基于索引过滤实现搜索引擎中的访问控制
2014-10-15张伟诚艾丽蓉
张伟诚,艾丽蓉
(西北工业大学计算机学院,陕西 西安 710129)
0 引言
与Internet上的信息不同,内联网络中信息结构和存储更为复杂多样。就存储而言,内联网络中信息分布在数据库、邮件服务器、Web页、其他协作软件、文档库、文件服务器和桌面中。内联网中信息的组织形式不仅仅有一般互联网中结构化信息形式,而且还有大量非结构化信息。内联网络中信息的这些特点就要求搜索引擎必须能全面、可跨结构化和非结构化的数据源,以及能够搜索每一个角落,而且还要保证其安全性。如果用户角色没有被授予访问文档、电子邮件或者记录的权限,甚至该信息是否存在也不应让其知道。这种带有访问控制的搜索引擎即为安全搜索引擎。
从安全搜索引擎中搜索安全性方面,本文提出一种基于索引过滤的访问控制策略,能较好地实现内联网搜索引擎的访问控制。
1 索引过滤策略的提出
安全搜索引擎的系统框架与传统的搜索引擎相比,安全搜索引擎在结构上并没有太大的差异,所不同的是,安全搜索引擎系统多了2个部分:单点登录模块和安全过滤模块。
(1)单点登录是实现基于访问控制的安全搜索引擎的先决条件。单点登录(SSO,Single Sign-on)是一种方便用户访问多个系统的技术,用户只需在登录时进行一次注册,就可以在多个系统间自由穿梭,不必重复输入用户名和密码来确定身份。
(2)安全过滤是实现基于访问控制的安全搜索引擎的技术关键。如何实现安全过滤,才能保障具有不同访问权限的用户在使用安全搜索引擎时,访问到用户角色所能访问的资源,是搜索引擎在访问控制上的具体实现。通过对搜索引擎的实现过程研究,可以从检索和爬行过程入手来实现搜索引擎的访问控制,即检索过滤策略和索引过滤策略。
1.1 两种策略的概念
(1)检索过滤策略。在用户查询时,根据用户的访问权限对索引结果进行过滤,返回索引文件中用户授控的资源。在用户提交查询条件,搜索程序在索引文件中检索出符合查询条件的链接。查询出的符合查询条件的链接被提交给安全过滤器,安全过滤器从受控资源的授权描述节点获得每个链接被授权访问的所有用户,安全过滤器的过滤结果为提交查询的用户所授权访问的满足用户查询条件的所有链接,安全过滤器所返回的所有链接交给排序器,根据排序策略对这些链接进行排序,经过排序后的链接最终显示在用户面前,显示结果包括这些链接的快照。
(2)索引过滤策略是从索引文件出发,在索引文件中加入访问控制策略的思想。在建立索引时,建立的索引文件根据资源节点描述的信息进行分组,分别存放。在提交查询以后,根据用户的授权描述信息,找到具有用户权限的资源节点对应的索引文件段(1个或者多个),提交检索器进行检索,最后将检索结果排序,生成快照,返回给用户。
1.2 两种策略的实用性对比
检索过滤策略建立的索引文件更小,爬行的时间也更快,减轻了服务器的压力。但是在检索过程,安全过滤策略时间却远远的大于索引过滤策略所需要的时间,用户搜索结果返回时间更长。索引过滤策略,虽然建立的索引更大,爬行的时间也更慢,但是却能够快速地返回搜索结果,更加贴近用户。实践证明,索引文件的大小相对索引对象的大小要小得多,对于一个几百G甚至于T级别的硬盘简直微乎其微。而且,由于爬行的过程是在服务器端进行,建立索引过程对用户的搜索影响也很小。同时,检索过滤对于资源信息的描述过于复杂,不适用于各种不同Web系统。
