基于GIS和PSO-SVM模型的文山州石漠化风险评估
2014-11-08冷信风赖祖龙
冷信风,赖祖龙
(1.修水县国土资源局,江西 修水332400;2.中国地质大学信息工程学院,湖北 武汉430074)
喀斯特石漠化是在脆弱的生态地质环境基础上,由于人为因素的影响而导致的以土地生产力退化为本质的现象,是土地荒漠化的主要类型之一,它对生态环境和人类生存发展造成了严重的危害[1—2]。石漠化风险评估是非常重要的自然灾害风险分析,但由于其具有明显的多目标性、且受多因子和各个层次因素相互作用的影响,因此对石漠化进行风险评估是一项复杂的系统工程[3]。目前针对石漠化风险评估主要考虑以下三大类的评估指标:现状指标(基岩裸露率、植被覆盖度、坡度、土壤裸露率、土壤类型)、演变速率指标(石漠化年增长率、人均耕地面积)、脆弱性评价指标(人口密度、人均 GDP、农业利用价值)[4],这些指标主要是通过遥感[5]和调查统计获取,并运用地理信息系统(Geographic Information System,GIS)对处理后的遥感影像进行综合分析。由于GIS具有数据组织和管理、空间分析、地理制图和空间数据可视化等方面的优势,因此已成为进行地理空间信息综合分析的有效工具[6]。
在进行石漠化风险评估时,面对大规模的指标体系,必须要揭示变量之间的关系并简化数学建模的过程,使得评估模型变量的选取更加合理,风险评估结果精度更高,因此有必要先使用主成分分析(PCA)将原始指标数据进行压缩以避免指标间的多重共线性[7]。传统评估模型大都存在权重系数难以确定、只考虑了各指标间线性关系的缺点,而支持向量机(Support Vector Machine,SVM)具有避免定权、充分考虑非线性关系和评估结果更加客观可靠的优点,它是一种基于统计学理论和结构风险最小化原理的模式识别方法[8],评估分类效果较基于经验风险最小化原理的人工神经网络更优。此外,考虑到SVM模型的评估性能很大程度上依赖于参数的选取,如文献[9]中支持向量机参数选取均采用穷举法等人工反复试验的方法,不仅效率低且得到的未必是全局最优解,针对这一问题,采用全局搜索能力强且实现简单的粒子群优化(PSO)算法[10]来优化选取SVM模型参数。
