基于EMD的神经网络股价预测方法∗
2014-11-07陈园园刘俊傅强
陈园园,刘俊,傅强
(中央财经大学金融学院,北京 100081)
一、文献综述
近年来,我国股票市场取得了迅猛发展,在股本、交易量、上市公司数量以及交易资金量等方面均获得了长足进步。但由于发展时间短、发展基础薄弱、受政策干扰性大等原因,目前仍是强噪音市场,表现为股价波动呈现明显的非线性、非平稳、长期记忆的特点。这也决定了股价预测的复杂性和难度。随着证券市场的发展以及投资策略研究的深入,建立适宜的股价波动模型、分解股价波动的规律,就具有了重要的理论价值和现实意义。
针对中国股市非线性、非平稳、长期记忆的特点,广大学者提出了不同的预测方法,这些研究方法主要有以下几种:
(一)多元回归和VAR模型方法
该种方法属于经典计量手段,其优点是简便与清晰易懂,其缺点则在于受主观因素影响较大。如多元回归模型简单的假设变量之间存在线性关系,VAR模型需要进行先验主观判断等都使得模型过于理想化和脱离实际。近期采用多元回归模型和VAR模型的主要研究文献有:刘海飞用VAR模型建立的股票价格模型等[1]。
(二)神经网络模型方法
神经网络试图通过模仿人脑的机能和运作流程来处理复杂数据,它能够根据训练过程中反馈的相对误差的大小来调整内部权重矩阵数据的大小,从而达到减小相对误差和使模型尽可能精确化的目的。其中,BP神经网络是最成熟也是最普及的神经网络模型之一,它由Rumelhant和McClelland(1986)提出,目前使用神经网络建立股价预测模型的学者有Han M,Xi J H[2]以及郑不谔[3]等。BP神经网络虽然克服了传统模型主观性过强的缺点,但是也有局部极小化问题及收敛速度慢、样本依赖性大、结构选择不一等缺点,在实践中往往将其与其它模型结合使用。
(三)小波分析方法
小波分析法是通过伸展平移函数使得数据在高频和低频各处都能够细化和分解。单独使用小波分析法建立股价波动模型的国外学者有Victor Lux Tonn[4]以及国内学者梁强、范英、魏一鸣[5]等。结合了神经网络系统和小波分析方法的学者有Yoshinori K[6]以及国内学者严敏、巴曙松、吴博[7]等。尽管小波分析法的分析思路非常明了,但也有很多不足,如它仅仅适用于分析平稳时间序列等。
其中,目前认可度最高的研究方法是将小波分析法嵌入神经网络建立的小波神经网络模型,由于集合了小波分析法和神经网络方法的优点,该方法的预测精度和认可度都很高。
本文在前人研究的基础上,将机械工程领域中用于处理复杂信号波的经验模态分解方法(EMD)与BP神经网络模型相结合,建立了基于EMD的神经网络股价预测方法,并通过将该方法的预测效果与小波神经网络预测方法的预测结果进行比较,得出了该方法优于小波神经网络预测方法的最好预测方法的结论。
二、基于EMD的神经网络预测方法的基本理论
EMD方法是1998年由美籍华人N.E.Huang提出的,它能将复杂信号分解成若干个相互独立且正交的若干个近似服从正态分布的平稳的本征模函数,简称为IMF分量,且分解出来的各IMF分量包含了原信号中不同波动频率的信号的特征值。IMF分量须满足以下两个条件:
1.极大值和极小值的个数之和与零点的个数相同或相差最大为1。
2.IMF分量关于时间轴对称。
(一)EMD方法的分解步骤
鉴于以上内容一个实信号的EMD的分解步骤如下:
1.找出原始数据中能够代表数据特征的极大值和极小值。
2.通过对极大值和极小值进行三阶样条函数插值或多项式拟合得到模型的上下包络线。在任意一个时刻t,都能得到一个数据的极大值x1(t)和极小值x2(t)。取极大值和极小值的均值,得到m(t)=(x1(t)+x2(t))/2。则m(t)能够反映任意时刻信号的一般水平,即m(t)代表信号x(t)的低频数据。