所以,索引过滤策略更加适合于安全搜索引擎中安全过滤模块的实现。
2 索引过滤的实现
基于索引过滤思想实现搜索引擎访问控制策略体现在搜索引擎的几个基础模块,具体实现原理如下:
(1)爬行中带访问控制。爬行器的爬行工作,不再是传统搜索引擎对公共资源的爬行,爬行器应当同其他用户一样,作为访问控制的一个主体。受爬行系统内访问权限的约束,提供给爬行器系统的某一个角色,使其爬行该角色所对应的能访问的客体资源。
(2)具有访问控制信息的索引。由于爬行器的爬行过程是带权访问,不同权限的爬行器爬行的资源是不一样,所以为它们建立的索引也应该与爬行的内容相一致,所谓的一致,并非仅仅指内容上的一致,还包括权限信息上的一致,索引内部应该包含索引内容对应的权限信息,如系统对应的分组、角色等信息。
(3)索引文件的过滤。用户提交查询,根据用户的访问权限信息,与系统具有相同访问权限信息的索引文件进行匹配,得到用户访问权限的索引文件。
(4)检索系统根据用户提交查询关键字,在匹配的索引文件进行检索,得到用户访问控制权限所对应的资源链接。
3 安全搜索引擎总体设计
基于索引过滤实现具有访问控制搜索引擎,需要在原有的搜索引擎的基础上进行必要的改进,使其能够应用于具有访问控制信息的系统。在搜索引擎中的不同阶段有不同的工作流程,改进后搜索准备阶段的工作流程如图1所示。

图1 准备阶段工作流程
在图1中,爬行器根据资源授权描述信息,对不同访问控制权限的资源分别进行爬行。索引器根据爬行器的访问控制的资源建立索引,索引文件是带有访问控制信息的索引文件。
根据访问控制需求,用户使用阶段改进后的工作流程如图2所示。

图2 用户使用阶段工作流程
利用单点登录技术,用户登录后,可以访问所有对其进行了授权的资源节点的资源。同时,利用单点登录可以实现用户跨域角色信息的匹配,方便用户一次登录多处搜索。用户提交搜索的条件给检索器,检索器首先根据用户的访问权限,对索引文件进行匹配,得到用户访问权限的索引文件,然后对索引文件进行检索,得到用户的访问权限资源链接。
4 安全搜索引擎的实现
根据索引过滤策略的实现原理,本文提出安全搜索引擎的实现方案。在内部网络上基于索引过滤策略实现带访问控制的安全搜索引擎的框架如图3所示。
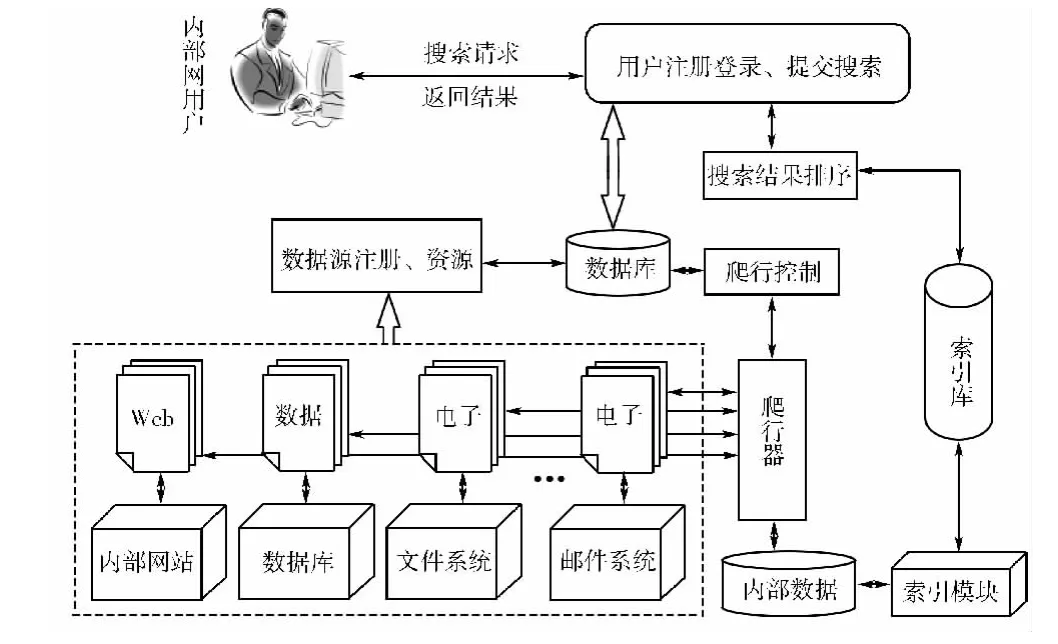
图3 搜索引擎系统实现框架
搜索引擎系统提供爬行器(Crawler)能够快速访问内部网信息资源,为了实现授权用户能够搜索到其有权访问的资源,在爬行器开始工作之前,这些网站必须到搜索引擎处进行注册,同时对其访问控制策略及其接受访问控制的资源进行描述,使得爬行器获得这些描述信息后,即可通过爬行获取各网站接受访问控制的资源,据此建立索引文件。基于此索引在前端提供基于访问控制的内部网搜索引擎,当用户进行搜索时,在索引文件中可以搜索出所有满足用户条件的资源,但只能将对用户进行了授权的资源反馈给用户,需要对搜索出的资源进行安全过滤。最后,系统将过滤后的结果经排序处理后返回给用户。