基于此,本文在利用GIS进行空间数据管理和分析的基础上,首先采用主成分分析进行指标筛选,再运用PSO-SVM模型对云南省文山州喀斯特石漠化现象进行风险评估,并将评估结果与单独SVM模型和PSO-BP模型进行对比分析,以期为石漠化风险评估提供一种新思路。
1 粒子群优化算法和支持向量机模型
1.1 粒子群优化算法
粒子群优化(PSO)算法是由Eberhart和Kennedy等提出的基于群体智能的参数寻优技术,它通过群体中各个粒子间的竞争和合作形成的群体智能来优化搜索。PSO算法数学描述为:初始化D维向量空间中的K个随机粒子,其中第k个粒子的位置向量为xk=(xk1,xk2,…,xkD),速度向量为vk=(vk1,vk2,…,vkD),(k=1,2,…,K),将xk代入目标函数,计算出每个粒子的适应度值,确定每个粒子的当前个体最优解pbest记为Pk=(pk1,pk2,…,pkD)和当前群体最优解gbest记为Pg=(pg1,pg2,…,pgD)。在每一次迭代中,找到这两个最优值后,粒子根据下面公式更新本身的速度向量和位置向量:式中:t=1,2,…,tmax代表迭代次数;ω为惯性权重;r1和r2为区间[0,1]上的随机生成数;c1和c2为学习因子。
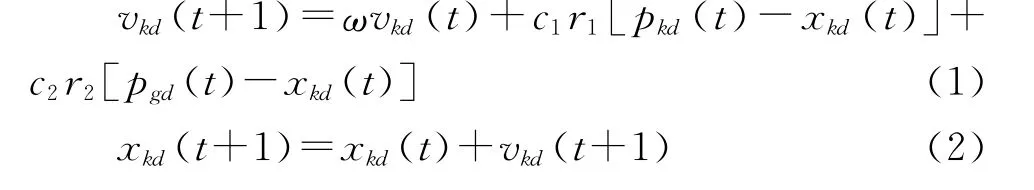
1.2 支持向量机模型
Vapnik等1995年提出基于统计学习理论的支持向量机模型(SVM模型),它是一种新型机器学习算法,其基本思想为:定义最优线性超平面,并把寻找最优线性超平面的算法归结为求解一个凸规划问题;进而基于Mercer核展开定理,通过非线性映射把样本空间映射到一个高维特征空间,使其在特征空间中可以应用线性学习机的方法解决样本空间中的高度非线性分类和回归等问题。与传统统计学相比,统计学理论专门研究有限样本条件下的机器学习规律,而SVM模型既有严格的理论基础,又能较好地解决有限样本、高维数、非线性和局部最值等问题。
2 基于GIS和PSO-SVM模型的石漠化风险评估
2.1 基于GIS的指标数据管理和可视化分析
本文的三大类评估指标主要通过遥感影像解译、地图数字化和实地调查统计获取,指标数据量巨大,因此需要利用GIS软件制作出反映各种信息的专题图与专题数据库,以便高效地管理风险评估的空间数据与属性数据。由于GIS具有优越的空间数据显示功能[11],因此可采用颜色的深浅和填充纹理的差异来反映不同地区的石漠化风险,从而形象、直观地表达石漠化风险评估的结果。基于GIS的石漠化风险评估类似于一种栅格影像的叠加分析,如图1所示。
