二进制代码级的密码算法循环特征识别
2014-11-30李继中蒋烈辉
李继中,蒋烈辉,舒 辉
(1.信息工程大学,河南 郑州450002;2.数学工程与先进计算国家重点实验室,河南 郑州450002)
0 引 言
二进制代码中的密码算法技术主要分为静态识别和动态识别2种[1,2],静态识别主要采用特征字匹配[3]和基于指令统计属性[4]的筛选,具有识别效率高、误报率较高的特点;动态识别是在对目标代码执行指令监控记录的基础上,针对指令序列采用累加百分比[5]进行密码函数大致位置定位,针对指令中的内存数据和寄存器数据进行密码算法动态特征字识别[6],由于动态记录信息庞大,造成识别效率不高,但识别准确性较高。
文献 [7,8]中指出循环是密码函数实现代码中的重要特征之一,识别代码中的循环特征对于密码函数的筛选与定位具有重要作用。本文详细分析了密码算法循环特征产生机理,分别针对控制循环结构和指令序列循环提出了识别算法。
1 密码算法循环模式分析
1.1 密码算法循环特征
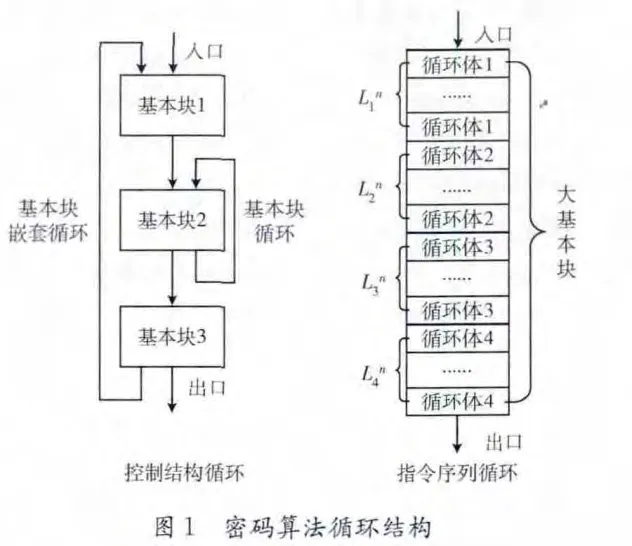
密码算法在设计中,通常会采用循环模式实现加解密功能。根据循环存在的粒度不同,密码算法循环特征可分为2种:密码函数内部循环;加解密分组循环。在程序执行流程中,密码函数内部循环包含于加解密分组循环内部。
(1)密码函数内部循环
密码函数内部循环是指在密码函数在设计时,使用相同或类似的功能函数对数据进行反复操作,在Hash函数和分组密码中体现的比较明显。逻辑表达式是构造Hash函数的重要组件,代码实现时会反复循环运用该类表达式,为了提高执行效率,Hash函数代码实现时通常进行循环展开;分组算法设计时通常采用Feistel结构和Spn结构,该结构以函数形式存在于代码中,该函数中包括若干轮的循环 (循环次数与密钥长度相关);公钥算法通常在二进制代码中采用包含乘、除指令的循环实现模幂运算。
(2)加解密分组循环
分组循环是指在数据加解密时,把输入数据按照特定的分组长度 (128bits,256bits等)进行数据填充与切割,并针对切割后的各个分组依次采用密码函数进行加解密处理,分组间的关系取决于使用的加密模式 (CBC、ECB、CFB等)。
1.2 密码算法循环结构
循环是密码算法代码实现时常用的结构形式,循环体中包括密码函数的核心操作部分 (如逻辑表达式、算术表达式、Feistel结构函数等),按照循环结构不同,密码算法主要包括控制结构循环和指令序列循环。
在二进制代码反汇编结果中,基本块是单入口、单出口的连续指令序列,基本块循环 (基本块自身所构成的循环)和基本块嵌套循环是典型的控制循环模式,常常出现在分组密码、公钥密码和流密码的实现代码中;为了提高执行效率,Hash函数通常采用加密主函数循环展开的方式,构造成为一个大基本块,简单循环模式则蕴藏在其中;此外,在对二进制目标代码进行动态分析过程中,通常对记录下的执行指令序列进行分析,抽取出基本块循环和嵌套循环等密码算法常用的循环模式。密码算法常用的两种循环结构如图1所示,其中循环体是指构成循环的最小连续指令序列;因此,面向二进制代码的密码算法循环特征识别主要分为控制结构循环识别和指令序列循环识别。
