基于主观质量的JPEG XR量化参数选择
2014-09-29刘致远陈耀武
刘致远,陈耀武
(浙江大学嵌入式系统研究开发中心,杭州 310027)
1 概述
JPEG XR是来自联合图像专家组的一种最新的图像压缩标准,其前身是由微软发布的HD PHOTO。该标准主要用来满足端到端的数字图像应用需求,具有高压缩率和更佳的图像质量,允许输入宽动态范围图像,提供无损压缩模式,支持全格式色彩采样、缩略图提取以及嵌入码流的可伸缩性,同时保持编码和解码过程的低复杂度[1]。
压缩效率是衡量图像压缩标准应用价值最重要的指标之一,更高的压缩率下更好的图像质量一直是图像压缩领域的研究目标。与主流的图像压缩标准JPEG和JPEG2000相比,JPEG XR的压缩效率大大高于 JPEG,接近于JPEG2000[2],但是,由于前两者出现时间较长,相关研究和优化技术众多,在很多应用场合都有更优异的表现。JPEG XR作为较新的标准,有关图像质量和率失真性能优化的研究逐渐兴起。文献[3]通过实验比较并分析了 JPEG XR、H.264 Intra模式、JPEG20003种图像编码器的质量差异;文献[4]从标准制定的角度提出了在峰值信噪比(Peak Signal to Noise Ratio, PSNR)、多尺度结构相似性(Multi-scale Structural Similarity Index Measurement, MSSIM)等多种评价标准下提高 JPEG XR率失真性能的若干技术;文献[5]进一步在主观质量评价标准 MSSIM 下讨论了量化系数的选取策略;文献[6]优化了编码过程中的熵编码环节,从而使得特定码率下的 PSNR提高了 0.5 dB。上述研究均在JPEG XR的率失真性能提高方面有所贡献,但基于人类视觉系统(Human Visual System, HVS)特点的感知域JPEG XR图片质量优化的研究却鲜少见到,而这类优化方法已经使用于 JPEG和 JPEG2000。文献[7-8]分别描述了基于 HVS特点的JPEG和JPEG2000编码优化方法。