2.2 基于PSO-SVM模型的石漠化风险评估步骤
依据基岩裸露率、植被覆盖度等指标数据进行石漠化风险评估,其本质是一个非线性映射的过程,而利用SVM模型解决这类复杂的非线性映射问题具有明显的优势,因此本文使用SVM模型进行石漠化风险评估。使用SVM模型进行评估之前,需先运用主成分分析对原始指标数据进行预处理,具体流程如下:
(1)将原始指标数据进行归一化处理,主要是为了消除各指标量纲不同和数量级差异过大对模型造成的影响。

图1 各个指标专题图以栅格影像的方式进行叠加分析Fig.1 All indexes thematic maps
(2)对归一化后的指标数据进行主成分分析,获得新的综合指标,主要包括求取原始指标数据相关系数矩阵的特征值、特征向量以及指标主成分。
适合的温度有利于酿酒酵母更好的生长代谢,研究了温度对Y17aM3生长及生产RNA的影响,结果如图 13。Y17aM3随着培养温度升高而生长减慢及RNA产量减少,因此低温更有利于Y17aM3生长和积累RNA。最适温度为26 ℃,此时Y17aM3生长OD600最高为14.5,RNA含量最高为115 mg-RNA/g-DCW,比在30 ℃条件下提高了3 mg-RNA/g-DCW。
(3)将新的综合指标作为SVM模型的训练和测试数据,并运用PSO算法对SVM模型进行参数寻优,得到SVM模型的最佳参数,以便确定最终用于石漠化风险评估的SVM模型。
(4)使用石漠化风险评估的分类精度作为模型训练和模型测试的效果检验,通过野外实地调查和专题图采样获取样本数据,选取其中部分样本数据用作模型训练,另外的样本数据用作模型测试,并在试验分析的基础上,对石漠化风险评估模型的性能进行综合评定。
3 石漠化风险评估实例分析
3.1 研究区概况及数据来源
本文以云南省文山州为研究区进行石漠化风险评估。
文山州位于滇东南偏西,东经103°43′~104°27′、北 纬 23°16′~23°44′之间,全州总面积2 972km2,总人口419 018人。文山州地域属滇东南岩溶山原区,境内山峦起伏,河谷沟壑纵横,大部分地区属西风带中亚热带季风气候,年均气温为12.8℃~18.1℃,降雨量较充沛,年均降雨量为992.7mm。图2为文山州的州界轮廊图。
