基于GIS的汉语历史方言地理研究
2014-12-02张义
张 义
(1.华中科技大学中国语言研究所,湖北武汉430074;2.淮北师范大学文学院,安徽淮北235000)
一、引 言
方言地图是显示语言特征空间分布的专题性地图,是方言地理学的一个极具解释力的工具。它可以将方言调查数据以直观的方式呈现出来,有利于研究者以全局的眼光,综合考量多因素交互影响下的语言变异机制。早期的方言地图先后采用了方言定点符号图、方言范围图、方言同言线图、方言接近率图以及方言动线图等不同绘制形式。随着方言研究的深入,我们越来越发现传统方言地图主要局限于原始方言数据的可视化呈现,而在对不断累积的大量不同时段、不同格式的方言数据的存储、表达、查询以及非语言因素对语言变异影响的刻画等方面存在诸多不足。这需要我们寻求新的途径去解决。GIS技术的兴起,使我们对空间信息的采集、显示、存储、转换、分析、表达的方式发生了根本性的变化,为上述难题的解决提供了一个新的思路。郑锦全[1]、张 维 佳[2-3]、 潘 悟 云[4]、 沈 力[5]、 胡迪[6]等在这方面都做过很多有益的探索,也取得了不少成果。总的来看,这些研究基本上是基于对现代方言共时分布的描写和呈现,这可能与静态GIS系统的成熟性以及现代方言数据采集的便利性有关。然而,我们知道,语言的共时分布是历时演化进程长期积累的产物,很多共时层面的语言现象都需要从历时层面寻求解释。因此,如能在现有共时方言GIS中增加历史方言数据,系统的解释力会大大增强。汉语历史方言GIS的开发正是在这一背景下提出的。
研究以谭其骧《中国历史地图集》为底图,制作中国历史时态GIS数据库,同时建立词汇、语音、语法三方面的历史方言数据库,建立可能影响语言变异的其他非语言因素数据库,并将它们整合起来,构建汉语历史方言地理信息系统。通过这个系统,可以横向了解某一特定时期汉语方言的共时分布情况,也可以动态地查询方言特征历时的演变与分布,还可以结合一些非语言因素,如人口迁移、自然地理等,解释汉语方言变异原因。这些功能的实现,可以让研究者将汉语置于一个广阔的时空背景中,综合考察中国历史时空坐标中的汉语方言演变轨迹,对汉语方言及汉语史研究都有很大的帮助。
二、系统开发
(一)系统规划
这个系统的各类数据性质很不相同,数据的格式及其丰富程度也都不一致,不同类型数据间的关系十分复杂。因此,我们有必要对数据模块、功能模块间的逻辑关系进行全面梳理,对所有数据及其关系进行分析、评价,并建立统一的数据字典。根据数据性质,将所有数据分为三类:时空数据、方言属性数据、非语言因素数据,每个数据模块下面都还可以分出很多子模块(见图1),整个系统的实现是通过一系列功能模块来实现的。根据数据性质以及使用需求,确定了系统功能构成 (见图2)。

(二)数据模块设计
1.时空数据模块。中国历史时空GIS数据库以谭其骧《中国历史地图集》为设计底图。该图集包含约70 000个精确到县的地名,并以索引形式标注古今地名对照及其坐标位置。时空数据模块设计关键的问题就是时空数据模型的建立,而其中最主要的问题就是对时间、地名以及空间范围的处理。
与时间有关的数据主要有方言数据和空间数据。从方言数据上看,从现存第一部自觉的方言调查著作——扬雄《方言》到现代,时间跨度达2 000多年,然而目前能够掌握的历史方言材料在时间上的分布是很不均匀的。另外,语言作为一种交际工具,在相当长一段时间里是比较稳固的,明显的变异一般要以百年计。从空间数据上看,有两个方面,一个是历代行政区沿革,一个是方言的空间分布,这两个方面的空间数据在时间上的分布也是很不均匀的。因此,时空数据模型的时间粒度的选择应该考虑到行政区沿革数据以及方言属性数据生存期较长这个特点。
地名以及行政区范围是另一个问题。虽然历代行政区边界及其名称变化较大,但是从全国范围来看,还是有一个相对稳定的传统边界和相对较长的生存期。另外,目前可获得的汉语历史方言数据大多数没有精确到县级程度,太细致的空间数据只会造成冗余。应该根据现有方言数据时空分布情况对空间粒度的选择做一些调整,这样也可以减少部分工作量,同时提高系统效率。
