视频阵列处理器数据加载电路的设计与实现*
2014-12-10冼子雨柏承双
冼子雨,蒋 林,柏承双,王 汐
(西安邮电大学 电子工程学院,陕西 西安 710061)
0 引言
视频信息的采集、存储、传输与处理一直都是多媒体领域研究的热点[1]。多种视频标准并存,桌面、嵌入式等不同应用,需要兼顾计算高效性和编程灵活性的动态可重构可编程视频处理器体系结构[2]。而传统通用处理器(Gnereal Purpose Processor,GPP)、DSP 以及专 用电路已很难满足视频处理性能和灵活性的要求,所以支持多标准和多种视频编解码算法已成为视频编解码器发展的趋势,这向体系结构设计提出了更高的要求[3-4]。GPP采用RISC指令系统,通过超标量、乱序执行、动态分支预测、推测执行等机制,但执行效率低下,也只能处理较小 的图像[5];如 Intel的 MMX/SSE、IBM 的 AltiVec、HP 的MAX-I/MAX-II等。专用集成电路(ASIC)性能高,执行效率也成倍提高,如TIAN X H[6]通过利用流水线的方式来减少数据相关性,并设计了一种完全支持RDO的上下文存储器管理机制,能够达到每个时钟周期处理一个符号的速度,但它没有了可编程的灵活性,无法适应多标准的发展。现有编解码器体系结构无法完全满足视频处理的需求,研究创新的可编程可重构统一处理阵列体系结构,能够解决视频处理的计算高效性和编程灵活性问题[7-9],但在视频阵列处理器中数据加载已逐步成为阵列处理器的瓶颈。如何减少数据的访存冗余,提高视频阵列处理效率,是一个亟待解决的问题。
本文将要介绍可编程可重构数据加载单元的设计与实现,从而提升视频处理的效率与性能。
1 运动估计算法对存储结构要求
目前在视频编解码标准中,运动估计算法主要是为了除去帧间冗余,使视频传输过程中的比特数大大减少。运动估计基本算法就是要对当前帧和参考帧进行最小平均绝对值误差(MAD)操作,得到其运动矢量发送到解码端。如图1所示,实线框分别表示当前帧(W×H)和编码的当前块(N×N),虚线框分别表示参考帧(W×H)和计算的候选块(N×N),点线框是参考帧的搜索区域(2pv+N×2ph+N)。

图1 运动估计算法图

计算过程包括了六重循环,当前块和候选块的每个像素计算绝对误差和(SAA),候选块遍历了(2ph+N)×(2pv+N)个像素的搜索窗,即在搜索窗内选定了2ph×2pv比较块。一帧图像计算绝对误差和 (SAA)就要进行 W×H×2pv×2ph次操作,每次绝对误差和操作需要2个像素,那么一帧图像要访问存储 2×W×H×2pv×2ph次。若为1 080P 30 f/s,则总线将要读取像素点 7.962 64 Gpixel/s,而实际当前帧和参考帧的全部像素点仅为 2×1 080×1 920×30=0.124 416 Gpixel。访存冗余规定如下:那么存储的带宽 BW=f×W×H×访存冗余当前帧+f×W×H×访存冗余候选块。存储带宽由访存冗余决定,当每个像素只进行一次访存操作时,存储器的带宽最小。所以必须在硬件内部设置像素缓存区域。若系统时钟为100 MHz,进行1 080P 30 f/s帧间预测,那么搜索一帧的最大时间为1/30 s,搜索每个4×4子块的时间为 26个系统时钟。pv=ph=32的搜索区域含有1 024个候选块,每个候选块要进行16次减法和15次加法,即26个时钟要处理1 024个候选块31K次操作,这显然需要多个候选块并行操作,所以存储系统要有能够支持多个候选块并行操作的能力。
2 视频阵列处理器数据加载单元设计
2.1 视频阵列处理器结构
视频阵列处理器可编程可重构的统一体系结构就是采用处理单元(PE)之间邻接互连,基于单指令多数据(SIMD)的数据级并行计算和多指令多数据(MIMD)的指令级并行计算,解决了并行算法和非并行算法的计算高效性和编程灵活性。简单来说就是将算法中灵活的部分用编程方式执行,而算法中计算量较大的部分采用可重构的方式并行处理。图2给出了完整的视频阵列处理器系统结构,包含5个可编程可重构阵列,每个可编程可重构阵列都是通过总线与主处理器连接且可编程可重构阵列之间可以通过寄存器进行通信。每一个可编程可重构阵列包含 16个可编程可重构处理单元组以及一个单元组阵列控制器处理器;每一个处理单元组主要包含一个可重构的4×4处理单元阵列以及一个可编程的处理单元组控制处理器。
该视频阵列处理器可编程可重构的统一体系结构可以完成视频压缩的计算任务,主处理器将不同的视频压缩算法映射到可编程可重构阵列处理器上。根据算法特点分为可重构处理部分和可编程处理部分,用4×4阵列处理单元处理一些计算量大的算法,用可编程控制器处理比较灵活的算法。