本次喀斯特石漠化风险评估以栅格为计算单元,每个格网的大小为50m×50m,将研究区分割成372 311个格网。其中,基岩裸露率、植被覆盖度、坡度和土壤裸露率的分布见图3至图6。
图2 文山州的州界轮廓图Fig.2 Boundary contour figure of Wenshan Prefecture

图3 文山州基岩裸露率分布图Fig.3 Bedrock exposed rate distribution of Wenshan Prefecture
图4 文山州植被覆盖度分布图Fig.4 Vegetation coverage distribution of Wenshan Prefecture

图5 文山州坡度分布图Fig.5 Slope distribution of Wenshan Prefecture
本文选取200个样本数据,根据野外调查,将对应的喀斯特石漠化风险程度分为4个等级,形成训练样本和测试样本数据,见表1。

图6 文山州土壤裸露率分布图Fig.6 Bare soil rate distribution of Wenshan Prefecture
为了便于对SVM机模型的参数进行训练,将SVM模型的训练结果和石漠化风险程度评估等级相对应,即没有石漠化风险时对应等级为1,轻度石漠化时对应等级为2,中度石漠化时对应等级为3,重度石漠化时对应等级为4。
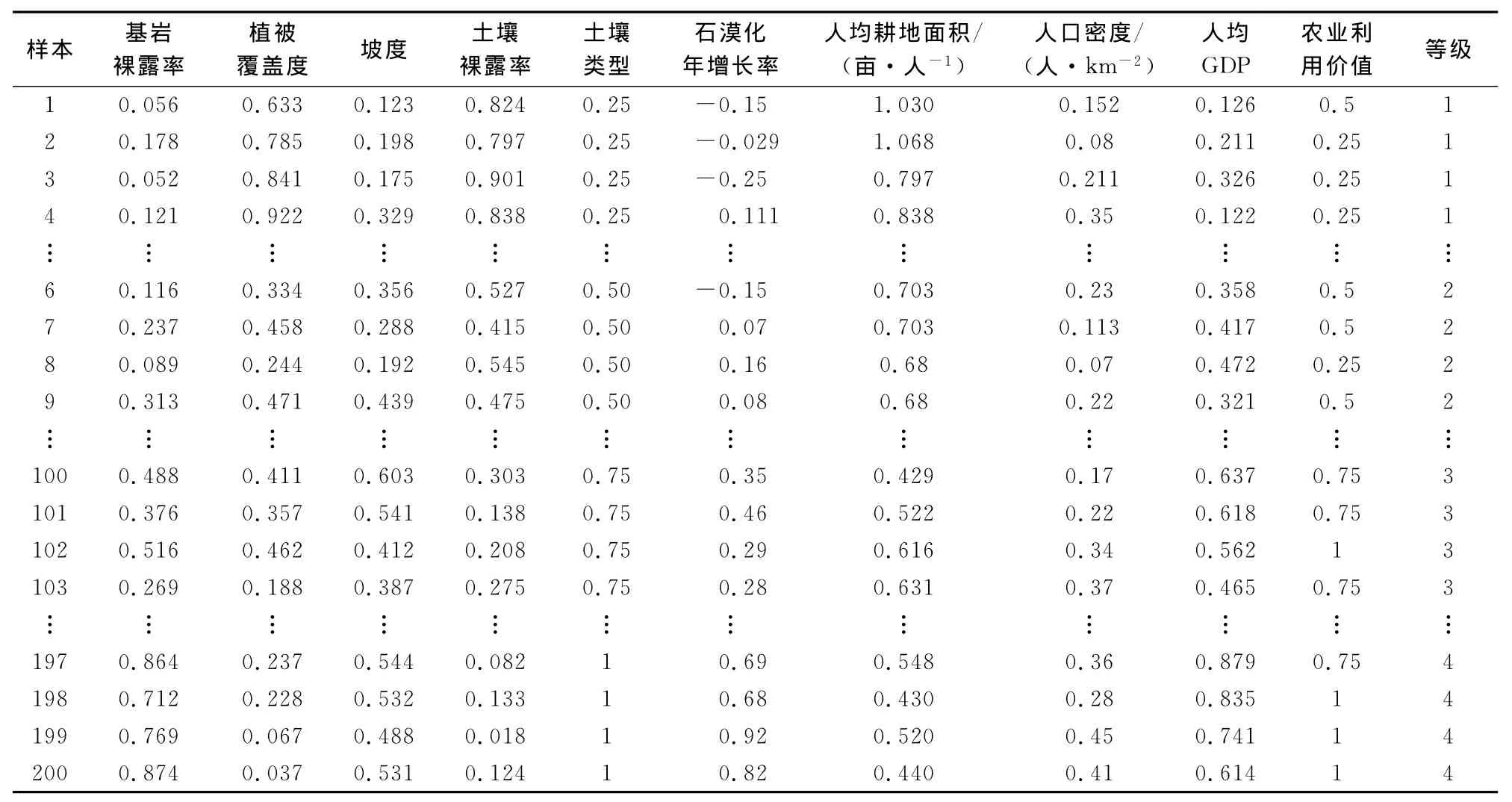
表1 归一化处理后的样本数据Table 1 Sample data after normalization
3.2 数据预处理
表1中10个风险评估指标中,某些指标间可能存在一定的相关性,如植被覆盖度与土壤裸露率之间、石漠化年增长率与人均耕地面积之间均呈负相关性,而且过多的输入变量容易造成数据冗余,增加评估模型的复杂度,因此有必要对200个样本数据的10个变量指标进行主成分分析,剔除变量之间的相关性,提高模型风险评估的精度。本文使用SPSS软件自动计算主成分其具体计算过程如下:
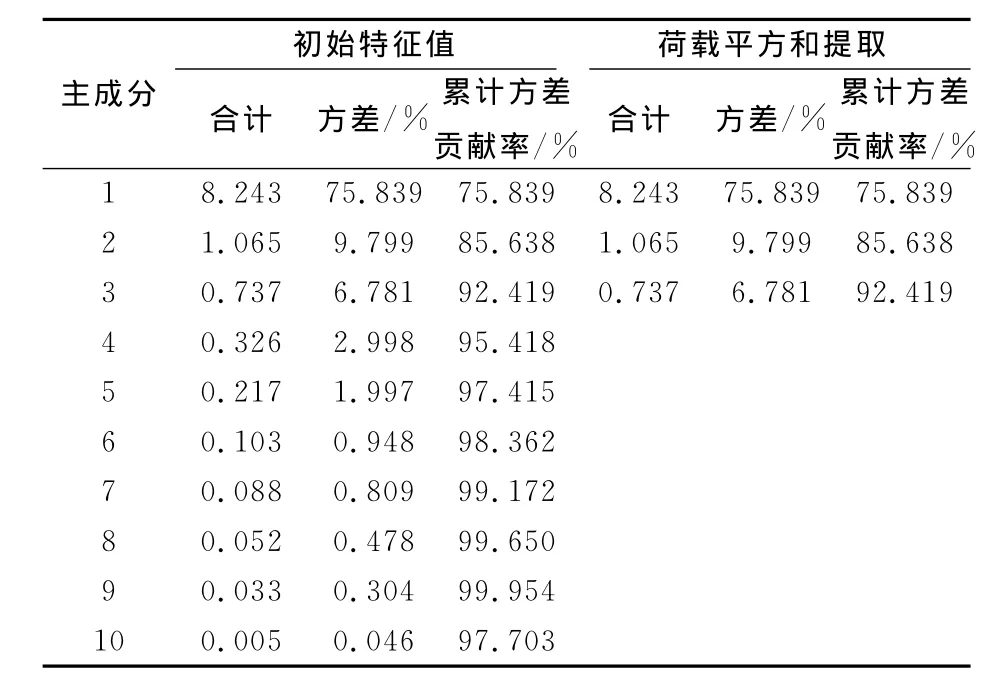
表2 累计方差贡献率Table 2 Cumulative variance contribution rate