本文利用 JPEG XR编码标准的特点,根据能够反映HVS特性的最小可觉差(Just Noticeable Difference, JND)模型提出一种自适应量化参数(Quantization Parameter, QP)选择算法。将该算法加入到现有JPEG XR编码过程中,使量化参数根据亮度、纹理等图像内容进行动态调整,输出压缩图像与用户指定量化参数生成的压缩图像保持主观质量相同,但压缩效率得到较大提高,实现JPEG XR图像的编码优化。
2 JPEG XR编码关键环节
JPEG XR仍是一种基于块的混合编码方法,与其他静止图像压缩标准在高层流程上有很多相似之处,JPEG XR编码流程见图1。
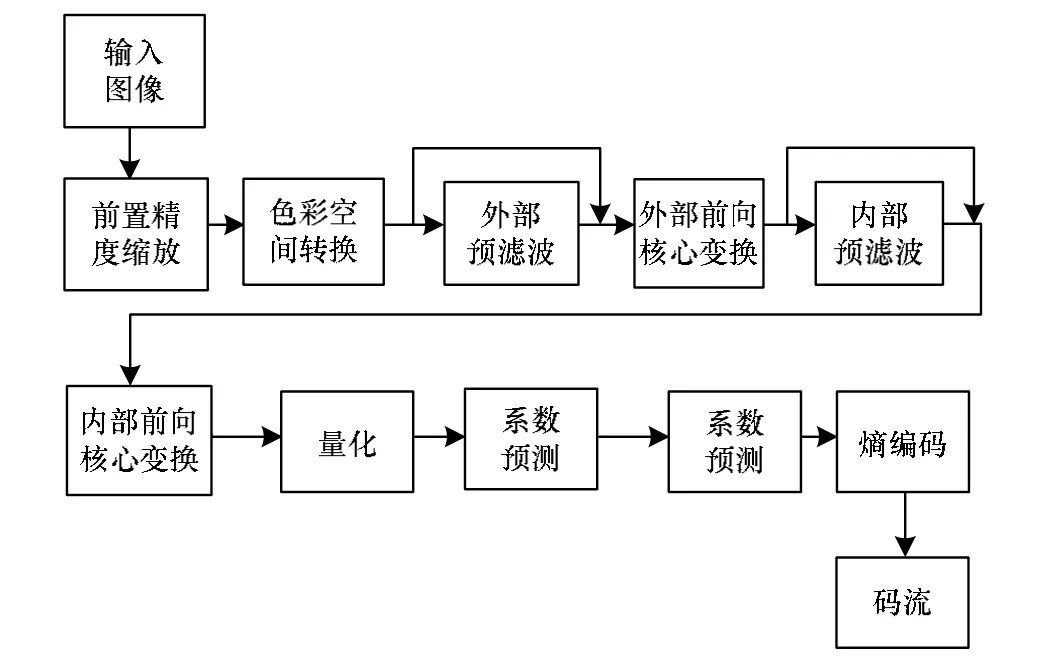
图1 JPEG XR编码流程
2.1 变换过程
PEG XR最具有特色的环节之一就是系数变换。所谓的外部变换与内部变换构成了变换的 2个阶段:第一阶段的变换将一个 16×16宏块中的像素值从空域变换到频域,其中每个4×4块中的交流(Alternating Current, AC)系数组成了该宏块的高频(High Pass, HP)系数;第二阶段的变换针对每个4×4块中的直流(Direct Current, DC)系数,这16个系数再经过一次与第一阶段相同的变换,最终组成了该宏块的1个DC系数和1个低频(Low Pass, LP)系数。各阶段的变换又可分为预滤波与核心变换。预滤波是可选的,其作用在于消除块效应及振铃效应,核心变换是一种类似于离散余弦变换(Discrete Cosine Transform, DCT)的变换。预滤波与核心变换结合在一起就构成了双正交叠式变换(Lapped Biorthogonal Transform, LBT),该变换被证明可以有效地消除块效应[9],从而提高视觉质量。
2.2 量化过程
