一种融合信任度和相似度的推荐算法
2014-12-14刘群,陈阳
刘 群,陈 阳
(重庆邮电大学计算机科学与技术学院,重庆400065)
0 引言
随着互联网技术的快速发展,推荐系统[1]被广泛地运用于在线网络平台中。协同过滤[2]是目前应用最普遍的一种推荐技术,该方法仅仅依赖于用户对项目的历史评分,计算用户之间的相似性,得到与源用户相似的邻居集合,最后为源用户推荐其可能感兴趣的项目。为了提高算法的性能,使推荐系统有更好的用户体验。近几年,周涛[3-4]等利用物理动力学方面的知识,如物质扩散理论,提出基于物质扩散的推荐算法,刘建国[5]等在协同过滤算法中引入了物质扩散动力学,这类算法的准确性明显好于经典的协同过滤算法,较大地提高推荐结果的准确性。但是,上述推荐技术在处理数据稀疏性,冷启动等问题上存在先天的缺陷。
为了缓解上述算法的不足,基于信任模型的推荐系统[6-7]应运而生。目前,信任已经在推荐系统中得到了深入的研究。TidalTrust[8]利用一种改进的广度优先遍历方法来计算用户之间的信任度。文献[9]介绍了MoleTrust,这种方法与 TidalTrust算法相似,只是在计算源用户与目标用户信任度时,信任的传播距离是一个预先输入的确定值。这类算法通过在用户信任网络中,计算源用户与目标用户之间的信任度,再利用信任度为源用户做出推荐。这种方式能更合理地解释为用户做出的推荐结果,在克服数据稀疏性和缓解冷启动问题上也起了很大的作用,使推荐结果有更高的准确度,同时覆盖率也有了较大的提高,不过仍然需要进一步的提高。
实际上,在基于信任的推荐系统中,源用户信任的邻居倾向于分享各自的兴趣。研究者们发现用户之间的信任关系与用户的偏好有很强的正相关关系,这种方法能有效地减少推荐结果的误差。Ray和Mahanti[10]提出了在用户的信任网络中删除那些相似性低于预先设定的阈值的信任邻居,得到一个新的信任网络,这种方法在推荐精度上有一定的提高,但却牺牲了一定的覆盖率。
针对上述问题,本文提出了一种结合物质扩散和信任模型的融合推荐算法(merge method)。该算法根据源用户直接信任的邻居对项目的评分来表示源用户的喜好,并利用信任邻居评分过的项目集合,结合物质扩散得到源用户的相似邻居,最后,合并信任邻居和相似邻居来计算源用户对项目的预测评分。本文使用2个真实的数据集来评估融合算法的性能,实验结果显示,该混合算法和本文其他算法比起来有更高的准确性和覆盖率,特别是对冷启动用户更有效。
1 融合信任度与相似度的方法
本文提出的融合直接信任邻居集合与相似邻居集合为源用户做出推荐的方法,主要有以下3个步骤:①融合源用户直接信任邻居集合对项目的评分代表源用户的个人喜好;②利用物质扩散理论求出用户之间的相似度,找出源用户的相似邻居集合;③利用信任邻居和相似邻居对给定项目进行评分,为源用户计算对该项目的预测评分。
