大数据研究中需要关注的几个问题
2014-11-22张福利
张福利
(鞍山师范学院图书馆,辽宁鞍山114007)
引言
早在2008年,《Nature》就推出了Big Data专刊;在2011年,《Science》推出了“Dealing with Data”,重点研究大数据的科学问题.大数据以泛在网络(泛在网络来源于拉丁语Ubiquitous,指广泛存在的网络)为依托,乘风破浪,正逐渐走进人们的生产和生活,大数据时代已经来临.如何正确认识大数据、如何利用大数据为人们的生产和生活提供优质的服务是科研工作者面临的新挑战.
大数据的研究正处于起步阶段,各国的专家学者对大数据的各个方面的工作正进行积极地探索.本文对大数据的采集、预处理、存储和管理等问题进行了相关研究.
早在1980年,“大数据”一词,出现在著名未来学家托夫勒所著的《第三次浪潮》,称颂“大数据”为“第三次浪潮的华彩乐章”.今天,大数据以其势不可挡之势,涌入人们的生产、生活,其概念也在不断地完善.
从大数据特点的角度来看,比较有代表的是3V定义[1],即大数据要满足数据量大(Volume)、数据类型多样化(Variety)和数据传输的高速性(velocity).此外,也有4V定义,国际数据公司认为大数据还应当具有价值性(Value)[2].
关于大数据的概念还有不同的定义,比如维基百科对“大数据”的解读是:“大数据”(Big Data),或称巨量数据、海量数据、大资料,指的是所涉及的数据量规模巨大到无法通过人工,在合理时间内达到截取、管理、处理、并整理成为人类所能解读的信息.百度百科对“大数据”的定义为:“大数据”(Big Data),或称巨量资料,指的是所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯.传媒专家刘建明教授认为:“大数据”同信息是不可分离的,是指信息浩大数量的统计与技术运作.作为人类认知社会方法的一次飞跃,“大数据”技术将给企业运营、政府管理和媒体传播的科学化创造有效机制.
无论是哪种定义都渗透着大数据的特点,维克托·迈尔·舍恩伯格和肯尼斯·克耶在编写的《大数据时代》中提出:“大数据”的4V特点:Volume(数据量大)、Velocity(输入和处理速度快)、Variety(数据多样性)、Value(价值密度低).
1 大数据研究中需要关注的问题
1.1 大数据的采集
大数据的一个重要方面就是大数据的采集,采集是大数据期望价值挖掘的基础.随着移动网络、社交网络以及传感网络的发展,大数据呈现出极为复杂的结构.数据类型从以结构化数据为主转向结构化、半结构化、非结构化三者的融合[3].
