基于改进凝聚层次聚类算法的生态环境监测采样点优选技术研究
2014-10-29彭硕,郭晨,周松,王博
彭 硕,郭 晨,周 松,王 博
基于改进凝聚层次聚类算法的生态环境监测采样点优选技术研究
彭 硕1,郭 晨1,*周 松2,王 博1
(1.井冈山大学电子与信息工程学院,江西,吉安 343009;2.井冈山大学商学院,江西,吉安 343009)
随着经济的快速发展,我国的生态环境面临着越来越大的压力,对生态环境的监测和预警是维护绿色生态环境可持续发展的重要措施。获得最为理想的生态环境数据是开展生态监测和预警的前提,而合理的采样点选择是生态环境监测中一个重要环节。本文介绍了一种对采样点进行优选的方法,首先利用数据预处理技术对初始环境监测数据进行处理,之后利用基于改进凝聚层次聚类算法对环境监测数据进行聚类,最后选出距离聚类中心最近的采样点作为优选采样点。整个处理技术简单有效,对于中小规模的生态环境监测采样点的优选具有现实意义。
环境监测;采样点;数据聚类;凝聚层次聚类
0 引言
当前,生态环境问题日益突出,对生态环境指标的监测与预警是对生态环境问题进行调查和研究的重要手段,而对研究对象的采样又是进行生态环境监测和预警的一个重要环节,这个环节出现问题或者选择不当,后续的分析工作无论多么的精确、无误,其结果都是毫无意义的,而由此得出的结果也将导致对环境状态的误判。
在生态环境监测的采样过程中,如何合理地选择采样点是获得准确而可靠的环境监测数据所必须面对的问题。以地下水采样为例,当前的采样点选取原则大都是依循水质采样技术规程[9]来实施,主要以布设采样井和使用现有民用井,在具体的采样过程中,尤其是针对小范围生态环境监测的过程中,往往都是使用现有民用井,采样人员往往需要在十几个甚至几十个候选采样点里来选择,而如何选择最具代表性的采样点,使得其能反映出该区域地下水质的典型特征,成为了采样人员的一个困扰。鉴于此,本文采取数据挖掘的一些手段对采样点进行进一步分析和处理,以建立一个更加合理和更具有代表的采样点。
本文的研究旨在利用基于凝聚层次的聚类算法对符合采样原则的采样点进行进一步优选,以选取出最具特征性的代表性采样点,并把该技术用于景区村落地下水采样点的选择上。整个处理过程简单有效,对于中小规模的生态环境监测采样点的优选具有现实意义。
1 预备知识
1.1 数据聚类
数据聚类(Data Clustering)是把待处理的数据集分割成互不相交的多个类或者簇(Cluster),这种分割出来的类是事前未知的类,各个簇之间的相异度需要保持较大,而类内部的相异度要求维持较小[8]。数据聚类可以把数据集中的数据进行识别,最终得出多个浓密和稀疏的数据区域,从而得到数据集中各种数据的总体分布情况,以及各个属性间的有趣关联[1]。