3.将m(t)从中扣除,得到一个新的信号,用h1(t)表示,h1(t)是一个比x(t)高频的信号,即h1(t)=x(t)−m(t)。判断h1(t)是否满足本征模函数(IMF)的条件,若满足,则定义为h1(t)=c1(t)=IMF1(t);若不满足,则将h1(t)看成是一个新的信号,并对其进行类似于对x(t)的处理,即找极大值与极小值、求包络线、求均值、扣除均值,判断是否为本征模函数,如此重复迭代k次直到hk(t)满足本征模函数的定义,提取出第一个频率最高的本征模函数(IMF),即hk(t)=c1(t)=IMF1(t)。
4.将频率最高的本征模函数从原始信号x(t)中扣除,得到剔除了高频本征模函数的低频信号r(t),即r(t)=x(t)−IMF1(t),重复上述操作(1)~(3),得到频率次高的IMF2(t)。
5.反复进行上述操作最后得到的IMFn(t)或其残余量相对于原始数据非常小;或当残余分量rn(t)是单调函数或常量时,EMD分解结束,此时x(t)可以表示成:
其中rn(t)为趋势项,x(t)代表信号的真实值或均衡值。经EMD分解后得到n个频率由高到低的本征模函数和一个残差项。实际上局部极大值和极小值很少关于时间轴对称,通常以如下式子作为判断分量是否满足IMF定义的条件中δ为临界值,取值一般为0.2到0.3之间。
(二)基于EMD的神经网络预测模型
以EMD方法分解得到的各分量为输入变量,以股价预测值为惟一输出变量,通过反复模拟得出实现相对误差最小化的最佳隐含层个数,即可得到最终的基于EMD的神经网络预测模型。
三、实证研究
(一)数据采集与研究方法
本文选取2011年1月4日至2013年3月31日我国上证综合指数(000001)各交易日的日收盘价共542个有效样本数据为研究对象,以2011年1月4日至2013年3月19日共534个数据为样本数据,建立了基于EMD和神经网络的预测模型,并以2013年3月20日至2013年3月31日共8个数据作为检验数据用于模型的检验。
(二)数据性质检验
由检验结果可知,2011年1月4日至2013年3月31日我国上证综合指数时间序列的偏度为0.5148>0,峰度为2.2059<3,因此,其分布显著偏离正态分布,且上证综合指数的ADF统计量值-1.53245小于临界值-2.86665,统计值落在置信区间以内,表明上证综合指数的时间序列数据并非平稳序列。由此也就排除了利用多元线性回归、VAR模型等传统方法的可能性,因为这些模型对数据的平稳性有着硬性的要求。与些方法相比,EMD方法和BP神经网络能突破这一限制,适用于处理该复杂的股价信号波。
(三)EMD分解结果
1.IMF分量和残差项的统计性质
(1)数据统计特征
对样本数据运用EMD方法进行处理,得到相关分量走势和性质如图1和表1所示。
由分解结果可知上证综指样本周期内两个方面的波动含义:
1)周期性
IMF分量的平均持续周期可以定义为样本点的个数除以极大值(极小值)点的个数来表示。经计算,各IMF分量的平均持续周期分别为1.32、14.56、24.03、36.87、89.46和367.81天。如果把1个月以内看作短期,1个月到1年看作中期,1年以上看作长期的话,显然,分量IMF1~IMF3为分解出的高频部分,代表一个月以内的短期市场波动因素;分量IMF4~IMF6为分解出的中频部分,代表一个月以上的中期市场波动因素;残差项RESID为原始数据剔除短中期干扰因素之后的趋势项。
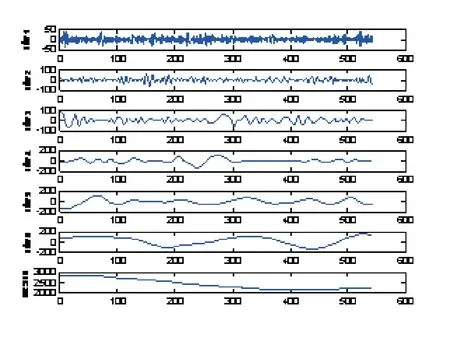