5 结束语
当今,在政府办公系统以及大型企业事业单位的日常信息处理过程中,通常对信息具有各种不同的安全要求,因此内联网络信息带有明显的分级安全特性。本文针对实现安全搜索问题,提出了一种基于索引过滤的访问控制策略,保证了不同用户搜索信息的准备性和安全性,具有较好的实际应用效果,适合政府和事业单位内部网信息的查询和搜索。
[1]李小明,刘建国.搜索引擎技术及趋势[J].中国计算机用户,2000(9):27-28.
[2]北京拓尔思(TRS)技术有限公司.TRS企业搜索引擎白皮书[Z].2007.
[3]佚名.雅虎IBM联手推免费信息搜索软件[J].电子商务,2007:89.
[4]朱恒亨.安全搜索引擎中的访问控制策略研究[D].武汉:华中科技大学,2009.
[5]RodrigoL,Benjamins V R,Contreras J,et al.A semantic search engine for the international relation sector[C]//International Semantic Web Conference,ISWC 2005.2005:1002-1015.
[6]王福荃.企业信息搜索软件——IBMOmniFind特性简介[DB/OL].http://www.ibm.com/developerworks/cn/data/library/techarticles/dm-0711wangfq/,2007-11-12.
[7]曲成义.电子政务安全保障体系探索[J].信息技术与标准化,2003(11):19-23.
[8]贺兆辉.“门户+搜索”打造政府门户网站建设新模式[J].电子政务,2006(5):14-16.
[9]朱俊卿.搜索引擎Google研究[J].现代图书情报技术,2002(1):45-47.
[10]Lupu E C,Marriott D A,Sloman M S,et al.A policy based role framework for access control[C]//Proceedings of the First ACM Workshop on Role-based Access Control.1995:28-39.
[11]刘怀宇,李伟琴.浅谈访问控制技术[J].电子展望与决策,1999(1):42-46.
[12]邓集波,洪帆.基于任务的访问控制模型[J].软件学报,2003,14(1):76-82.
[13]沈海波,洪帆.面向Web服务的基于属性的访问控制研究[J].计算机科学,2006,33(4):92-96.
[14]刘宏月,范九伦,马建峰.访问控制技术研究进展[J].小型微型计算机系统,2004,25(1):56-59.
[15]严悍,张宏,许满武.基于角色访问控制对象建模及实现[J].计算机学报,2000,23(10):1064-1071.