此外,与方言分布相关的地名体系较为复杂。如扬雄《方言》中的地名,就既有行政区划地名 (如五国之交、三辅),又有自然地理地名 (如江沔、沅湘、自关而东);既有先秦地名(如赵、魏、朝鲜),又有汉代地名 (陇、丹阳);既有代表广大地域的地名 (如自关而西,自关而东),又有表示个别地域的地名 (如秦晋之故都)。有必要对获取到的这些不同类型、时间的地名体系进行转换和统一,变成时空数据库中可接受的时空ID,这样才能保证空间数据和方言属性数据的有机结合。
基于上述考虑,决定采用一种相对简单的时空数据模型——基于快照序列的时空数据模型。这一模型的实质是将时间作为空间的一个属性附着在空间数据上,通过一定的算法将离散的时空数据在传统静态数据库中关联起来。虽然这一模型在从技术上看似乎有点过时,但其实现简单便捷,对于像这样时间粒度较大,属性数据量不太大的系统,还是有较好表现的。根据中国历史时空数据的特点,设计了如下数据结构 (见图3)。
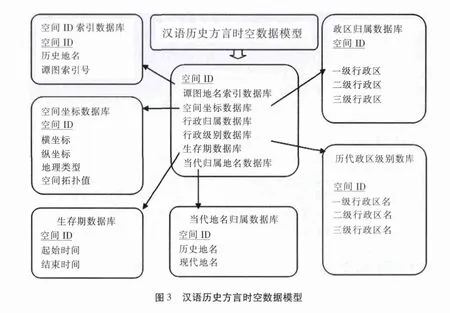
2.历史方言数据模块。根据语言系统内部划分,将历史方言数据模块分为词汇、语音和语法子模块,每个子模块下面还可以析出若干从模块。打算以词汇模块为纲,建立历史方言属性数据库。之所以以词汇为纲,主要出于两点考虑:一是因为方言的变异通常会直接体现在词汇系统中。从一个方言词语通行区域的变化中我们可以窥视到它所在的方言的历史演变轨迹。这里我们要重提并赋予吉耶龙“每一个词都有它自己的历史”的口号[7]另外一种意义——试图从每一个方言词的历史变迁中整理出它所处的方言的历史。二是在现有的三类历史方言数据中,词汇属性数据最为完整,格式化也最强,此外,词汇数据颗粒度更小,对方言区划的辨识度更强。
(1)词汇模块。词汇模块以扬雄《方言》为纲。它是中国历史上第一部、世界范围内最早的方言地理学著作,除了没有绘制方言地图外,它的做法基本上符合现代方言地理学研究的旨趣。[8]《方言》收集的材料比较充足 (约9 000余条),调查的地域也比较广泛。东起东齐海岱,西至秦陇凉州,北起燕赵,南至沅湘九嶷,东北至朝鲜冽水,西北至秦晋北鄙,东南至吴越东瓯,西南至梁益蜀汉,几乎囊括了汉代的全部版图,而且后世对它的注解或者以它为体例参照进行的方言调查也很多。据不完全统计,历代注解《方言》的文献至少有30来种,而以它为体例参照进行的方言调查的著作就更多了。这些文献往往都会将调查结果和《方言》进行比较,通过这些文献中方言词汇随时间变化的分布状况,我们可以方便地了解从杨雄时期到该文献著录时期汉语方言的历时演变轨迹。如从《方言》与郭璞注的比较中我们可以发现很多原来属于北方方言的词汇,到了晋代都成了“中国通语”“北方通语”“中国”了。这说明晋代北方各个方言之间的差别在逐渐变小,内部已经趋向一致 (这可能与汉末离乱和三国纷争时期北方人民经常的流徙播迁有关)。正如王国维所言:“读子云书 (扬雄《方言》),可知汉时方言;读景纯注 (晋·郭璞 《方言注》),并可知晋时方言。”[9]
词汇数据库的制作主要考虑三个变量:词汇、时间、通行区域。词汇数据共有9 000多条,时间数据相对少很多,而且在我们的时空数据模型中,时间是作为空间的一个属性,附着在空间数据上的。一般我们知道了一个方言词汇对应的空间ID,也就很容易判断它的存在时间了。空间数据也很多,谭图一共收录70 000多个历史地名。如何在尽可能地减少数据库字段的情况下,将方言词汇数据和它所属的时空ID整合起来是词汇数据库建立的关键问题。通过分析这三类数据及其相互之间的关系,我们发现,如果以时空ID作为数据库主键,那么一个ID对应的方言词汇可能有几百个,但是如果以方言词作为主键的话,一个方言词对应的时空ID少的可能只有一个,多的也不过十来个。