2 基于回向边遍历的控制结构循环识别
在二进制代码反汇编结果中,采用四元组G=(START,END,N,E)对函数中基本块之间的控制关系进行描述,其中N是结点 (基本块)集合,E是边集合,START∈N是一个没有入向边的开始结点 (函数入口),END∈N是一个没有出向边的结束结点 (函数出口)。
传统的控制流图循环检测方法根据已识别的必经节点对回向边进行循环判别,在控制节点判定时需要遍历所有的有效路径,效率比较低;密码函数控制结构中的回向边比较少,首先获取回向边的源节点和目的节点,而后通过目的节点和源节点之间是否存在有效路径来判别循环结构,可以有效提高检测效率;此外,基本块循环并且基本块内部使用逻辑运算或算术运算是密码函数的重要特征,针对该特征可进行疑似密码基本块筛选。
针对X86指令集,在目标二进制代码反汇编结果中,跳转指令决定控制流图的结构,根据跳转目的地址的方向不同,反汇编结果控制流图中的有向边可划分为:回向边、前向边和顺序边,有向边类型如图2所示,假设跳转指令地址和目的地址分别为SrcAddr,DstAddr,判别条件如下:①回向边:SrcAddr>DstAddr;②前向边:SrcAddr<DstAddr & & !seq (SrcAddr,DstAddr);③ 连续边:seq (SrcAddr,DstAddr)。
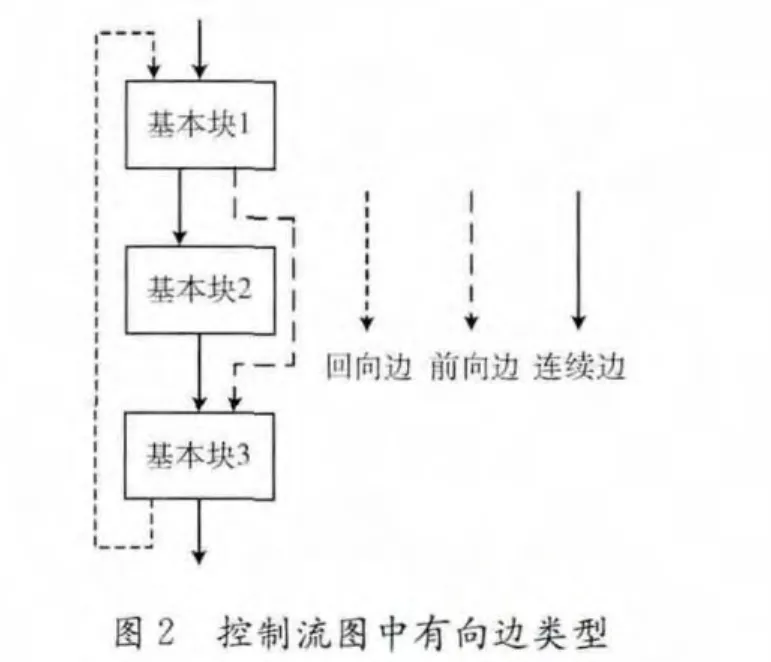
其中函数seq(SrcAddr,DstAddr)判断2个地址是否连续,若连续则返回1,否则返回0。
在反汇编结果控制流图的有向边中,回向边决定着是否存在着循环,基于控制结构的循环检测算法主要步骤如下:
步骤1 获取函数内部基本块信息bblInfo<bblBeginAddr,bblEndAddr>,有向边集合Edges<edgeSrc,edgeDst>;
步骤2 遍历基本块的出边集合,若跳转指令的目的地址edgeDst小于当前指令地址edgeSrc,则把该边加入到回向边集合BackEdges<>中;若基本块出边地址edgeDst等于bblBeginAddr,则识别出基本块循环,并把该基本块信息添加到bblLoop<>结构中;
步骤3 遍历回向边集合BackEdges<>,采用DFS(深度优先搜索)算法判别跳转指令的目的地址所在基本块与跳转指令所在基本块之间是否存在路径;
步骤4 输出基本块循环和普通循环的检测结果。
相比于传统的基于必经节点识别的循环检测方法,针对目标二进制代码反汇编结果所设计的基于回向边遍历和DFS路径发现的循环检测算法,省略了控制节点识别步骤,时间复杂度是O(m*n2),其中m是回向边个数,n是基本块节点个数;在二进制代码反汇编结果的控制流图中,回向边个数通常远小于基本块节点个数,则O(m*n2)≈O(n2),该算法主要是DFS路径发现所产生的开销。
3 基于循环体归约的指令序列循环识别
