基于纹理分解的变换域JND模型及图像编码方法
2014-10-27郑明魁苏凯雄王卫星兰诚栋杨秀芝
郑明魁,苏凯雄,王卫星,兰诚栋,杨秀芝
(福州大学 物理与信息工程学院,福建 福州 350108)
1 引言
最小可觉察误差(JND,just noticeable distortion)[1]用于表示人眼不能察觉的最大图像失真,体现了人眼对图像改变的容忍度。在图像处理领域,JND可以用来度量人眼对图像中不同区域失真的敏感性。近年来,JND模型在基于视觉特性的视频图像编码[1,2]、数字水印[3]、图像质量评价[4]等方面受到广泛关注。目前已有多个JND模型被提出,这些JND模型主要可以分为2类:基于像素域的JND模型和基于变换域的JND模型。
像素域 JND模型能在像素域上更为直观地给出JND阈值,在视频编码时常常用于运动估计以及预测残差的滤波。Yang等人提出了经典的非线性相加掩蔽模型(NAMM,nonlinear additively masking model)[1],该方法兼顾了亮度自适应掩蔽和对比度掩蔽的重叠效应。Liu等人在NAMM 模型的基础上,通过全变分(TV,total variation)分解对图像中的纹理以及结构分量赋以不同加权值,使像素域JND模型具有更好的计算精度[5]。Wu等人则在计算纹理掩盖时进一步考虑了人眼对规则区域与非规则区域不同的敏感性,提出一种基于亮度自适应与结构相似性的JND模型[6]。
变换域 JND模型可以方便地把对比度敏感函数(CSF,contrast sensitivity function)引入模型中,具有较高的精度。由于大多数的图像编码标准都采用了DCT变换,因此基于DCT域的JND模型得到了很多研究者的关注。Ahumada等人通过计算空域CSF函数得到灰度图像的JND模型[7],在此基础上,Watson提出了DCTune方法,进一步考虑了亮度自适应、对比度掩蔽等特性对 JND的影响[8]。Zhang等人通过加入亮度自适应因子和对比度掩蔽因子,使得 JND模型具有更高的精度[9]。Jia等人将物体的运动等因素引入到JND模型中,提出了一种更精确的视频图像JND模型[10]。Wei等人则将伽马校正引入到JND模型,提出新的亮度自适应和对比度掩蔽因子计算方法[11]。Ma等人在Wei的基础上提出自适应块大小的JND模型,将通常8×8尺寸的JND模型扩展到16×16[12]。最近,Luo等人把Wei的JND模型推广到4×4,并用于扩展基于H.264的视觉特性视频编码[13]。
