跨语言查询扩展优化
2014-11-30李书琴李伟男李新乐
魏 露,李书琴,李伟男,李新乐
(西北农林科技大学 信息工程学院,陕西 杨凌712100)
0 引 言
跨语言查询扩展主要是为了解决词不匹配问题,在初始查询词的基础上,加入若干相关词,使文档相关性信息更全面[1,2]。文献 [3,4]使用基于潜在语义分析的跨语言查询扩展方法进行检索,减轻了翻译的歧义性。但是,该方法还存在一定缺陷。首先,在建立双语空间时,用奇异值分解法对矩阵进行分解,得到的矩阵元素存在负数,致使一些有用的语义信息丢失,降低了检索精度。其次,降维时根据经验来选取1个维度值d,d值的选取对检索结果有重要影响,若d值偏小,则得到的双语空间丢失语义信息;若d值偏大,则计算量加大,且会出现过拟合现象[5]。最后,用跨语言扩展避免扩展词翻译带来的歧义问题时,使用k-means进行聚类,k-means算法虽然有简单快速等优点,但是它对于噪声和孤立点是敏感的,少量该类型数据就会对平均值产生极大影响,从而降低检索精度。
本文跨语言查询扩展研究将对以上不足进行改进。首先,采用奇异值分解 (singular value decomposition,SVD)与非负矩阵分解 (non-negative matrix factorization,NMF)[6]相结合的方法对矩阵进行分解,使得到的双语空间不含负数,避免了因为矩阵中存在负数而导致语义的信息丢失。其次,提出择优模型,建立多个d值模型,再选取最优的模型进行计算,以此降低因d值过大或过小而导致的信息丢失和过拟合问题。最后,使用k-medoid进行聚类,避免聚类过程中出现孤立点和噪声,提高扩展文本集合的精度,进而提高检索精度。
1 择优模型
建立双语空间时,需要对最初的词条文本矩阵进行降维,通常降维因子d都是在100~300中选取单一值,导致语义丢失或过拟合问题。择优模型是指在100~300之间选取多个维度值d分别建模,给每个模型都赋予一个信任度AIC (akaike information criterion),AIC主要是用来计算总文档的相似度,选择相似度最大时的d作为降维的维度,采用择优模型可以弥补单一维度值的缺陷。AIC指多个不同维度模型与未知准确模型之间的距离[7]

式中:l——模型中的参数量,l=rd+l-d (d-l)/2,r——矩阵M的秩。lnL (Ud|M)——d维潜在语义模型的对数似然函数
lnL(Ud|M)=λ1+ … +λd-nlogZ(Ud|M) (2)式中:Ud——矩阵M进行SVD分解 (M=USVT)和NMF分解 (M=UV)后的矩阵U。λd——矩阵 M’M的前d个特征值,Z——分割函数
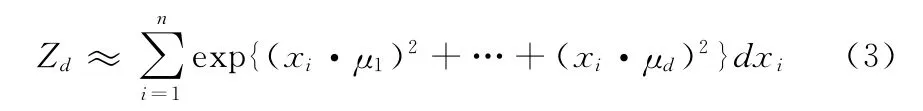
求相似度时,设A为包含多个不同d维模型的集合,然后根据A分别计算SVD和NMF分解以及2种方法结合时查询文档的相似度

式中:ωd——d维SVD矩阵分解模型的信任度,与AIC成反比,Ud、Sd和Vd——奇异值分解降维后的矩阵。

式中:ωd——d维NMF矩阵分解模型的信任度,Ud——非负矩阵分解降维后的矩阵

式中:ωd1和ωd2——d维SVD矩阵分解模型d维NMF矩阵分解模型的信任度。
2 跨语言查询扩展
跨语言查询扩展[8]整体流程可分为以下几个部分,本体 (ontology)扩展、跨语言扩展、翻译、权重计算以及检索。具体流程如图1所示。
2.1 ontology扩展
本文使用英文的 WordNet[9]和中文的同义词林[10]2种语义词典来构建查询词的扩展词,步骤如下:
步骤1 采用WordNet和同义词林作为本体扩展资源,使用protege本体构建工具构建一个简单本体库;

