基于关联规则的术语自动抽取研究*
2014-12-03王昊贤李广建
王昊贤 李广建
(北京大学信息管理系 北京 100871)
术语自动抽取是自然语言信息处理中的一项重要课题,在机器翻译、信息检索、词典编纂、文本分类和自动文摘等领域中有重要的作用。目前,人们已经从多个方面提出了各种方法,并且不断有新的方法出现。本文的目的是研究关联规则算法抽取术语的可行性及优势。
1 相关研究
国内外研究人员已经通过大量的研究工作取得了一系列的成果。归纳起来,术语自动提取的方法可以分为基于语言学知识的方法、基于统计学原理的方法以及基于语言学知识和统计学原理结合的方法。
1.1 基于语言学知识的自动抽取方法
基于语言学知识的方法,又称为基于规则的方法。所谓的“规则”指的是术语的词法模式、词形特征、语义信息等,利用这些知识可以从语料中抽取出术语或者识别术语在语料中的位置。基于语言学知识的术语自动抽取研究主要集中在上个世纪90年代,以Justeson&Katz算法为代表,该算法首先确定一系列语言性质的规则,然后用这些规则来识别文本中的术语。较为成熟的自动术语抽取系统有 FASTR 系统、Termight系统、Termino 系统、Nodalida 系统、Clarit系统、Heid-96 系统、Lexter 系统和 Naulleau-98 系统等。
1.2 统计学原理的抽取方法
基于统计学原理的抽取方法,主要利用统计学的原理计算出文本的各种统计信息,并利用统计结果选取术语。在线系统Term Extraction通过简单统计基本词频来实现术语识别。Termextractor系统也是如此,通过统计选取高频词为术语。RIDF算法则不同,该算法关注低频词,在逆文档频率(IDF)的基础上,利用Poisson检验来确定术语;互信息方法也是一种比较常用的术语抽取算法,它利用两个或两个以上的词之间的互信息度,来决定这些词汇是否组成一个复合词,即它们是否组成了一个术语。
1.3 基于语言学知识与统计学原理结合的抽取方法
目前,单纯运用语言学知识或者统计学原理的抽取方法并不多见,因为,基于语言学知识的方法和基于统计学的方法虽各有优势,但也有明显缺点。因此,有很多研究将基于语言学知识的方法与统计学原理的方法结合起来,力争扬长避短。例如,将统计学的策略融入到基于语言知识的抽取方法中去,将二者有效地结合,可以显著改善术语抽取系统的性能。这方面的代表方法是C-value/NC-value方法,该方法综合运用结合语言知识和统计信息来提取由多个词汇组成的术语。C-value/NC-value方法包括了两个步骤,首先,用C-value方法计算词汇的出现频率测量,找出多词候选术语,然后利用NC-value方法根据词的上下文信息,最终确定要抽取的术语。近年来,机器学习的方法是这类基于语言学知识与统计学原理结合的抽取方法的一个重要发展方向,并取得了较好的抽取效果,它主要通过利用计算机对先前知识进行学习(训练),利用这些训练的经验来对后续的文本进行相应的抽取,得出准确术语。
2 关联规则方法及其抽取术语的可行性分析
2.1 关联规则的基本原理
韩家炜在《数据挖掘概念与技术》一书中给出了关联规则的确切定义:
项的集合 I={I,I,I,…,I},数据库中事务的集合T={t,t,t,…,t},每个事务 t则是项的集合,即 t⊆I。若X→Y,满足 X⊂I,Y⊂I,且 X∩Y=φ,则 X→Y 为 T 中的关联规则。
关联规则中,支持度(Support)是指T中的事务同时包含X、Y的百分比:

置信度(Confidence)是指T中事务已经包含X的情况下,包含Y的百分比:

若关联规则X→Y,同时满足支持度大于最小支持度Support(X→Y)>minSupport和置信度大于最小置信度Confidence(X→Y)>minConfidence,则认为关联规则 X→Y是有趣的,即为强关联规则,其中,最小支持度和最小置信度的阈值均人为设定。关联规则挖掘就是在事务集合中挖掘强关联规则。
关联规则关注两个事项的共同出现,或者说在前驱出现的条件下,后继也出现,其经典应用是发现顾客的购买规律(如沃尔玛超市发现的“啤酒和纸尿裤”的购买规律),在图书馆中进行书目推荐以及火灾分析、交通事故处理、森林病害虫预测和肺肠合病医案用药规律研究等。
2.2 术语构成基本原理
术语是特定领域中概念的语言表示,它可以是字、词语或者字母与数码符号。按照术语的构成,可将术语分为简单术语和复杂术语。简单术语,就是指仅由一个单词构成的术语。例如:“信息 (information)”、“天 (sky)”、“雨(rain)”等。这样的简单术语不能再分解为更小的具有独立含义的单元。复杂术语,则是指由两个或更多单词或语素按照一定的语法或语义结构组成的术语。例如:“信息检索 (information retrieval)”、“复杂系统 (complex system)”、“计算机系统理论(computer system theory)”等,其中“信息检索(information retrieval)”是由“信息(information)”和“检索(retrieval)”构成,“复杂系统(complex system)”是由“复杂(complex)”和“系统(system)”构成。
2.3 关联规则抽取术语的适用性
从以上关联规则的定义可以看出,事务组合(X→Y)满足最小的支持度和置信度,就可以称之为“规则”,这就说明关联规则中强调的是事项(即上述定义中的“项”I)的共同出现,或者说在前驱出现的条件下后继出现。
术语的基本构成方式与关联规则方法关注的内容具有一定的契合点,例如,如果我们把构成复杂术语的每个单词或语素(以下简称词汇)看作是“项”,那么,能共同构成一个复杂术语的若干个词汇(项)必定会同时出现,因而可以根据词汇之间的关联程度来达到提取复杂术语的目的。不过,与一般的关联规则发现中仅强调“共现”有所不同,构成复杂术语的词汇之间必须具备位置相邻性,而不是单纯的“共现”,也就是说,在经典的关联规则方法中引入项之间的邻接性限定,是关联规则应用于术语抽取的关键。
由此,术语抽取中的关联规则可以表述为:若词汇X与词汇Y依次邻接出现,且满足最小的支持度和最小的置信度,则可以认为词汇X和词汇Y按照XY的次序,组成复杂术语。其中,关键的两个参数即支持度和置信度可以这样理解,支持度体现了词汇邻接出现的频率,支持度高,说明词汇邻接组合出现的次数多,这样邻接出现的词汇往往就会组成一个术语。置信度是指在词汇X出现的条件下,词汇Y紧跟其后出现的概率,或者在词汇Y出现的条件下,词汇X恰好出现它前面的概率,置信度越高,说明词汇X和词汇Y的组成一个复杂术语的可能性越大。所以,可以这样给支持度和置信度下定义:
支持度为词汇X和词汇Y依次邻接出现的概率,即:

其中,N为用于术语抽取的文本的句数。
置信度为在词汇X出现的条件下,词汇Y紧跟X后出现的概率或词汇Y出现的条件下,词汇X和词汇Y依次邻接出现的概率,即

或

如此,一个复杂术语的抽取将涉及到一个置信度的集合C,如果抽取者更重视召回率(Recall),置信度可取集合中的最大值(confidence=max(C)),并将它与预定的最小置信度比较,这样的取值强调在置信度集合C中“存在”比最小置信度大的值,能够保证召回率。
如果抽取者更重视准确率(Precision),置信度可取集合中的最小值(confidence=min(C)),并将它与预定的最小置信度比较,这样的取值强调在置信度集合C中的“所有”值均比最小置信度大,能够保证准确率。
如果抽取者的要求比较苛刻,需要召回率和准确率均较高,但由于召回率和准确率呈反比例关系,取最大值和最小值的方法均不可取,必须选取最大值和最小值之间的合理的数值,这个值可以为置信度集合的算数平均数、几何平均数以及中位数等。
这里给出的置信度的定义,与经典的关联规则不同,它不涉及“前驱”和“后继”的概念,在术语抽取中区分词汇的“前驱”和“后继”的意义不大。这里的置信度是指多个词汇组成新的复杂术语的可能性的大小。
3 实验结果及分析
3.1 实验基本条件与内容
实验的基本条件如表1所示。
3.2 用关联规则方法进行术语抽取的实验过程及结果
(1)基本结果展示
表2是利用关联规则FT-tree算法,对图书馆学情报学领域中英文文摘进行术语抽取所得到的部分术语。
(2)中英文对照实验
从理论上讲,中英文在利用关联规则进行抽取时仅有预处理部分有所不同。中文不像英文那样词与词之间存在着空格,因此在预处理时需要对中文进行分词。在中英文对照实验中,对图书馆与情报学领域的全部中英文数据进行了抽取,实验使用了49种最小支持度和最小置信度组合,得到了49种抽取结果,表3列出了这49种抽取结果中最高的F-measure值、召回率值或准确率值(最高项用阴影标识)及它们对应的支持度与置信度取值。

表1 实验基本条件表
从表3中可以看出,在应用关联规则进行术语抽取时,可以通过合理配置参数(最小支持度和最小置信度)而得到满意的效果,而且,无论是对于中文文本,还是英文文本,都可以通过配置不同的最小支持度和最小置信度来获得较好的抽取效果。这说明,用关联规则方法进行术语抽取不存在语言依赖,如果不考虑不同语言在预处理阶段有较大的差别,关联规则方法可以用于抽取任何一种语言中的术语。

表2 输出结果表

表3 中英文对照表
(3)数据量大小对照实验
分别以10条、100条、1000条图书馆学与情报学的英文数据作为抽取对象,每一种数据量都可以得到49种抽取结果,表4列出了这些结果中最高F-measure值、召回率值或准确率值(最高项用阴影标识)及它们对应的支持度与置信度取值。

表4 数据量大小对照表
从表4中可以看出,关联规则方法不适用对数据量过小的数据集进行抽取,相反,数据量越大,抽取效果越好,而且,对于不同数量的数据集,同样可以通过配置不同的参数来达到用户最满意的效果。
(4)不同学科数据对照实验
实验过程中,除图书馆与情报学数据之外,还增加了数学和地球科学的数据,分别对这三种学科的数据进行术语抽取,对每一个学科的抽取结果,做与表3或表4相同的统计分析,得到表5的结果。

表5 不同学科对照表
从表5可以看出,用关联规则方法对各个学科的文本进行抽取,均能得到较好的结果,这说明,关联规则应用于术语抽取不存在学科依赖,即使用关联规则进行术语抽取不存在学科限制。在本实验中,由于不同的学科具有不同的数据量,同时,各个学科的术语结构、已知术语等有所区别,因而达到最佳抽取结果的参数配置(最小支持度和最小置信度)也有所不同,这再次证明,合理的参数配置是将关联规则应用于术语抽取的关键问题之一。
3.3 关联规则方法与其他方法的对比实验及结果
以图书馆学与情报学领域1000条英文文摘数据为处理对象,分别用互信息(基于统计学原理方法)、Justeson&Katz算法(基于语言学知识方法)、C-value算法(基于语言学和统计学结合方法)以及关联规则的FT-tree算法进行术语抽取,以下是实验过程中算法的实现难度、算法所需资源以及算法抽取效果等三方面比较结果。
(1)算法实现难度比较
算法实现难度是算法实用性的标志之一。表6列出了实验中使用的四种算法的核心代码量、核心内容和人为参与情况。
从表6可以看出,关联规则有着较小的代码量,但各个算法的核心代码量不存在数量级上的明显差别。在需要加载的内容方面,C-value/NC-value和Justeson&Katz算法需要加载规则,这类算法需要很强的先验知识,关联规则和互信息方法则不需要过多的规则,仅在在预处理部分做停用词拆分和已知术语切分即可。值得一提的是,四种算法均必须人为控制参数,而且这些参数都是至关重要的。从总体上看,关联规则方法拥有较小的代码量,较简单的抽取步骤和少量必须的人为参与,因此,关联规则应用于术语抽取有着易于实现的优势。