变换域 JND模型需要考虑人眼对不同亮度以及对比度掩盖等特性的敏感度,在计算对比度掩盖时使用Canny滤波来判断区域的类型并赋予不同的加权值,由于Canny算子主要用于边缘检测,这种方法在计算纹理区域的 JND时存在误判低估的问题。为了提高JND阈值的估计精度,本文采用一种预先纹理分解的方法,使用了纹理分量计算对比度掩盖因子并与其他模型进行仿真对比;为了去除更多的视觉冗余,提高图像编码效率,本文把改进的JND模型用于图像编码,考虑到编码的兼容性以及辅助信息对编码效率的影响,设计了一种基于JND模型的量化方法;最后通过理论分析与仿真对本文的编码方法与JPEG等编码方法进行对比。
2 变换域JND模型
基于DCT变换域的JND模型描述为空间对比度敏感函数、亮度自适应因子和对比度掩盖因子三者的乘积[9],为
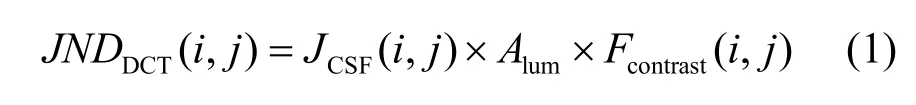
其中,JCSF(i,j)是空间对比度敏感函数,体现了索引号为(i,j)的DCT系数基本的JND阈值,其计算公式为[11]

其中,s表示集合效应;φi、φj分别表示DCT归一化系数;ωij为DCT系数的空间频率;r+(1-r cosφij)代表人眼的倾斜效应;φij代表相应DCT系数的方向角。本文中取s=0.25,r取经验值0.6。
式(1)中的Alum是亮度自适应加权因子。亮度自适应掩蔽效应使人眼对图像中的不同亮度区域敏感度不同。亮度自适应加权因子Alum与局部区域的平均亮度有关。具体为
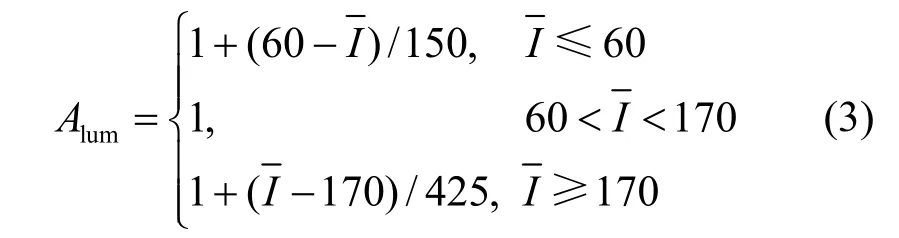
Fcontrast(i,j)是对比度掩盖加权因子,考虑到子带系数自身的掩盖效应,最后得到的对比度掩盖加权因子如式(4)所示[11]。
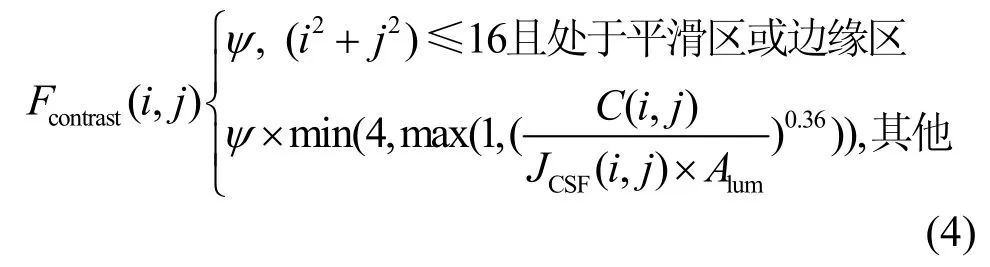
计算对比度掩盖加权因子时先将图像块划分成3类:平滑区、边缘和纹理区,然后对不同的区域进行不同的加权。其中,平滑与边缘区域的加权ψ=1;由于人眼对纹理区域低频系数的敏感度相对较小,因此加权系数ψ=2.25,而高频系数的加权ψ=1.25。
3 基于纹理分解的变换域JND改进模型
在计算对比度掩盖加权因子 Fcontrast(i,j)时,首先对图像进行Canny滤波获得各分块的边缘像素,通过计算边缘像素的分布情况划分区域类别,通常情况下平滑区域的边缘像素较少,而纹理区域的边缘像素较多,其划分的方法如式(5)所示[11~13],其中,ρedgel表示边缘像素在整个分块中的比例。
Canny滤波主要用于边缘检测,通过搜索局部邻域内的像素变化强度获得边缘像素,它并不是专门针对区域划分而设计[5]的。在实现Canny滤波的过程中,算法对图像进行高斯平滑滤波以及计算图像的梯度幅值和方向后,为了保证边缘的精确定位,使用了非极大值抑制的方法,将其他非局部极大值的像素清零以得到细化的边缘。这个过程就使许多纹理区域的像素也被清零,将影响纹理区域判别的准确性。由于纹理区域能够容纳更多的视觉误差,其JND阈值也相对较大,如果该区域被错误划分,JND阈值将被低估。