1.1 合并信任邻居集的评分
记U和I分别表示推荐系统中所有用户和项目集合,rv,i表示用户v对项目i∈I的评分。对于任一源用户u∈U没有评分的项目j∈I,算法的任务就是为源用户u对项目j计算得到一个预测评分,记为u,j。
首先,我们找出源用户u直接信任的邻居集合TNu。对于每一个信任邻居v∈TNu,都与源用户u有一个确定的信任值tu,v,表示用户u对用户v的信任程度。源用户u对项目的评分准确代表了其个人喜好,因此,我们假定源用户u是完全信任自己的,即TNu中包含源用户u,且tu,u=1。
对于每个项目i∈I,如果被TNu中至少一个用户评分过,我们就可以利用用户u与v∈TNu之间的信任值合并u所有信任邻居对项目i的评分,得到

1.2 合并基于物质扩散的协同过滤算法
基于物质扩散理论的协同过滤算法不考虑用户和项目的内容特性,而仅仅把它们都看成抽象的节点,算法利用的信息都藏在用户和产品的选择关系之中。在网络中,所有的用户记为集合U={u1,u2,…,um},所有的项目记为集合 I={i1,i2,…,in},整个推荐系统就可以定义成为一个邻接矩阵A={aij},如果用户uj选择过项目ii,则aij=1,相反则aij=0。对于每个源用户,算法将为该用户得到一个有序的推荐列表,推荐到表中的是源用户没有选择过的项目。
根据上述用户——项目矩阵A,利用物质扩散动力学就可以构建一个用户相似性矩阵,得到每一对用户之间的相似性。首先,假定项目二分图网络中每一个用户具有确定的资源1(用户具有的推荐能力为1)。然后,根据文献[3-4]提出的基于物质扩散的算法:第1步,每一个用户先将自己的资源平均分配给他选择过的项目;第2步,每一个项目将第1步中资源传递后自己得到的资源再平均地分配给选择过它的用户。资源传递完成后,每一对用户之间都会得到一个权重su,v,它表示用户u愿意分配给用户v的那部分初始资源。利用1.1节中得到了合并评分后的项目集合~Iu,根据物质扩散的过程,则用户u和用户v的相似性su,v可表示为
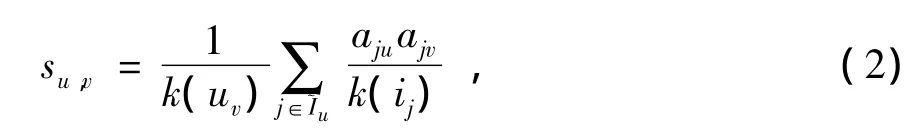
(2)式中:k(ij)表示项目ij的度;k(uv)表示用户uv的度。利用(2)式就可以得到源用户与其他用户间的相似性,进而得出源用户最相似邻居集NNu为
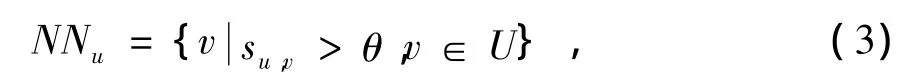
(3)式中,θ是预先设定的相似性阈值。
