基于关键姿势的人体动作识别
2014-11-20安建成
刘 博,安建成
(太原理工大学计算智能研究室,山西太原030024)
1 人体动作识别
人体动作识别在计算机视觉方面已经成为了一个流行的话题。在如此多的视频监控和人机交互系统中,一个可靠有效的解决方法显得尤为重要。
现在有很多方法来表示动作和提取动作特征,例如基于运动的方法[1]、空间—时间的兴趣点[2-3]、空间—时间分割[4]。相对于以上复杂的识别方法,对于给定的动作,人脑可以很快地识别出这个人在干什么,这是因为人脑可以根据这个人的姿势,不需要看完这个动作过程就可以做出判断。在人脑识别动作的过程中,不需要任何的时间信息,而是需要去挖掘用姿势来进行动作识别的潜力。
本文提出一种基于关键姿势的简单方法,类似于人脑识别方式来识别动作。通过提取人体轮廓,再对轮廓进行线条化处理。对于一个动作,能提取出带有这个动作特征的几个或十几个关键姿势。对于给定的动作帧序列,每一帧中的动作都会被提取出来线条化并与线条化后关键姿势对比,计算相似度。最后,分类动作的帧序列,分类数最多的就是识别结果。
2 关键动作的提取
对每个帧提取动作的步骤(图1)为:首先利用基于序列图像的人体跟踪算法[5],然后在每一帧中用方框框出人的图像,接着利用背景减除法提取人像的边缘信息。为了消除由杂乱背景所产生的噪声的影响,滞后阈值将在下一个步骤添加。在这点就可以从一个给定的帧序列中发现最佳的高和低的阈值,步骤如下:从一个动作序列选择一个随机帧,用一个多边形手动画出人体图像的边缘,在所选区域的边缘值变化范围可以用来确定低和高的阈值。为了消除残留的噪声,边缘像素投射到x轴和y轴,则不属于最大连接组件的像素被去除。之后,剩下的像素点用带有方向的信息链连接起来。这些链结构可用来构建一个轮廓段的网络(CSN)[6]。最后用k邻接轮廓段(k-Adjacent Segments,k-AS)描述CSN网络,这也是在物体识别领域里比较流行的做法。

图1 姿势提取的步骤
在CSN网中,如果k条线段是按序连接的,即第i条线段与第(i+1)条线段连接(i∈(1,k-1)),则称这k条线段组成一个k邻接轮廓线段组,k为其度。随着k的增长,k-AS能够描述越来越复杂的局部形状结构。人类的姿势,特别是肢体运动,可以用L-shapes来描述。因此,选择k=2,即2-AS直线对。这样每个线对由直线段S1和直线段S2组成,即
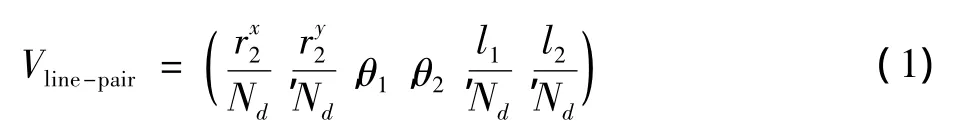
3 计算姿势之间的相似性
用线对的集合来描述给定每一帧的姿势。两个线对描述(va,vb)的相似性计算为
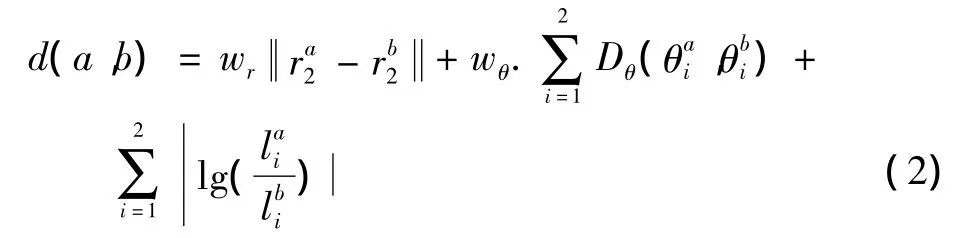
式(2)的第一部分是计算两个线对的位置差异,第二部分是计算方向差异,最后一个是计算长度差异,每项的权重wr=4,wθ=2。式(2)只能比较两个线对的相似性,下文将介绍一种可以计算比较两帧里多个线对的方法。