由于人眼对平滑与边缘区域比较敏感,它们的加权是相同的,提高JND阈值估计主要依靠纹理区域的精确划分。为了更精确地划分区域类型,本文使用了纹理分解的方法,只对分解获得的纹理分量进行Canny滤波,减少边缘像素的影响,提高了JND的计算精度。基于总变分的结构纹理分解方法,采用边界变分函数和振荡函数分别模拟图像的结构信息和纹理信息,通过求解边界变分函数的空间最小化问题来有效的分解图像,因此,在图像的结构纹理分解中受到广泛关注。本文正是采用基于总变分的结构纹理分解方法,如式(6)所示[14],其中f为原图像,u为图像的结构分量,主要包含平滑以及轮廓边缘信息;v=f-u则体现了图像的纹理分量,以一阶范数的形式作为保真项。经过纹理分解后的图像如图1所示,其中,图1(c)为图像的纹理分量。
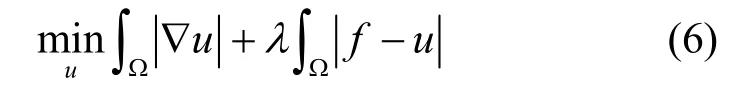

图1 基于TV-L1的结构纹理分解示意
使用Canny算子分别对原图像与纹理分量进行滤波,如图2所示。由图2(a)可以看出,Lena图像的头发区域在采用Canny算子直接对原图像进行滤波时,许多纹理像素被清零,有些区域将被误判为非纹理区域;图2(b)采用纹理分量滤波的方法,结构纹理分解使图像减少了边缘像素的干扰,这些区域保留着较多的纹理像素;图2(c)与图2(d)分别为不同方法的纹理判别结果,白色区域表示纹理部分,由图2(d)可知采用纹理分量滤波的方式提高了判别的精确度,避免了JND低估的问题。

图2 纹理分量Canny滤波示意
图3为基于纹理分解的变换域JND改进模型的计算流程,在计算空间对比度敏感函数与亮度自适应因子时采用了传统的方法,但在计算对比度掩盖Fcontrast(i,j)时,先对图像进行纹理分解,然后对纹理分量v进行Canny滤波和区域划分,计算出更精确的Fcontrast(i,j),最后使用式(1)获得JND阈值。

图3 基于纹理分解的变换域JND改进模型流程
4 改进模型的性能仿真与测试结果
在相同的视觉质量下,获得的JND阈值越大,其性能越好。为了评估 JND模型的优劣,通常将JND值作为噪声加入到原始图像中,如式(7)所示。其中,C(k,i,j)表示原始图像第k个分块在(i,j)索引处的DCT系数,J ND(k,i,j)为该系数对应的JND阈值,Srandom随机取+1或者−1,CJND(k,i,j)为加入噪声后的DCT系数。