根据前文所述,对于任一源用户没有评分过的项目j,我们利用源用户与信任邻居TNu间的信任度和最相似邻居NNu的相似度作为权重,合并信任邻居与相似邻居对项目j的评分,则源用户u对项目j的预测评分^ru,j可以表示为
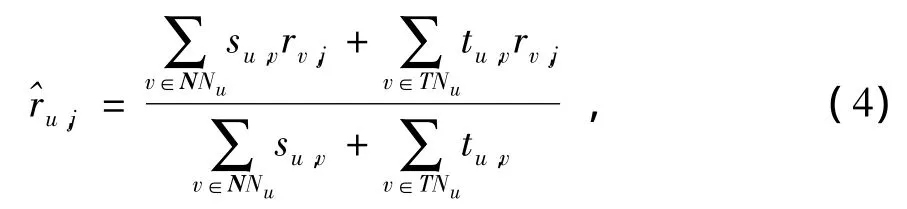
(4)式说明了与源用户u相似度高或者信任度高的邻居对项目的预测评分有很大的影响,使推荐结果的质量更高。
2 实验仿真和分析
为了验证本文提出的融合算法,我们在2个真实数据集上进行了实验仿真。实验的主要内容包括:①融合算法与其他方法进行性能对比;② 信任的传播距离对算法的性能有何影响;③ (3)式中的相似性阈值θ对算法性能的影响。
2.1 实验数据介绍
本文实验使用FilmTrust,Epinions这2个真实的数据。FilmTrust是一个基于信任的社交网站,该网站允许用户对电影做出评分和评论。FilmTrust包括1 986个用户,2 071部电影和35 497个评分(评分从0.5到4.0),以及609个用户做出的1 853条信任评分,信任评分是一个二进制数,1表示信任;0表示不信任。Epinions是一个用户可以发表自己意见的网站,该网站允许用户对电影、书籍、软件等做出评论,也可以对这些产品进行评分(从1分到5分),同时用户也可以对其他用户做出信任评分,信任则为1;反之则为0。该数据集包括49 290个用户对39 738不同的产品至少有过一次评分,总共有664 824评分,用户之间的信任评分有487 181条。
2.2 实验设置
实验中,我们使用如下的方法与融合算法进行比较。
·TrustAll:将所有用户对某个项目评分的平均分作为源用户对该项目的预测评分。
·user-based collaborative filtering(UCF):根据PCC计算用户之间相似性,找出源用户的最近邻居集,对源用户没有评分的物品做出预测评分。
·massive diffusion-based collaborative filtering(MD-UCF):根据物质扩散的过程,得到所有用户最终的资源分配矩阵,用该矩阵的每一个元素代表2个用户之间的相似性,找出相似性大于阈值θ的用户,利用这个相似性作为权重,为源用户未选择过的项目做出预测评分。
·MTx(x=1,2,3)表示 MoleTrust算法[9],x为信任的传播距离,且只有源用户的信任邻居才能参与对项目的预测评分。
·Merge2:表示本文提出的算法Merge的信任传播距离为2的情况,是为了检验信任传播距离对算法性能的影响,该方法也是融合了信任邻居和相似邻居。
同时,我们对数据集中的用户和项目做了如下定义[6]。
·All:表示整个数据集。
·Cold Users:表示评分过的项目数量少于5的用户。
