数据仓库构建之数据预备域的数据质量研究
2014-12-06余肖生胡孙枝王东娟王缓缓
余肖生,胡孙枝,王东娟,王缓缓
(三峡大学计算机与信息学院,湖北宜昌 443002)
企业数据仓库主要提供战略信息用于支持管理决策[1]。高质量的数据可能是数据仓库成功最重要的因素[2],而低质量的数据可能对决策产生不利影响[3-4]。数据仓库环境由3个相互独立的组件组成,即数据预备域、数据处理域和数据存储域。其中,数据预备域除了接收来自源应用系统的操作数据外,还执行很多潜在的转换,例如纠正拼写错误、解决域冲突、处理丢失的元素或解析成标准格式等[5]。除此之外,它必须保证数据的完整性。这不仅限于新数据,也针对存储在数据仓库中的所有数据。输出的数据将作为下一步处理的基础。从某种意义上讲,数据预备域输出的数据质量将直接决定着整个数据仓库的质量。本文首先讨论数据仓库的数据预备域和数据仓库的数据质量维度,在此基础上,讨论从操作源应用系统来的数据可能存在的问题,最后针对这些问题,讨论在数据预备域中如何进行处理以得到高质量的数据。
1 数据仓库之数据预备域
数据预备域是数据仓库中关于数据处理的第一个域,如图1所示[6]。在这个域,从源应用系统中接收来的数据将被按数据质量要求进行预处理,以便后续数据的处理和分析可以顺利进行。

图1 数据仓库之数据预备域
1.1 平面文件区
在平面文件区,先接收从源应用系统传送过来的平面文件。有时由于一些原因这些平面文件不可能直接置于操作平台上,因此这些平面文件在该区还需要进一步处理。在接收的平面文件上执行的典型操作有解压缩、验证、处理、压缩、存档等。
1.2 原始表区
原始表区的管理通过DBMS而不是平面文件区的操作系统。这个区中的相关对象是数据库表。
为了使收集、整合或转换等接下来的处理更顺利,在这个区中必须完成许多任务。其中,有些任务是复杂的,而另一些任务则面临着大数据量。针对这种情况,应尽可能地将平面文件区来的平面文件加载至原始表区的各自的表中,主要原因有:
1)表由已命名的行和已排序的数据列组成,而平面文件则包括多行字符,字符之间通过一些特殊字符分隔。因此,相比平面文件而言,表的内容更容易阅读和理解。这与数据调试特别相关。
2)相比操作系统提供的命令脚本语言,DBMS提供的数据操作语言(例如SQL),则更为简单、强大。因此,基于表的程序开发比基于平面文件使用命令脚本语言更容易且更富有成效。
3)为了有效地处理大量数据,一些复杂和巧妙的算法、数据结构、方法等不可缺少。目前,所有这些通常在专业的DBMS中都已实现。另一方面,若没有极大的努力,使用操作系统提供的命令脚本语言实现所有这些几乎是不可能的。
1.3 已预备表区
在预备域中所有处理执行的最终结果都将置于已预备表区,由DBMS管理。这是整个预备域的终点,也是随后处理域的起点。
2 数据仓库之数据质量维度
数据质量是数据仓库中分析结论正确性和有效性的基础,也是最重要的前提和保障。数据质量维度是数据质量的评价标准。为了保证数据预备域的平面文件区、原始表区的数据质量,笔者建立了数据仓库的数据质量维度[7-9](如图2所示),以此作为规范已预备表区中数据的基础。
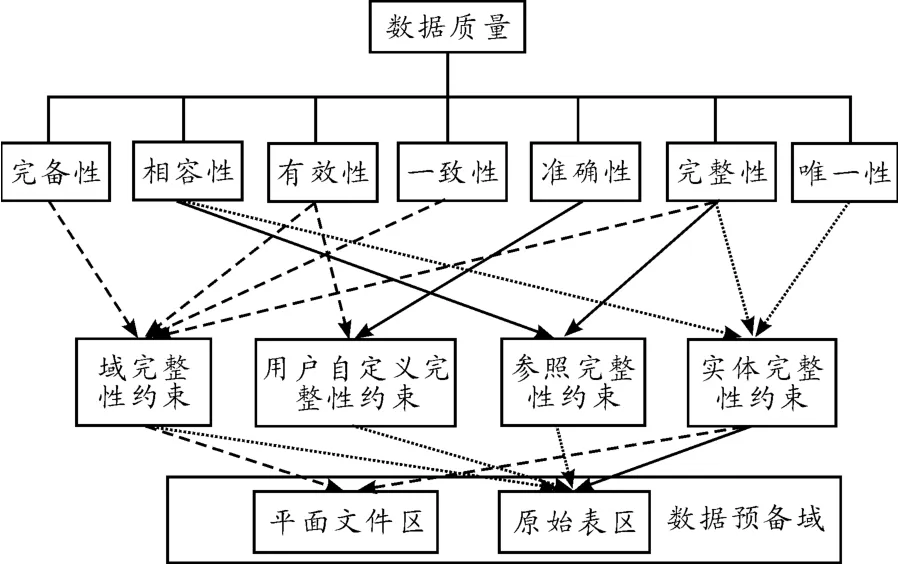
图2 数据仓库的数据质量维度
完备性:数据的完备性确保提供的数据能满足用户的期望且数据是可用的。必须注意的是:尽管数据可能是不可用的,但如果数据能够满足用户的期望,它仍然可被视为完备的。
相容性:为了使数据保持相容,整个企业中的数据应彼此协调,且与其他的数据集没有任何冲突。
有效性:这里指数据的正确性和合理性。
一致性:数据一致性意味着在特定的格式下数据值是一致的。
准确性:如果数据能正确反映现实世界的对象或一个被描述的事件,那么数据是准确的。若产品、人名或地址被不正确地拼写,这些数据迟早会影响操作和分析应用。
完整性:数据的完整性是指数据的可信赖性。如果数据丢失重要的关系连接,不能把相关记录连接在一起,那么它可能会在不同系统之间产生冗余。
唯一性:数据唯一性主要用来避免不必要的数据重复。