性能较好的 JND模型在相同的视觉质量下应能容忍更多的噪声,即允许更多噪声加入原始图像中。一般用峰值信噪比(PSNR,peak signal to noise ratio)来表征加入噪声的大小,JND阈值越大,所加入的JND噪声能量越多,加噪后图像的PSNR就越小,JND模型就越接近于视觉特性。
对本文所提出的变换域 JND改进模型进行仿真分析,并与其他变换域模型进行比较。仿真中使用了 10张不同内容与空域复杂度的测试图像,如表1所示。仿真时把JND阈值作为噪声,随机加入到原始图像中。Wei等人提出的JND模型与DCTune模型以及Zhang的模型相比,能容纳更多的噪声,对于512×512的图像平均PSNR分别下降了0.61 dB与0.90 dB,同时获得更好的视觉质量[11]。文献[12]与文献[13]也是基于Wei的模型,但把DCT的块尺寸分别扩展到4×4与16×16,本文的模型面向常见的 8×8尺寸,因此主要与文献[11]的模型对比。由表1第2列与第3列数据对比可以看出,本文所提出的改进模型与文献[11]所提出的JND算法相比,平均PSNR下降了0.479 dB。
图4显示了Lena图像在不同模型下的JND阈值,图4(c)为本文模型增加的纹理区域,由图中可知,在平坦区域,2种算法的JND相同,但是改进模型能精确判断更多的纹理区域,相应区域的JND阈值也随之增加。

图4 不同模型JND阈值对比
本文进一步对加噪处理图像进行主观质量测试,把改进的模型与文献[11]的模型进行比较。比较时,将经过加噪的图像分别显示在显示器左右两侧。为了避免可能产生的偏见,两幅图像的显示位置是随机产生的,并且 10幅图像的显示次序也是随机的。实验采用LG W1942SY显示器,观测者距离为显示高度的4倍。观测人数10人,其中3人为女性。所有观测者被要求对图像进行评分,评分标准如表2所示。表1第3列给出了观测者对各图像的平均得分,负值表示本文提出的模型观测质量优于其他模型,正值则相反;得分越接近零,表示视觉质量越接近。
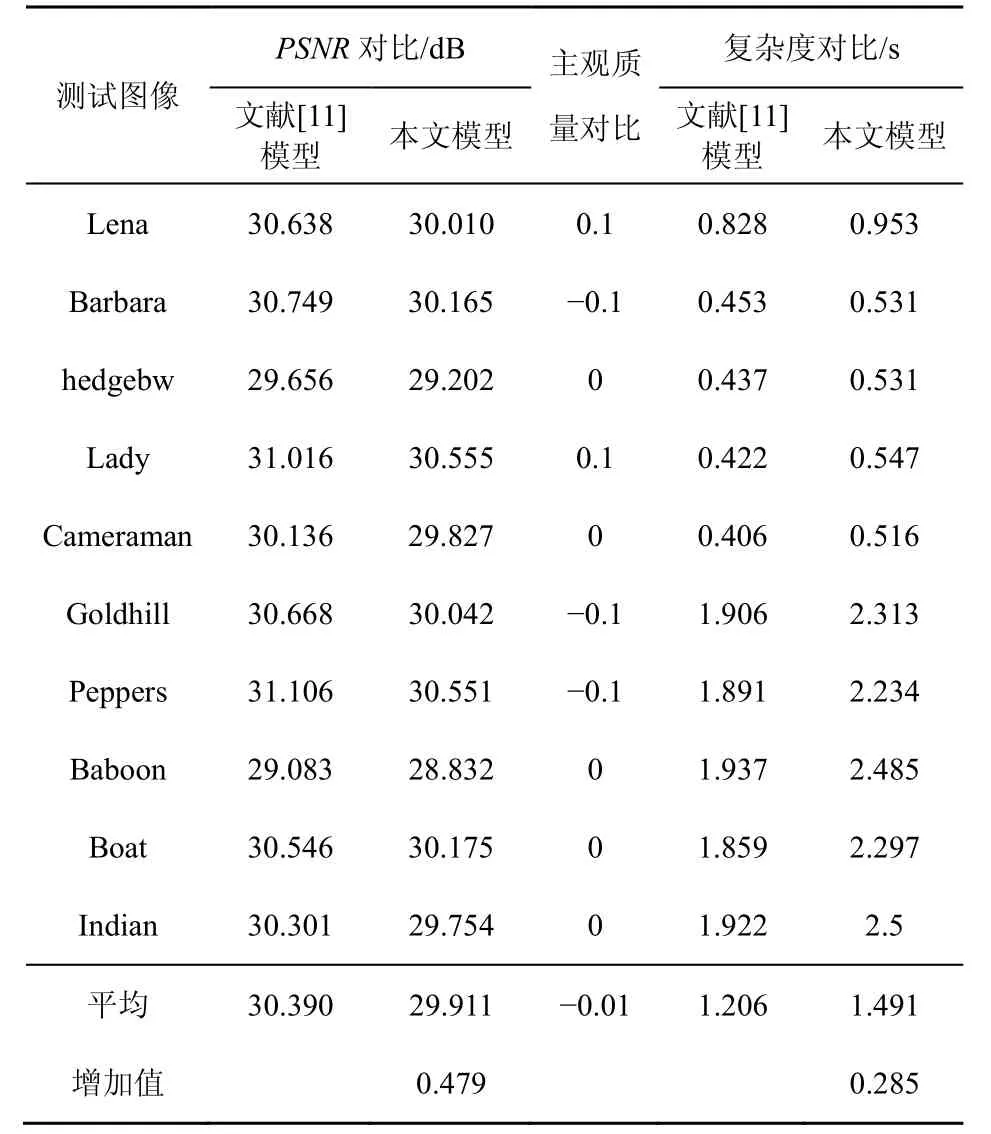
表1 本文模型与文献[11]对比

表2 主观质量评分标准
由表1可以看到,本文所提出的模型与文献[11]提出的模型相比,主观评价质量非常接近,平均质量稍好于文献[11],主要原因在于本文的算法主要改进纹理区域的JND,人眼对这些区域的敏感度较低,可以容纳更多的噪声,在JND阈值提高的同时人眼不会感觉到图像的变化;同时,只对纹理分量进行滤波判断,减少了边缘像素的影响,避免了某些边缘区域可能被误判为纹理而使 JND阈值高估的情况,由于人眼对边缘区域比较敏感,这种方法将减少误判的机率。图5分别给出了利用本文模型与文献[11]模型加噪处理后的Lena测试图像,从主观上观察,两者质量非常接近。