指令序列根据产生方式不同可以分为循环体展开的指令序列和代码动态执行所记录的指令序列,这两类指令序列中指令间具有较好的线性时序关系,描述为指令流T=I1,I2,…,In,其中Ik表示指令流中的第k条指令。
在X86指令集中,假设指令序列α∈X86*,Pref(α)是α的前缀序列集合,即若-γ∈X86*且α=βγ,则β∈Pref(α);当α∈X86*且≥1时,α∈X86+。
令TRACE为指令序列集合,一条指令序列L∈TRACE,则简单循环定义为
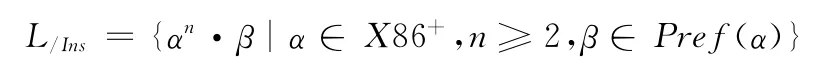
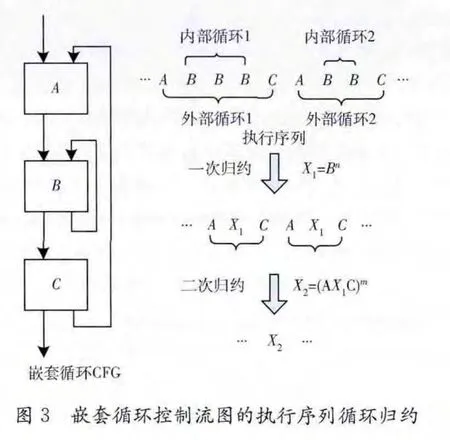
上述定义只能识别不具有循环嵌套关系的指令循环体,不能反映循环体之间的嵌套、迭代等关系,为了解决该问题,引入循环标识集合Lid表示已识别的嵌套内层循环体,循环识别采用从内到外的逐层归约方式,令TRACELid是包含循环标识的执行记录集合,则嵌套循环定义为
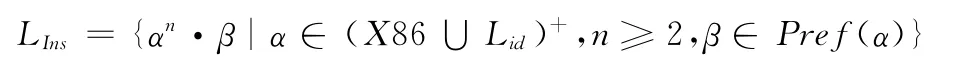
循环实例L的循环体BODY[L]∈(X86∪Lid)+,嵌套循环控制流图的执行序列循环归约如图3所示,其中X1,X2∈Lid。
在指令序列T=I1,I2,…,In中,一条指令Ik若属于循环实体BODY [loop],则指令Ik是循环实体的内部指令或是循环实体的开始指令,可以在指令序列的循环判别过程中根据可能存在的循环实体进行指令归约,基于指令序列的循环识别算法主要步骤为:
步骤1 从TRACE中取指令Ik,若k>n则退出;
步骤2 判断潜在循环堆栈结构PotentialLoops Stacks是否为空,若为空,转步骤3更新Potential LoopsStack结构,否则,转步骤4;
步骤3 采用算法FindPotentialLoops(History,Ik)更新PotentialLoopsStack结构,并把Ik添加到History指令序列中,转步骤1;
步骤4 在PotentialLoopsStack结构中按照从栈顶到栈底的顺序,依次匹配每条潜在循环指令序列中的等待指令,若匹配转步骤5,否则转步骤6;
步骤5 调整当前循环指令序列中的循环指针指向下一条指令,若循环指针不为空,转步骤1;否则,转步骤7;
步骤6 弹出栈顶的潜在循环指令序列直至Potential-LoopsStack为空,转步骤1;
步骤7 匹配一个循环体,把该循环体用Lid代替,并存储在LoopStorage结构中,调整该潜在循环指令序列的等待指针指向该指令序列的第一条指令,转步骤1。
潜在指令序列循环实体是根据当前指令内容,从已处理的指令序列 (History)中识别出可能的循环实体,具体算法伪代码如下:
算法:FindPotentialLoops (History,Ik)
输入:已处理的指令序列History,当前指令Ik
输出:更新潜在循环指令序列的堆栈结构Potential-LoopsStack
for(int j=1;j<k;j++)
{if (Historyj==Ik)
{sp=Historyj+1; //下条指令指针,等待指令
