基于关键词的云计算语义文本自适应分类
2014-09-29沈佳杰
沈佳杰,江 红,王 肃
(华东师范大学信息科学技术学院,上海 200241)
1 概述
随着互联网和云计算技术的发展,越来越多的应用被部署到了云端。如何在保证分类准确度的情况下,提高文本在云计算环境下的分类效率以及减少对于整体网络带宽的开销,从而高效地在云计算环境下对文本进行分类成为一个亟需解决的问题。
本文提出一个云计算环境下的基于语义的中文文本关键词自适应分类算法,通过对于文本关键词传输而不是文本本身的传输,减少云计算环境下对于分类通信的代价。
2 文本处理技术及云计算简介
2.1 集中式情况下常见的关键词提取技术
对于集中式文本关键词提取算法大致可分成以下2步:
步骤1对于文本进行预处理,如分词,并对词语进行词性标注。
步骤2使用一定的规则对文本中的信息进行关键词的提取。
对于步骤1分词已经有了很多不同的算法[1-2],而对于步骤2,现在比较主流的关键词提取算法有基于统计特征的关键词提取算法、基于语义的关键词提取算法[3-4]以及基于词语网络的关键词提取算法[5-6],并且相关的语义提取技术也已经应用到了很多的领域,如语义的相似性[7]、语义与频率的关系[8],以及对于网页关键词的抽取。
本文介绍基于语义的任务调度算法。基于文本语义的关键词提取算法相较于一般的关键词提取算法,其最大的区别在于这种算法不仅关心词语在文本中的位置和数量信息,还需要结合语言本身的特点,如词语的词性和语法的信息。对于基于其他方法的关键词提取算法还可以参考文献[9]。图1展示了一种基于语义的关键词提取算法[4]。
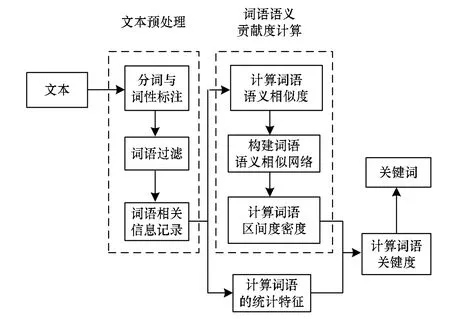
图1 基于语义的关键词提取算法
2.2 集中式情况下中文文本分类算法
针对文本分类的算法,在集中式条件下已进行了很多相关方面的研究,如机器学习[10]、统计方法[11]、语义的方法、关键词[12]和推理网络[13]。但是如何在分布式的环境下,构建相应的文本分类算法依然是一个值得研究的问题。
2.3 云计算
云计算是现在研究的热点问题,对于如何在云计算环境下进行程序的开发和部署以及云计算的定义已经有很多的文献对这个问题进行讨论,如对于云计算进行综述[14-15],对云计算关键技术进行总结[16-17]。如何在云计算的情况下对已知的算法进行改造依然是一个值得研究的问题。
3 云计算文本分类算法
3.1 算法假设以及定义
本文中算法的假设以及定义如下:
假设1计算传输的代价与传输的文本字数成正比,本地的计算代价较网络传输代价忽略不计。
假设1说明了云计算网络的开销代价与传输内容的数量有关,而文本应用中主要的传输内容为文字,所以需要尽量减少传输的文字数。
假设2文本提取的关键词字数小于文本本身的字数。
假设3随着正确关键词数量的增多,文本的语义描述越明确,但是正确关键词与传输关键词字数的比值将变小,当全文传输时其比值接近于0。
对假设2和假设3,为了保证在每一个代理的关键词提取算法可以优先找出比较的重要关键词,并且对应的文本分类算法可以根据正确关键词进行有效的分类,而关键词仅仅只是文本中的一部分,所以关键词的字数将小于文本本身的字数。
假设4阅读文本的人足够聪明,可以有效地分辨文本关键词和文本的类别。
定义1人工判断和自动判断均判断为关键词的数与传输字数的比值,称为单位传输准确数,记为:

其中,A为人工及机器都判断为关键词的数量;n为传输的文字个数。
定义2文本整体分类算法传输所需的字数与关键词分类算法所需传输的字数差值,叫做关键词整体差,记为:

其中,Talli代表全文分类算法需要传输的字数;Tkeywordi代表关键词提取分类算法需要传输的字数。
定义3人工提取和自动提取均判断为关键词的数量与人工提取和自动提取均判断为关键词的数量、人工提取为非关键词而自动提取为关键词的数量之和的比值,称为知识点的查准率[4],记为:

其中,B表示人工判断不是关键词而机器判断是关键词的数量。
定义4人工提取和自动提取均判断为关键词的数量与人工提取和自动提取均判断为关键词的数量、人工提取为关键词而自动提取为非关键词的数量之和的比值,称为召回率[4],记为:

其中,C表示人工判断是关键词而机器判断不是关键词的数量。
定义5查准率与召回率的乘积的2倍与2个和的比值称为查准率P和召回率R的调和[4],记为:

其中,P为查准率;R为召回率。
定义6节点查准率P和召回率R的调和与该节点传输文字数之间的比值称为单位查准率P和召回率R的调和,记为:

其中,n为传输的字符数。
定义7本文中提出的算法,根据词性的不同确定词语的重要性,对于词性重要性定义的权值如下:当wi为名词时, posi=0.8;当wi为简略语时, posi=0.9;当wi为处所词时, posi=0.7;当wi为动词时, posi=0.2;当wi为形容词时,posi=0.2;当wi为副词时,posi=0.2;当wi为介词时,posi=0.2;当wi为状态词时,posi=0.2;当wi为连词时,posi=0.1;当wi为方位词时,posi=0.1;当wi为时间词时,posi=0.1;其他情况时,posi=0.01。其中,wi为第i个词的词性;posi为第i个词的权值。
3.2 算法步骤描述
本文中的算法主要涉及4个主要的步骤,包括对于本地代理文本关键词提取、中心端进行关键词信息汇总、和中心端输出全局分类结果。本文中的云计算环境下的语义提取算法步骤如下:
步骤1使用本地关键词提取算法对本地代理文本进行关键词提取。
步骤1.1输入每一篇文本需要提取的关键词数。
步骤1.2使用本地关键词提取算法对每一篇文档提取关键词及其相应的属性,如关键词以及相应的数量等。
步骤1.3将关键词及相应信息上传到中心端进行统计。
步骤2中心端对进行代理关键词的数据进行汇总。
步骤2.1中心数据端汇总不同的代理关键词信息,调用信用分配算法对每一个关键词分配一个信用值。
步骤2.2根据代理上传关键词及其生成信用值,生成目标类别以及关键词列表。
步骤2.3将目标类别及关键词列表传输到每一个代理。
步骤3根据中心传来的关键词及类别信息进行文本分类。
步骤3.1接受来自中心数据库的关键词列表及目标类别。
步骤3.2根据中心数据库的关键词列表以及目标类别,比对本地文本关键词进行性分类。
步骤3.3将分类结果上传中心数据库。
步骤4根据各个代理分类信息,中心端输出全局分类结果。
3.3 算法性质证明
定理1基于关键词的分类算法的传输效率严格优于传统的基于文本分类的方法。
在军工局资助下,北极星近几年一直在稳步推进新型钼-99生产技术的研发工作。这种技术以钼的稳定同位素为原料,而不是以传统技术使用的浓缩铀为原料,因此可以消除与浓缩铀相关的扩散和环境风险。
证明:
由于假设2,提取出的关键词长度要严格小于文本传输的字数,又因为假设1,随着字数的增加传输代价也将增加,所以对于字数比较少的关键词分类方法其传输效率较高。
定理2当关键词提取的数量大于某一个常数时,随着关键词提取数量的增加,查准率P和召回率R的调和将单调上升。
证明:
将式(3)、式(4)代入式(5),得:

随着关键词提取数量的增加,又根据假设3、假设4,在关键词提取的过程中A,B,C将变大,而S是一个常量,又因为:

将式(9)代入式(7),得:

又因为A单调递增,所以原式单调上升。
证明:
将式(10)代入式(6),得:

从定理2和推论中可以看到,只要关键词提取算法足够好(即满足假设3),通过关键词提取的技术可有效地对各个代理中文本的关键词,即准确度较高的关键词先提取出来,就可以在传输的过程中只传输前面有用的信息以代替对于文本全文的传输,从而达到通过传输少量关键词对文本进行分类的目的。
定理3随着每一个代理关键词提取数量的增加,中心数据库本文分类的准确率将上升,但是每增加一个关键词,中心数据库分类准确率的增加量将减少。
证明:
整个正确关键词的数学期望,满足以下公式:

其中,Ek为提取关键词数为k时正确关键词的期望;pk为第k个关键词是正确关键词的概率。
当提取关键词k时,正确关键词的数学期望为:

由于在假设2中,随着正确关键词数量的增加,文本语义的描述越明确,又因为随着关键词提取数量的增加正确的关键词数也会增加,所以当每一个节点提取以及传输到中心数据库的关键词数增加时,对每一篇文本的内容理解将会更加明确,从而提高在中心数据库中的文本分类效果。
又因为正确关键词与传输关键词字数的比值将变小,当全文传输时其比值接近于0,所以每增加一个关键词,产生正确关键词的可能性变小,中心数据库分类准确率的增加量也将减少。
由定理3可知,虽然随着各个代理关键词增加,中心数据库文本的分类准确率将增加,但是每增加一个关键词,中心数据库分类准确率的增加量将减少。这样当整个云计算系统网络性能较差时,则可以通过减少各个代理对文本提取的关键词数量,从而减少网络中传输的数据量,最大程度保证分类的效率。而网络条件较好时,通过对提取的关键词进行调整,改变网络中数据的传输量以及中心数据库文本的分类准确率,实现算法自适应当前云计算系统网络状态的目的。
4 实验分析
4.1 实验环境和数据组成
本实验环境是Matlab2010b,实验的主要目的是为了证明本文算法的准确性。首先实验中比较了基于语义关键分类算法与基于统计的关键词分类算法对不同代理以及中心数据库关键词提取能力(主要比较查准率、召回率以及查准率P和召回率R的调和)。其次本文中的实验比较改进分类算法与集中式基于统计和语义分类算法的分类准确率。最后通过对比提取关键词个数与关键词整体差的关系,说明改进的分类算法可以有效地提高云计算分布式网络环境下网络的传输效率。本实验数据主要由人民日报1998年语料库中随机抽出120篇文章进行统计,整个数据集将随机划分成2个集合来模拟2个代理集合,每一个代理分别有60篇文章,与此同时,将原先的120篇文章作为集中式实验的素材。其中对于各种不同词语词性权值的定义,如定义7所示。