图5 利用文献[11]模型以及本文模型加噪处理后的Lena测试图像
由于本文的算法在计算JND阈值时,需要先对图像进行纹理分解,因此在计算复杂度上有所增加。仿真实验基于酷睿i3-530,CPU主频为2.93 GHz,2G内存,仿真软件采用Matlab 7.11.0版本。由表1第5列与第6列数据对比可以看出,本文所提出的改进模型与文献[11]的算法相比,平均时间增加了0.285 s,而且图像尺寸越大,纹理分解需要的时间也越多,计算复杂度也相应增加。
由以上的实验可知,本文提出的改进模型能容忍更多的噪声,在相同的主观质量下,能够去除更多的视觉冗余,经过噪声处理后图像的PSNR也更低,与文献[11]所提出的JND算法相比,平均PSNR下降了0.479 dB。
5 基于JND模型的图像编码算法研究
目前的图像视频编码标准主要建立在香农信息论基础之上,用概率统计模型描述信源,其压缩思想主要从去除数据冗余方面出发,较少考虑视觉上的冗余特性。文献[15]引入人类视觉特性,对不同的 DCT系数进行加权,设计了一种基于视觉特性的量化表,该算法在相同的PSNR下比JPEG节省更多的码率。本文尝试将改进的变换域JND模型用于JPEG图像编码。由于人眼对不同类别区域的敏感度不同,因此可以将体现敏感程度的JND阈值结合到量化过程中,在不同敏感区域使用不同的量化步长。
对于量化步长Q,其最大的量化误差为Q/2;如果进一步考虑了视觉冗余,在视觉质量不变的情况下量化步长可以适当增加为Q+ΔQ,其对应的最大的量化误差为Q/2+ΔQ/2。与原来的误差相比,考虑视觉冗余增加量化步长后产生的误差增加了Δ Q/2,如果误差增加量ΔQ/2没有超过JND阈值,人眼将不会觉察到这个变化。即要求

最后得到的量化步长为

由于不同内容图像的JNDDCT(i,j)不同,为了能正确解码,需要将体现 JNDDCT(i,j)的辅助边信息加入到码流中,这会使压缩码率增加,同时不兼容原有的编码标准。为了减少辅助边信息的传输,本文考虑对 JNDDCT(i,j)进行适当调整。JNDDCT(i,j)与空间对比度敏感函数、亮度自适应因子和对比度掩盖三者有关,其中空间对比度敏感函数JCSF(i,j)与图像的内容无关,解码端可以预先获得,因此JCSF(i,j)不需要加入码流;亮度自适应因子Alum与平均亮度有关,而 DCT系数的直流分量直接体现了平均亮度的水平,式(10)表示了JPEG编码标准中DCT直流系数DC与平均亮度的关系,其中,N=8,为图像分块的尺寸。为了减少辅助信息的传输,对直流系数 DC量化时 JND只采用视觉基本阈值JCSF(i,j)部分的值,这样不需要传输相关的数据解码器就可以很方便地获得直流分量,用式(10)计算出平均亮度后,就可以获得亮度自适应因子Alum。