//History(j,k-1)指在History指令序列中取j至k-1的部分
PUSH (PotentialLoopStack,History (j,k-1),sp);}
}
在循环归约过程中,对于循环L= (body)m和L′=(body)n,L和L′具有相同的循环实体,为了归约外层的循环结构,则把L和L′视为相同的循环并存储在LoopStorage结构中。
4 测试与结论
4.1 测试环境
操作系统:Windows7SP1,处理器:Intel(R)Core(TM)i5-2400@3.10GHz,内存:4.00GB,硬盘:1000GB;反汇编工具[9]:IDA 6.2.0111006,动态记录工具[10]:Pin 2.11。
4.2 测试结果
(1)基于控制结构的密码函数筛选测试
通过对大量密码函数实例研究发现密码函数内部的基本块个数不会太多,核心基本块常常采用自身循环结构,基本块内部的运算类指令频次比较高,并存在数条有效异或指令,因此依据逆向分析经验设置疑似密码函数筛选条件:①函数内部基本块个数不大于20;②存在基本块循环且循环体内包含代数运算类指令频次 (除去数据传输类指令)大于0.5;③存在基本块循环且循环体内包含至少一条有效异或指令;④存在基本块循环且循环体内包含至少一条乘、除类指令 (针对公钥密码);⑤存在基本块内部指令条数不少于50且代数运算类指令频次 (除去数据传输类指令)大于0.8(针对Hash函数基本块循环展开);
上述条件③主要针对分组密码和流密码,条件④主要针对公钥密码,条件⑤主要针对基本块循环展开的Hash函数;条件①与条件②,③,④,⑤之间为 “与”关系,条件②,③,④,⑤之间为 “或”关系。
针对压缩软件WinRar、局域网通信软件FeiQ、密码学工具SHA1KeyGen和BlowfishKGM分别进行基于控制结构的密码函数筛选测试,结果见表1,其中FNbbl表示函数内基本块个数,Nbbl表示基本块指令条数,Fbbl表示基本块运算类指令频次,NbblLoop表示基本块循环个数,NComLoop表示普通循环个数,Tloop表示循环类型,基本块循环与普通循环分别表示为B、C。根据目标二进制代码反汇编结果中的函数个数、用户函数个数和筛选出的疑似密码函数个数,分别计算应用软件winrar3.91和FeiQ2.4的筛选比例分别为2.66%和1.04%;通过动态调试分析,疑似密码函数筛选结果包含了加解密主函数、密钥产生函数和动态S盒产生函数等密码关键函数。
表1 测试结果中,密码核心函数都包括了基本块自身循环,winrar3.91采用的AES加解密函数循环控制结构相同并且核心基本块具有相同的运算类指令频次,并且加解密函数使用的S盒是动态产生;SHA1KeyGen中的SHA1算法包含4个基本块循环结构,每轮循环执行次数为16次;在FeiQ2.4和BlowfishKGM采用的BlowFish密码函数核心基本块循环中存在叶子函数 (在控制流图中,不包含函数调用的一类函数)调用,该叶子函数是一个运算类指令频次较高的基本块,完成Feistel网络结构的相关功能。