图2 视频阵列处理器总体结构
2.2 数据加载单元的设计
访存时,需要局部存储单元加载部分数据,以实现数据复用。对当前帧需要N×N存储大小,而数据复用重叠区域的大小为N×(N-1);对参考帧搜索区域的存储大小为2ph×2pv,数据复用重叠区域的大小为 2ph×(2pv-1)。由于处理单元(PE)不存在局部存储,采用广播策略分派数据。计算过程应该是PC地址和数据地址的计算,所有的操作指令都应由PC和数据地址驱动,系统根据PC取出相应指令得到所需数据,并由数据地址得到对应的数据,由新数据或已有数据计算下一次操作的PC值和数据地址循环往复。其数据流经计算部件输出数据结果,可编程大多是自主申请所需数据,而可重构或ASIC为了更高的性能大多使用地址生成的策略将数据“灌入”计算单元,以节省读取数据的时间,增加系统吞吐率。如图3所示数据存储结构,块区域存储(Block Area Mem)需要兼顾申请读取和“灌入”数据两种模式。实线表示加载数据通过总线分别加载到各个块区域存储中;而当多个PE组需要加载相同数据时,如虚线表示可以通过一个发出读请求的块区域存储广播到其他需要数据的块区域存储中实现数据的共享。
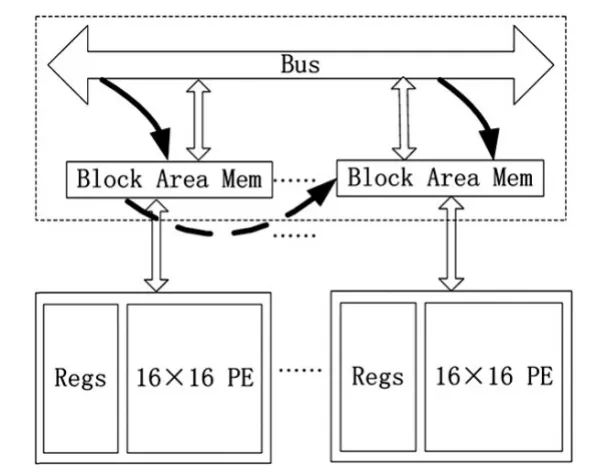
图3 数据存储结构图
块区域存储(Block Area Mem)负责与总线通信,以及数据的缓存,即需要当前帧缓存、参考帧缓存和写入数据缓存。当前帧缓存负责当前块的缓存和预取,参考帧缓存负责参考块的缓存和预取,写入缓存负责重建帧和相关变量的写入。若使用灌入模式,为了达到高的处理能力,块区域存储(Block Area Mem)对当前块和参考块进行缓存和预取,为阵列处理器提供不间断的数据源。在数据加载中搜索窗口的数据量要多于当前块数据,能满足搜索窗口的加载即可满足当前块的加载,若要实时加载32×32搜索区域,每个搜索区域的最大处理时间是4 115 ns,即410个时钟要加载1 024个像素分量,每时钟应加载3个像素。块区域存储(Block Area Mem)采用一次加载4个像素分量设计,即32 bit的数据位宽,256个时钟可以加载一个32×32搜索区域的像素分量。对16×16宏块和 32×32搜索区域数据采用乒乓操作,使当前块和参考帧在“灌入”模式下不间断地提供数据。根据帧间预测算法对存储需求,电路工作在100 MHz下,对于pv=ph=32的搜索区域,每26个系统时钟要处理1 024个候选块,若 16×16 PE组的每个 PE只求一个当前块像素和候选块像素差的绝对值,剩余操作由其他PE组的PE流水完成,那么一个16×16的PE组可以处理16个4×4子块像素差的绝对值。这样要完成1 080P 30 f/s实时整数运动估计,需要读取数据的 16×16 PE组有 1 024/(26×16)=2.462个,且这 3个 PE组可以利用数据共享减少对存储的访问,而总线可以对各块区域存储进行数据广播,为减少对内部总线带宽的要求,块区域存储(Block Area Mem)应具备从总线读取相同数据的能力。在Cache模式下20 KB的当前块缓存和参考块缓存共同构成了16个2路直接相联Cache。
如图 4所示,块区域存储(Block Area Mem)由互连检测模块(connect_chk)、读写控制模块(rd_wt_ctrl)、16×16 Buf和 32×32 Buf构成。
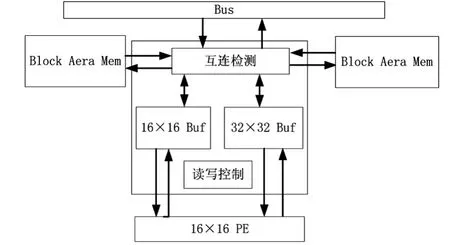
图4 块区域存储模块划分
(1)互连检测模块:主要用于检测相邻块区域存储与本块区域存储的互连情况,根据配置的互连情况与周围模块建立连接,传递数据以实现数据的广播。
(2)读写控制模块:负责在“灌入”模式时计算下次读取数据的首地址、缓冲区的切换及数据写入;在Cache模式时,负责对2 KB寄存器进行管理,构成16个 2路直接相联Cache。
(3)16×16 Buf:用于存储当前块数据,受读写控制模块的控制。
(4)32×32 Buf:用于存储参考块及搜索区域数据,受读写控制模块的控制。
3 结果及分析
用Synopsys公司Desgin Compiler在 SMIC 0.13μm CMOS工艺标准单元库下综合,频率可达197.3 MHz。选用Xilinx公司Virtex6系列芯片Virtex XC6VLX550T进行FPGA验证,综合后的芯片资源使用情况如表1所示。本结构采用Verilog硬件描述,在Questasim 10.1d下完成了功能仿真和验证;图5所示为Cache模式时一组2路直接相连Cache替换策略仿真波形图。
第 1次访问的数据地址 peg_rd_add0为 25’d823区号块号(rd_area_nu,rd_block_nu)即(12,13),在输出有效信号valid0有效时,hit0_0、hit0_1均为低,此次访问没有命中,替换 id(excid0)为低表示本次读取数据应写入本组2路ram中的0号数据ram。第2次访问的地址仍是25’d823,在输出有效信号 valid0有效时,hit0_0有效表示0号ram命中,且0号ram的访问计数counter_0为0,1号 ram的访问计数 counter_1为 1,表明 ram0最近被访问过而ram1没有被访问。第3次访问的地址为25’d564 区号块号(rd_area_nu,rd_block_nu)为(8,13)与 823的块号一致,但ram1数据有效标志tag_valid1无效,表示不发生替换exch0为低。第4次访问地址为上次的564,hit0_1有效表示ram1命中。第5次访问的地址为25’d52 区号块号(rd_area_nu,rd_block_nu)为(0,13),此次exch0为高表示需要替换cache数据块,且excid0为低表示要替换ram0的数据。从上述描述可知,Cache替换策略得以正确实现,电路功能正确。