对比度掩盖加权因子 Fcontrast(i,j)与图像块的区域划分有关,将纹理区域的加权系数统一调整为ψ=1.25,并忽略子带系数自身的掩盖效应,这种调整会使JND阈值减少,但是也减少了辅助边信息的传输。由于平滑区域与边缘区域的加权都是ψ=1,纹理区域的加权系数都统一为ψ=1.25,因此每个块在编码时只需要额外增加块区域类型信息就可以使解码端计算出 Fcontrast(i,j)。在JPEG编码标准中,每个块经过哈夫曼编码以后都会以EOB结尾,标准表中亮度系数的EOB为1010,实际上块区域类型信息可以与EOB 一起判断,根据霍夫曼编码的唯一性原则选取了另一个码值1001[16]与1010联合判断,其中1010表示当前块为边缘或者平坦区域,1001则表示当前块为纹理区域。这种编码方法使编码端在不需要增加任何比特数据的同时把块区域类型信息嵌入到码流,解码端很容易从改进的 EOB信息中判断出块类型并计算出量化步长。
对10张测试图像分别使用JPEG基本系统,文献[15]以及本文改进的编码方法进行压缩,其中256×256与512×512尺寸各5张,JPEG编码采用缺省的亮度信号量化表,本文的量化步长在缺省量化表的基础上利用式(9)计算,编码结果如表3所示。由于随着图像尺寸的增加,JND阈值也会提高[11],量化步长的增加使得本文算法对512×512图像的压缩性能提高稍大一些,与JPEG编码相比本文的算法平均码率减少了 14.7%,与文献[15]相比本文算法平均码率减少了10.7%。

表3 JPEG编码算法、文献[15]以及本文编码算法码率对比
PSNR在评价图像质量时不能体现人眼的视觉特性,本文将不同编码方法的重构图像使用基于结构相似度(SSIM,structural similarity)的评价方法进行客观质量对比[17],如表4所示。SSIM模型通过计算图像亮度、对比度和结构的相似性来度量图像质量的好坏,SSIM值越接近1则图像的质量就越好,由表4可知本文编码方法的重建图像与JPEG以及文献[15]的编码重建图像非常接近,虽然SSIM值稍小一些,比JPEG标准平均减少了0.013,比文献[15]的重建图像平均减少0.014,但并不意味着实际的主观图像质量就偏差,因为SSIM算法主要考虑图像的结构相似性,较少考虑到人眼对不同类型区域的敏感性。进一步对重构图像的主观质量进行测试,把改进算法的重构图像分别与JPEG编码以及文献[15]进行比较,测试方法与之前的主观评价实验类似,结果如表4第5列与第 6列所示,3种编码方法的重构图像主观质量非常相近。图 6为Lena图像使用不同编码算法后的重构结果,本文算法所获得的重构图像与 JPEG非常接近,但是码率下降了13.6%,与文献[15]相比码率减少了9.7%。因此,本文提出的基于JND模型的图像编码方法在节省更多码率的同时仍然保持了相似的视觉质量。