·Heavy Users:表示评分过的项目数量多于10的用户。
·Niche Items:表示被评分少于5次的项目。
在本文实验中,数据划分为80%作为训练集,20%作为测试集。为了检验算法的性能,我们使用平均绝对偏差(mean absolute error,MAE)来验证算法的准确性,用评分覆盖率(rating coverage,RC)来评价算法预测评分项目数量占总的项目的百分比。
2.3 融合算法的性能
首先,固定相似性阈值为0,然后,将融合算法与前文所述算法做比较,并根据实验结果对算法的性能做出评价。表1,表2分别显示了在数据集FilmTrust,Epinions的实验结果。表1,表2中对应算法的MAE值,该值越小表明该算法的准确性越高;对应算法的RC值,该值越大表明该算法的覆盖率越高,性能越好。
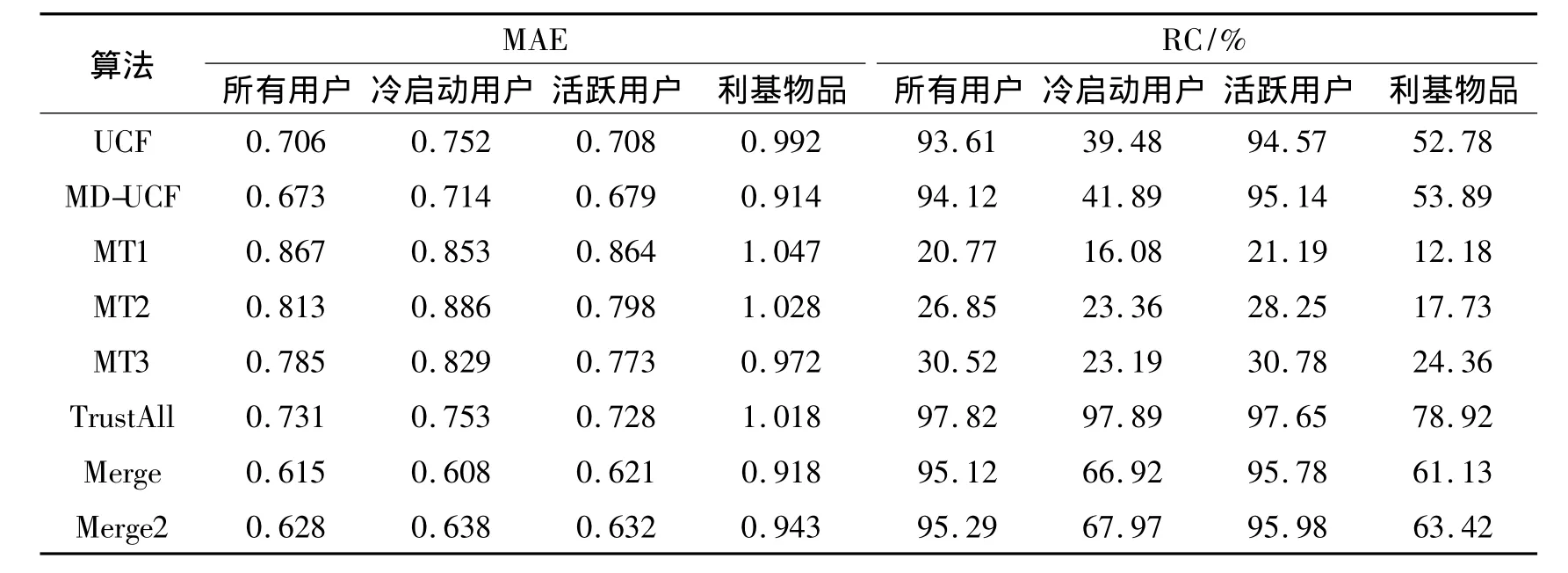
表1 FilmTrust上MAE与RC的实验结果Tab.1 Experimental results of MAE and RC on FilmTrust
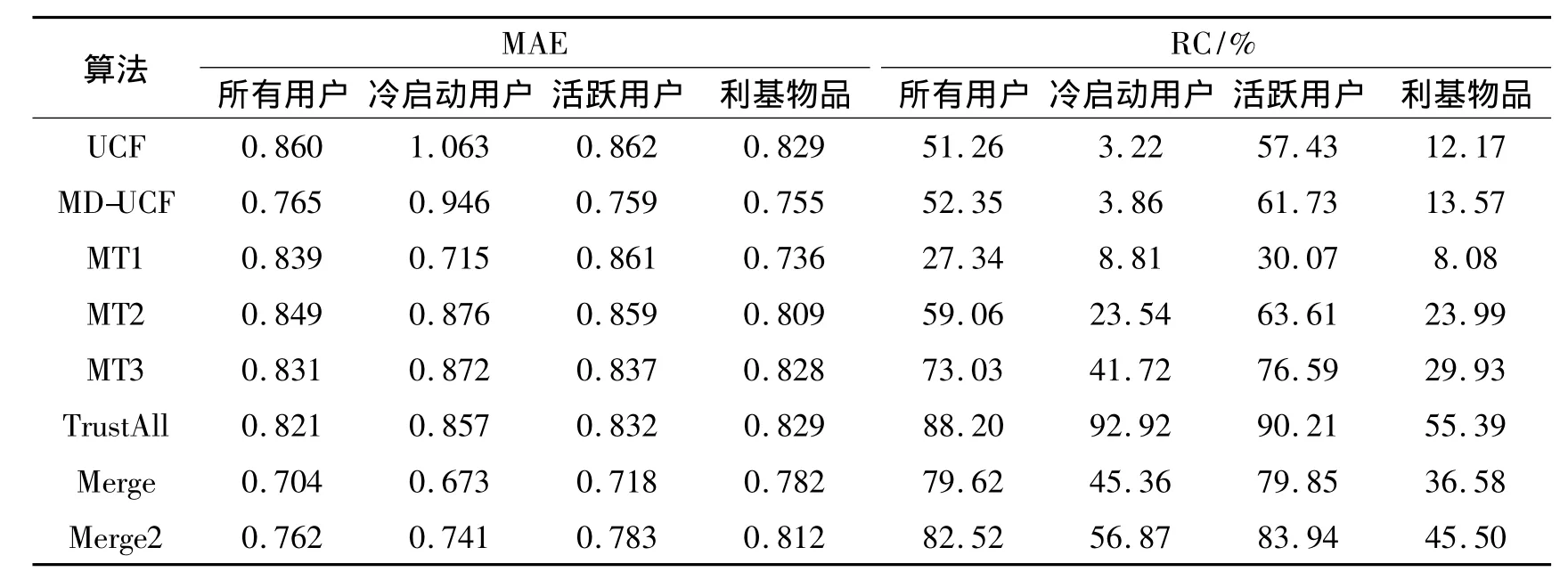
表2 Epinions上MAE与RC的实验结果Tab.2 Experimental results of MAE and RC on Epinions
从表1,表2可以看出,UCF在2个数据集上得到的实验结果有很大的不同,这是由于Epinions比FilmTrust的数据更稀疏,Epinions上冷启动用户覆盖率仅为3.22%,而MAE值却高达1.063。MD-UCF的准确性虽然比UCF要好些,但冷启动用户的评分覆盖率也仅有3.86%。相对于UCF和MD-UCF,从2个表中可以看出,基于信任的推荐算法(MTx),部分缓解了冷启动问题,并且覆盖率随着信任传播的距离增大而有所提高,但是算法整体的MAE值却比MDUCF还要大,甚至有些方面比UCF还大。
前述的3种算法都存在准确性或者覆盖率方面的缺陷,性能甚至比TrustAll还差。反观Merge算法,有更好的准确性和覆盖率。也证明了Merge在保证准确性的同时有效地缓解了冷启动问题,达到了预期的实验效果。同时,本文也比较融合算法Merge和Merge2,我们发现,Merge2的评分覆盖率仅仅比Merge提高了不到1%,但Merge2的平均绝对偏差却有明显地上升。这是因为虽然随着传播距离增加,可以得到更多的信任邻居来表示源用户的个人喜好,但这并不意味着合并后的评分集合覆盖了更多不同的项目,特别是当源用户直接信任的邻居本来就较多的情况下更是如此。此外,信任传播的距离增加,不可避免地将引入脏数据,这样就必然会降低算法的准确性。而且,融合算法已经有了很高的评分覆盖率,更没有必要为了提升很小的覆盖率而牺牲准确性。综上所述,信任的传播距离增加不会对Merge算法有很好的帮助。