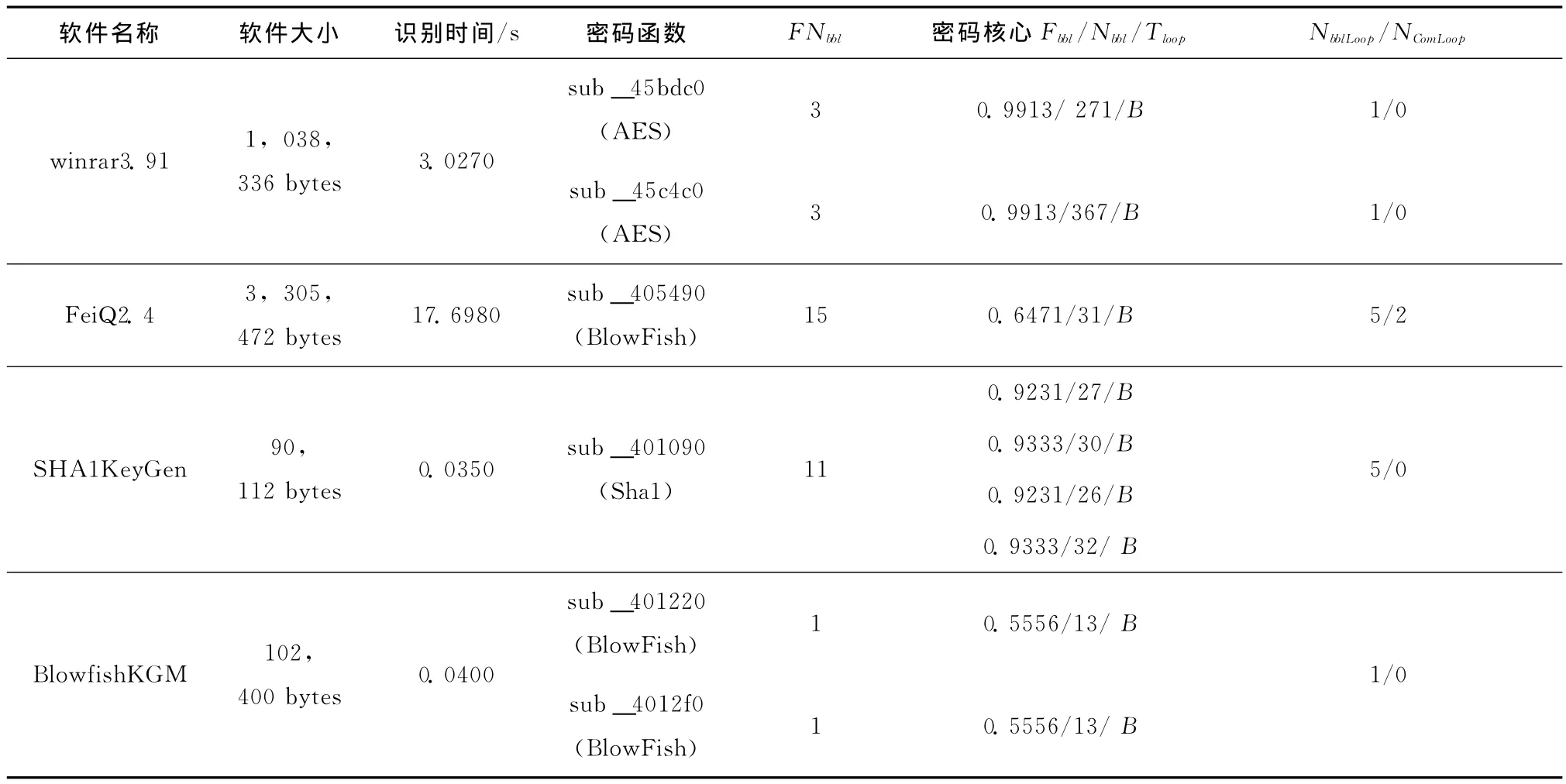
表1 基于控制结构的密码函数筛选测试结果
(2)基于指令序列的密码循环识别测试
根据产生机制,基于指令序列的循环主要分为循环展开和动态执行2种情况,Hash函数为了提高执行效率,通常采用循环结构展开的方式,在二进制代码反汇编结果中对应一个高密度算术运算的大基本块,针对循环结构展开的测试用例主要从Hash函数中选取;针对动态执行指令序列中的循环识别,采用动态二进制插桩工具Pin记录下目标代码的执行结果,并在设置密码算法的开始与结束地址后进行局部循环识别,测试用例主要从分组密码和流密 码中选取。测试结果详见表2。
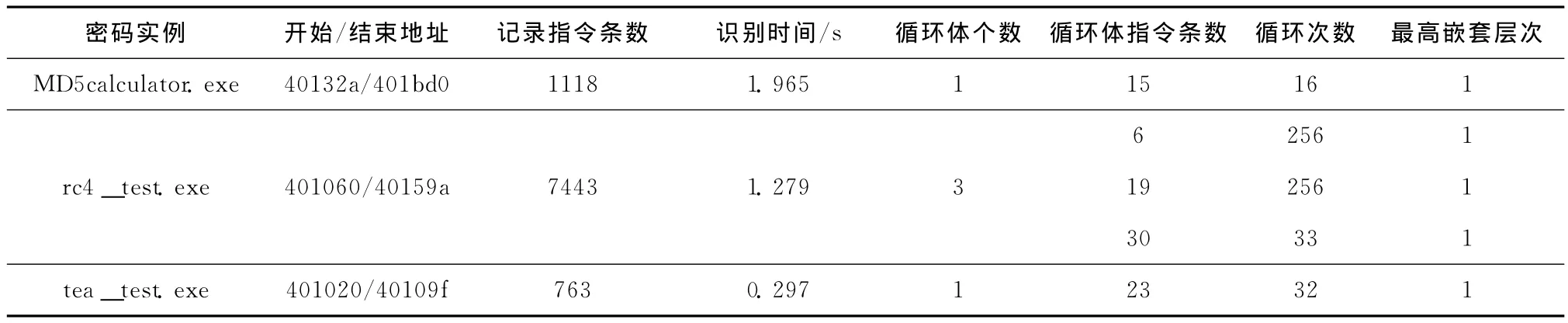
表2 基于指令序列的密码循环识别测试结果
在测试结果中,选取的开始与结束地址包含了密码算法的加密操作主要步骤,循环指令条数在总记录指令条数的百分比范围为21.47%-96.46%,具有较好的覆盖率。
5 结束语
循环模式是鉴别密码函数的重要特征之一,对于同一目标二进制代码,动态循环指令序列是静态控制循环结构展开执行的结果,针对大数据量的动态指令序列循环检测效率不高的问题,可以根据静态控制循环结构识别结果,对代码动态执行结果进行局部循环识别与验证。
此外,根据二进制代码中静态控制结构和动态指令序列的循环特征识别结果,并结合密码函数循环体中内存操作数据的高熵值特性以及循环体输入、输出数据的严格关联关系进行准确筛选与定位。
[1]Ranjan Bose.Information theory coding and cryptography[M].2nd ed.WU Chuankun,LI Hui,transl.Beijing:China Machine Press,2010 (in Chinese).[Ranjan Bose.信息论、编码与密码学 [M].2版.武传坤,李徽,译.北京:机械工业出版社,2010.]
[2]Christof Paar,Jan Pelzl.Understanding cryptography:A textbook for students and practitions [M].MA Xiaoting,transl.Beijing:QingHua University Press,2012 (in Chinese).[Christof Paar,Jan Pelzl.深入浅出密码学-常用加密技术原理与应用 [M].马小婷,译.北京:清华大学出版社,2012.]
[3]Liu Tieming,Jiang Liehui,He Hongqi,et al.Researching on cryptographic algorithm recognition based on static characteris-tic-code [C]//Future Generation Information Technology Conference,2009:140-147.