在任何由线对组成的两帧中,把这两个帧中的线对当成是两个集合X,Y,为了匹配这两个集合中的元素,线对的匹配必须要满足一对一和多对一的模式,所以集合X中的每一个线对元素和集合Y中的每一个线对元素对应。
在f1,f2两帧中,包含了两个线对的集合φ1={v1,v2,…,vi,…,vn}和 φ2={v1,v2,…,vk,…,vm},f1中有n个线对,f2中有m个线对。用φ1中每一个vi和φ2中每一个vk做比较,找出匹配线对,只有在φ2中vk对于vi有最小相似距离和φ1中对于vk有最小相似距离时,vk和vi相似,图2是相对匹配事例。

图2 相似姿势的线对匹配
当满足这种一对一的匹配属性时,就可以求出平均的线对匹配距离davg。sim(f1,f2)是f1,f2的相似度计算公式
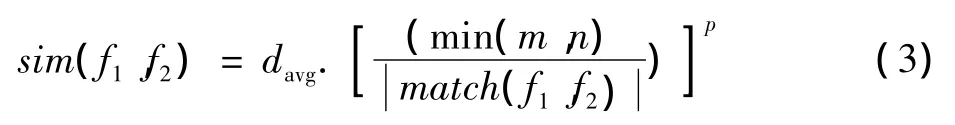
式中:match(f1,f2)表示匹配成功的线对数量,经过实验发现,p=2是最优值。
4 关键姿势的提取
关键姿态序列一般可以表示一种特殊的动作。直观地说,视频中一个关键姿势序列合理地分布在视频帧中,这个关键姿势序列很好地再现了这个动作形态。用K中心点聚类算法[7]来提取关键姿势,因为聚集的中心点能很好地提取每个动作的姿态。但是,直接用中心点作为关键姿势并不能保证和另一个动作区分开,因为一系列的姿势可能属于多个动作。例如,挥手和拍手的动作共享几个姿势,都是人在挥动手臂。因此本文采用下文算法来把关键的姿势(能区分开来和其他动作)分类。最后,给每一个动作关键姿势的帧排序,根据其识别度给出分数,然后把分数最高的作为关键姿势。图3是KTH数据集中6种动作的关键姿势[8]。

图3 在KTH数据集中6种动作的关键姿势(拳击、拍手、挥手、慢跑、跑步、走)
提取关键姿势算法具体如下:
1)K=(1,N),K是关键姿势的数量。
(1)每一个动作ai∈A,A={a1,a2,…,aM},M是不同动作的数量。用K中心点聚类算法来提取ai中的关键姿势,数量为K;从ai动作提取出来的候选关键姿势序列为ci={ci1,ci2,…,ciK}。
(2)将上述样本的动作视频按一帧分开,f为一帧。用f和关键姿势序列匹配ci={ci1,ci2,…,ciK};ciK和视频中所有的帧f匹配的i∈[1,M],k∈[1,K];对每个关键姿势设定个值,如果匹配成功,就给这个关键姿势的值增加1。
2)对每组动作中的关键姿势按他值排序,把值最高的几个作为这个动作的关键姿势。
5 动作识别
为了分类给定的动作序列,首先每一帧要和所有动作的所有关键姿势对比,把给定视频中的动作序列和关键姿势进行相似分类计数,就是视频帧中有多少和给定的关键姿势序列1相似,统计出来,以此类推。图4说明了分类计数的过程。
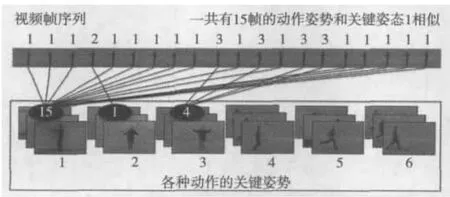
图4 使用关键姿势进行动作识别的过程
6 实验结果