(2)由前3个特征根求得相对应的特征向量构成正交矩阵,再用特征根平方根对角矩阵左乘正交矩阵,得到主成分载荷矩阵,见表3。
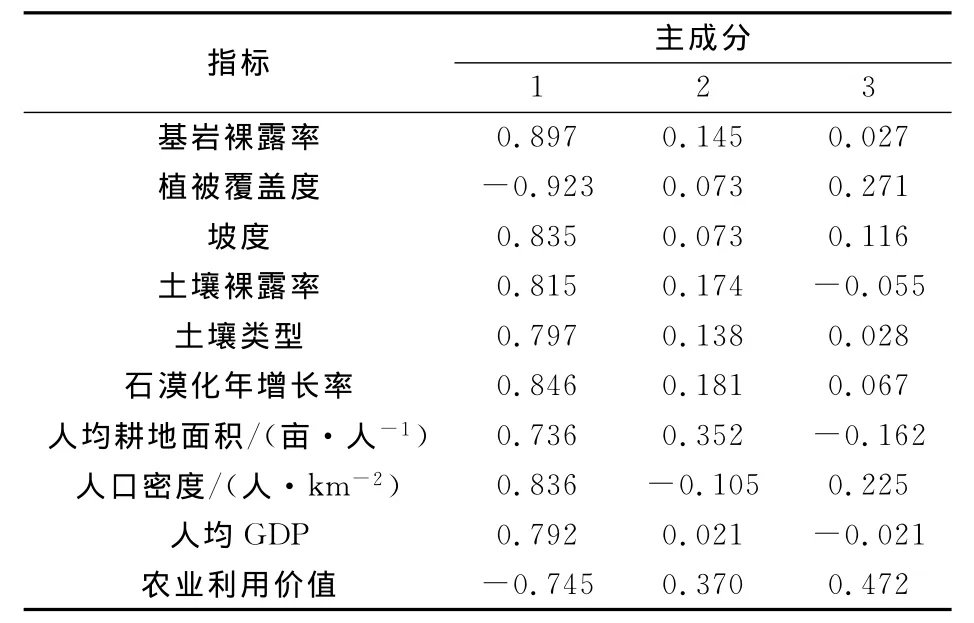
表3 主成分载荷矩阵Table 3 Principal component load matrix
(3)最后计算主成分与原始变量之间的关系,用转置后的正交矩阵左乘原始数据矩阵,即可得到经过主成分变换后的新指标,这3个新指标反映了原始变量92.419%的信息。
3.3 PSO-SVM模型确定
从主成分分析后得到的新指标样本中,选取100个样本作为训练样本,另外100个样本作为测试样本,并采用PSO算法优选SVM模型的参数,具体过程如下(见图7):
(1)用分类预测误差作为适应度值,初始化PSO-SVM模型,主要是针对SVM模型的两个参数(核函数参数g和惩罚因子C)进行优化选取,PSO算法需要设置的参数主要包括粒子维数d、粒子位置和速度随机初始化、种群规模N、最大迭代次数tmax等。
(2)分别由每个粒子建立相应的SVM模型,再根据计算适应度值的函数对各个粒子的初始适应度值进行对比分析。
(3)由迭代后的粒子获取新的SVM模型参数,并建立新的预测模型,再对比分析目标函数预测值,重新对每个个体进行迭代更新。
(4)对区域中的所有个体,将当前位置计算出的目标函数适应度值同该个体历史最优位置和群体最优位置的目标函数适应度值进行对比分析,假若当前位置效果更好,则将该位置替代掉历史最优位置。
(5)给粒子群设定终止条件,通常设定为迭代次数达到了极限迭代次数,若满足该终止条件,搜索停止,否则算法会返回到第(3)步,继续迭代。
(6)将满足条件的全局最优粒子所对应的核函数参数g和惩罚因子C,代入SVM模型中对其进行分类评估。
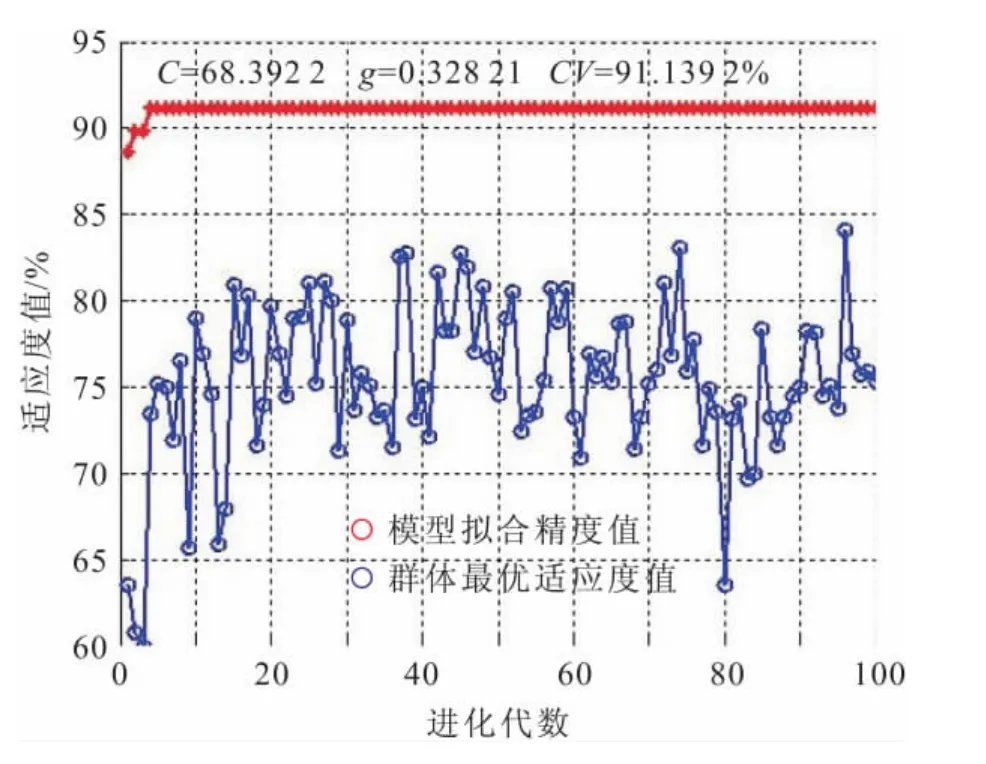
图7 PSO-SVM模型参数选取过程图Fig.7 Process of parameter selection in PSO-SVM model
由图7可知,粒子群优化的SVM模型参数为核函数参数g=0.328 21,惩罚因子C=68.392 2。
对于PSO-BP模型,采用PSO算法优化选取BP模型的参数值,BP网络隐藏层神经元个数为20,训练次数为500次。对于单独SVM模型,采用交叉验证的方法来得到最优参数,并通过反复验证最终确定SVM模型的参数为:核函数参数g=0.15,惩罚因子C=50。