图1 EMD分解图
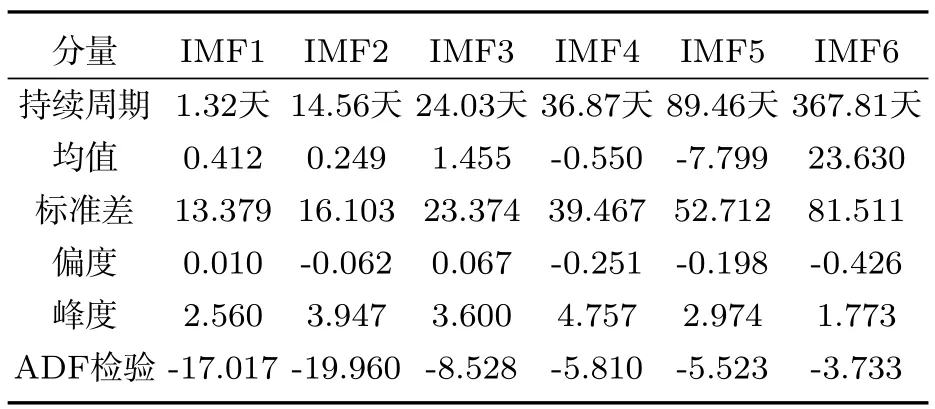
表1 各IMF分量的频率状况图
2)正态性和平稳性
从各IMF分量的统计特征来看,分量IMF1~IMF6的均值并非为0,但相对于总2 000多点的指数总点数而言,已经小到可以忽略不计,且其偏度和峰度都接近于0和3,且满足而各IMF分量近似服从标准正态分布,且经平稳性检验知,各IMF分量的ADF检验的t值均小于置信度为5%的临界值-2.866683,表明数据均落在置信区间外,即各IMF分量均为平稳数据。这些都印证了EMD方法可以将非平稳序列分解成若干相互独立且正交的平稳序列的结论。
(2)各IMF分量以及残差项对模型的解释能力
各IMF分量以及残差项对上证综合指数的解释能力可以用与指数的关联性和对指数方差的贡献度两个方面分析,分析结果如下:
1)IMF1~IMF3分量与上证综合指数的相关性分别是0.005、0.004和0.006,其方差的贡献度分别为 0.003、0.004和0.008,且均未通过显著性水平为5%的t检验和p检验,表明代表短期影响因素的IMF1~IMF3分量对上证指数的解释能力不大,说明短期因素对综合指数的影响可以忽略。
2)IMF4~IMF6分量与上证综合指数的相关性分别为0.021、0.008和0.282,其方差的贡献度分别为0.022、0.039和0.093,表明代表中期影响因素的IMF4~IMF6分量对股价指数的解释能力较强,因而中期因素的影响不容忽视。
3)残差项RESID与上证综合指数的相关性达到了0.841451,对指数样本方差的解释能力达到了0.8328,表明它完全可以代表股价的长期变化趋势,可以体现指数的真实价值和均衡价值。
2.各IMF分量以及残差项RESID代表的经济意义
(1)趋势项
如上所证,残差项RESID是上证综合指数波动的最主要决定因素;由图2也可知,剔除了短中期波动因素的残差项与上证综合指数的拟合度很高,完全可以代表上证综合指数的长期波动趋势以及指数的均衡价值和真实价值。

图2 残差项与上证综合指数趋势拟合图
残差项的波动方向受经济周期的影响,反映着经济的景气状况, 真正体现着股市的“晴雨表”的内涵。 如在我国上证指数波动趋势图中,2011年1月4日至2013年1月1日,我国股市一直处于持续下跌的熊市状态,说明当时经济正处于经济周期中衰退和萧条阶段,而从2013年1月开始股市呈现出持续上扬的回调状态,至2013年4月1日,应该说已经出现牛市的前兆即平底,表明经济已经逐步的走出低谷,开始回升。在现实中,如果能把短中期干扰因素从原始上证综合指数中剔除,得到残差项代表的长期趋势的大体位置,就能够判断当前的股市处于高估还是低估状态,并据此调整投资组合和投资决策,以获取最大收益。
(2)重大事件影响
分量IMF4~IMF6表示重大事件的对上证指数的影响,其持续周期长度短至1月长达1年,表明由重大事件引起的利好或利空消息难以由市场自动消化,对经济的冲击可能很大。从图3可以看出,在第200~240个交易日期间可能出现了重大的利空消息,如某个公司高管被曝出丑闻等;而在30~50个点附近出现重大利好消息,如央行调低存款准备金率等。重大事件可以解释上证综合指数91.8%的短中期波动,且尽管其影响可能持续较长,但由其引起的指数波动一般会回归到长期趋势线上。如果将每个重大事件都从原始信号中分解出来,并计算出对经济的影响,就可以为预测类似事件对经济造成的冲击提供参考。
(3)短期市场波动因素