(2)语音模块。语音差异是方言差异最显著的表现。古音学家陈第就谈到“一郡之内,声有不同,系乎地者也;百年之中,语有递转,系乎时者也。”[10]历代关于方言语音记载的文献比较丰富,我们可以利用的方音材料主要包括以下几类:1)历代韵书。韵书具有收字广、材料丰富集中的优点,一部韵书基本上可以完整地揭示某一地区语音系统。现存的韵书中基本上都含有方音成分,或者都具有一定的方言基础。此外,还有不少地方韵书。如福州的《戚林八音》、泉州的《汇音妙悟》、潮汕的《潮汕十五音》、广州的《千字同音》、徐州一带的《十三韵》、河北一带的《五方元音》、山东一带的《十五音》等。[11]这些韵书都以方音为依据,虽然有的审音上不够精确,但大体上还是符合当时的方音实际的。2)地方戏曲。地方戏是古代方言的“活化石”,据统计,中国的地方戏有360多种,[12]它们保留着古代方音的真实面貌。3)地方志或者方言志。在我国数千种地方志中,有相当一部分载有各地的方音材料。这些材料或独立自成《方言志》,或附在《风俗志》、 《地理志》等后面。据日本学者波多野太郎《中国方志所录方言汇编》的材料统计[13],仅江苏、浙江、广东、福建四省各历史时期包含方言材料的方志数量就达115种。这个汇编还是很不完全的,实际数量要超出这个数量不少,就全国而言就更多了。这些地方志除了记录方言的语音面貌外,还收录训释了很多方言词汇,这些材料都可以丰富词汇模块的数据。4)散见在历代文献中具有方音的诗文以及切语。
语音数据相对词汇数据而言有一定的特殊性。每一个单独的词汇都可以成为一个有效的识别特征,有一定的地域分布属性,而语音数据不具有这样的特点。每个不同的方言区或者同一个方言区不同的历史时段可能都存在某类语音特征,只是这些特征在组合成词的层面上可能存在差异,方言语音的差异要落实到词汇层面,因此,语音数据必须通过词汇层面才能和一定的时空数据发生联系。那么到底该选择哪些词作为语音数据的关联项呢?笔者认为:一方面要顾及到汉语所有可能的音素,另一方面,作为关联项的词一定要在所有方言里面都能找到。基于这种考虑,选择《方言调查字表》作为语音的词汇关联项。《方言调查字表》是以《切韵》音系为框架编排的。高本汉就认为“现代汉语方言,除了闽语之外都从《切韵》语言演化而来。”[14]通过考察《方言调查字表》中的词条在每一个方言中的语音情况,基本上可以确定该方言的语音面貌。此外,《方言调查字表》在方言调查中广泛使用,这使得我们的历史方音数据可以非常方便地与现代方言调查数据在格式上兼容,便于历时数据与现代共时数据的比较。
随着历史语音研究的深入,上述方音材料中相当一部分的音值已经被构拟出来了,我们可以非常方便地运用这些材料。如果条件成熟了,语音数据库还可以进一步扩展,比如给出一段文字材料,我们就可以利用不同的历史方言将它的读音标注出来,甚至可以通过语音合成模拟历史方言语音。如台湾“中央研究院”开发的汉语方言地理资讯系统就《荔镜记》、《陈三五娘》以及一些台湾谚语用22种汉语方音对文字材料进行标注。
(3)语法模块。汉语方言差异在语法方面相对词汇、语音方面要小些,但是将上古汉语和现代汉语、普通话和方言比照,我们发现语法差异还是比较大的,而且这些语法差异还会随着方言接触相互影响,发生变异。汉语历史方言地理信息系统应该收录一些典型的方言语法特征,如修饰成分位置、重叠式、状语和谓语的位置关系、疑问句格式等。此外,汉语方言在词法和句法上面都有差异,我们的历史方言语法数据库应该包括词法特征和句法特征库。
3.非语言因素方面。人口迁移、民族融合、自然地理、行政区划沿革等因素都可能会对语言变异产生影响,但这些因素都是离散性的,必须单独建库。考虑到这些因素对方言变异的影响强弱不同以及目前能够获得的相关资料丰富程度不一,决定先只建立人口迁移数据库。因为人口迁移是汉语方言形成的一个重要原因,一部中国方言史从某种程度上可以说是移民史在语言上面的投影。