与对预测后的残差进行变换和量化的H.264标准不同,JPEG XR直接对变换系数进行量化,因此从理论上说,一个宏块的量化误差并不会对使用该宏块进行预测的其他宏块造成影响,这为通过量化系数控制压缩率及压缩质量起到了一定的简化作用。
JPEG XR的标准量化过程比较灵活。不同的图像区域、色彩通道各自拥有独立的量化参数集,每个宏块按照所属图像区域及色彩通道从对应的量化参数集中选择自己的量化参数。一个宏块的DC、LP、HP系数的量化参数可以不同,其中,DC系数量化参数集仅有 1个量化参数;LP、HP系数的量化参数集可分别有最多16个量化参数。量化参数的范围为[1, 255],1对应的就是无损压缩。由量化参数到量化因子的映射具体如下:
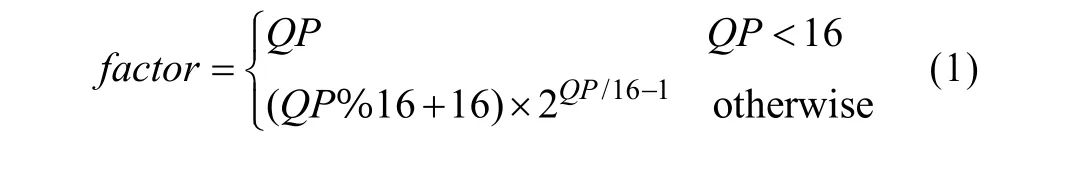
3 图像的JND评价
JND指的是HVS可以察觉到的差异的最大阈值,在主观图片及视频处理中扮演了重要角色[10]。在有关图片的JND评价中,已经发展出了众多模型,这些现有模型基本可分为基于像素和基于子带 2类。它们的本质原理都是HVS的一些特性,并可以通过空域频域变换来互相转化。
基于像素的JND模型大多用作图像质量评价、运动估计等,由于空域的限制,该类模型一般不考虑HVS对于不同频率成分的不同敏感度,因此不能精确地描述 HVS的特性[11]。
基于子带的JND模型则包含了影响HVS感知的主要因素,如对比度敏感函数(Contrast Sensitivity Function, CSF)、亮度自适应和对比度掩盖等,该类模型大部分用来提高图片及视频的压缩效率,由于主流压缩算法大多使用DCT变化,因此基于频带的JND模型大多是基于DCT的,其他则基于DWT,处理使用小波变换的压缩算法如JPEG 2000等。
在基于子带的JND模型中,DCTune是其中发展时间较长且接受度比较高的一个。该模型由NASA Ames研究中心提出,申请了发明专利并推出了相应的JPEG编码软件。在最新的DCTune2.0中,增加了根据原始图像评判压缩图像JND质量的功能,是一种快速方便的图像主观质量评价工具。
4 自适应量化参数选择算法
