AVS 熵编码C64x+优化
2014-11-28白伟,张帅
白 伟,张 帅
(太原广播电视大学,山西 太原 030002)
AVS 数字音频、视频编码标准是我国自主定制的基础性压缩标准,其特点是编码效率显著较高、复杂度明显降低、图像质量实现高清晰度和较强的抗误码性能[1,2]。在AVS 编码过程中熵编码模块运算过程相对复杂,并且耗时较长,因此快速实现熵编码有利于编码器的实时实现。
超长指令字(VLIW)和直接处理打包数据技术在高端DSP 体系结构中得到广泛应用,因此如何结合两者的优点并有效提高算法的运行速度将成为深入研究的热点[3,4]。TMS320DM6446 是美国TI 公司研发的高集成度视频处理芯片,本文以该开发平台为例,研究了利用该系统平台优化超长指令字(VLIW)和打包数据处理技术的方法,并实现了对AVS 熵编码模块的汇编级优化。
1 AVS 熵编码算法分析
AVS 标准首先利用Zig- Zag 对量化后的数据进行扫描,游程和幅值对(Run,Level)是量化后的8* 8 个系数按照扫描顺序得到的序列对,Level 为非零系数的幅值,游程Run为连续为0 的系数的个数。研究表明,游程和幅值具有关联性,在整个频率范围内,当幅值变化较小,对应的游程可能会发生较大的变化,而当幅值不断增大时,其对应的游程则会有明显下降。由于(Run,Level)扫描序列局部的联合概率分布具有一定的差异性,因此AVS 采用了联合编码的方法,并设计了19 个VLC 码表为适应局部的差异性,根据幅值变化的程度动态使用相应的码表,从而大大提高了VLC 编码的效率。其编码过程如图1 所示。
每张VLC 码表存储空间26 ×27 byte,19 张VLC 码表需要的存储空间约为13 kbyte。对于嵌入式处理器,其内部存储器速度快,存储空间有限,将19 张VLC 码表完全存储在内部存储器,将浪费珍贵的的内部存储空间,放在外部存储器,将大大降低编码速度。对VLC 码表进行分析,其中有效码字(非负值)仅有30 个左右,码表中存在大量的逃逸标志位-1。对VLC 码表进行改造,每张码表存储32(为了字对齐)个码字,对逃逸标志不存储,通过更多判断完成实现。改进后的码表所需要的存储空间约为0.6 kbyte,占用的存储空间仅是原来的4.3%,完全可以放在内部存储,同时也方便查找,提高数据cache 命中率。

图1 熵编码流程图
2 熵编码优化
支持VLIW 的DSP 具有的特性是一条指令并行执行多个线程。C64 +有两个数据处理通路:path A 和path B,每个数据处理通道有一个包含32 个32bit 寄存器和4 个运算单元(M、D、L 和S)。四个运算单元分别执行乘法运算、地址运算、逻辑运算和移位运算等操作。由于path A 和path B是可以并行运算的,8 个运算单元在一个指令周期内并行执行的效率将是最高的,因此实际应用中尽可能将path A 和path B 的八个功能单元并行执行[5]。
DSP 数据打包处理是指对多个整型数据进行相同操作时使用单一指令对进行同时访问的技术。C64x +增加了49条新指令,提供的指令支持双字读取和存储指令,新的指令占用程序空间小,处理效率高,大大提高了流媒体的处理速度。打包数据类型是C64x +打包数据处理的基础,支持8和16 位的数据打包类型[6]。
AVS ZIG-ZAG 扫描模块是对量化后残差数据,原始的C 语言实现如下:


实现AVS 8x8 块扫描需要64 次乘法运算,64 次符号判断,最多192 次加法运算,320 次赋值运算,可见编码的复杂度相对较高。