[4]LI Jizhong,JIANG Liehui.Cryptogram algorithm recognition technology based on Bayes decision-making [J].Computer Engineering,2008,34 (20):159-160 (in Chinese).[李继中,蒋烈辉.基于Bayes决策的密码算法识别技术 [J].计算机工程,2008,34 (20):159-160.]
[5]Wang Zhi,Jiang Xuxian,Cui Weidong,et al.ReFormat:Automatic reverse engineering of encrypted messages [R].NC State University,2008.
[6]LI Yang,KANG Fei,SHU Hui.Cryptographic algorithm recognition based on dynamic binary analysis [J].Computer Engineering,2012,38 (17):106-109 (in Chinese).[李洋,康绯,舒辉.基于动态二进制分析的密码算法识别 [J].计算机工程,2012,38 (17):106-109.]
[7]Felix Gr bert.Automatic identification of cryptographic primitives in software[D].Ruhr University Bochum,2010.
[8]Joan Calvet,JoséM Fernandez,Marion Jean-Yves.Aligot:Cryptographic function identification in obfuscated binary programs[C]//ACM Conference on Computer and Communications Security,2012:169-182.
[9]Chris Eagle.The IDA pro book-the unofficial guide to the world’s most popular disassembler [M].SHI Huayao,DUAN Guiju,transl.Beijing:Post & Telecom Press,2010 (in Chinese).[Chris Eagle,IDA Pro权威指南 [M].石华耀,段桂菊,译.北京:人民邮电出版社,2010.]
[10]Luk C,Cohn R,Muth R,et al.Pin:Building customized program analysis tools with dynamic instrumentation [C]//ACM SIGPLAN Conference on Programming Language Design and Implementation,2005:190-200.