优化图片的压缩编码有 2种实现途径:一种是在保持图片码率不变的情况下,使得解码图片的质量得到增强;另一种是保持图片质量不变,减少图片码率。这 2种途径本质是相同的,都是提升压缩图片的率失真性能。本文主要从第 2种途径出发,针对控制图片质量的量化环节,提出一种优化算法,其框图如图2所示。
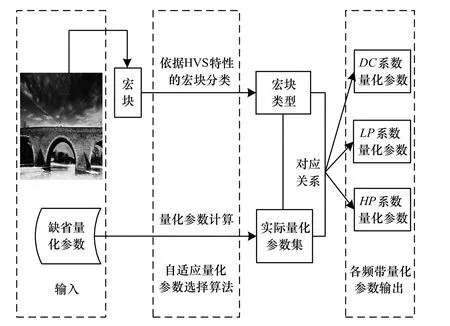
图2 自适应量化参数选择算法框图
4.1 依据HVS特性的宏块分类
4.1.1 分类要素
对于无色度图像来说,像素的JND可以用式(2)的非线性模型[12]来近似描述:

其中,x、y分别为像素的横、纵坐标;Tl为与背景亮度有关的可视阈值;Tt是与图像纹理掩膜效应有关的可视阈值;Cly是两者的叠加效应系数。
可见,主要有2个因素影响每个像素的视觉感知阈值:(1)像素所处区域的平均背景亮度;(2)像素所处区域的纹理情况。
人眼在不同亮度下的感知阈值呈近似的抛物线:在中等亮度下,阈值最低,差异最容易被感知;在极暗和极亮的亮度下,阈值较高,差异不容易被感知,该曲线如式(3)所示[12]:
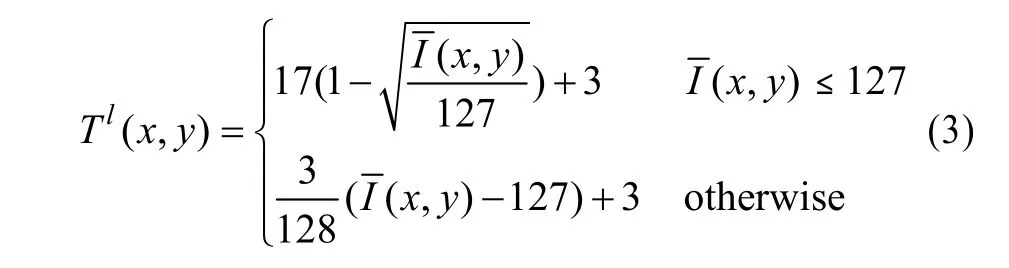
其中,I为背景平均亮度。
同样地,图像纹理也可以用一个因子来表示,该因子与像素亮度的邻域梯度和边缘权重有关,如式(4)所示[12]:
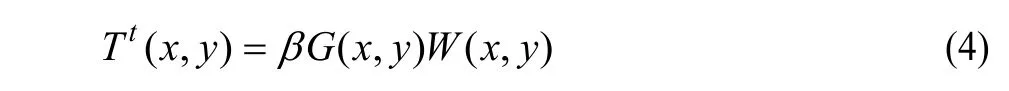
其中,β为调整因子;G为该像素4邻域最大梯度;W为边缘权重。可见,人眼对于平坦光滑区域和图像中边缘附近的差异较容易觉察,对于复杂纹理区域的差异察觉阈值则较高。
基于上述HVS特性可知,若想保持图片的主观质量不变而提高压缩率,则要对更少的码率进行合理分配。针对亮度自适应因子,应在中等亮度区域分配较多的码率,而在暗区和亮区分配较少的码率;针对纹理应在平滑区域和边缘区域分配较多码率,而在复杂纹理区域分配较少码率。为此,必须首先准确地判断图像区域特性。最简单直接的方法就是在空域直接求上述属性的值。如对于平均亮度,只要求区域内像素亮度的平均值即可;求背景亮度的非均匀性,则相当于求区域内像素亮度的均方差。但在JPEG XR图像压缩过程中,上述空域处理属于额外步骤,会占用一定的编码资源,更好的方法是利用压缩过程中的变量来进行判断。
