同时,会对查准率造成一定的损失,但本文模型在查准率方面较基于WADL模型还是有了较大的提高。
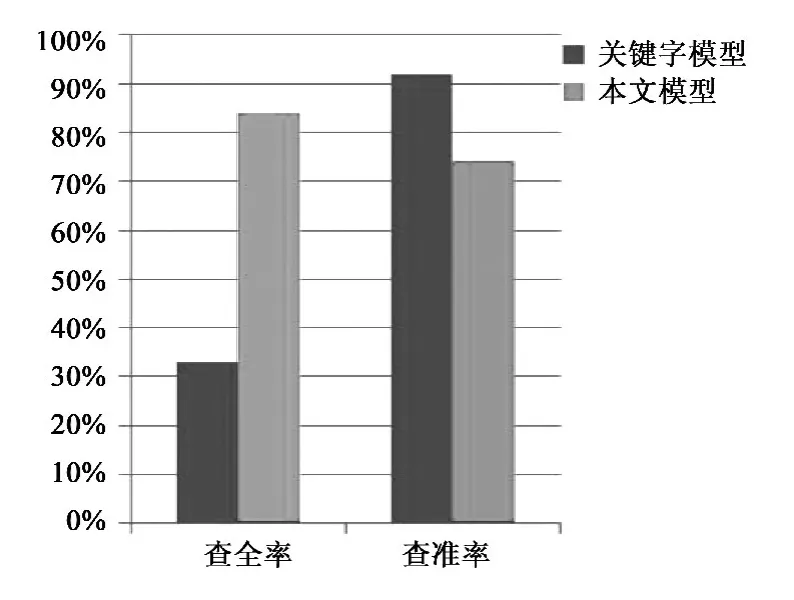
图4 操作相似度效率指标对比Fig.4 Efficiency index contrast of operation similarity
5 结束语
本文模型是在hRESTS和MicroWSDL微格式的基础上,运用一种有效算法,并结合领域本体,将RESTful Web服务和请求条件描述为服务名称、操作及操作的输入、输出和方法信息,再进行匹配,最后提取出匹配的RESTful Web服务。但是,本文中的算法在模拟实验时,只是对α,β,γ,δ和θ人为设定了初始值,而未对其做深入研究,因为这些权重和阀值的大小对匹配的影响很大,后续将对权重和阀值进一步研究。
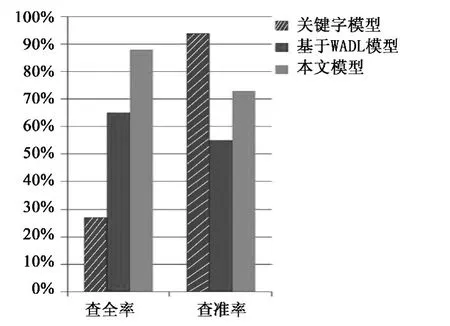
图5 服务整体相似度效率指标对比Fig.5 Efficiency index contrast of overall service similarity
[1]王非,蔡勇,贺志军.RESTful Web Services在信息系统中的应用[J].计算机系统应用,2013,22(2):221-225.WANG Fei,CAI Yong,HE Zhijun.RESTful Web Services Applied in Information System[J].Computer Systems&Applications,2013,22(2):221-225.
[2]LEE Yongju,KIM Changsu.Building Semantic Ontologies for RESTful Web Services[C]//Proc of the Computer Information Systems and Industrial Management Applications(CISIM).Piscataway,United States:IEEE Computer Society,2010:383-386.
[3]PAUTASSO C,ZIMMERMANN O,LEYMANN F.RESTful Web Services vs.Big Web services:Makingthe Right Architectural Decision[C]//Proc of the 17th International Conference on World Wide Web.New York,U-nited States: Association forComputing Machinery,2008:805-814.
[4]JOHH D,RAJASREE M S.A Framework for the Description,Discovery and Composition of RESTful Semantic Web Services[C]//Proc of the 2nd International Conference on Computational Science,Engineering and Information(CCSEIT).New York,United States:Association for Computing Machinery,2012:88-93.
[5]LEE Yongju,KIM Changsu.A Learning Ontology Method for RESTful Semantic Web Services[C]//Proc of the IEEE 9th International Conference on Web Services(ICWS).Piscataway,United States:IEEE Computer Society,2011:251-258.
[6]LI Nan,CAI Hongming.Functionality Semantic Indexing and Matching Method for RESTful Web Services Based on Resource State Descriptions[C]//Proc of the 2nd International Workshop on Computer Science and Engineering(WCSE).Piscataway,United States:IEEE Computer Society,2009:371-375.
[8]MALESHKOVA M,PEDRINACI C,DOMINGUE J.Supporting the Creation of Semantic RESTfulService Descriptions[C]//Proc of the 3rd International Workshop on Service Matchmaking and Resource Retrieval in the Semantic Web(SMR2).Netherlands:Sun SITE Central Europe CEUR-WS,2009:525
[9]SCHULTE S,LAMPE U,ECKERT J,et al,LOG4SWS.KOM:Self-Adapting Semantic Web Service Discovery for SAWSDL[C]//Proc of the 6th World Congress on Services.Piscataway,United States:IEEE Computer Society,2010:511-518.
[10]KOPECKY J,VITVAR T,FENSEL D.Microwsmo:Semantic Description of Restful Services[EB/OL].[2014-01-13].http://wsmo.org/TR/d38/v0.1/20080219/d38v0120080219.pdf.
[11]贺超波,陈启买.基于本体的Web服务发现方法研究[J].计算机工程与设计,2010,31(7):1421-1423.HE Chaobo,CHEN Qimai.Study on approach for web service discovery based on ontology[J].Computer Engineering and Design,2010,31(7):1421-1423.
[12]侯丽娟,李蜀瑜.一种基于情境的语义Web服务发现方法[J].计算机应用与软件,2011,28(1):154-156.HOU Lijuan,LI Shuyu.A context-based semantic Web service discovery method[J].Computer Application and Software,2011,28(1):154-156.
[13]李春梅,蒋运承.具有QoS约束的语义web服务发现的研究[J].计算机科学,2007,34(6):116-121.LI Chunmei,JIANG Chengyun.Study on semantic Web services discovery with QoS constraint[J].Computer Science,2007,34(6):116-121.