表6 算法实现难度比较表
(2)算法所需资源比较
运行算法时所需计算机资源的多少,是算法可用性的重要表现。计算机资源最重要的是时间和空间资源。以1000条图书馆学与情报学英文数据(大小为1028kb)为处理对象,统计各算法在术语抽取时的时间消耗以及最大内存占用量,结果如表7所示。

表7 资源占用比较表
从表7中可以看出,FT-tree(关联规则)和互信息算法具有明显的运行时间优势,C-value/NC-value和Justeson&Katz算法除进行基本词频统计和参数控制外还需要进行规则的加载和筛选,因而时间消耗较大。在占用内存方面,FT-tree(关联规则)和互信息算法同样有明显优势,C-value/NC-value和Justeson&Katz算法所使用的规则库必需常驻内存,同时,为了满足规则匹配的需要,这两种算法还要求对每个词进行词性的标注等,所以其所需内存较大。这一结果表明,关联规则算法在算法的可用性即占用计算机资源方面具有一定优势。
(3)算法抽取效果比较
算法的抽取效果是评价算法优劣的重要方面。此部分实验,是中英文对照实验中的运行结果。算法的参数配置,关联规则选取本节数据量大小对照实验运行结果F-measure值最高的一组支持度和置信度,其他算法的参数配置来源于相应的参考文献[1,13,14]。算法的抽取效果从准确率、召回率和F-measure三个指标进行评价,结果如表8所示。
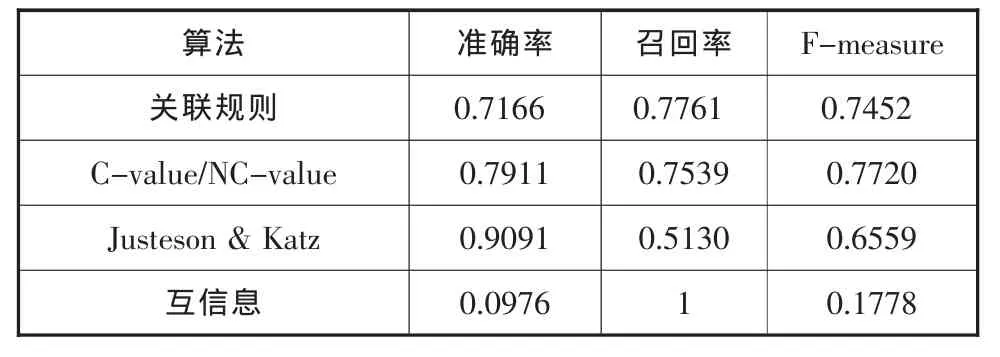
表8 算法抽取效果比较表
从表8中可以看出,Justeson&Katz算法的准确率要高于其他算法,C-value/NC-value算法和关联规则算法的准确率次之,互信息方法的准确率最低。而实验结果的召回率与准确率结果相反,Justeson&Katz算法的召回率最低,互信息方法的召回率达到了1。F-measure是综合评价准确率和召回率的指标,C-value/NC-value算法的F-measure值最高,其次为关联规则算法以及Justeson&Katz算法,互信息算法的F-measure值最低。综合来看,就1000条的数据量来讲,关联规则算法取得了不错的抽取效果,但还有一定的进步空间。
4 结语
本文讨论了基于关联规则的复杂术语抽取方法,从理论上看,关联规则的基本原理决定了它在充分解决“序”的条件下,可以很好的完成术语的识别和抽取问题。从实践上看,关联规则的方法的确可以正确抽取出术语,而且,通过与现有算法的比较,可以发现,关联规则在算法实现难度和占用资源方面具有非常明显的优势。而且,关联规则在术语抽取时没有学科和语言的依赖性,这一点,是基于规则的方法所不能比拟的。我们的下一步工作将进一步分析如何合理配置参数以及各种关联规则算法用于术语抽取时的特点,包括效率、效果和限制条件。
[1] Justeson J, Katz S.Technical Terminology: some Linguistic Properties and an Algorithm for Identification in Text[J].Natural Language Engineering,1995,1(1):9-27.
[2] Jacquemin C.Recycling Terms into a Partial Parser[C].Proceedings of NALP’94,1994:113-118.
[3] Dagan I, Church K.Termight: Identifying and Translating Technical Terminology[C].4th Conference on Applied Natural Language Processing,1994:34-40.
[4] Andy L.Automatic Recognition of Complex Terms:Problems and the TERMINO Solution [J].In Terminolo-gy: Applications in Interdisciplinary Communication,1994,1(1):147-170.
[5] Arppe A.Term Extraction from Unrestricted Text[C].10th Nordic Conference of Computational Linguistics,1995.
[6] Chengxiang Z, Xiang T, Frayling MN.Evaluation of Syntactic Phrase Index CLARIT[C].Proceedings of TREC-5,1996.