几种模型对文山州石漠化风险最终评估精度见表4。由表4可见:PSO-SVM模型对文山州石漠化风险的评估精度为90%,高于单独SVM模型的86%和PSO-BP模型的87%,表明本文所提出的评估模型精度更高。

表4 三种模型的评估精度(%)Table 4 Assessment accuracies of three models
3.4 文山州石漠化风险综合评估
本文采用PSO-SVM模型对文山州石漠化风险进行综合评估,经PSO算法优化的SVM模型参数为:核函数参数g=0.328 21,惩罚因子C=68.392 2。首先将GIS数据库中的经主成分分析后得到3个主分量指标导入MATLAB软件中,在MATLAB软件中运用PSO-SVM模型进行研究区石漠化风险评估;再将评估结果返回GIS数据库中,使用专题图的形式展示石漠化风险程度分布状况。文山州喀斯特石漠化风险程度综合评估结果见图8。
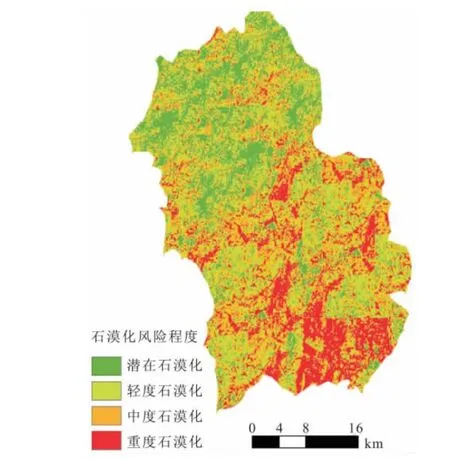
图8 文山州喀斯特石漠化风险程度综合评估图Fig.8 Comprehensive assessment of risk for karst rocky desertification in Wenshan Prefecture
由图8可以看出:从整体上看,文山州石漠化风险比较严重,需要加大综合治理的力度,遏制石漠化现象进一步向北部扩展;文山州南部的石漠化风险明显较北部严重,东西方向变化趋势不明显,其原因在于北部植被覆盖度较高,土壤裸露率和基岩裸露率较低。可见,加强植树造林、防止土壤流失对于遏制该地区石漠化扩张具有重要的意义。
4 结 论
(1)石漠化风险评估的最大难点在于原始指标数据的获取,本文获取的10个原始指标数据主要来源于遥感影像和地形图数字化,通过模型评估和野外实地调查,可以看出本文提出的评估模型可信度较高,评估结果从整体上反映了文山州喀斯特石漠化分布现状,可为该地区石漠化治理提供依据。
(2)GIS在专题图制作、空间分析和可视化方面运用广泛,而SVM在解决小样本和非线性等模式识别问题中表现出特有优势。本文将GIS技术与PSO-SVM模型有机结合起来进行喀斯特石漠化风险评估,表明该模型具有良好的模式识别和泛化能力,也表现出了优越的评价性能和空间信息展示能力,适用于对石漠化风险进行有效的评估。但同时也存在诸如SVM模型参数选取困难、计算量大、判别效率有待进一步提高等问题。