4.2 实验结果
为了比较不同的关键词提取方法在云计算分布式情况下的影响,分别使用基于语义的关键词提取和基于统计的关键词提取,对2个代理进行关键词提取,并在中心数据库汇总并以此为依据进行文本分类。
表1展示了2个代理对关键词提取的查准率、召回率以及查准率和召回率的调和。如表1所示,对于2个代理基于语义的关键词提取方法和基于统计的关键词提取算法,基本符合本文的假设3,随着关键词个数的增加,其查准率、召回率以及两者的调和单调递增,而且基于语义的关键词提取算法明显优于基于统计的文本提取算法,所以在代理关键词提取算法选择中,选择基于语义的关键词提取算法性能优于基于统计的关键词提取算法,且随着关键词个数的增加,查准率P和召回率R的调和也将单调上升,这与定理2中的结论一致。表2展示了中心数据库合成关键词的查准率、召回率以及查准率和召回率的调和。
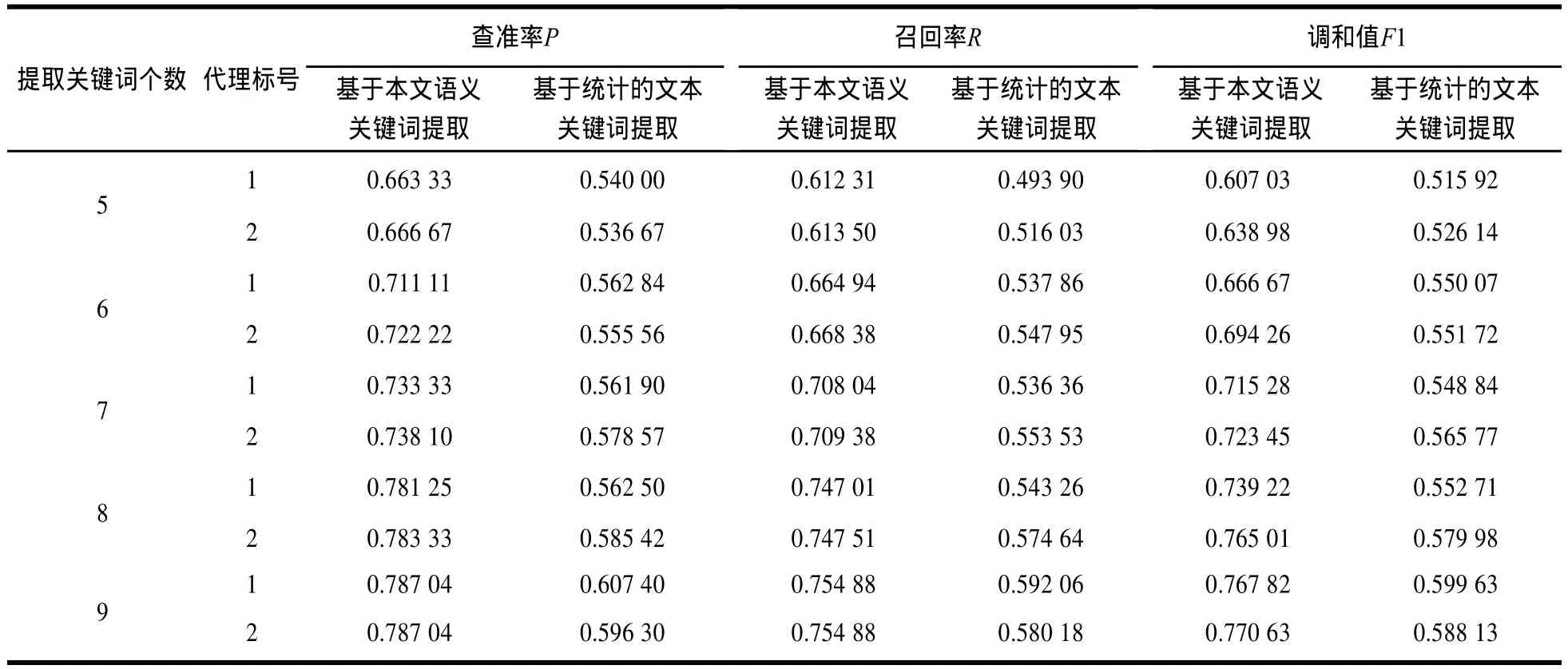
表1 各个代理关键词的提取结果
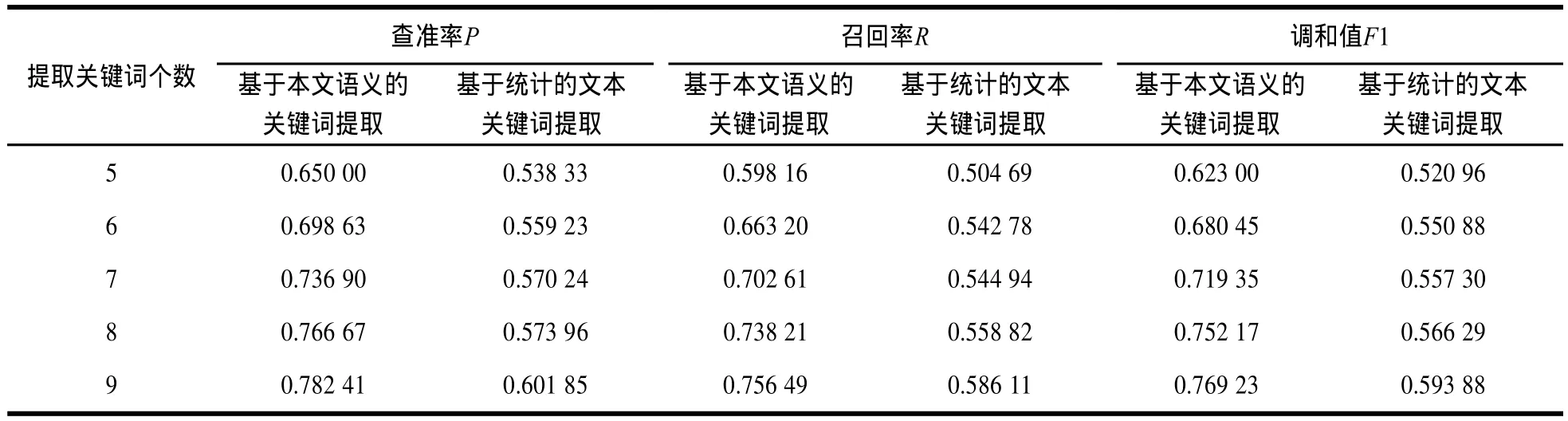
表2 各个中心数据库的关键词合成结果
图2展示了在2个代理中随机选取5篇文章,其关键词的权值分布情况。可以看到不同文章的关键词分布是不同的,如图2(a)中第1篇、第2篇和图2(b)中第1篇、第2篇的关键词权值分布差别比较明显,说明只需要提取部分关键词便可以将文本描述清楚,而图1(a)中的第4篇和第5篇和图2(b)中的第3篇和第5篇权值的差别不大,所以对于这一类的文本则需要提取更多的关键词,以求达到更加好的文本分类效果。
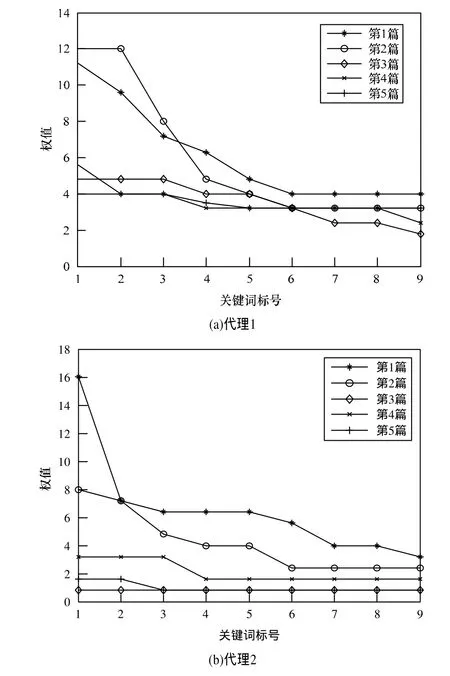
图2 2个代理中5篇文章关键词权值比较
图3主要展示了关键词提取算法代理和中心数据库中单位查准率P和召回率R的调和与提取关键词个数之间的关系。如图3(a)主要展示了2个代理的单位查准率P和召回率R的调和,随着提取关键词个数的增加,每一个代理单位查准率与召回率的调和减少。图3(b)主要展示了中心数据库的单位查准率P和召回率R的调和,随着提取关键词个数的增加,中心数据库端单位查准率与召回率的调和也减少,这与推论的结果一致。对比图3(a)和图3(b)可知,2个代理的单位查准率P和召回率R的调和是中心数据库的2倍,其主要原因是中心数据库的通信量是每一个代理的2倍,而中心数据库中关键词的质量则与每一个代理的质量大体相当。