步骤2 在本体库中找到查询词ti,根据实体相关度计算公式计算各词与ti之间相关度[11],得到与ti相关的概念集Seti,计算Seti中的每个概念与ti之间的相似度,若相似度大于某一阈值 (此处取0.7),则把Setij加入到ti的候选扩展概念集中;
步骤3 重复步骤2至原始查询式S0= {t1t2…tm}中所有查询词的候选扩展概念集均被找到;
步骤4 用逻辑或把所有的查询词和它们的候选扩展概念集结合起来,利用FirteX2开源搜索引擎检索出初始结果;
步骤5 选出初始查询结果中的前N篇文档构成局部文档集P,利用局部共现分析法计算词语—概念对的共现度权值;
步骤6 对候选扩展词组进行筛选,把符合条件的扩展词作为qi的ontology扩展,并加入到初始查询式中。扩展后的查询式为
S1= {t1t2…tmtm+1,…tm1,m ≤m1≤2 m}
2.2 建立双语空间
由语料得到最初的中英词条文本矩阵M
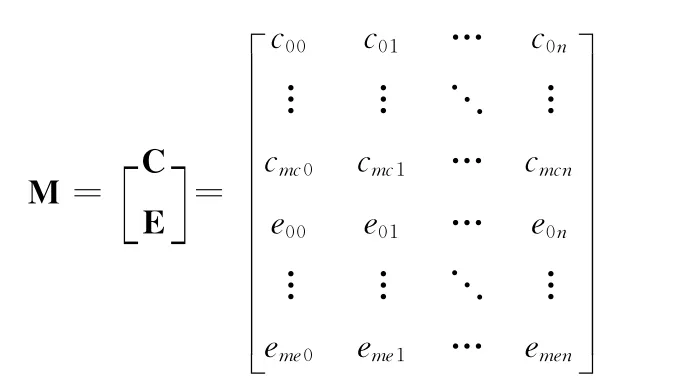
权值cij和eij结合使用对数词频法和熵方法
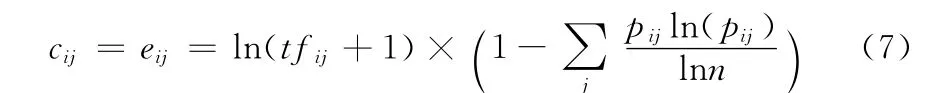
式中:tfij——词i在文档j中出现的频度,gfi——词i在整个文档中的出现频度,pij=tfij/gfi,n——总文档数。
结合SVD和NMF对M进行分解,采用择优模型对M进行建模,选取相似度最大时的d值,截取V的前d列,最终得到双语空间Vd。
2.3 跨语言扩展
跨语言扩展需要用聚类提高扩展精度,本文采用k-me-doid聚类算法,它属于划分方法,在存在孤立点的情况下,算法鲁棒性好[12]。
跨语言扩展是在ontology扩展的基础上,结合双语空间和k-medoid聚类来完成,具体步骤如下:
步骤1 将ontology扩展得到的查询式S1用fold-in方法构成d维文本向量qd;
步骤2 计算Vd中各文本与qd之间的相似度,找出前T个相似度最大的文本;
步骤3 对这T个文本进行k-medoid聚类,找出和qd距离最近的簇,将该簇中的所有文本形成双语查询扩展文本集合ET= {d1,d2,…,dt,t<T};
步骤4 对ET中的所有目标语言词汇用熵方法进行全局信息计算找出最大的me个词,记为
S'= {q1,q2,…,qme}
S’就是我们得到的跨语言查询扩展词组。
2.4 翻 译
S’已经是目标语言形式的查询式,所以只要对S1进行翻译,借助双语词典,使用双向翻译模型[13]对S1进行翻译,得到目标语种查询式

2.5 权重计算
在跨语言查询扩展中,原始查询S0最直接体现查询意图,为之分配最大权重。扩展词指的是与原查询相关的语词,它是原查询的语义上的补充和完善,其重要性比原查询语词稍低。为了体现这种思想,在进行查询扩展时,本文将原查询词的权重值置为2,扩展词的权重采用Rocchio方法,为0到1之间的值。
2.6 检 索
把跨语言扩展得到的查询词组S’加入到S2中,得到最终的目标语言查询式