移民数据主要以葛剑雄等著的《中国移民史》为依据,该书是迄今国内外最完整、最系统的中国移民史专著。它论述了自先秦至20世纪40年代,发生在中国境内的移民,指出了每次迁移的对象、时间、方向、迁出地、定居过程及产生的影响,并且以大事年表形式列出自公元前21世纪至公元1949年间可考的主要移民事件。
中国历史上的移民可能会出现如下一些比较复杂的情况:一个地方移民会分散到不同的区域,一个地区接受的移民也可能来自不同的地区,一个地方可能会在不同的时间接受来自不同地方的移民,一个地方移民移出后可能又有来自其他地方的移民。这些不同的移民类型对汉语方言的形成产生的影响是不同的。为了便于研究移民对方言的影响,在移民数据库中以每一次移民事件作为唯一的ID,标明移出地ID、移出地方言类型、移出时间、移出人数、移入地ID、移入地方言类型、移入时间、移入地人数,并附上相关移民事件的文献材料,便于研究者考证。
三、难点及对策
(一)历史时空数据
行政区的废置、易名、边界的变动以及因此带来的一连串的空间拓扑关系的复杂变化,给研究带来了很大的麻烦。主要表现在如下两点:第一,每次行政区划废置后,随即产生了一套新的历史地名体系,而且新地名与旧地名所代表的区域边界并不一致,存在着很多复杂的关系。这样考察方言的历史变化在空间上的投影时,很难找到一个地名参照。第二,中国的方言区划与行政区划有着很强的一致性,由于长期的、封闭的聚居,语言习惯相互濡染,同一行政区域内语言使用趋于一致,一旦行政归属变换了,那么当地的权威土语也会随之变换。而行政区划的复杂变动的内在联系如果不通过一种有效的模式加以表现,那么方言的历史变迁也将很难真正揭示出来。
通过对中国历史政区沿革的分析,我们发现每一个变化事件都有一定的规律性:一个新的行政区格局 (区间的空间拓扑关系,这里称子拓扑)的产生,总是伴随着一个旧区格局 (这里称父拓扑)的消亡,即父子拓扑关系具有空间上的相交性和时间上的相接性。那么中国历史上的每一个行政区都可以看作是在一个生存期中的空间存在,它具有唯一性。利用这种唯一性,便可以很方便地建立同一时间段内不同空间实体间的属性关联,也可以比较父子空间拓扑之间的复杂继承关系。
贝明远先生将中国历代行政区沿革的空间拓扑变化形式归纳为存在、替代、设置、废除、关闭、毁灭、易名、重组、擢升、降级、合并新名、合并带名、分裂新名、分裂带名、复置、边界变化、迁徙等17种,[15]这些形式都可以由分、合、继承等三种基本形式孽乳而来。为了研究方便,将其简化为三种形式。这三种形式表现在行政区沿革的拓扑关系上,具有空间上的相交性和时间上的相接性。我们给谭图中每一个历史地名一个唯一的ID(即使两个地名空间上存在着空间上的继承关系),每个ID都对应着空间拓扑体中的具体图元,记录着该地名在其生命周期内的空间位置和属性数据。我们可以通过ID定位该地名在空间的位置,也可以通过其空间位置检索到与之相关的属性数据。同一时间段的地名ID可以通过级层关系 (行政隶属关系)描述其静态拓扑关系,不同时间段的ID可以通过静态快照的比对,确定其继承关系。
(二)方言属性数据
相比现代汉语方言地理信息系统来说,汉语历史方言地理信息系统的开发难度以及工作量更大。这是因为现代汉语方言地理信息系统所需的方言数据都是现存的活的数据,可以通过田野调查,较为准确而丰富地获得,而汉语历史方言地理信息系统记载的是已经过去的、死的语言,方言数据时间、空间上的分布很不均衡,不少数据需要从现存的历史文献零星的记载中,通过比较、分析、鉴别、构拟等方法来获取。而且越是年代久远,能够获得的资料越是稀少,而且可靠性越差。另外,这方面材料的获取在很大程度上依赖对汉语史研究和认识的程度,而这些工作的进展在很大程度上来说不仅仅是时间的问题。汉语历史方言地理信息系统不能等到汉语史研究充分了再去做。目前,比较可行的办法是先选择能够获取到的方言数据比较充分的汉语发展阶段,搭建一个开放的汉语历史方言的时空框架。对于尚未发现材料的时间段以及区域,可以预留数据库接口,等日后有了新的数据再做。经过一段时间的研究讨论,不断修正完善,最后形成一个比较符合汉语历史方言面貌的历史方言信息系统。