根据MapReduce产生数据的应用系统分类,大数据的采集主要有四种来源:管理信息系统、Web信息系统、物理信息系统、科学实验系统[4].MapReduce的执行流程如图1所示.对于多个异构的数据集,需要进行集成或整合处理,将不同数据源收集、整理、清洗、转换后,会生成一个新的数据集,供查询、分析等处理.数据的可用性是大数据采集的一个关键方面.一个正确的大数据集合至少包含5个性质:一致性、精确性、完整性、时效性和实体同一性.在数据采集阶段,由于数据多来源、多模态,大数据的采集方法尤为重要.
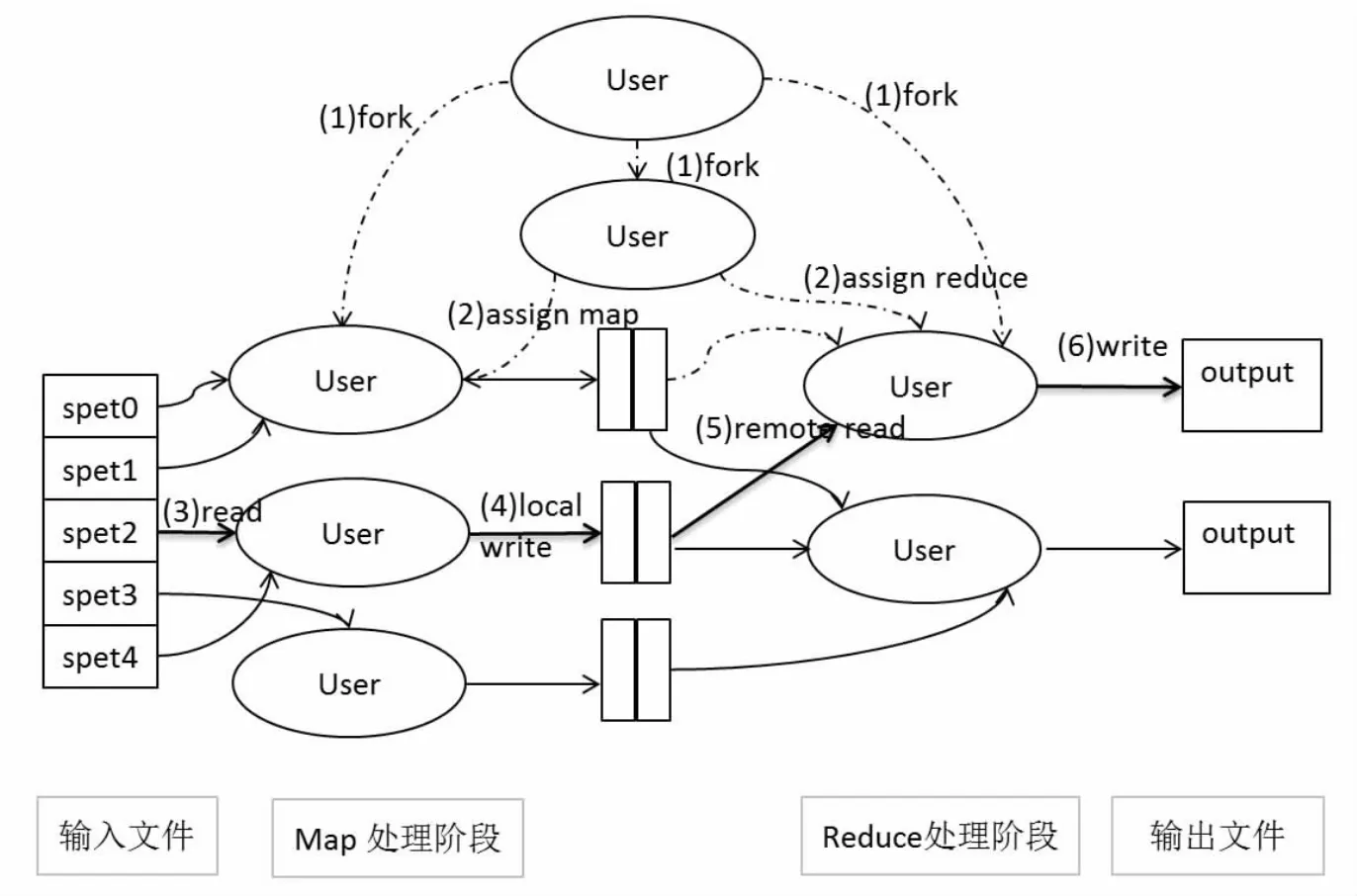
图1 MapReduce的执行流程
1.2 大数据的预处理问题
大数据预处理的研究是非常复杂的,它包含丰富的策略和技术.大数据来源的真实性、准确性、完整性、时效性等研究,在大数据几个处理阶段中是非常关键的第一步.只有保证大数据来源的质量,才能发挥大数据处理和分析的作用,才能体现大数据研究的价值.目前,关于大数据预处理的研究的关键技术有:
1.2.1 数据源的选择和高质量原始数据的采集方法 通常需建立大数据源的质量评估方法、高质量数据源的选择方法、高质量多模态大数据的获取方法.其中现有的获取方法如下:有效的数据采集方法、多模态数据融合算法、数据的保质转换算法、数据精确性和一致性方面的错误校验和纠错、数据完整性方面的缺失值处理算法、数据的时效性检验、数据的真实性验证等.
1.2.2 大数据的实体识别和解析方法 通常需要建立大数据实体关联模型、识别模型、多元多模态数据的实体自动识别方法和实体识别效果的评估模型等.模型的优劣,关系到大数据识别的效果.
1.2.3 大数据的清洗和自动修复方法 对数据进行有效的清洗,能够保证数据的质量.依据数据的约束规则,在保证数据完整性的前提下,清除不合理和错误的数据,修复重要的数据,是数据清洗的重要目的.通常需要建立数据正确语义模型、关联模型和数据约束规则、数据错误模型和错误识别学习框架、对数据不同错误类型的自动检测及修复算法、错误检测与修复结果的评估模型和评估方法等.
1.2.4 大数据整合方法 大数据高质量是数据处理过程中非常重要的研究方面,整合大数据需要整合高质量的数据.这个过程通常需要建立多源多模态信息集成模型、异构数据智能转换模型、异构数据集成的智能模式抽取和模式匹配算法、自动的容错映射和转换模型及算法、整合信息的正确性验证方法、整合信息的可用性评估方法等.
1.2.5 数据演化的溯源管理 建立世系模型及其追踪技术来跟踪和记录数据演化过程,确保数据的质量.
1.3 大数据的存储问题
大数据时代的数据呈现出多样化,不仅有结构化数据,还存在半结构化和非结构化的数据,而且随着社交网络和移动网络的发展,非结构化数据越来越多.大数据的存储重点就是把采集到的不同结构的数据经过预处理,提高数据质量,将其存储起来,并建立相应的数据库来进行管理.