3 实验设计和结果分析
实验所用的数据是从中国知网等数据库中随机抽取的1000篇农业专利相关论文中的中英文摘要,将这些信息建立成双语空间,用于查询、翻译和扩展。
评测指标MAP指查询集中每个查询准确率的算术平均值,辅助评测指标P@X指某个查询S检索出前X篇文档的准确率。
本文共设计5个实验 (NMF,C-B,NMFC-B,K-MD,INTEG)和一个对比实验SVD。SVD采用最传统的基于潜在语义分析方法进行跨语言查询扩展;NMF降维时结合使用SVD矩阵分解与NMF矩阵分解;C-B使用择优模型计算5个模型 (d=100,d=150,d=200,d=250,d=300)的相似度,并且选取相似度最大时的d值作为降维的维度;NMFC-B使用了C-B的方法,同样建立5个模型 (d=100,d=150,d=200,d=250,d=300),但同时采用了NMF非负矩阵分解的方法。K-MD和SVD的区别在于,它在跨语言扩展时用k-medoid聚类代替k-means聚类提高聚合精度;INTEG结合NMFC-B和K-MD方法。实验结果见表1、表2。

表1 英文检索中文准确率

表2 中文检索英文准确率
在召回不同条记录时,使用不同方法对应的准确率情况见表1、表2,其随召回条数变化趋势如图2、图3所示。
实验结果表明,使用 NMF、C-B、NMFC-B、K-MD、INTEG均能提高跨语言查询扩展精度,INTEG效果最佳,下面具体分析其原因。
实验SVD采用传统基于潜在语义分析的查询扩展模型,奇异值分解时存在负数,造成信息表示不全面;d值选取单一,不能使所有查询都最优,d值过大会导致计算量大,从而出现过拟合现象,d值过小则丢失很多有用的信息;使用k-means聚类,产生噪声和孤立点。在多重因素的影响下,检索精度降低。
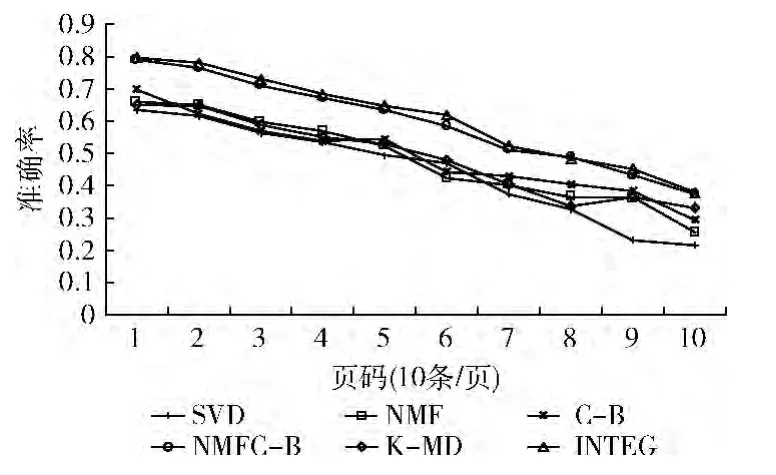
图2 英文检索中文召回准确率曲线