四、余 论
根据前文论述,将汉语历史方言地理信息系统定位为开发性的汉语历史方言时空数据框架。基于这个定位,在系统设计和构造时,考虑到了相关的标准和规范,同时还充分地考虑到了系统的可扩展性、可移植性,在设计时尽可能地使每个不同类型的数据独立作为一个子模块。这样,系统日后升级数据或者二次开发时,不必对整个数据模块进行大的修改。升级主要可能在两个方面:第一,与专业的基础地理数据库共享。目前时空数据最大的问题就是比例尺单一,对方言数据分布的空间粒度较密集的区域处理不够理想。复旦大学正在开展的“中国历史地理信息系统”是国家历史地理基础数据平台,笔者的系统将来可以共享这个历史地理数据,以提高时空信息的精准度。第二,与正在开发的现代汉语方言地理信息系统以及一系列不同类型的方言数据库整合。这方面主要有麦耘先生的“汉语方言词汇数据库”、周磊先生的“现代汉语方言自然口语语料库”、“汉语方言语法类型比较研究与方言语法语料库”、“中国方志方言资料库”,潘悟云先生的“汉语方言地理信息系统”、“21世纪中国语言与方言数据库”等。研究者可以根据自己的研究需要,将已有的方言数据,转换为合适的格式,导入到系统中,进行二次开发。
[1]郑锦全.语言与资讯:厘清台湾地名“厝”、“屋”[M] //语言、文学与资讯.新竹:清华大学出版社,2004:1-24.
[2]张维佳.方言研究与方言视图的数字化 [M] //西北方言与民俗研究论丛.北京:中国社会科学出版社,2004:89.
[3]张维佳.建立汉语方言地理底图和坐标编号系统的设想[J].语言科学,2006(3):72-79.
[4]潘悟云.汉语方言地理信息系统平台建设课题开题[EB/OL].(2010-03-19)[2013-10-08].http://www.cass.net.cn/file/20100401264143.html.
[5]沈力,冯良珍,中野尚美.用GIS手段解读混合方言的成因——以灵石高地为例[J].语言教学与研究,2011(5):30-39.
[6]胡迪.我国方言地理学发展演变及问题分析[J].南京师范大学学报:自然科学版,2012(3):106-110.
[7] GILLIERON.Each Word Has a History of its Own[M] //From Particular to General Linguistics:SelectedEssays,1965-1978.Amsterdam:John Benjamins Publishing Company,1983:217.
[8]李智明.中国古代语言学史稿[M].贵阳:贵州教育出版社,1993:67.
[9]王国维.观堂集林[M].石家庄:河北教育出版社,2003:115-119.
[10]陈第.毛诗古音考附读诗拙言一卷[M].康瑞琮,点校.北京:中华书局,1988:201-212.
[11]许宝华.许宝华汉语研究文集[M].北京:中华书局,2006:125.
[12]戏剧报资料室.我国有多少剧种?[J].中国戏剧,1959(18):54-55.
[13]波多野太郎.中国方志所录方言汇编 (9册)[M] //横滨市立大学纪要.横滨:横滨市立大学出版社,1963—1972.
[14] KARLGREN,BERNHARD.Compendium of Phonetics in Ancient& Archaic Chinese[J].Bulletin of the Museum of Far Eastern Antiquities,1954(26):211-367.
[15]贝明远,李晓杰.CHGIS Time-Continuous Data Model,Minimum Required Tables[EB/OL].(2002-01-08)[2013-10-08].http://www.people.fas.harva rd.edu/~chgis/work/design/datamodel_HZ/.