2.4 相似性阈值θ
相似性阈值θ在UCF和MD-UCF算法中是一个非常重要的参数,它被用来选择源用户最相似的邻居并参与计算源用户对给定项目的预测评分。当相似性阈值设置较大时,只能得到很少的相似邻居,这样,虽然在准确性上有一定的提升,但牺牲了覆盖率。因此,为了找到一个合适的相似性阈值,我们将θ从0到0.9按照每间隔0.1设置,实验结果分别如图1和图2所示。
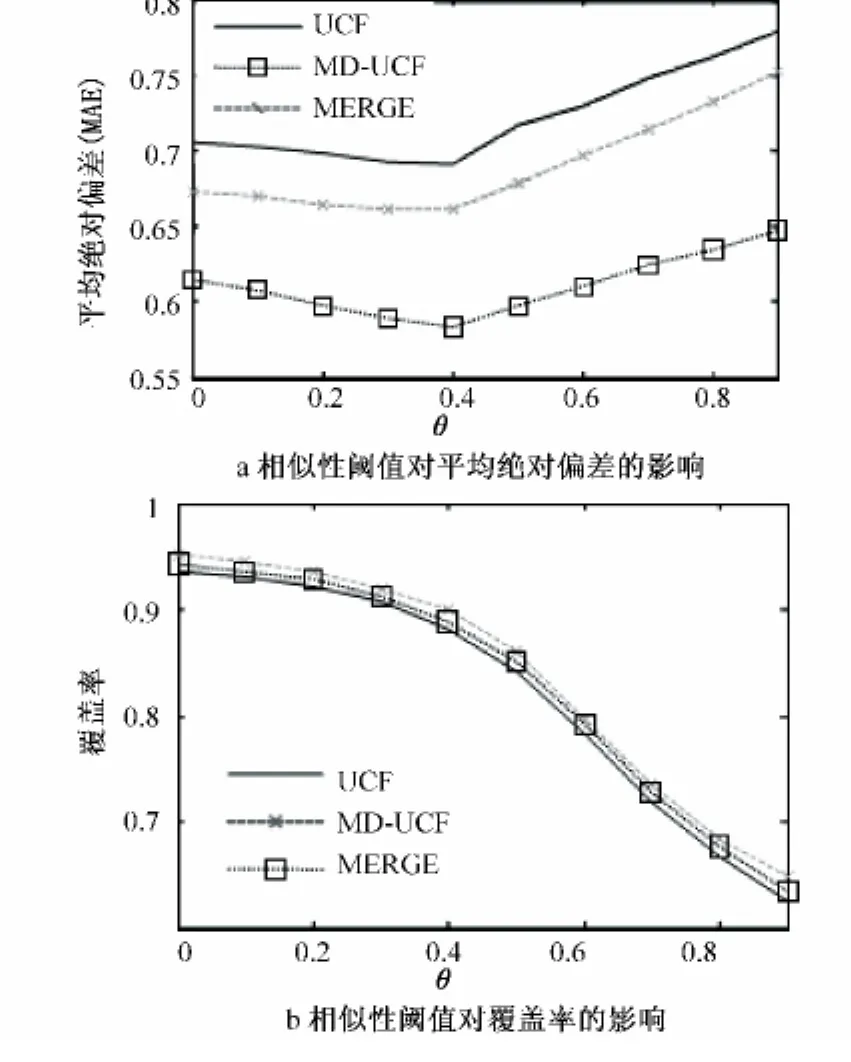
图1 FilmTrust上相似性阈值实验结果Fig.1 Experimental results of similarity threshold on FilmTrust
实验结果显示,UCF和MD-UCF的准确性随着θ提高反而有所下降。这是由于UCF和MD-UCF计算相似性的方法所造成的,当数据稀疏性变大时,用户之间共同评分的项目就会越来越少,UCF算法就很难有效地区别这些相似的用户是否可靠,造成推荐结果不准确。而MD-UCF算法在面对数据稀疏性较大时,用户与项目之间的关联关系则越来越少,难以准确找到用户的相似邻居。本文提出的融合算法随着θ的提高,准确性逐渐上升,但当θ>0.4时,在FilmTrust上准确性又会降低。当相似性阈值分别达到0.4和0.8时,在FilmTrust和Epinions上融合算法达到最高的准确性,并且覆盖率只是略有下降。
由于基于用户信任关系的算法在提高准确性的同时也部分缓解了冷启动问题,基于物质扩散的协同过滤算法则在准确性上比协同过滤有较大的提高。因此,融合这2种算法的思想,既可以利用信任朋友的评分信息,丰富可用数据,提高推荐的可靠性;又可以利用物质扩散倾向于推荐度大的项目,从而是混合算法整体的性能比起单个算法更优秀。通过上文的实验也证明了这种混合后算法可以有效地提高推荐系统的准确性,同时进一步提高系统缓解冷启动问题的能力。
3 结束语
本文提出了一种简单有效的融合推荐算法,该算法混合了基于信任邻居和基于物质扩散理论的协同过滤,为源用户产生推荐。根据2个真实数据集上的实验结果显示,融合算法在准确性和覆盖率上比其他对比算法有了较大的提高,很好地解决了数据稀疏性和冷启动问题,也证明了该算法只需要根据直接信任的邻居便可以得到很好的效果。同时,调整相似性阈值可以使融合算法的性能更进一步的提升,但是仍然不够完善。该算法没有考虑到将信任邻居中与源用户相似性低的用户排除掉,这对算法的准确性有一定的影响。因为实验数据非常稀疏,只有很少的信任邻居对给定的项目有过评分,采用这些评分容易引入脏数据,难以准确表示源用户的个人喜好,进而影响算法的整体性能。在以后的工作,我们将重点处理这些问题,进一步完善算法。
