BBS网络舆情的在线自适应话题演化模型
2014-09-29杨春明石大文
杨春明,张 晖,石大文
(西南科技大学计算机科学与技术学院,四川 绵阳 621010)
1 概述
电子公告栏(Bulletin Board System,BBS)的开放性与互动性使其成为了新闻、观点、民生的集散地,在BBS上围绕某一话题的报道、言论、观点能在互联网上迅速传播,在短时间、大范围内形成强大的影响力。话题是指事件相关报道的集合[1],话题演化则表示了话题随时间推移表现出的动态性、发展性和差异性。研究BBS中话题的发现与演化是网络舆情[2]分析的重要内容之一,有助于全面把握公众对社会突发事件所表达出的具有较强影响力、带有倾向性的言论和观点,了解事件变化规律及发展趋势,便于提前采取相应的应对措施。
话题演化主要研究在时间维度上话题的变化情况,表现为话题在内容上的延续性和强度的变化。近年来对新闻话题演化的研究较多[3],而对BBS话题演化研究较少,主要集中在热点话题的检测与预警上。BBS中的信息具有特征稀疏性、奇异性和动态性等特点,与新闻话题区别较大。特征稀疏性是指发表在BBS上的信息长短不一,存在大量的短文本,信息量少,以词为维度的向量空间模型呈现出高维稀疏的特点;奇异性是指这些信息中广泛存在用词不规范、谐音词、简写词等;动态性表现在随着时间的推移,文本信息流的数量在变化,会产生新话题,消亡旧话题,同时还需要实时处理新增文本流。
针对BBS信息的以上特点,本文提出针对BBS内容的自适应在线话题演化模型。以历史时间窗口中话题、词分布的后验作为当前时间窗口中话题、词分布的先验,利用在线新话题检测和消亡话题检测方法自动适应数据流中的话题数量。
2 相关研究
话题演化是话题检测与跟踪(Topic Detection and Tracking,TDT)的一项重要研究任务,目的是研究话题在时间维度上的变化情况[4]。早期的TDT没有充分利用语料的时间信息研究话题随时间的演化,近年来,随着统计话题模型潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)的兴起,在模型中引入语料的时间信息研究话题在时间维度上的演化,成为机器学习和文本挖掘领域的研究热点。
LDA模型是一种具有文本话题表示能力的非监督学习模型,通过潜在的话题变量将文档与词关联起来,文档在主题上的分布和主题在词上的分布式都是条件独立同分布。LDA将每篇文档看成是所有话题的一个多项式分布,而文档中的每个词则先由文档-话题多项式分布生成一个话题,再由话题-词多项式分布生成[5]。该模型可以很好地模拟文本的生成过程,对文本的预测也有很好的效果。很多研究人员通过引入时间信息对LDA模型进行了扩展来研究话题演化,根据模型是否具有在线的处理能力,可以分为线下模型和在线模型2类。
线下的话题演化模型主要对特定的语料进行建模分析,不能在线处理新到的文本,其主要方法有2种:
(1)TOT(Topic Over Time)模型[6],将时间作为一个可观测的连续变量来指导语料集合上的话题分布,话题的演化反映在时间上的分布强度。
(2)后离散分析方法[7],该方法把时间看作一个离散的变量,首先不考虑时间的影响,在文本集上运行LDA模型,获得模型的参数,然后按照时间把文档分配到对应的时间窗口中,对于某个话题考虑它在每个时间窗口中的强度,从而发现热话题和冷话题。
类似的模型还有DTM(Dynamic Topic Model)模型、CTDTM(Continuous Time Dynamic Topic Model)模型、MTTM(Multi-Scale Topic Tomography)模型等。
在线的话题演化模型需要实时分析新到文本,ILDA(Incremental Latent Dirichlet Allocation)模型根据文本到达时间进行增量建模,以每个时间窗口上话题个数的变化情况研究话题内容的演化[8]。OLDA(Online Latent Dirichlet Allocation)模型利用历史的数据作为模型的先验分布,对时间间隔内到达的数据流采用LDA模型,展现话题在内容和强度上的演化[9]。文献[10]提出一种基于LDA的在线话题演化挖掘模型,研究了不同时间窗口话题所含关键词的联系,以发现话题演化中的话题遗传和话题变异。文献[11]针对网络舆情的特点,提出一种基于OLDA的话题演化方法,在BBS数据集上分析了不同时间窗口之间话题的关联。
上述研究多基于行文规范的新闻报道,BBS上的文本信息主要由转载其他新闻网站的报道、网民原创内容以及回复构成,其表达上具有口语化、写作不规范的特点。由于BBS的强交互性,使得同一帖子表达的话题具有外延性,可能涉及多个话题,如“我爸是李刚”事件中,很多帖子的内容是描述李刚有几套房、开什么档次的汽车、岳父是副省长等。上述特点使得BBS中每一时刻都有新话题的产生与旧话题的消亡,话题的数量在不同时间窗口内不一样。而在LDA模型中,评估参数时都需要假设话题数量是固定的;在文献[9]的OLDA模型中通过保留每一个时刻的话题分布来发现新的话题和评估话题的演化,只考虑到相邻时刻的话题相似性,没有考虑话题数量的变化。文献[11]针对舆情信息的特点,主要分析了不同时间片话题间的关联,且话题的粒度较大。
本文在上述2种方法的基础上,利用时间片间话题的相似度监测新话题的产生及旧话题的消亡,细化话题粒度,提出针对BBS上网络舆情的自适应在线话题演化模型,以解决不同时刻话题数量变化的问题。
3 自适应的在线话题演化模型分析
3.1 BBS内容话题演化建模
话题的演化表达了话题随着时间推移的变化过程,如BBS中一个帖子产生后,会引起很多为围绕这一帖子的讨论,随着时间的推移,讨论的热度会降低,或者会起波动,最后直到淡化。这个演化过程可分为形成、高涨、波动、消亡等阶段,反映了话题在内容上的延续性和强度。
在线的话题演化需要实时处理到达的文本数据流,根据话题演化分析的实际要求,将按时间序列到达的文本以一定的时间粒度划分,时间窗口t内到达的文本集为Dt={d1,d2,…,dn},di为其中的一个文本。话题是文本集在语义空间中的表现,在LDA模型中,由一组关键词的分布来表示一个话题,每个文本视为一组话题的混合分布。则时间窗口内话题的分布可由文本di中词w对于话题z的后验概率表示,如下式所示:

其中,z是一组话题向量,第k维即表示话题k。
延续性表达了相邻时间窗口间文本内容的关联,强度表达的是某一时间窗口内某个话题讨论的热度。历史时间窗口中话题以及所含词语的分布为当前时间窗口的话题演化分析提供了先验知识。不同时间窗口内话题的分布体现了内容的延续性,而强度则表现为话题所含词语的分布,因此,可由时间窗口内文本表达话题的相关性来表示,相关性越大,该话题的强度越大,反之越小。考虑话题k在时间窗口t中每个文档所占的比重之和为该话题的强度,公式如下所示:

其中,TS(K)t为时间窗口t中话题k的强度;|Dt|为时间窗口t中文档的数量;为话题k在文档d中的概率。
3.2 自适应的BBS话题演化模型
假设每个时间窗口中文本集涉及的话题数为K,令t时刻文本d上的话题分布服从参数为θ(d)的多项分布,话题在词汇集合上服从参数为φk的多项分布,同时令话题分布和词分布的先验服从Dirichlet分布,分别为θ:Dirichlet(α)和φ:Dirichlet(β)。
使用Gibbs[12]抽样方法估计当前时间窗口中的参数θ(d)和φk,考虑到不同的历史数据对当前时间窗口话题分布的影响,以t–1时间窗口中话题分布和词分布的后验作为时间窗口t中话题分布和词分布的先验。时间窗口t上,参数θ(d)对应话题k以及参数φk对应词w的估计公式如式(3)、式(4)所示:
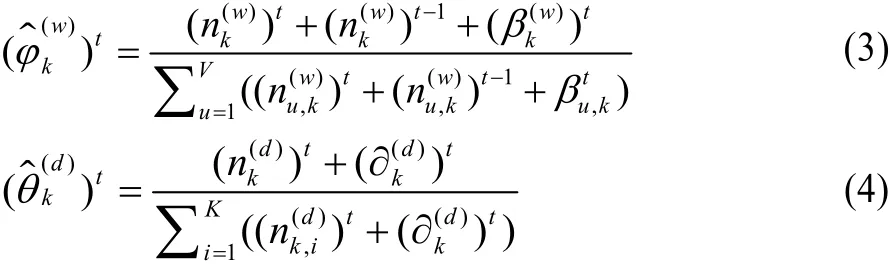