用 KTH[8]和 Weizmann[9]的数据集来测试本文的动作识别算法。选取了Weizmann 7个动作(蹲、起立、跳、快跑、侧面、走、挥手),这些动作由9个不同的人来演示。选取KTH的6个动作(拳击、拍手、挥手、慢跑、跑、走),这些动作由25个不同的人在4个场景下进行表演:室外(s1)、室外不同的地方(s2)、室外穿不同的衣服(s3)、室内(s4)。
对于选用Weizmann数据集合的6个动作样本,本文在对轮廓进行线对描述,忽略其噪声。为了评估分类性能,本文采用留一交叉验证[10]。
对于KTH,认为它是一个单一的大集合,但是其中的样本在边缘检测的结果中有大量的噪声。为了评估分类性能,采用十倍交叉验证然后求平均结果。因为计算开销较大,随机选择了一半的数据集,用十倍交叉验证对75%的样本进行训练,剩下的25%在每次测试中运行。在KTH数据集中,每个动作序列帧速率是不一样的。为了保持一致,把每个动作的帧限定到20~50之间,能使动作流畅地演示一次。
在K=47时获得了92.6%的识别率,K=78时也获得了91.5%的识别率,对于KTH的数据集,K是每个动作的关键姿势。对于Weizmann的数据集,还可以提高识别率到95.06%,采用严格的几何约束,对每个帧放到一个二维坐标中,只在同一坐标内线对做匹配。但是,对于一部分KTH的数据集,人的图像并不完整(例如缺少头、腿等),对图像进行边缘检测和对图像帧进行几何约束的匹配时,这样的图像不能被很好地识别。图5是平均分类的准确率和关键姿势数量的关系。本文方法需要大量的K值,以达到良好的分类性能,因为不同表演者对同一个动作的演示也是不同的。
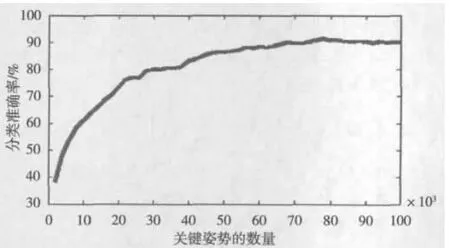
图5 分类的准确率和对每个动作提取关键姿势的数量关系曲线图
在识别结果方面,局部时空特征的动作识别[11]方法基于Weizmann数据集的识别率是75% ~87%(表1),局部时空特征的动作识别方法基于KTH数据集的识别率是59% ~100%(表2)。因为本文中的测试数据和基于局部时空特征的动作识别方法采用的数据一致(Weizmann数据集和KTH数据集),所以从实验结果看,基于Weizmann数据集大部分动作关键姿势的识别率比局部时空特征高(表3)。在基于KTH数据集,关键姿势的识别方法对比局部时空特征在跑、慢跑、挥手、走的动作识别方面也有一定的优势(表4)。
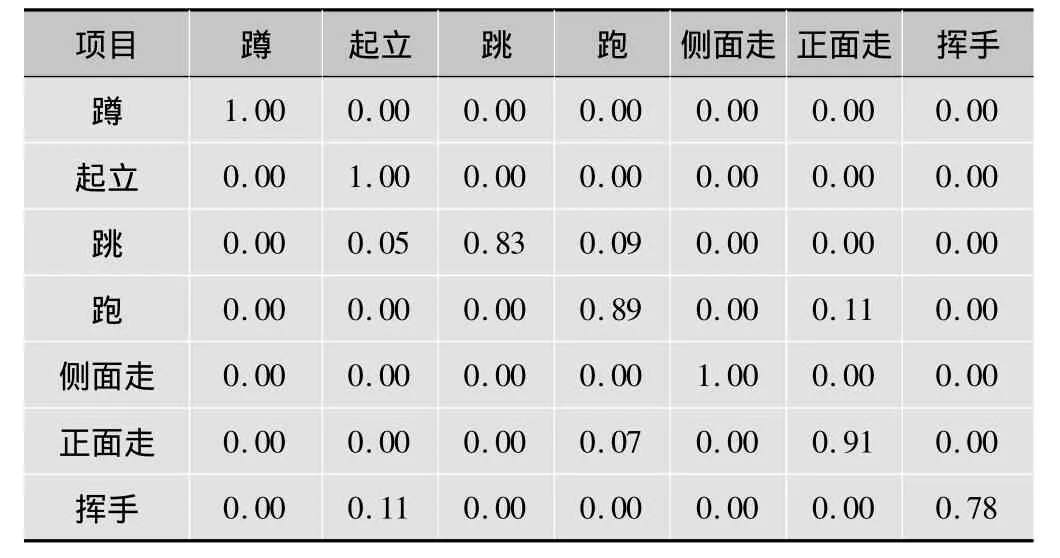
表1 在Weizmann数据集中K=47的混淆矩阵
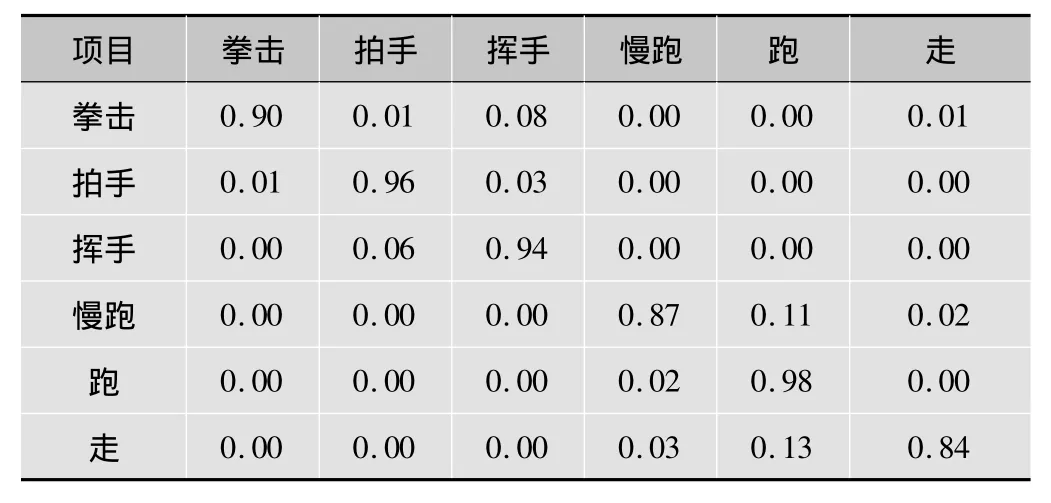
表2 在KTH数据集中K=78时的混淆矩阵

表3 局部时空特征的动作识别率基于Weizmann数据集

表4 局部时空特征的动作识别率基于KTH数据集
此外,对于KTH的数据集,一部分的错误分类也是由于场景(s3)中表演者穿不同的衣服,拿不同的东西,在提取轮廓的时候产生额外的线对。