[7] Ulrich H, Jauss S, Katja K.Term Extration with Standard Tools for Corpus Exploration:Experience from German[C].4th International Congress on Terminology and Knowledge Engieering,1996:139-150.
[8] Bourigault D, Mullier GI, Gros C.Lexter, A Natural Language Processing Tool for Terminology Extraction[C].7th EUEALEX International Congress on Lexicography,1996:771-779.
[9] Naulleau E.Profile-guided Terminology Extraction[C].the TKE’99: Terminology and Knowledge Engineering,1999:222-240.
[10] Herman E, Chomsky N.Term Extraction [EB/OL].[2014-07-02].http://fivefilters.org/term-extraction/.
[11] Sclano F, Velardi P.Termextractor: a web application to learnthe shared terminology of emergentweb communities[C].the 3rd International Coference on Interoperability for Enterprise Software and Applications,2007.
[12] Church K,Gale W.Inverse Document Frequency (IDF):A Measure of Deviations from Poisson [C].the 3rd Workshop on Very Large Corpora.Cambridge,Massachusetts, USA,1995:121-130.
[13] Frantzi K, Ananiadou S.Extracting Nested Collocations[C].Proceedings of the 16thinternational conference on computational linguistics,Coling 96,1996:41-46.
[14] Frantzi K, Ananiadou S, Mima H.Automatic recognition of multi-word terms:the C-value/NC-value method [J].InternationJournalonDigitalLibraries,2000,3(2):115-130.
[15] 辛欣,李涓子.文本信息抽取平台的设计与实现——基于机器学习[A].第七届中文信息处理国际会议论文集[C].中国中文信息学会,2007:7.
[16] 韩家炜.数据挖掘概念与技术[M].北京:机械工业出版社,2013.
[17] 陈定权,朱维凤.关联规则与图书馆书目推荐[J].情报理论与实践,2009,(6):81-84.
[18] 徐晓楠,张晓珺,张伟等.北京市火灾关联规则分析[J].安全与环境学报,2010,(3):151-156.
[19] 罗五明,韩平阳.车辆事故关联规则的提取[J].交通与计算机,2003,(2):17-19.
[20] 任长伟,尚艳英,曹彦荣.基于GIS与空间关联规则数据挖掘在森林病虫害预测中的应用初探[A].中国地理信息系统协会.第四届海峡两岸GIS发展研讨会暨中国GIS协会第十届年会论文集[C],2006:6.
[21] 林炜烁,纪立金,高思华.基于关联规则的肺肠合病医案用药规律探索[J].世界中医药,2014,(4):401-404.
[22] Zhang Z, Iria J, Brewster C, Ciravegna F.Java Automatic Term Extraction toolkit[EB/OL].[2017-07-02].https://jatetoolkit.googlecode.com/svn/trunk/2.0Alpha.