其中,λ为权重因子,离当前时间窗口越近,影响越大,权重越大。
上述模型中需要确定时间窗口中的话题数K,在强交互的BBS数据流中,话题的数量时刻发生变化,一个话题可以演化为多个话题。因此,需要考虑在每一个时刻话题数量的变化,既有新产生的话题,又有消亡的话题。新话题的产生是检测上一时刻话题分布的评估值,利用话题检测算法生成;话题消亡则通过考虑在ρ个时间间隔内该话题的强度小于给定的阈值ε,即认为该话题已经消亡。通过上述调整自动更新时间窗口内话题的数量,形成一个话题在时间和内容上的演化矩阵。
3.3 时间窗口内新话题的检测
时间窗口内新话题的出现表现为当前数据流中的一个异常值,该异常值由相邻时间窗口中话题的相似性来衡量,如果相似性到一定阈值NTVt,则表明有新话题产生。话题间的相似性用KL(Kullback-Leibler)散度衡量,记作KLS(p||q)。KLS是KL散度的变形,是一个对称的KL散度测度,定义为KL(p||q)和KL(q||p)的平均值,表达了2个话题p和q之间的相似性,计算公式如下:

定义Kt维距离向量DV,其中DV(k)表示话题k在t–1时刻和t时刻的相似性。引入新话题发现自信水平测量(NTCL,t时刻话题达到自信水平的百分比)来确定NTVt,使小于NTVt值的距离占所有距离的百分比正好是NTCL。则t时刻的新话题检测算法(NTDetect)如下:

3.4 话题消亡检测
旧话题的消亡表现为话题的强度明显地不同于数据流中的其他话题,但在t时刻话题的强弱不仅与时间窗口的大小有关而且与话题本身的发展有关,如由其他突发事件而暂时降低了该话题的关注度。因此,考虑在连续σ个时间窗口内话题强度都被标记为消亡话题,则该话题标记为真正消亡话题,并删除该话题,话题的数量也相应减少,否则取消消亡话题标记。