4.1.2 基于变换系数的图像亮度与纹理分析
虽然LBT并不等同于DCT,但其系数在频域的意义是近似的。在亮度通道中,DC系数仍然代表宏块中像素亮度的平均值,所以,可以用宏块的 DC系数根据阈值来判断宏块的亮度类型;同理,AC系数可以反映宏块的纹理情况,具有复杂纹理的宏块区域有较高能量的AC系数。
表1表示LBT变换系数与图像亮度、纹理的对应关系。

表1 LBT变换系数与图像亮度、纹理的对应关系
对于每个宏块仅有的1个DC系数,只要直接判断其值即可;对于每个宏块含有多个的 LP、HP系数,通过大于一定阈值的LP、HP系数个数衡量LP与HP系数的大小:
LP_num为当前宏块中大于LP系数阈值的LP系数个数,LP系数阈值设为100。
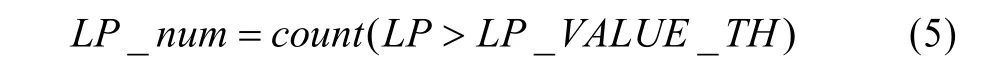
HP_num为当前宏块中大于HP系数阈值的HP系数个数,HP系数阈值设为134。
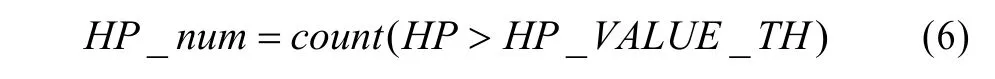
4.1.3 图像中边缘区域的检测
实际上,并不是所有的高能量AC系数区域均为复杂纹理区域,边缘区域也会有较高能量的AC系数。判断边缘区域的关键在于从LP系数较大的区域中排除粗纹理区域,即将具有较大 HP系数的区域排除。还有一种需要考虑的情况,就是在纹理区域中出现边缘,则因为具有较大HP系数的区域已被排除,该边缘不会被检测到。补偿的方法是计算每个宏块HP系数与相邻宏块HP系数的能量差,该差大于一定的阈值代表纹理中可能有边缘。综上所述,一个宏块满足以下任意一个条件即为边缘宏块:
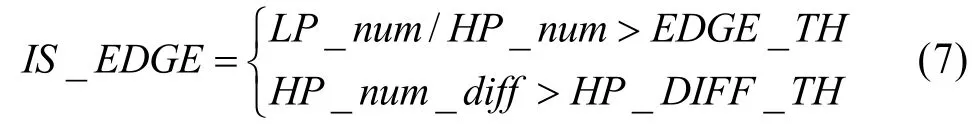