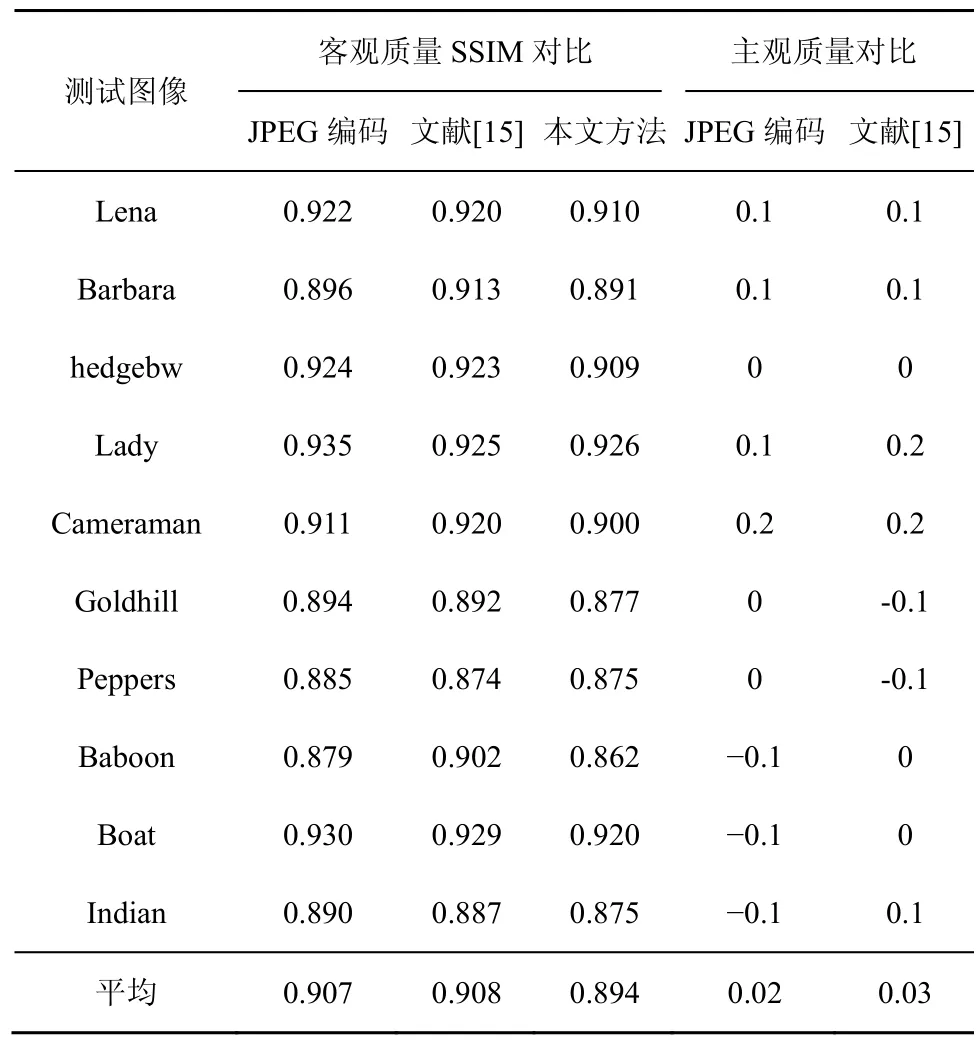
表4 JPEG、文献[15]以及本文编码算法重构图像质量对比

图6 JPEG编码、文献[15]以及本文编码算法重构图像对比
在编码复杂度方面,本文的方法对不同的图像编码时需要先计算JND阈值,因此编码时间有所增加,仿真结果如表5所示。与JPEG编码标准相比,本文算法编码时间平均增加16.7%左右;由于文献[15]需要对不同的DCT系数进行加权相乘,因此与文献[15]相比本文算法增加了 7.9%的编码复杂度。

表5 JPEG编码算法、文献[15]以及本文编码算法复杂度对比
6 结束语
变换域 JND模型主要与人眼对图像的频率敏感度以及掩蔽特性等因素有关,具体由基本视觉阈值、平均亮度以及对比度掩盖因子3个方面组成。对比度掩蔽使得人眼对纹理区域的噪声容忍度相对较高,而对平坦区域以及边缘区域的噪声比较敏感。本文在计算对比度掩盖因子时先对图像进行结构纹理分解,然后只对纹理分量滤波并判断区域类型,这种方法去除了边缘像素的干扰,提高了对比度掩盖因子计算的精度。仿真实验表明,本文的方法能获得更高的 JND阈值,平均减少视觉冗余达到0.479 dB。
本文在改进JND模型的基础上,将其用于静止图像编码,设计了一种基于JND模型的量化方法。考虑到编码的兼容性以及辅助信息对编码效率的影响,在量化之前对JND模型进行折中处理,虽然会使JND阈值有所下降,但总的码率得到较大的提高。仿真结果表明,与JPEG编码标准相比,本文的算法在相似的视觉质量下能去除更多的视觉冗余,并且不需要增加额外的比特数据,同时保持与JPEG编码标准的兼容,能平均节省码率 14.7%左右。由于本文编码方法需要计算图像的JND阈值,因此在计算复杂度上还有待改进。该编码思路不仅适用于静止图像编码,也可以用于基于视觉特性的视频编码,在下一步的研究中,拟将该方法用于下一代的高效视频编码标准HEVC中,以进一步提高HEVC的编码效率。
[1]YANY X K,LIN W S,LU Z K,et al. Just noticeable distortion model and its applications in video coding[J]. Signal Processing: Image Communication,2005,20(7):662-680.