数据仓库的数据质量与数据库的完整性约束存在着密切的关系。从图2可以看出:数据库的域完整性约束对数据仓库的完备性、有效性、一致性和完整性等数据质量维度有较明显的影响;用户自定义完整性约束与有效性和准确性等数据质量维度联系紧密;参照完整性约束对相容性和完整性等数据质量维度会产生很大的影响;实体完整性约束往往与相容性、完整性和唯一性等数据质量维度有很大关联。数据质量维度与数据库完整性约束之间的关系没有明显的界线,同一个完整性约束可能同时影响多个数据质量维度,而同一个数据质量维度也可能同时受多个完整性约束影响。
3 数据预备域之数据可能存在的问题
数据仓库构建的每个阶段都存在数据质量问题,而作为接收外部源应用系统数据的数据预备域的数据质量问题显得尤为突出。数据质量问题主要存在于以下几个方面:
3.1 数据不完整
数据不完整是数据预备域中存在的主要问题之一,包括记录的缺失、字段信息的缺失、记录不完整等。数据中的值缺失、列缺失,源数据校验标准的缺乏以及未定义或不明确定义的参照完整性都是数据不完整的表现[8]。此外,未指明值域和数据类型也很大程度地影响了数据的完整性[10]。
3.2 数据不一致
数据不一致主要体现在系统之间或功能模块之间的记录不一致、编码不一致、引用不一致等[8]。此外,数据类型不一致、数据描述不清晰、信息句法和数据语义不明确以至于无法捕捉真实值也会产生数据不一致[10-11]。
3.3 数据错误
数据错误主要体现在数据类型错误、数据范围越界、数据违反业务规则等[10]。另一方面,数据采集和数据运算的错误也是导致数据错误的主要原因。
3.4 数据不准确
数据不准确是导致数据质量低下的原因之一,主要表现在数据源中使用了近似值或替代值,数据值不符合字段描述和商业规则等。
3.5 时效性问题
同一个数据源中可能由于没有及时更新或者更新失败致使数据失效,不同数据源依据各自的业务规则定义的数据时效各不相同。另外,某一业务系统中的数据更新没有记录或者没有传递到其他的系统中也会使得数据失去时效,从而导致数据质量问题[10]。
3.6 数据冗余
同一数据由于存在于多个数据源中,又缺乏统一建模而产生数据冗余。此外,对于数据仓库而言,并非所有的源应用系统传递来的数据行都是相关的[10]。
4 数据预备域之数据处理方法
数据预备域采用错误拒绝、列清洗、行过滤等方法[6]来处理进入数据仓库中的数据,保证进入已预备表区的数据是“清洁”的。由于数据仓库在构建过程中不断地有新数据载入,因此先要识别已有数据和新加载数据之间的变化量。
4.1 变化量识别
变化量是指与上次交付的数据相比,此次交付时的变化。变化量可定义如下:
两个时间点 t1,t2,t1<t2,数据集 DS在时间点t1,t2的差异就是数据集在t1,t2的变化量,即(DS_t2-DS_t1)∪(DS_t1-DS_t2)。
数据仓库应该有自己的机制来识别变化量,否则受到影响的源应用系统只能周期性地交付完整的全部数据。
为了正确识别现在接收的与先前接收的全部数据之间的变化量,应满足以下条件:
1)先前的全部数据直接可用,并且存储在数据预备域的一个表中。2)前后两次交付的数据有完全相同的模式。假设目前的全部数据FS_new与先前的全部数据FS_old都满足以上条件,则:
纯插入(INSERT)部分:FS_new-FS_old,FS_new≠FS_old
纯删除(DELETE)部分:FS_old-FS_new,FS_new≠FS_old
修改插入(INSERT)部分:FS_new-FS_old,FS_new=FS_old
修改删除(DELETE)部分:FS_old-FS_new,FS_new=FS_old
将这4个部分合并得到完整的变化量。
4.2 错误拒绝
如果这些表定义明确且利用了合适的加载工具,加载过程中就能检测出重复的行和重复的码。事实上,在不同层次上,表已经定义了许多约束来保证这个阶段的数据质量。不满足约束的行将被拒绝且被写入一些特定的数据错误表中。
4.3 列清洗
根据数据仓库的要求和标准,如果不能保证从源应用系统传递过来的数据都满足数据仓库的数据质量维度,那么清洗数据就是数据预备域的任务之一。
为了清洗数据,需要建立一个至少含有以下列的转换表:
①源应用系统;
②数据类型;
③该数据类型的本机默认值;