[1]中国科学院地学部.关于推进西南岩溶地区石漠化综合治理的若干建议[J].中国科学院院刊,2003,18(4):165-169.
[2]王世杰.喀斯特石漠化概念演绎及其科学内涵的探讨[J].中国岩溶,2002,21(2):101-105.
[3]王世杰,李阳兵,李瑞玲.喀斯特石漠化的形成背景、演化与治理[J].第四纪研究,2003,2(6):657-666.
[4]苏维词.中国西南岩溶山区石漠化的现状成因及治理的优化模式[J].水土保持学报,2002,16(2):29-32.
[5]周忠发.贵州高原喀斯特石漠化遥感调查研究——以贵州省清镇市为例[J].贵州地质,2001,18(12):93-98.
[6]闫满存,王光谦,刘家宏.基于GIS的澜沧江下游区滑坡灾害危险性分析[J].地理科学,2007,27(3):365-369.
[7]伊元荣,海米提·依米提,王涛,等.主成分分析法在城市河流水质评价中的应用[J].干旱区研究,2008,25(4):497-501.
[8]邓乃扬,田英杰.数据挖掘中的新方法——支持向量机(第2版)[M].北京:科学出版社,2004:25-30.
[9]Shi,Y.,R.C.Eberhart.A modified particle Swarm optimizer[A].InProceedingsofIEEEInternationalConferenceonEvolutionaryComputation[C].Anchorage,Alaska,USA,1998:69-73.
[10]Wan,V.,W.M.Campbell.Support vector machines for speaker verification and identification[A].InNeuralNetworksforSignalProcessing-ProceedingsoftheIEEESignalProcessingSocietyWorkshop[C].Sydney,Australia,2000:775-784.
[11]唐川,朱大奎.基于GIS技术的泥石流风险评价研究[J].地理科学,2002,22(3):300-304.