当前在数据挖掘领域中的数据聚类分为如下几种方法:划分法、层次法、基于密度的方法、基于网格的方法和基于模型的方法[3]。上述的5种方法在具体的应用过程上都存在着不同程度的限制和约束条件,有的是无法对整个数据集的数据动向进行准确的定位,有的是无法对冗余数据属性和数据对象进行清理,或者是需要有前提的簇数或者既定的分类阈值。
本文研究的数据集具有生态环境的特点,所以本文基于此特点对基于凝聚层次的聚类算法进行改进,使得算法更加适用于生态环境监测数据集的处理,从而达到更好的聚类和优选效果。
1.2 凝聚层次聚类方法
在层次法中,聚类划分是通过层次来进行的,不需要在初始输入指定要分成的簇数。层次聚类方法分为自底向上和自顶向下两种情况进行,根据这两种情况,层次的聚类方法可以进一步分为凝聚型和分裂型层次聚类[2]。
凝聚型层次聚类方法是层次方法中使用最为广泛的一种方法[5],凝聚型层次聚类是一种自底向上的聚类方法,这种方法首先是将每一个数据对象认定为一个初始簇,然后根据一些选定的规则对初始簇进行一步一步的合并,使得初始簇变得越来越大,直到所有的数据对象都包含在一个簇中,或者满足某个设定的终结条件[6]。初始簇之间的合并规则有4种,包括:单链接、全链接、平均链接和重心法[6]。
有关距离的计算常用的有三种,分别是:欧几里得距离、曼哈坦距离和明考斯基距离。最常用的是欧几里得距离,它的定义如下:

其中对象=(x1,x2,…,x),
(x1,x2,…,x)有p个属性。
2 基于改进凝聚层次聚类的采样点优选技术
基于改进凝聚层次聚类的采样点优选技术是利用凝聚层次聚类同时结合生态环境监测数据的特点对环境监测的采样点进行优选的技术。本技术首先使用数据标准化技术对初始生态环境监测数据样本集进行标准化处理,以建立起具有独立性并且属性权重适当的标准化度量数据矩阵,然后通过改进的凝聚层次聚类算法计算出结果簇的数目和簇中心,最后通过计算各个结果簇中最靠近簇中心的样本点来最终确定优选采样点的位置,处理过程如图1所示。
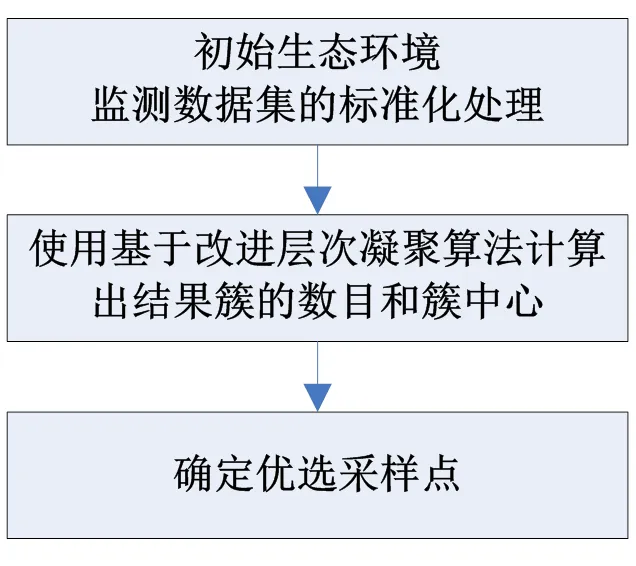
图1 基于改进凝聚层次聚类的采样点优选技术流程图
2.1 初始生态环境监测数据集的标准化
环境监测数据集的标准处理过程的第一步是要对环境监测数据库进行预处理,预处理过程包括对特征变量的选择和提取以及标准化处理。
特征变量的提取和选择主要是针对某些特定的属性和属性集合之间存在着的某种程度的相关性而进行的,处理后的环境监测数据集中只包含一些相互独立的特征属性。
同时由于初始生态环境监测数据集中各属性的取值范围和单位不同,直接影响到属性之间的权重比例,导致对最终结果产生影响。因此,要对数据集进行标准化。初始生态环境监测数据集的标准化是要给所有的属性一个合理的权重,在属性性质一致的时候通常取相同的权重,但是在一些重要属性上需要合理地提高其权重比例。
由于初始生态环境监测数据集在剔除属性相关性之后数据属性上具有相同性,所以视为具有相同权重,这种情况下只需要将原来的度量值转换为无单位的值即可。初始生态环境监测数据集需要经过以下3个步骤的变换之后转换成标准化数据集合,如图2所示。