④在数据仓库中该数据类型的相应的标准默认值。
在这个转换表中的行意味着:如果讨论中的列是来源于已给定的源应用系统,具有指定的数据类型,并有规定的本机默认值,那么这个表中的行现在应该包含数据仓库中指定的标准值。
由于源应用系统没有安全的数据类型系统,故应该创建一个校正表,且至少包含以下一些列:
①源应用系统;
②源表;
③数据类型VARCHAR的源列;
④源列错误值的域;
⑤在校正的情况下,这个列正确的默认值;
⑥当检测到一行包含不正确的值时,应该诱发附加的指令。
这个校正表中的行意味着:如果从给定的源应用系统来的源表列中,其中一个目标列有错误值,那么提供的正确值将被用于数据仓库。如果需要附加的指令,如将包含错误值的行写进错误表,那么指令将被执行。
校正表将用以下附加列来扩充:
①源列的格式,如:在VARCHAR中表示的日期“YYYYMMDD”或“YYYY-MM-DD”。
②数据仓库中目标列的数据类型,如:DATE或TIMESTAMP。
带有这些附加列的行意味着:源列的值应该按照指定的格式正常地转换成给定数据类型的目标列的值。按照定义,如果结果值是错误的,那么指定的正确值将被用于目标列。
假设以上描述的转换表和校正表是可利用的,则可按以下步骤进行列清洗:
1)从数据库目录提取讨论中的源表列,根据它们的序列号给它们排序;
2)如果转换表、校正表是可用的,则合并转换表或校正表或两者中相应的行;
3)对于包含在1个或2个表的每个列,根据表中提供的信息,相应地构建转换表和/或校正表的片段;
4)构造2个列列表:
①目标列表:从数据库目录中取这些列。
②源列表:用与目标列表相同的顺序。如果这个列在步骤3)中已经处理,那么取结果片段;否则,从数据库目录取它自身;
5)构造一个语句:INSERT INTO〈目标列表〉SELECT〈源列表〉FROM源表。
4.4 行过滤方法
即使只考虑最后一次更新后的变化(即变化量),也不是所有从源应用系统中传递过来的行都与数据仓库有关。由于无关数据行的处理可能消耗一部分系统的存储和处理能力,因此数据预备域的下一个任务是从传过来的数据中过滤不相关的行。此外,它经常需要识别剩下的行的相关操作以正确地更新数据仓库。
在不失一般性的情况下,为简单起见,假设被处理的行来自于源应用系统网站的日志,且由5个部分组成。每行的第1部分是标识顺序的序列号(Sequence_No),这里,该行被添加到该应用程序网站的日志中。第2部分是对象键(Object_key)或用多行描述的事件的数量。注意,即使在一个更新周期内,一个对象或一个事件也可以由多行来描述。第3部分是时间点(Time_Point),即表示对象数据的“状态开始”(state_start)或事件数据的“发生”(occurred_on)。第4部分是包含描述内容的行的业务信息(Business_Information)。每一行的第5部分表示2个基本操作(Elementary_Operation)中的一个,即INSERT或DELETE。总之,输入行具有下面的模式:

Sequence_No Object_key Time_Point Business_Information Elementary_Operation
假设输出行(即处理后剩余的行)有下面的模式:

Object_key Time_Point Business_Informatio n Elementary_Operation Original_Operation
Original_Operation是指通过操作应用系统来执行相应记录上的原始操作。它们插入一条新记录,删除或修改一条已经存在的记录。通过该任务,必须确认每个剩余行。仅保留与数据仓库相关的行做进一步处理,其余的都按这种方法过滤掉。此外,为了进一步处理,Sequence_No将不会被使用,这样它就不再保存在输出行中。
假设输入和输出行分别具有以上描述的格式,则可按以下步骤进行过滤:
1)通过对象键和时间点组合对所有行进行分区;
2)在每个分区内,根据序列号升序排列所有行,注意排序后分区内的第一个行和最后一行;
3)对每一行进行下面的操作:
①如果行是分区中的第一行且基于此行的基本操作是DELETE,那么这个行是相关的;
②如果行是分区中的最后一行且基于此行的基本操作是INSERT,那么这个行是相关的;
4)对每一个相关的剩余行进行以下操作:
①如果在这个行上的基本操作是DELETE,同时,如果这个行是分区中的最后一个剩余行,那么相关的原始操作是DELETE;否则,相关的原始操作是MODIFY;
②如果在这个行上的基本操作是INSERT,且这个行是分区中的第一个剩余行,那么相关的原始操作是INSERT;否则,相关的原始操作是MODIFY。
5 结束语
通过错误拒绝、列清洗、行过滤等处理,从各种源应用系统来的数据基本上消除了数据不完整、数据不一致、数据错误、数据不准确、数据冗余等数据质量问题,为数据仓库后续处理提供数据质量上的保障。
[1]Kimball,R Reeves L,Ross M,et al.The Data Warehouse Lifecycle Toolkit:Export Methods for Designing,Developing and Developing and Deploying Data Warehouses[M].Indiana:Wiley Publishing Inc.1998.
[2]Loshin D.Data Quality ROI in the Absence of Profits[J].Information & Management,2003(9):22.
[3]Huang K,Lee T,Wang Y W,et al.Quality Information and Knowledge[M],NJ:Prentice-Hall,1999.
[4]Clikeman P M.Improving information quality[J].Internal Auditor,1999(3):32-33.
[5]Kimball R,Ross M.The Data Warehouse Toolkit:the complete guide to dimensional modeling(Second Edition)[M].NEW YORK:Wiley Computer Publishing,2002:7-8.
[6]Bin Jiang.Constructing data warehouses with Metadatadriven Generic Operators and more.Switzerland,DBJ Publishing,2011.
[7]Singh R,Singh K.A descriptive classification of causes of data quality problems in data warehousing[J].International Journal of Computer Science Issues,2010(3).
[8]程大庆,郑承满.数据仓库数据质量的治理及体系构建[J].中国金融电脑,2011(6):28-34.
[9]刘润达.社会化媒体数据质量评价初探[J].中国科技资源导刊,2012(2):72-79.
[10]Markus Helfert,Gregor Zellner,Carlos Sousa.Data Quality Problems and Proactive Data Quality Management in Data-Warehouse-Systems[EB/OL].[2013-11-12].http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.98.5149&rep=rep1&type=pdf.
[11]Thomas C.Redman,Ph D.Data Warehouses and Quality:Not Just for IT Anymore[J].A Navesink Consulting Group White Paper,2008.
[12]陈林,陈维义.基于数据仓库的海军要地防空作战决策支持系统[J].四川兵工学报,2011,32(7):90-92.