表1 FPGA芯片资源使用报告表

图5 Cache替换策略仿真波形
从上述分析可知,在Cache模式时对寄存器进行管理。验证结果表明,灌入和Cache模式可以满足1 080P实时处理对数据加载的需求。
4 结束语
本文在研究分析了视频处理编码中运动估计算法的基础上,制定了视频阵列处理器数据加载电路设计的详细方案,通过功能仿真验证了电路功能的正确性,并综合电路,得到了资源占用率、工作频率等指标。结果表明,该电路能够满足1 080P视频处理对数据加载的要求。该研究对于灵活性和高效性的可编程可重构视频阵列处理器结构的设计有重要意义,后期将选用更多的视频算法对该设计进行验证。
[1]毕厚杰.新一代视频压缩编码标准—H.264/AVC(第二版)[M].北京:人民邮电出版社,2009.
[2]CHEN T C,CHIEN S Y,HUANG Y W,et al.Analysis and architecture design of an HDTV720p 30 frames/s H.264/AVC encoder[J].IEEE Trans.Circ.Syst.Video Technol.,2006,16(6):673-688.
[3]LIN Y L S,KAO C Y,KUO H C,et al.VLSI design for video coding[M].Springer,2010.
[4]刘定佳.H_264视频编码算法研究及DSP实现[D].西安:西安电子科技大学,2010.
[5]黄小平,樊晓桠,张盛兵,等.32位双发射双流水线结构RISC微处理器设计[J].西北工业大学学报,2011,29(1):6-11.
[6]TIAN X H,LE T M,HO B L,et al.A CABAC encoder design of H.264/AVC with RDO support[C].IEEE International Workshop on Rapid System Prototyping,2007:167-173.
[7]陶文卿.面向媒体处理的可重构阵列的结构设计与研究[D].上海:上海交通大学,2010.
[8]张鹏,杜建国,解晓东,等.一种基于多核流水的多标准视频编解码器体系结构[J].计算机研究与发展,2008,45(11):1985-1993.
[9]PASTUSZAK G,TROCHIMIUK M.Architecture design and efficiency evaluation for the high-throughput interpolation in the HEVC encoder[C].Digital System Design(DSD),Euromicro,Los Alamitos CA,2013:423-428.