大数据的管理、查询及分析方面对存储技术提出了更高的要求,数据量大、结构复杂、存储标准都将发生革命性的改变.适合大数据存储与管理的技术有存储海量非结构化数据的分布式文件系统、存储海量无模式的半结构化数据的分布式数据库和存储海量结构化数据的分布式并行数据库系统[4].
分布式文件系统,主流的有HDFS和GFS.HDFS具有很强的可扩展性,很高的容错性,是模仿GFS的开源实现.GFS是Google自行开发的文件系统,是一个能够应用在大量廉价服务器上的可扩展的分布式文件系统.但是,GFS存在单点故障,Google又研发了Colosuss系统,解决了GFS的单点故障的瓶颈问题以及实现了海量小文件的存储.Tachyon是建立在内存基础上的分布式大数据文件系统数据库系统包括事务性数据库和分析型数据库.事务性数据库主要包括NoSQL和NewSQL.根据管理数据的模式分类,NoSQL系统可以分为3类:键值系统、文档存储系统以及图数据库.键值系统的代表性系统包括BigTable,Dynamo,HBase,Gemfire,Redis,Cassandra;文档存储系统的代表包括 MongoDB 和 Couchbase;图数据库的代表是Neo4j,等等.NewSQL代表的有Spanner、NuoDB、SQLFile和VoltDB.分析型数据库代表的有 Hive、HAWQ、Impala 和 Hadapt.
上述数据存储技术还存在一些局限性,只能针对某一类型的数据进行存储,大数据类型复杂,往往是结构化、半结构化和非结构共存,大数据的存储需要实现各种类型的数据统一的存储,这样,云存储成为大数据存储的归宿.云存储系统可分为4种类型:基于块存储、基于文件存储、基于对象存储以及基于表存储.云存储的简易架构如图2所示.其中,存储节点负责存放文件,控制节点则是作为文件索引,并负责监控存储节点间容量及负载的均衡,这两个部分合起来便组成一个简单的云存储框架.国内尚未有大数据存储的管理服务,研究适合大数据存储框架以及研究适应数据分布的存储结构优化方法,对提高大数据存储和管理具有非常重要的意义.
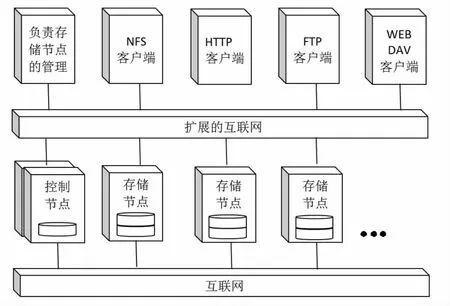
图2 简单的云存储框架
1.4 大数据的管理问题
有效的存储和索引技术能够大幅提高数据管理效率.多维索引包括:R-tree、M-tree、SR-tree.关于不确定性的大数据的查询研究,越来越多地得到重视.不确定性对象的概率查询包括:范围查询、最近邻查询、反向最近邻查询、排序查询、天际线查询、反向天际线查询和相似连接等.反向最近邻查询通常用在游戏里,比如只能射击最近的人,再有就是用于海洋援救.最近邻查询可以在传感网络和RFID中得到很好的应用.
2 结论
大数据采集与预处理工作中,由于大数据的数据规模大、数据产生快、数据类型复杂、价值密度低的特点,给大数据采集与预处理工作带来了巨大的挑战.虽然对于数据的可用性、完整性、不确定性等方面的研究已经取得了一些成果,但是,大数据的研究还是处于起步阶段,数据的多源化、质量的差异化、如何获取高质量的大数据、如何整合现有的多源数据、如何检测和修复数据等问题,都是大数据亟待解决的问题.
大数据存储与管理的问题主要集中在如下几个方面:(1)存储规模大;(2)存储管理复杂,由于结构化、半结构化和非结构化数据并存;(3)对于数据服务要求更高.对于存储中问题的解决,要融合高效元数据管理技术、系统弹性扩展技术、负载均衡技术等.
科学地解决大数据采集与预处理、大数据存储与管理等方面的问题,将会加快大数据时代的到来,让大数据更好地服务于人们的生产和生活.
[1]Grobelnik M.Big - data computing:Creating revolutionary breakthroughs in comerce,science,andsociety[R/OL].http://videolectures.net/eswc2012_grobelnik_big_data,2012 -10 -02.
[2]Barwich H.The“four Vs”of Big Data.Implementing Information Infrastructure Sysposum[EB/OL].http://www.computerworld.com.au/article/396198/iiis_four_vs_big_data.2012 -10 -02.
[3]孟晓峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[4]王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):125-1137.