图3 查准率P和召回率R的调和
图4主要展示基于关键词的中文文本分类算法的准确率与集中式条件下基于语义的中文文本分类算法和统计算法的中文文本分类算法的准确率比较。如图4(a)所示,随着关键词提取数的增加,每一个代理对于文本的分类准确率提高,接近于基于语义分类方法的准确率,并在提取关键词大于一定数量后,其准确率升值超过了集中式的基于统计的文本分类方法。如图4(b)所示,随着关键词提取数量的增加,中心数据库的分类准确率上升,但是每多提取一个关键词,其准确率的上升量却在减少,这与定理3的结论一致。图4说明了无论在代理端,还是在中心数据库端,在每一个代理提取的关键词数量达到一定数量之后,可以近似代替集中式的语义提取文本分类方法。
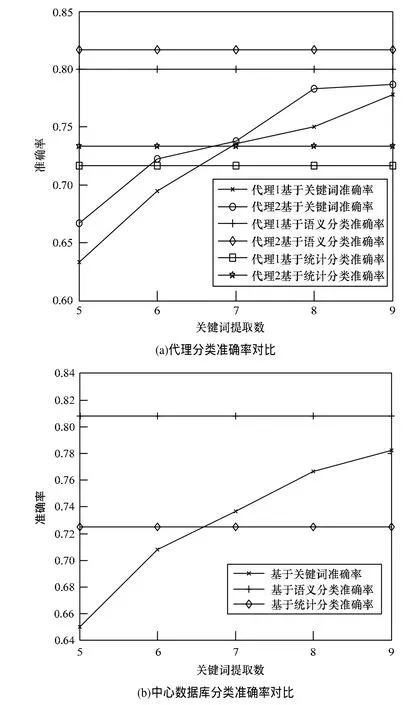
图4 算法准确率比较
图5展示了每一个代理和中心数据库提取关键词数与关键词整体差之间的关系。如图5(a)所示,随着关键词提取数量的增加,每一个代理提取的关键词个数增加,每一个代理的关键词整体差随之下降。如图5(b)所示,随着关键词提取数量的增加,中心数据库的关键词整体差也随之下降,这与定理1的结论一致。综合图5(a)、图5(b)虽然代理和中心数据库的关键词整体差,即使提取的关键词数达到了20个,其中心数据库关键词整体差依然高达1.75×105,说明改进的关键词提取分类算法可以有效地减少网络的传输量,从而在保证分类效果的前提下,减少云计算对网络传输的开销。