[2]MATTEO N,FERNANDO P. Advanced H.264/AVC-based perceptual video: coding: architecture,tools,and assessment[J]. IEEE Transaction on Circuits and Systems for Video Technology,2011,21(6):766-782.
[3]PHIBANG N,BEGHDADI A,LUONG M. Perceptual watermarking robust to JPEG compression attack[A]. Proceedings of the 5th International Symposium on Communications Control and Signal Processing[C]. Rome,Italy,2012.1-4.
[4]HSU M C,WU G L,CHIEN S Y. Combination of SSIM and JND with content-transition classification for image quality assessment[A]. Visual Communications and Image Processing (VCIP)[C]. San Diego,USA,2012.1-6.
[5]LIU A,LIN W S,PAUL M,et al. Just noticeable difference for image with decomposition model for separating edge and texture regions[J].IEEE Transaction on Circuits and Systems for video Technology,2010,20(11):1648-1652.
[6]WU J J,QI F,SHI G M. Self-similarity based structural regularity for just noticeable difference estimation[J]. Journal of Visual Communication and Image Representation,2012,23(6):845-852.
[7]AHUMADA A J,PETERSON H A. Luminance-model-based DCT quantization for color image compression[A]. Hum. Vision Visual Process. Digital Display III[C]. 1992.365-374.
[8]WATSON A B. DCTune: a technique for visual optimization of DCT quantization matrices for individual images[A]. Proceedings of Society for Information Display Digest of Technical[C]. San Diego,USA,1993.946-949.
[9]ZHANG X H,LIN W S,XUE P. Improved estimation for just- noticeable visual distortion[J]. Signal Processing,2005,84(4):795-808.
[10]JIA Y,LIN W S,KASSIM A A. Estimating just noticeable distortion for video[J]. IEEE Transactions on Circuits and Systems for Video Technology,2006,16(7):820-829.
[11]WEI Z Y,NGAN K N. Spatio-temporal just noticeable distortion profile for grey scale image video in DCT domain[J]. IEEE Transactions on Circuits and Systems for Video Technology,2009,19(3): 337-346.
[12]MA L,NGAN K N. Adaptive block-size transform based just-noticeable difference model for images/videos[J]. Signal Processing: Image Communication,2011,26(3):162-174.
[13]LUO Z Y,SONG L,ZHENG S B,et al. H.264/AVC perceptual optimization coding based on JND-directed coefficient suppression[J].IEEE Transactions on Circuits and Systems for Video Technology,2013,23(6):935-948.
[14]YIN W,GOLDFARB D,OSHER S. A comparison of three total variation based texture extraction models[J]. Journal of Visual Communication and Image Representation,2007,18(3):240-252.
[15]WANG C Y,LEE S M,CHANG L W. Designing JPEG quantization tables based on human visual system[J]. Signal Processing: Image Communication,2001,16(5):501-506.
[16]潘榕,刘昱,侯正信等. 基于局部 DCT系数的图像压缩感知编码与重构[J]. 自动化学报,2011,37(6):674-681.PAN R,LIU Y,HOU Z X,et al. Image coding and reconstruction via compressed sensing based on partial DCT coefficients[J]. Acta Automatica Sinica,2011,37(6):674-681.
[17]WANG Z,BOVIK A C,SHEIKH H R,et al. Image quality assessment:from error measurement to structural similarity[J]. IEEE Transactions on Image Process,2004,13(4): 600-612.