预测残差经过整型量化之后,AVS Zig-Zag 对其数据进行扫描,输出为8 ×8 游程数据和幅值数据。ZIG-ZAG 扫描实现需要读取扫描数组AVS_SCAN0[64]和AVS_SCAN1[64]。由于读取数据指令存在延迟,并且耗时较长的特点,故采用LDDW 双字取数据指令的技术,一次同时取8 个需要处理数据。又因为C64 +有两个数据处理通路:path A 和path B,通道A 和B 又可以并行执行,故用A 通路一次完成AVS_SCAN0 数组8 个数据读取,用B 通路一次完成AVS_SCAN1 数组8 个数据读取。用LDDW 指令从AVS_SCAN0数组一次读取8 个xx,此时xx 为8 位,分别用UNPKHU4 和UNPKLU4 把它扩展成16 位;用LDDW 指令从AVS_SCAN1数组一次读取8 个yy,用MPYU4 指令一次完成8 个yy 与常数8 相乘,得到16 位的运算结果,然后分别用A 和B 交叉通路和SADDU4 指令完成与8 个xx 相加。用DPACK2 指令将yy* 8 +xx 的值扩展成每个寄存器一个值,然后读出curr_val。将curr_val 与0 比较进行赋值运算,AB 两侧寄存器并行处理,循环8 次便可使全部运算完成,最终将所得到的ipos 的值赋给icoef。其实现过程如图2 所示。

图2 ZIG-ZAG 扫描汇编优化示意图
该汇编优化示意图仅为一次循环的流程,经过首次优化后仍存在一些并行不完全的代码,为提高代码的并行性,需要将二次循环中的部分操作与首次循环没有关联的代码再次进行并行操作。
该量化系数经扫描后需通过2D-VLC 查表和指数哥伦布编码。假设扫描后得到N 个(Run,Level)对,保存在数组RunBuf 和LevBuf 中。先用默认的VLC 码表TableArr[0],对RunBuf[N-1]和LevBuf[N-1]进行指数哥伦布编码。当游程和幅值对(Run,Level)在该码表范围内时,根据索引求出码字,再得到E-G 码;反之当(Run,Level)对不在码表范围内时,则作为逃逸事件进行处理。然后根据幅值的绝对值更新码表,如果大于之前幅值的最大值,则根据码表索引数组求出用于下一个编码的(Run,Level)码表,反复循环至结束。对于逃逸事件先对Run 和Level 的符号编码,如果Run 在码表范围内,说明幅值绝对值有可能过大,则对幅值与参考值索引的差值进行E-G 编码;如果游程Run 超出了码表的范围,此时需要对幅值减1,然后再进行E-G 编码。对于负值的Level,当其绝对值在码表范围内时,具体操作是对其绝对值加1,然后再进行E-G 编码。
从上面分析看出,2D-VLC 查表运算需要根据不同门限值进行查表操作,通过对VLC 码表改造,节省了存储空间,但也带来了更多的判断操作,因此需要合理的安排指令时序实现高效的操作。不同码表间的切换,需要大量的条件跳转操作,因跳转语句B 需要6 个指令周期的延迟,如何最大程度的在跳转语句后进行无关联并行操作提高编码效率的难点。查表过程中需要将level 的绝对值和run 的范围进行界定,从而确定具体码字,如果将需要的不同常数提前准备好,在判断使用具体哪个码表时,就不需要大量的取数据操作,直接进行比较,将大大提高效率。又因为C64 +有两个数据通路A 和B,通道A 和B 可以并行执行,分别用不同的通路独立完成level 和run 的范围。首先用LDH 指令读出level 和run 的值,并通过指令CMPEQ 与0-6 比较判断处于其中哪一个表。根据判断出的值跳转到不同的表内进行下一步操作。表内的操作基本相同,使用A 通道完成对level 界定,用B 通道完成对run 界定,通过ADD,CMPLT,MVK,CMPLT 和条件判断等基本指令来完成。下面以帧内熵编码为例,说明采用汇编指令优化的实现过程。将各表跳转的门限常数值预存到通用寄存器,表1,3,5,7 采用A 通道及相应通用寄存器,表2,4,6,采用B 通道及相应通用寄存器。因跳转需要周期数较大,故在此期间将各表需要比较的常数预存到对应寄存器。跳转到各表后,通过MVK 指令将相应的常数赋值到寄存器,通过CMPLT,CMPLT2 及CMPEQ 等比较指令确定最后的level 和run 值,通过level 和run 值来确定编码的码字,完成2D-VLC 查表。