分量IMF1~IMF3代表其它短期市场波动因素。例如某短期市场供求变化导致的该公司股价和综合指数的变化。由于长期内市场供求会再次达到均衡,公众也会调整他们对公司价值的评估值,因而此类因素导致的股价指数的波动既是不可持续的,又不会过于剧烈。短期投机者可以通过分析这些代表短期影响因素的分量IMF1~IMF3,对短期内股指波动趋势进行判断,并据此获得超市场的利润。
3.各IMF分量与MAR的关系比较
为进一步探索IMF分量在现实中的真正含义,以与上证综合指数相关性和对其方差的解释程度最强的分量IMF5和IMF6为例进行以下操作:
(1)将上证综合指数进行了90步和365步的移动平均,得到代表上证综合指数期限为3个月和1年的趋势值,记为MA(90)和MA(365)。
(2)将上证综合指数的534个样本数据与其对应日期的MA(90)和MA(365)相减得到去除了短中期趋势的上证综合指数的波动值,记为MAR(90)和MAR(365)。
(3)将波动值MAR(90)和MAR(365)与IMF5和IMF6进行Granger检验,并画出拟合图。Granger检验结果如表2所示,拟合结果如图3和4所示。
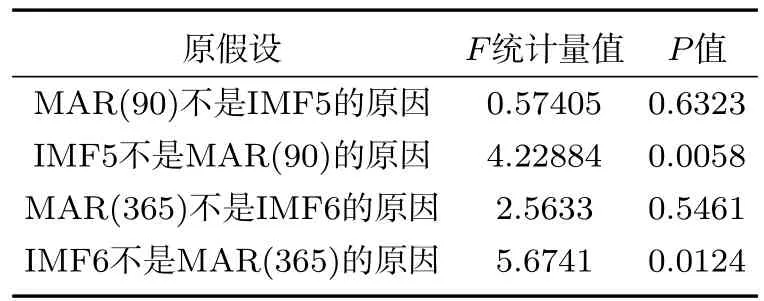
表2 变量关系检验
由表2可以看出,对MAR(90)与IMF5进行因果检验的P值分别为0.6323和0.0058,表明原假设1为假命题,而原假设2为真命题,即IMF5为MAR(90)的原因,而MAR(90)不是IMF5的原因,同样可得出IM F6为MAR(365)的原因,而MAR(365)不是IMF6的原因的结论。
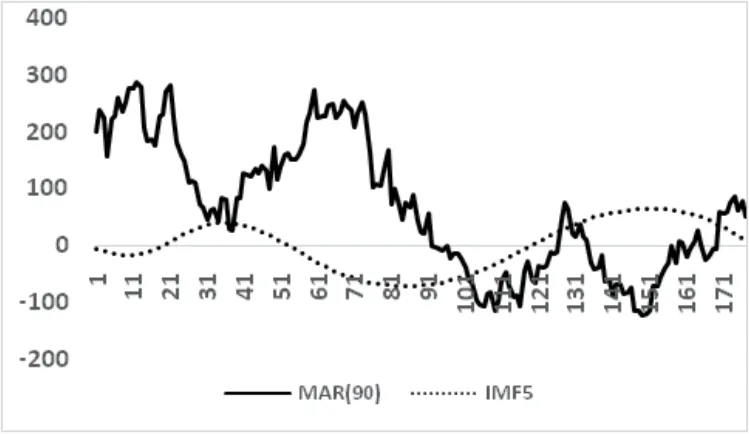
图3 IMF5与MAR(90)的拟合图

图4 IMF6与MAR(365)拟合图
由图3和图4也可知,分量IMF5、IMF6与波动值MAR(90)和MAR(365)的变动趋势大致相同,但波动值MAR(90)和MAR(365)的变动更为剧烈,即IMF分量是导致波动值MAR发生的原因,但由于其仅仅代表特定期限的影响因素,其变动趋势图更为平滑。较之于IMF分量,MAR除了包含由特定IMF分量代表的特定期限的影响因素外,还受市场短期波动因素的干扰,因而其波动更为剧烈。
因而,关于IMF在现实中的含义,总结得出以下两个结论:
(1) 由图3、4来看,IMF分量本质就是波动值,是特定影响持续期的事件对指数产生的影响。但上证综合指数与其均线之差的波动较对应期限的IMF分量的波动更为剧烈,因为它不仅包含了IMF分量代表的特定持续期的事件对综合指数的影响,还包括了短期因素对综合指数的干扰。
(2)由格兰杰因果检验看,各特定影响持续期IMF分量是特定期间内上证综合指数变动的原因。
(四)基于EMD的神经网络预测模型的构建
1.输入层变量的选取
如上所证,股价波动的主要影响因素为分量IMF4、IMF5、IMF6以及残差项RESID,即影响周期在30天到1年的重大利空利好消息以及受经济周期影响的股价指数的长期波动趋势。为进一步验证上述结论,本文采用逐步回归法,证实了主要影响因素确实为分量IMF4、IMF5、IMF6以及残差项RESID。 因此选取EMD分解得到的分量IMF4、IMF5、IMF6以及残差项RESID为基于神经网络系统的股价波动模型输入层的四个输入变量,并分别设为x1、x2、x3、x4。
2.基于EMD的神经网络预测模型的构建