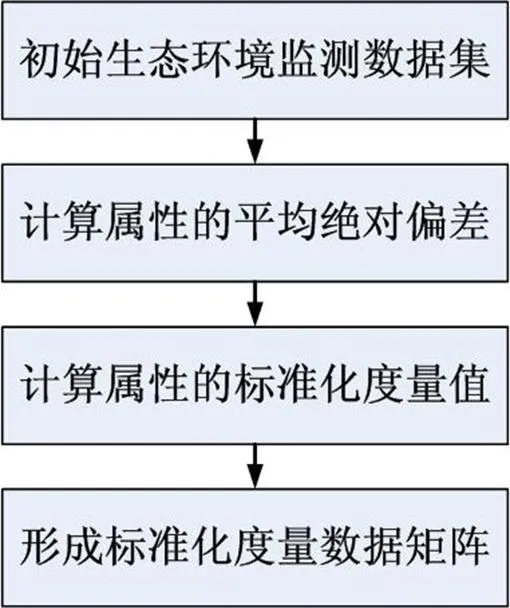
图2 数据集的标准化流程图
2.1.1 初始生态环境监测数据集
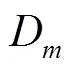
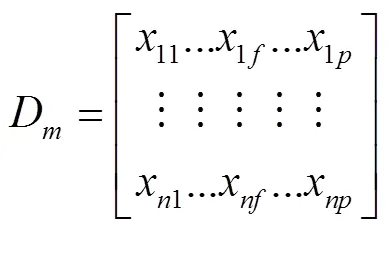
2.1.2 计算属性的平均绝对偏差
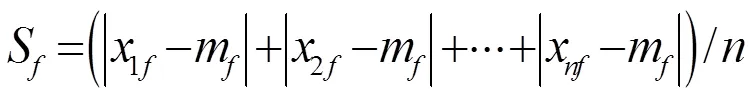
2.1.3 计算属性的标准化度量值

2.1.4 标准化度量数据矩阵
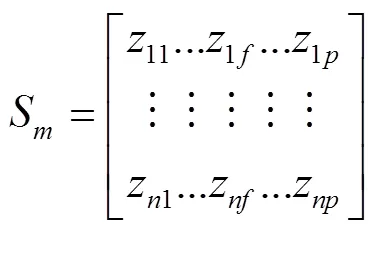
2.2 基于改进凝聚层次聚类算法的生态环境监测采样点优选技术
本文在对初始环境监测数据集进行标准化处理之后,使用改进的凝聚层次算法来对标准化数据集进行聚类。在选择凝聚层次算法的具体类型时,考虑到单链接算法计算较为简单有效,因此本文对单链接法的凝聚层次聚类算法进行改进,再把算法应用于标准化度量后的监测数据矩阵。
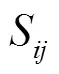
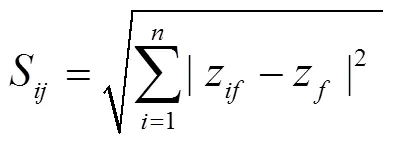
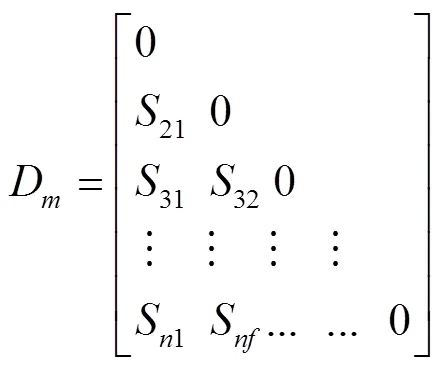
算法假设有个对象,表示为1,2,…,I这个对象需要进行数据聚类,本文提出的基于改进凝聚层次聚类算法描述如下:

Input:个对象的特征相异度矩阵Output:簇数及最靠近簇中心的数据对象 Step1:把每一个对象当成一个初始簇,即Ci={Ii}(i=1,2,…,n),这样初始就有n个簇;Step2: 将对象中相异度值Sij按升序进行排序,并组成一个三元组,其中。由于环境监测误差的存在,且相异度高于平均值是难以在同一个簇中出现,所以算法需要去除三元组中相异度最大的40%的三元组,这些三元组将不参与合并操作。Step3:把三元组中最小的两个类进行合并,合并之后的新簇记为簇,其中初始等于1。Step4:合并三元组顺序中下一组对象组,合并需要考虑以下四种情况:Case a:如果和都没有新簇中出现,那么合并组成新类,自增 1;Case b:如果和都出现在同一个新簇中则跳转到到Step5;Case c:如果和其中一个已被合并到某一新簇,则将另一个也合并到该新簇中;Case d:如果它们已分别被合并到两个不同的新簇,则将它们所在的那两个类合并成一个新簇,自增 1;Step5:取有序表中的下一个三元组,重复Step 4,直至结束。Step6:采用重心法计算出各个采样点新簇的中心点位置,然后以欧几里得距离为度量方法,计算出离采样点新簇中心点最近的采样点,并输出该采样点作为最终的优选采样点。