图3 中文检索英文召回准确率曲线
实验C-B中,择优模型选取不同的d值,建立多个模型,允许每个模型都对相关文档的相似度产生影响,给每个模型都赋予一个信任度进而计算整体文档相似度,它避免了信息丢失和过拟合问题,降低了单一模型的风险,检索精度自然也得到了提升。
实验NMFC-B运用模型择优的思想,通过每个模型的信任度将2种矩阵分解模型相结合,综合考虑2种矩阵分解方法的结果。由于NMF分解后的矩阵不存在负值,语义结构向量表示的物理意义明确,不会丢失语义信息。因此,将2种矩阵分解模型结合起来后,能较好地弥补SVD矩阵分解模型存在的语义结构向量表示受负值影响所造成的误差。
实验K-MD不用k-means算法进行聚类,而采用k-medoid对文本进行聚类,这种方法避免了SVD中存在的噪声和孤立点问题,提高了检索精度。
实验INTEG结合了以上所有方法的优点,既避免了信息丢失和过拟合,又消除了噪声和孤立点,因此精度最高。
4 结束语
本文使用潜在语义跨语言查询扩展方法对农业专利进行扩展查询,结合NMF和SVD矩阵分解方法使获得的双语空间不含负数,极大削弱了存在负值时语义表示不全面带来的负面影响;加入择优模型,消除了信息不全面与过拟合现象;使用k-medoid聚类对文本进行聚类,消除了噪声和孤立点。实验结果表明,该改进方法能明显提高检索性能。
[1]QU Guozhong.Query expansion technology research [D].Wuhan:Huazhong Normal University:Computer Software and Theory,2007(in Chinese).[瞿国忠.查询扩展技术研究 [D].武汉:华中师范大学:计算机软件与理论,2007.]
[2]LI Weijiang,ZHAO Tiejun,WANG Xiangang.A SMT-based approach for query expension in information retrieval [J].Journal of Electronics & Information Technology,2008,30(3):725-729 (in Chinese).[李卫疆,赵铁军,王宪刚.基于统计机器翻译模型的查询扩展 [J].电子与信息学报,2008,30 (3):725-729.]
[3]WANG Yang.The intelligent search technology based on latent semantic analysis [D].Heilongjiang:Harbin Engineering University:School of Computer Science and Technology,2010(in Chinese).[王洋.基于潜在语义分析的智能搜索技术研究[D].黑龙江:哈尔滨工程大学:计算机科学与技术学院,2010.]
[4]BI Jianting,SU Yidan.Expansion method for languagescrossed query based on latent semantic analysis [J].Computer Engineering,2009,35 (10):59-53 (in Chinese).[闭剑婷,苏一丹.基于潜在语义分析的跨语言查询扩展方法 [J].计算机工程,2009,35 (10):59-53.]
[5]NING Jian,LIN Hongfei.Cross-language information retrieval based on improved latent semantic indexing [J].Journal of Chinese Information Processing,2010,24 (3):105-111 (in Chinese).[宁健,林鸿飞.基于改进潜在语义分析的跨语言检索 [J].中文信息学报,2010,24 (3):105-111.]
[6]LI Ersen,ZHANG Baoming,YANG Na,et al.Discussion of the NMF’s application for hyperspectral imagery unmixing[J].Bulletin of Surveying and Mapping,2011,57 (3):7-10(in Chinese).[李二森,张保明,杨娜,等.非负矩阵分解在高光谱图像解混中的应用探讨 [J].测绘通报,2011,57(3):7-10.]
[7]JIANG Hao,TONG Shenjia,LI Gang,et al.The simulation of wind speed time series by the AIC [J].Technology & Economy in Areas of Communications,2008,47 (3):10-11(in Chinese).[姜浩,童申家,李纲,等.基于AIC准则的脉动风速时程模拟 [J].交通科技与经济,2008,47 (3):10-11.]
[8]GUO Wen,CHEN Yidong,ZHAO Xin.Query expansion in cross-language information retrieval[J].The Mind and Calculation,2009,3 (1):1-8 (in Chinese).[郭文,陈毅东,赵欣.跨语言信息检索中的查询扩展 [J].心智与计算,2009,3 (1):1-8.]
[9]ZHAO Tianzhong,MIAO Zhuang,ZHANG Yafei,et al.Reusing WordNet for building domain ontology [J].Journal of System Simulation,2007,19 (19):4583-4586 (in Chinese).[赵天忠,苗壮,张亚非,等.基于WordNet重用的领域本体构建方法 [J].系统仿真学报,2007,19 (19):4583-4586.]
[10]TIAN Jiule,ZHAO Wei.Words similarity algorithm based on tongyici cilinin semantic Web adaptive learning system [J].Journal of Jilin University (Information Science Edition),2010,28 (6):602-608 (in Chinese).[田久乐,赵蔚.基于同义词词林的词语相似度计算方法 [J].吉林大学学报(信息科学版),2010,28 (6):602-608.]
[11]WANG Xuyang,XIAO Bo.Query expansion method based on ontology and local contextual analysis [J].Computer En-gineering,2012,38 (7):57-59 (in Chinese).[王旭阳,萧波.基于本体和局部上下文分析的查询扩展 [J].计算机工程,2012,38 (7):57-59.]
[12]SUN Sheng,WANG Yuanzhen.Kernel-based adaptive K-medoid clustering [J].Computer Engineering and Design,2009,30 (3):674-675 (in Chinese).[孙胜,王元珍.基于核的自适应 K-medoid聚类 [J].计算机工程与设计,2009,30 (3):674-675.]
[13]CHEN Qin.Cross language information retrieval establishment of bilingual dictionaries and translation method [J].Computer Applications and Software,2010,27 (7):107-109 (in Chinese).[陈琴.跨语言信息检索中双语词典的建立和翻译方法 [J].计算机应用与软件,2010,27 (7):107-109.]