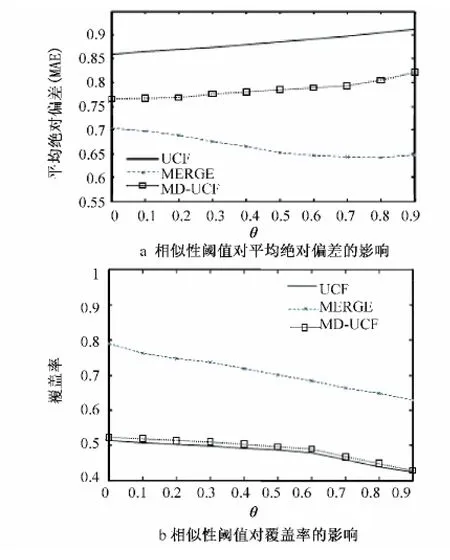
图2 Epinions上相似性阈值实验结果Fig.2 Experimental results of similarity threshold on Epinions
[1]LV Linyuan,CHI H Y,MATUS M,et al.Recommender systems[J].Phys.Rep,2012,519(1):1-49.
[2]SU Xiaoyuan,KHOSHGOFTAAR M T.A Survey of Collaborative Filtering Techniques[J].Journal Advances in Artificial Intelligence,2009(2009):421425-P1-421425-P19.
[3]ZHOU Tao,REN Jie,MEDO M.Bipartite network projection and personal recommendation[J].Phys Rev E,2007,76(4):046115-P1-046115-P7.
[4]ZHOU Tao,JIANG L L,SU R Q.Effect of initial configuration on network-based recommendation[J].Europhysics Letters,2008,81(5):58004-P1-58004-P6.
[5]LIU Jianguo,WANG Binghong.Improved Collaborative Filtering Algorithm via Information Transformation[J].International Journal of Modern Physics C,2009,20(2):285-293.
[6]MASSA P,AVESANI P.Trust-aware Recommender Systems[C]//Proceedings of the ACM Conference on Recommender Systems.Minneapolis:ACM Press,2007:17-24.
[7]JAMALI M,ESTER M.Using a Trust Network to Improve Top-N Recommendation[C]//Proceedings of the third ACM conference on Recommender systems.New York:ACM Press,2009:181-188.