算法的输出是得到簇数及最靠近簇中心的数据对象,算法的聚类结果可能会存在着某一个采样点不在任何一个新簇中,这表明该采样点是一个数据孤立点,孤立点出现的原因可能是采样手段不当而导致与其他采样点的数据存在着较大偏差而不具有代表性。
3 实验
本文以井冈山区域景区村落环境监测示范点——新干县华城门村的地下水采样点环境监测数据集为例进行实验。初始采样点环境监测数据包括该示范点区域的所有地下水井的监测数据,记为A1到A32,如表1所示。监测指标采取的是国标《地下水质量标准》[7]。具体包括:pH值、总硬度、硫酸盐、氯化物、铁、锰、铜、锌、挥发酚、阴离子合成洗涤剂、高锰酸盐指数、硝酸盐、亚硝酸盐、氨氮、氟化物、氰化物、汞、砷、硒、镉、铬、铅以及总大肠菌群,同时加上采样点名称、采样点编号以及经度、纬度构成一个由27个属性组成的初始数据库。初始数据库中采样点名称和采样点编号不作为特征属性使用,也不参与到属性的优选处理过程中。
通过计算,参与属性优选处理的25个属性平均值见表1,其中经度和纬度中的度分秒表示需要统一为以度为单位,保留到小数点后7位,其中氰化物、汞、镉和铬4个属性的平均值为0,表示这4个属性没有超过检出最低限值。

表1 采样地点及编号
参与属性优选处理的25个属性的平均绝对偏差见表2,其中氰化物、汞、镉和铬4个属性的平均绝对偏差仍然为0。
通过计算属性的平均值和平均绝对偏差值,可以确定氰化物、汞、镉和铬这4个属性在整个数据库中影响力权值为0,所以在接下来的处理过程中将不进行计算和评价。
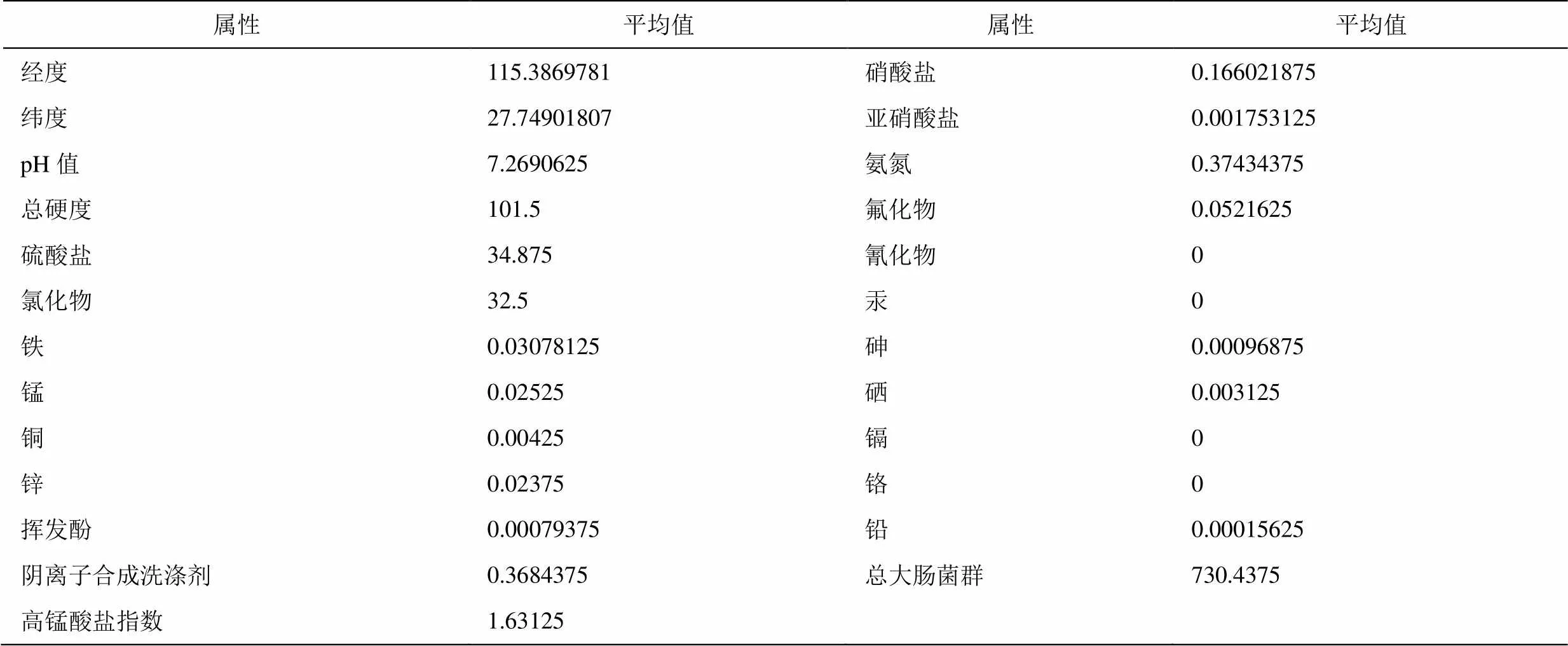
表2 初始数据库的属性平均值
参与属性优选处理的25个属性的平均绝对偏差见表3,其中氰化物、汞、镉和铬4个属性的平均绝对偏差仍然为0。
通过计算属性的平均值和平均绝对偏差值,可以确定氰化物、汞、镉和铬这4个属性在整个数据库中影响力权值为0,所以在接下来的处理过程中将不进行计算和评价。
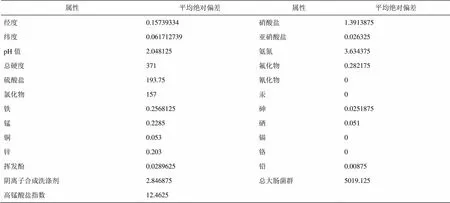
表3 初始数据库属性的平均绝对偏差
接下来根据公式3进行标准化处理和相异度计算,建立起标准化度量数据矩阵S和相异度计算,根据相异度矩阵中的每个值S相异度进行排序建立起三元组l=(c,c,S),见表4。

表4 相异度矩阵排序三元组
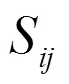
4 结束语
当前生态环境问题日益突出,生态环境监测与预警是当前的一个热点研究领域[10]。本文通过研究生态环境采样点的优选技术,提出了一种基于改进凝聚层次聚类算法的生态环境监测采样点优选技术,以技术手段对采样点的选取进行合理性的精确定位,从而保障了数据的代表性和可靠性。
[1] 冯治宇.网格采样—聚类分析在优化环境监测点中的应用[J].环境工程,2003,21(2): 55-58.