图5 关键词提取数与关键词整体差之间的关系
5 结束语
本文展示了一个云计算环境下基于语义关键词提取的分布式中文文本分类方法。通过理论推导和实验,证明了相对于传统的集中式文本分类方法,本文方法可以在近似保证分类效果的前提下,有效地减少云计算网络的传输开销。但是本文方法并没有具体说明在提取关键词数量和文本分类准确率的定量关系,仅对中文文本做了实验,该方法是否对其他语言依然有效尚无定论,下一步工作将对这些方面进行研究。
[1]何国斌,赵晶璐.汉语文本自动分词算法的研究[J].计算机工程与应用,2010,46(3):125-130.
[2]吴晶晶,荆继武,聂晓峰,等.一种快速中文分词词典机制[J].中国科学院研究生院学报,2009,26(5):704-710.
[3]傅 鹂,涂春梅,付春雷,等.基于语义的成语检索系统研究[J].计算机工程与应用,2011,47(13):147-149.
[4]王立霞,淮晓永.基于语义的中文文本关键词提取算法[J].计算机工程,2012,38(1):1-3.
[5]Turney P D.Thumbs Up or Thumbs Down Semantic Orientation Applied to Unsupervised Classification of Reviews[C]//Proc.of the 40th Annual Meeting on Association for Computational Linguistics.[S.l.]:ACM Press,2002:417-424.
[6]Turney P D.Learning Algorithms for Keyphrase Extraction[J].Information Retrieval,2000,2(4):303-336.
[7]Turney P D.Similarity of Semantic Relations[J].Computational Linguistic,2006,32(3):279-416.
[8]Turney P D,Pantel P.From Frequency to Meaning:Vector Space Models of Semantics[J].Journal of Artificial Intelligence Research,2010,37(1):141-188.
[9]郑家恒,卢娇丽.关键词抽取方法的研究[J].计算机工程,2005,31(18):194-195.
[10]苏金树,张博锋,徐 昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9):1848-1859.
[11]姜 远,周志华.基于词频分类器集成的文本分类方法[J].计算机研究与发展,2006,43(10):1681-1687.
[12]罗 杰,陈 力,夏德麟,等.基于新的关键词提取方法的快速文本分类系统[J].计算机应用研究,2006,23(4):32-34.
[13]李晓黎,刘继敏,史忠植.概念推理网及其在文本分类中的应用[J].计算机研究与发展,2000,37(9):1032-1038.
[14]Armbrust M,Fox A,Griffith R,et al.A View of Cloud Computing[J].Communications of the ACM,2010,53(4):50-58.
[15]Buyya R,Yeo C S,Venugopal S.Market-oriented Cloud Computing:Vision,Hype,and Reality for Delivering IT Services as Computing Utilities[C]//Proc.of the 10th IEEE International Conference on High Performance Computing and Communications.[S.l.]:IEEE Press,2008:5-13.
[16]陈 康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009,20(5):1337-1348.
[17]陈 全,邓倩妮.云计算以及其关键性技术[J].计算机应用,2009,29(9):2562-2567.