4 实验及分析
实验中利用网络爬虫采集了天涯虚拟社区上2011年3月-4月发布的正文大于20个字符且回复数小于20000的帖子,共计25495条,保留了URL、发表时间、发表作者、标题、正文内容、回复等信息。实验前对数据集进行了分词、去停用词和向量化等预处理,分词时使用ICTCLA分词器,添加20000用户词典,主要来源搜狗输入法词库;去除了副词、助动词以及BBS上的无意义词,如:“回复”、“发表时间”、“转载”、“顶一下”等;向量化帖子内容的词频,使每一个词都对应词表中的一个维度。
实验时以周为单位,将数据集划分为8个时间窗口,设置话题参数K=30,α=0.3,β=0.01,λ=0.4,σ=2,NTCL=90%,OTCL=95%,迭代500次,抽取出的话题涉及大学教育、自然灾害、食品安全、工资收入、医疗问题、土地拆迁、房价等。从时间窗口2开始,有新话题的产生,从第3个时间窗口开始有消亡话题,其数量在动态变化。话题数量由初始的30动态变化为最终的34,验证了模型中每个时间窗口中话题数量动态变化的假设,如图1所示。
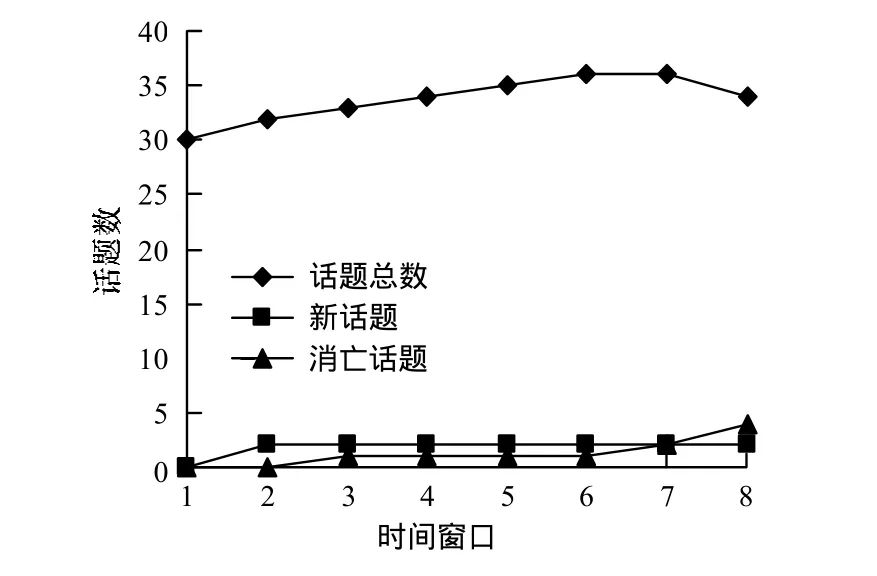
图1 时间窗口中的话题数量变化
进一步分析话题在内容上的演化趋势,选择一个已有话题21和新产生话题32在不同时间窗口中出现概率最大的10个词语展示,如表1所示,令ω为时间窗口。从每个时间窗口占主导地位的关键词变化情况可以看出,话题21由食品安全开始演化为双汇的瘦肉精事件,在第2个时间窗口产生了关于日本地震的新话题,并由开始的地震报道演化为救援,反映了该时间段中发生的一些重大突发事件。

表1 话题内容在时间窗口中的关键词
话题演化的趋势也表现为话题在每个时间窗口的强度上,如图2所示。话题21和32在8个时间窗口上的强度变化趋势与其在内容上的演化一致。随着时间的推移,强度逐渐减弱,其中话题21在消亡,有新的话题将要产生。实验进一步采用OLDA模型,使用相同的参数在数据集上与本文的模型进行对比分析,由于OLDA模型的话题数固定,只能对比话题在时间窗口上的关键词。同样以食品安全和日本地震的话题为例,OLDA模型在8个时间窗口上的关键词如表2所示。
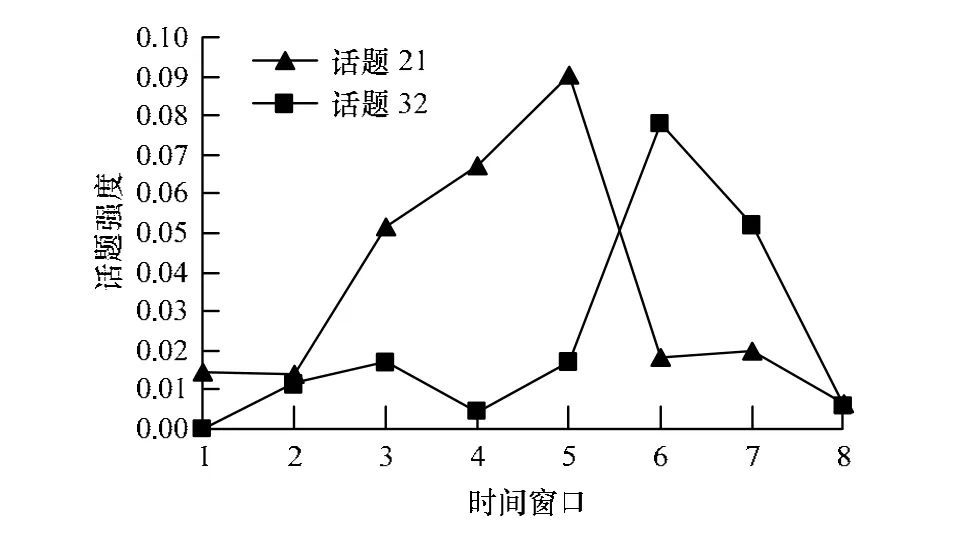
图2 话题在强度上的演化