2D-VLC 查表完成后,利用指数哥伦布编码对查出来的码字进行处理,指数哥伦布编码需要求出哥伦布码的长度与阶数。哥伦布码编码完成之后会以二进制的形式逐比特写入码流。为提高运算效率,可以多次进行并行写码流操作,以四个字节为单位,当写入码流的长度达到四个字节时结束操作。写码流的具体流程如图3 所示。bs 结构体中pos 记录写入的比特数,buf 保存写入的比特值,tail 指向码流输出地址。在C64x+DSP 中,仅有A0-A2 和B0-B2 寄存器可作为条件判断寄存器,资源比较少,且为高效运行,A 通道和B 通道可并行运行,因此操作时一般每个通道仅有3 个条件寄存器可使用,这就需要在优化时充分挖掘条件寄存器的潜力,对条件寄存器使用状态通过转移表的形式标注好状态,以便更好安排并行运算。当码流赋值给输出地址时,会出现字节高低位取反的现象,需要使用SWAP4 指令提前进行交换。
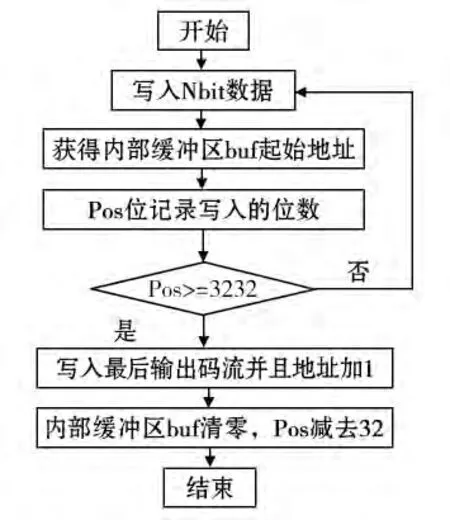
图3 写码流示意图
3 实验结果及分析
本文中采用TI 公司CCS3.3 仿真环境中profile 性能分析工具评估函数性能。不同的测试序列,熵编码时间不同,为测试精确,对CIF 格式各种典型测试序列进行测试,Y∶ U∶ V 为4∶ 2∶ 0,编码100 帧。取测试周期数平均值,每次实验环境相同,C 语言实现优化和汇编级优化编译环境设置相同,C 语言实现未优化未使用优化编译选项-o3。测试结果如表1所示。

表1 不同优化条件下函数性能比较
由上述实验结果得出:汇编级优化后量化所需时钟周期数是未优化的7.73%(762 ÷9856),是C 语言优化的17.622%(762 ÷4325);反量化需要的周期数是未优化的7.31%,是C 语言优化的13.93%。由此可见,优化效果显著。
4 结论
本文主要研究了DSP 平台VLIW 和打包数据处理的优化方法,采用此法对AVS ZIG-ZAG 扫描、2DVLC 查表和指数哥伦布编码进行汇编级优化,减少了AVS 编码器实现时间,能使AVS 算法在DSP 实现时延时更小。
[1]GB/T 200090.2-2006,信息技术 先进音视频编码,第2 部分:视频[S].2006.
[2]Wand Qiang et al,Context- Based 2D- VLC Entropy Coder in AVS Video Coding Standard,J.Comput.Sci&School,2006,21(3):315-322.
[3]李学明,李继.用超长指令实现DCT 的新算法[J].电子学报,2003,33(7):1074-1077.
[4]刘广,肖创柏,欧阳万里,等.基于VLIW 的汇编级FDCT 和扫描量化优化算法[J].计算机工程与应用,2006,43(3):59-62.
[5]TMS320C64x+DSP Megamodule Reference Guide(SPRU871K)[Z].2010.
[6]TMS320C64x/C64x+DSP CPU and Instruction Set Reference Guide (SPRU732J)[Z].2010.