在使用神经网络模型时首先构造矩阵X=[y(t),x1(t),x2(t),x3(t),x4(t)],其中y(t)是我国上证综合指数(000001)从2011年1月4日至2013年3月31日之间每个交易日的日结算价,共542个样本数据。x1、x2、x3、x4如上所述代表分量IMF4、IMF5、IMF6以及残差项RESID四个变量。X为一个542行5列的矩阵。在数据的使用上,我们选取前534行数据作为神经网络的训练样本,后8行作为检验样本用于检验模型的有效性。在变量的选择上,我们以x1、x2、x3、x4为四个输入变量,而以各变量的前534个数据作为输入数据,以y作为惟一输出层变量,以其前534个数据作为输出数据进行反复训练,构造神经网络。在函数的选取上,输入层与隐含层以及隐含层与输出层的传递函数均设为tansig训练函数设为trainglm,学习速率初始值设为0.1,动量系数的初设值为0.9,训练目标预设为小于0.01,训练次数为10 000次,隐含层个数设置为10。由Matlab软件实际模拟结果知,当训练次数为43时,训练误差实现了小于0.01的预设目标。
3.模型的检验
为检验模型的准确性,首先,需要对模型进行校核检验。我们从隐含层为1简单神经网络模型出发,分别进行了1到10的隐含层设置的反复试验,结果如表3所示,通过比较网络误差得出当隐含层个数为2时模型的网络误差最小,也即模型最准确。
其次,对模型进行有效性检验。将最佳隐含层(2)代入模型对2011年1月4日至2013年3月19日上证综合指数的534个数据进行模拟,平均网络误差仅为0.0027,证明了模型是有效的。

表3 隐含层个数与网络误差统计表
(五)与小波神经网络预测方法预测结果比较
1.小波神经网络预测方法的实证检验
采用Matlab编程语言,以我国上证综合指数(000001)从2011年1月4日至2013年3月31日各交易日的日结算价共542个数据进行小波分析,其中前534个数据为样本数据,后8个数据为检验数据。

图5 两种方法预测结果比较
由图5可知,基于EMD和BP神经网络的预测方法所获得的预测值与真实值的拟合效果更好,其相对误差的绝对值之和为0.0027,远小于采用小波神经网络预测方法获得的预测值与真实值的相对误差的绝对值之和0.0158, 由此可得, 基于EMD和BP神经网络的预测方法是目前优于小波神经网络预测方法的处理非线性、非平稳时间序列的方法。
2.原因阐述
尽管小波分析法和EMD方法有很多相似之处,其分析思路均为通过对原始复杂信号波进行分解以挖掘其中的有用信号。但与EMD方法相比,小波分析法有很多不足之处:首先,小波分析法仅仅适用于平稳的时间序列,对于复杂且波动剧烈的时间序列数据,小波分析法显然无能为力;其次,小波分析法不能根据自身特性实现自适应的多辨分析,而且为了模拟原信号产生了许多本身不存在的虚假谐波;再次,由于分解尺度事先设定且固定不变,而真实的分解尺度在分解之前并不知道,因而不能将信号进行充分分解。
基于以上解释, 就不难理解小波神经网络预测法对我国股市解释和预测效果不如基于EMD和BP神经网络的预测方法的原因了。
四、总 结
本文创造性地将机械工程领域用于处理复杂信号波的EMD方法与神经网络模型相结合,建立了基于EMD的神经网络股价预测模型。利用EMD分解法,将我国上证综合指数2011年1月4日至2013年3月19日共534个数据进行训练分解,得到6个相互独立并正交的IMF分量,并利用逐步回归、显著性检验等方法筛选出包括IMF4、IMF5、IMF6和RESID4个变量, 并以这4个变量为输入变量,以我国上证综合指数的历史数据为惟一输出变量建立神经网络模型。继而利用2013年3月20日至2013年3月31日8个交易日的数据进行模型的检验,并通过该法与小波神经网络预测方法的比较,得出检验样本真实值与预测值的拟合程度更好,而且检验样本数据真实值与预测值的相对误差更小,说明运用EMD与神经网络方法是现阶段优于小波神经网络预测方法的处理非线性、非平稳数据的更好预测方法。