7 总结
本文引入一个新方法——提取动作的关键姿势,试验这种方式在动作识别方面的准确度。用线对(包含位置、方向、长度信息)来描绘每一帧动作姿势的形状特征。因此,把姿势信息放到直方图上,该方法可以很好地保存线对(表示姿势)的空间信息。通过匹配算法,比较两帧中的线对集合。关键姿势描绘动作的识别上也能明显区别于其他动作。但是本文方法对边缘检测有很强的依赖性,对背景的噪声也十分敏感,有待进一步研究。
[1]LU G .Motion-based region growing segmentation of image sequences[J].Journal of Electronics,2000,17(1):53-58.
[2]李永浩,张西红,彭涛,等.基于视觉注意力模型的红外人体图像兴趣区域提取[J].计算机应用研究,2008,28(12):94-96.
[3]支俊.车辆检测中一种兴趣区域提取方法[J].计算机工程与设计,2007,28(12):3013-3015.
[4] BLANKM,GORELICK L,SHECHTMAN E,etal.Actions as space-time shapes[C]//Proc.ICCV 2005 .[S.l.]:IEEE Press,2005:2247-2253.
[5]范新南,丁朋华,刘俊定,等.基于序列图像的人体跟踪算法研究综述[J].计算机工程与设计,2012,33(1):278-282.
[6] FERRARIV,FEVRIER L,JURIE F,et al.Groups of adjacent contour segments for object detection[J].IEEE Trans.on Pattern Analysis and Machine Intelligence,2008,30(1):36-51.
[7]谢娟英,郭文娟,谢维信.基于邻域的K中心点聚类算法[J].陕西师范大学学报,2012,40(4):16-23.
[8] SCHULDT C,LAPTEV I,CAPUTO B.Recognizing human actions:A local SVM approach[C]//Proc.ICPR 2004.[S.l.]:IEEE Press,2004:32-36.
[9] BLANK M,GORELICK L,SHECHTMAN E,et al.Actions as spacetime shapes[C]//Proc.ICCV 2005.[S.l.]:IEEE Press,2005:2247-2253.
[10]刘学艺,李平,郜传厚.极限学习机的快速留一交叉验证算法[J].上海交通大学学报,2011,45(8):1140-1146.
[11]雷庆,李绍滋.动作识别中局部时空特征的运动表示方法研究[J].计算机工程与应用,2010,46(34):7-10.