[8]GOLBECK J.Computing and applying trust in web-based social networks[D].Washington D.C.:University of Maryland,2005.
[9]MASSA P,AVESANI P.Trust metrics on controversial users:balancing between tyranny of the majority and echo chambers[J].International Journal on Semantic Web and Information Systems,2007,3(1):39-64.
[10]RAY S,MAHANTI A.Improving Prediction Accuracy in Trust-aware Recommender Systems[C]//Proceedings of the 43rd Hawaii International Conference on System Sciences.Hawaii:IEEE Press,2010:1-9.
[11]李勇军,代亚非.对等网络信任机制研究[J].计算机学报,2010,33(3):390-405.LI Yongjun,DAI Yafei.Research on trust mechanism for peer-to-peer network[J].Chinese Journal of Computers,2010,33(3):390-405.
[12]O’DONOVAN J,SMYTH B.Trust in Recommender Systems[C]//Proceedings of the 10th international conference on Intelligent user interfaces.New York:ACM Press,2005:167-174
[13]乔秀全,杨春,李晓峰,等.社交网络服务中一种基于用户上下文的信任度计算方法[J].计算机学报,2011,34(12):2403-2413.QIAO Xiuquan,YANG Chun,LI Xiaofeng,et al.A Trust Calculation Algorithm Based on Social Networking Service Users’Context[J].Chinese Journal of Computers,2011,34(12):2403-2413.