[2] 李娜,钟诚.基于划分和凝聚层次聚类的无监督异常检测[J].计算机工程,2008,34(2): 120-123.
[3] 尉景辉,何丕廉,孙越恒.基于K-Means 的文本层次聚类算法研究[J].计算机应用,2005,25(10): 2323-2324.
[4] Han J,Kamber M.数据挖掘概念与技术[M].范明,孟小峰译.北京:机械工业出版社,2004.
[5] 王洋,涂登彪,安明远,等.层次凝聚聚类算法的动态分析与准则函数设计[J].高技术通讯,2013,22(11): 1169- 1175.
[6] 陈亚平,吴陈.FCM聚类算法与改进层次聚类算法的结合[J].科学技术与工程,2009(17): 5008-5011.
[7] GB/T14848-93.地下水质量标准[S].1993
[8] 冷明,孙凌宇,郁松年.无向赋权图剖分优化问题的研究进展[J].井冈山大学学报:自然科学版,2010,31(1):82-90
[9] SL187-96.水质采样技术规程[S].1996.
[10] 王博,万春,周松,等.基于模糊数学的景区村落生态环境评价技术研究[J].井冈山大学学报:自然科学版, 2014,35(3):59-63.
RESEARCH ON SELECTION OF PREFERRED ECOLOGICAL ENVIRONMENT MONITORING SAMPLING POINT BASED ON AN IMPROVED HIERARCHICAL AGGLOMERATIVE CLUSTERING ALGORITHM
PENG Shuo1,GUO Chen1,*ZHOU Song2, WANG Bo1
(1. School of Electronic Information and Engineering,Jinggangshan University,Ji’an, Jiangxi 343009,China;2.School of Business, Jinggangshan University, Ji’an, Jiangxi 343009, China)
With the rapid development of economy in our country, ecological environment is becoming more and more stressful.Environmental monitoring and early warning on the environment are important aspects to maintain the ecological green and sustainable development. In order to get the most optimal ecological environment data under limited conditions,we should carry out a reasonable selection of a preferred sampling point. Therefore, the selection of a preferred environmental monitoring sampling point is an importantpart of ecologicalenvironmental monitoring. Initial environment monitored data is processed first by usinga series of data preprocessing techniques. Therefore, environment monitored data is clustered by using a clustering algorithm based on improved agglomerative hierarchy. Finally, a sampling pointclosest tothe cluster center is selected as a preferred sampling point. The whole processis simple and effective and has arealistic significance for selecting a preferred sampling point during a small and medium scale ecological environment monitoring.
environmental monitoring; sampling point; data clustering; hierarchical agglomerative clustering
X830.1
A
10.3969/j.issn.1674-8085.2014.06.011
1674-8085(2014)06-0048-06
2014-05-11;
2014-09-15
国家科技支撑计划项目(2012BAC11B03);江西省科技支撑计划项目(20123BBG70221)
彭 硕(1982-),男,江西吉安人,讲师,硕士,主要从事计算智能,数据挖掘等研究(E-mail: pengshuo@jgsu.edu.cn);
郭 晨(1979-),男,江西泰和人,副教授,博士生,主要从事算法优化研究(E-mail: 519670255@qq.cm);
*周 松(1964-),男,江西吉安人,教授,主要从事环境监测,科技管理等研究(E-mail: zhousong@jgsu.edu.cn);
王 博(1980-),男,江西吉安人,讲师,硕士,主要从事神经网络计算研究(E-mail:ganjgszs307@163.com).