其中,边缘阈值EDGE_TH为2;HP系数差阈值HP_DIFF_TH为100;HP_num_diff为当前宏块相邻宏块(包括上边宏块和左边宏块)中大于HP系数阈值的HP系数个数,由式(8)计算得到:

图 3展示了根据变换系数检测边缘的效果,可见,该方法能够准确检测出大部分的清晰边缘。

图3 边缘检测效果
4.1.4 基于亮度和纹理的宏块分类
本文将宏块分为 6类,并根据变换系数判断宏块所属类型,具体分类方法如表2所示。根据LBT变换关系,其中,亮度阈值分别为−6000和4000。利用该分类方法对实验图片中的宏块进行分类情况如图4所示。
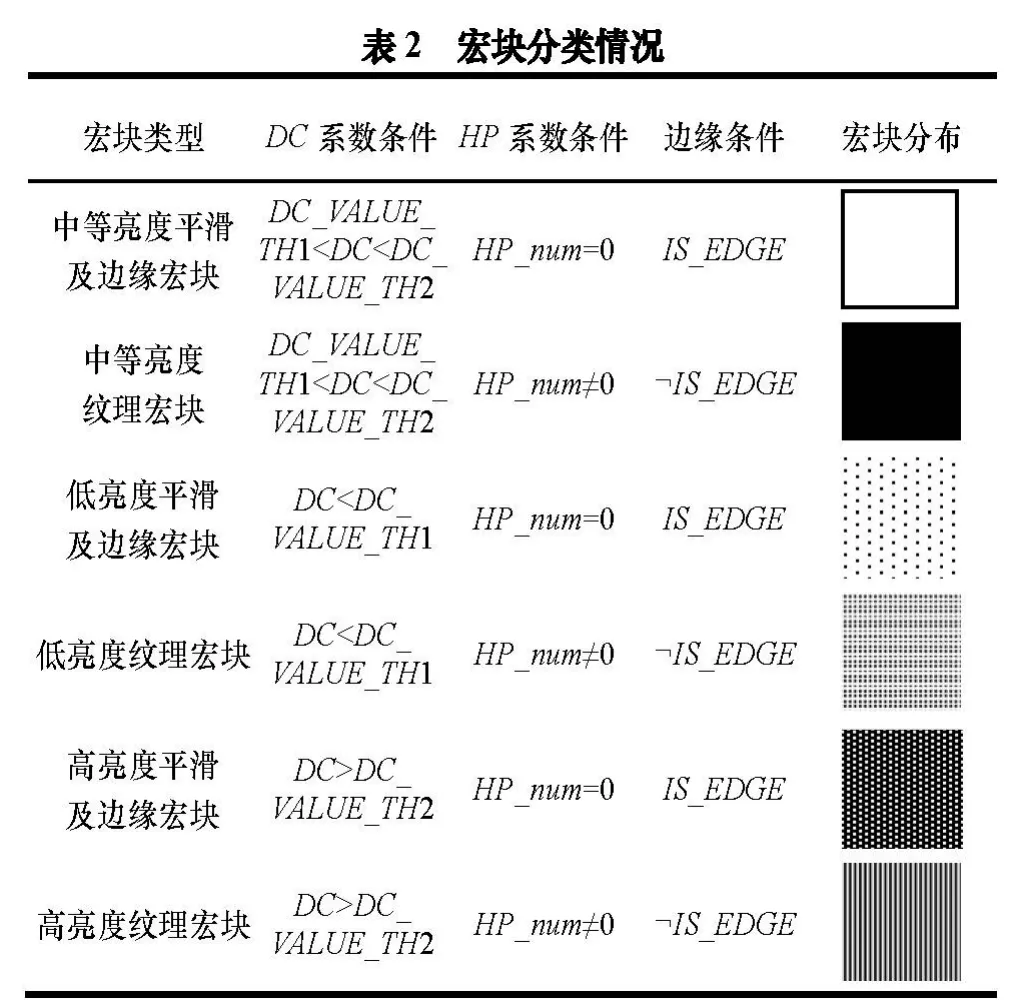
?

图4 宏块分类效果
4.2 量化参数计算
目前ITU-T发布的JPEG XR图像编码系统参考软件尚无码率控制功能,量化参数完全取决于用户的输入参数。缺省模式为使用统一量化参数模式并只输入一个固定量化参数值作为整幅图片各个色彩通道及各个宏块的量化参数。这样一幅图片的率失真性能就是该量化参数值的函数。本文改进了这种单一量化参数的编码方法,由缺省量化参数值计算出实际的量化参数集。
4.2.1 量化参数的个数
JPEG XR的DC、LP、HP 3种频带系数对码率及图像质量的贡献有所不同。文献[13]在统一量化参数模式下分析Lena图压缩码流中不同频带的码率情况,得到如下码率比:
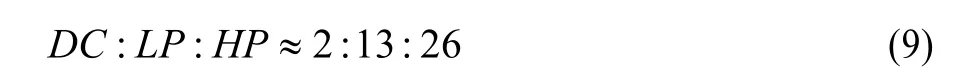
无论是对码率比的分析还是实验均表明,当量化参数改变量相同时,对HP系数量化参数的修改会使码率发生最大变化;而对 DC系数量化参数的修改则变化相对不大。因此,如果要大幅度调整码率,应改变HP系数的量化参数值;如果要调整图片质量同时保持一定范围内的码率,则应改变DC系数和LP系数的量化参数值。因此,需要将LP系数和HP系数的量化参数集合进行扩充。
量化参数集合并不是越大越好。原因主要有:每个宏块为了表示自身的量化参数,需要在码流中加入自身量化参数在量化参数集合中的序号。一个宏块的码率与量化参数集的关系[13]如式(10)所示:
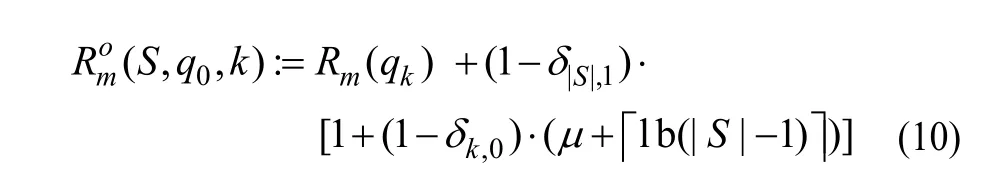
其中,R为该宏块的码率;m为宏块序号;q为量化系数;S为量化参数集;δ为选择某个量化系数或某种量化参数集的概率;μ为没有选择缺省量化系数的惩罚因子。从式(10)可见若量化参数集过大,则量化参数集本身就增大了码率;同时,如果选择量化参数集中排序靠后的量化系数,则要用更多的比特来表示这个量化系数的序号,就比排序靠前的量化系数更加耗费码率。
JPEG XR标准规定,相邻宏块之间的系数预测仅能在量化参数相同的情况下进行。量化参数的个数过多会导致相邻宏块之间量化参数相同的概率减小,也就减少了系数预测发生的次数,从而增加码率。
综上所述,本文算法实际使用的量化参数集合为:
(1)DC量化参数集:{DC_QP};
(2)LP量化参数集:{LP_QP_1, LP_QP_2};
(3)HP量化参数集:{HP_QP_1, HP_QP_2, HP_QP_3}。
4.2.2 基于缺省量化参数的实际量化参数计算
按照如下步骤计算实际量化参数:
(1)根据式(1)计算用户输入的缺省量化参数对应的缺省量化因子,用default_factor表示。
(2)根据式(11)分别计算各频带系数的实际量化因子。
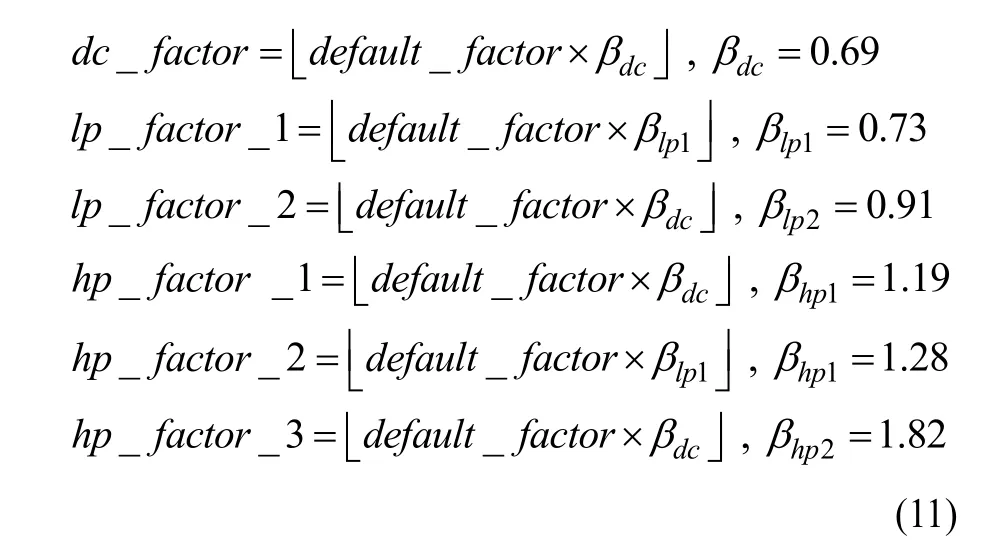
(3)根据式(1)对各个量化因子反推出对应的量化系数。
4.3 量化参数与宏块类型的对应关系
对于不同类型的宏块,从量化参数集中选择各个频带系数对应的量化参数,具体对应关系如表3所示。

表3 不同宏块类型对应的各频带量化参数
根据选择每种量化参数的宏块数,对量化参数在集合中的顺序进行排序,使对应宏块数较多的量化参数在前面,并使每个集合中对应宏块数最多的量化参数为该频带缺省量化参数。这样使得耗费在宏块量化信息上的码率最小。
4.4 算法整体流程
本文提出的自适应量化参数选择算法整体流程见图5。
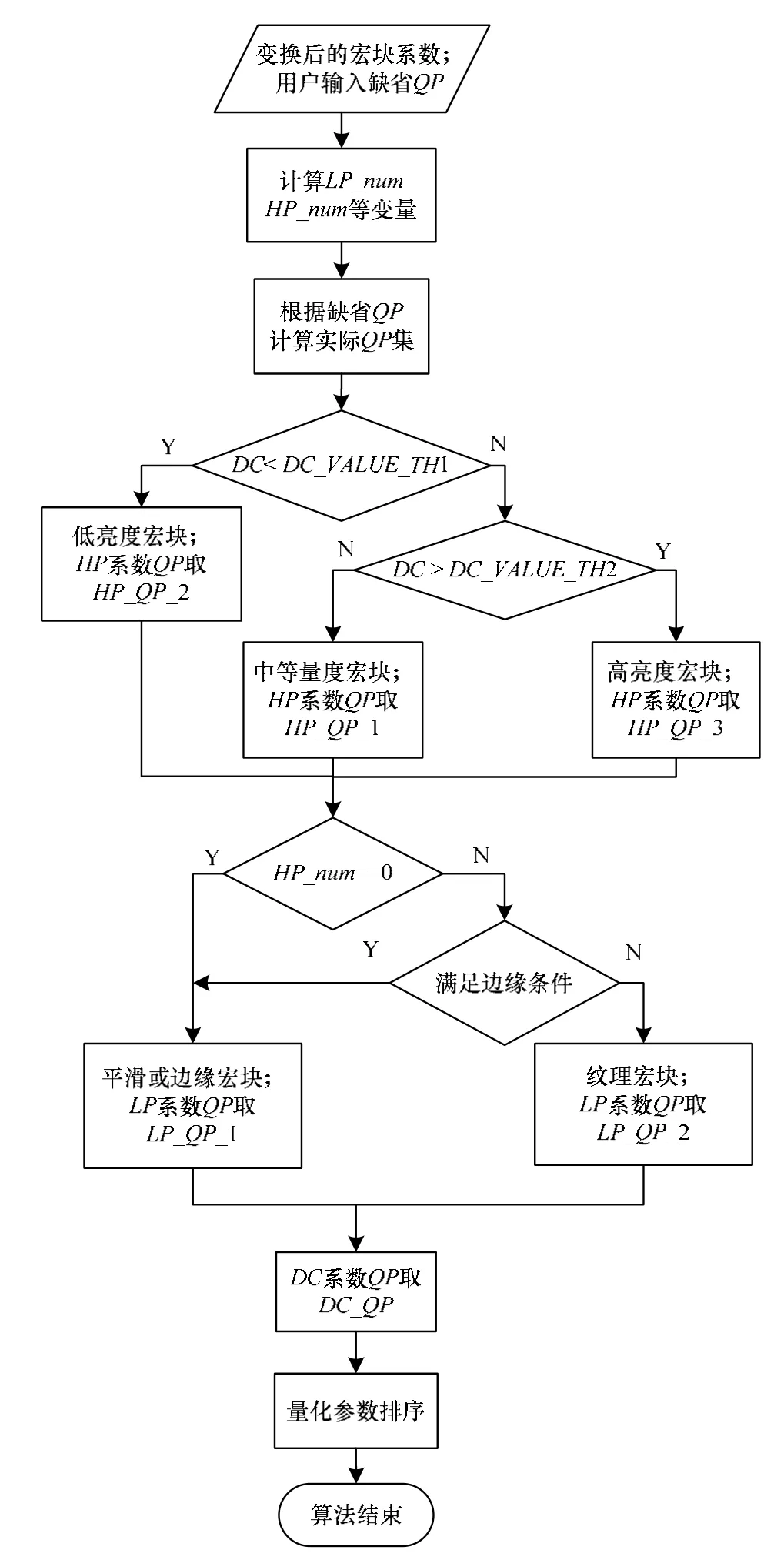