表2 OLDA模型话题演化关键词
OLDA模型仅考虑了时间窗口上话题内部关键词间的关联,但时间窗口间的话题关联不强,具有一定跳跃性,话题在时间上的演化过程不明显。根据计算的KL散度,也验证了上述情况,如图3所示。其中,1#2表示时间窗口1与时间窗口2;2#3表示时间窗口2与时间窗口3;以此类推。

图3 话题21时间窗口间KL散度比较
以上实验表明,本文模型能直观地表达出话题在时间维度上内容和强度的演化,且能检测新产生的话题和消亡的话题,对话题数量进行动态更新,最终趋向一个真实值,弥补了OLDA模型的不足。同时也表明模型能够较好地捕获正在发生的热点事件,分析它们在时间和内容上的演化,表明该方法在真实的网络数据上也能够获得较好的结果。
5 结束语
BBS的强交互性使得话题数量在演化过程中动态变化,对传统话题演化模型要事先确定话题数量的问题。为此,本文提出了自适应的在线话题演化模型。模型将按时间序列到达文本以一定时间粒度划分为多个时间窗口,在每个时间窗口内应用LDA模型获取话题分布,历史时间窗口中话题以及所含词语的分布为当前时间窗口的话题演化分析提供了先验知识。不同时间窗口内的话题强度表现为词的分布,以此提出了在线新话题检测和消亡话题检测方法来自动适应数据流中的话题数量。在天涯社区数据集上的实验结果表明,该模型能较好地反映出不同时间窗口内话题数量的变化,并能分析在时间和内容上的演化,及时发现一些正在发生的热点事件,在一定程度上弥补了传统话题演化模型的不足。本文只对BBS帖子的内容进行了分析,今后将研究帖子之间的链接、作者、回帖者等信息在网络舆情演化中的作用。
[1]洪 宇,张 宇,刘 挺,等.话题检测与跟踪的评测及研究综述[J].中文信息学报,2007,21(6):71-87.
[2]曾润喜.网络舆情信息资源共享研究[J].情报杂志,2009,28(8):187-191.
[3]赵旭剑.中文新闻话题动态演化及其关键技术研究[D].合肥:中国科学技术大学,2012.
[4]单 斌,李 芳.基于LDA话题演化研究方法综述[J].中文信息学报,2010,24(6):43-49.
[5]Blei D M.Probabilistic Topic Models[J].Communications of the ACM,2012,55(4):77-84.
[6]Wang Xuerui,Mccallum A.Topics over Time:A Non-Markov Continuous-time Model of Topical Trends[C]//Proc.of the 12th International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2006:424-433.
[7]Canini K R,Shi L,Griffiths T L.Online Inference of Topics with Latent Dirichlet Allocation[C]//Proc.of the 12th International Conference on Artificial Intelligence and Statistics.New York,USA:ACM Press,2009:937-946.
[8]Iwata T,Yamada T,Sakurai Y,et al.Online Multiscale Dynamic Topic Models[C]//Proc.of the 16th International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2010:663-672.
[9]Alsumait L,Barbará D,Domeniconi C.On-line LDA:Adaptive Topic Models for Mining Text Streams with Applications to Topic Detection and Tracking[C]//Proc.of International Conference on Data Mining.Pisa,Italy:IEEE Press,2008:3-12.
[10]崔 凯,周 斌,贾 焰,等.一种基于LDA的在线主题演化挖掘模型[J].计算机科学,2010,37(11):156-159.
[11]胡艳丽,白 亮,张维明.网络舆情中一种基于OLDA的在线话题演化方法[J].国防科学技术大学学报,2012,34(1):150-154.
[12]Kozumi H,Kobayashi G.Gibbs Sampling Methods for Bayesian Quantile Regression[J]. Journalof Statistical Computation and Simulation,2011,81(11):1565-1578.