图5 自适应量化参数选择算法流程
5 实验结果与分析
在ITU-T发布的JPEG XR图像编码系统参考软件版本1.8(JPEG XR image coding system-Reference software 1.8)中,本文加入了上述自适应量化参数选择算法,选取多张标准实验图片,分别用原始的固定量化参数算法与本文算法在不同的输入量化系数下对它们进行编码。对输出的压缩图片用DCTune2.0计算其主观质量误差。
5.1 JND一致性
首先测试本文算法对图片JND的保持性能,即在相同的输入量化参数下,采用本文算法得到的图片主观质量与原始算法的图片主观质量应基本保持一致。图6和图7显示了2幅实验图片在不同输入量化参数下的JND曲线。

图6 Lena图JND曲线
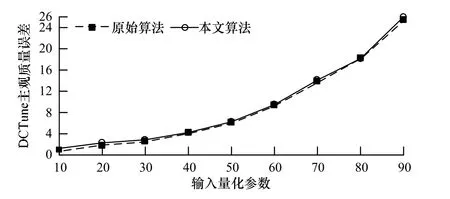
图7 Baboon图JND曲线
从曲线的重合程度可以看到,原始算法和本文算法的JND曲线基本重合,可见本文算法能够保持相同输入量化参数下的主观质量。
5.2 码率对比
对同一幅测试图片比较相同 DCTune主观质量误差下同一幅原始图片的不同压缩版本的码率大小,结果如表 4和表5所示。
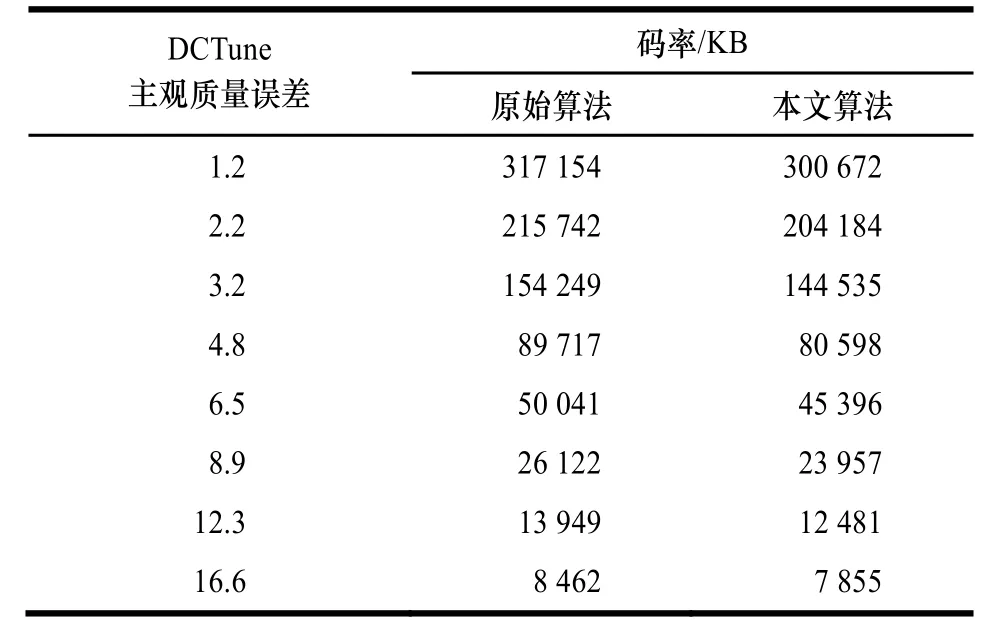
表4 相同DCTune主观质量误差下的Lena码率对比
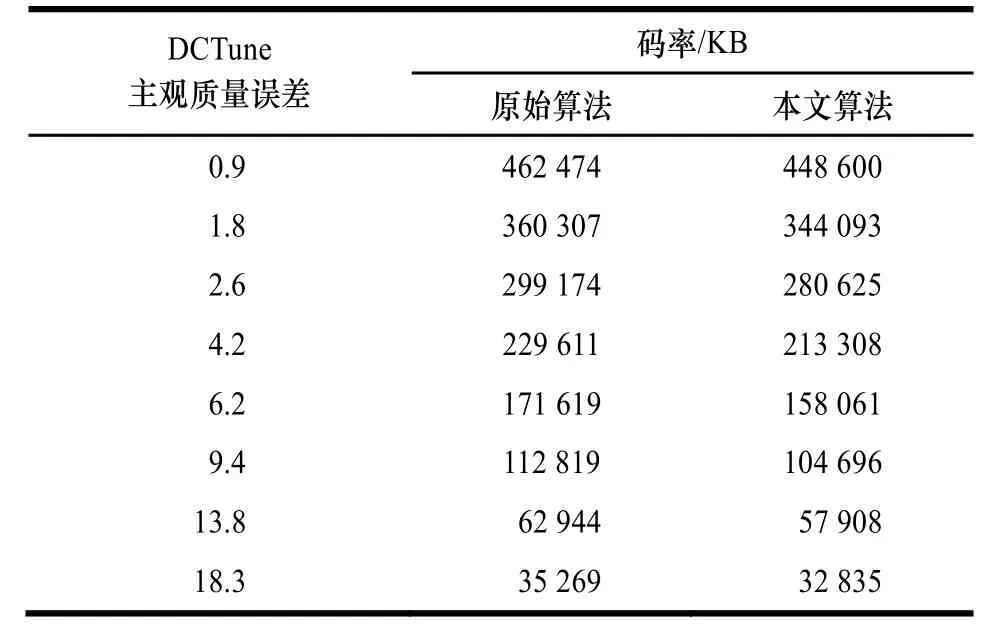
表5 相同DCTune主观质量误差下的Baboon码率对比
从表4、表5可看出,虽然2幅图片的原始压缩率有较大差别,但在各档次的 DCTune主观质量误差上,利用本文算法得到的图片码率均小于利用原始算法得到的图片码率。
5.3 压缩效率提升
本文从实验图片中选取了多幅具有代表性的典型图片,绘制了如图 8所示的在本文算法下不同图片的压缩效率提升百分比。压缩效率提升的计算公式如式(12)所示,其中,Bo和Bn分别代表原始算法码率和本文算法码率。

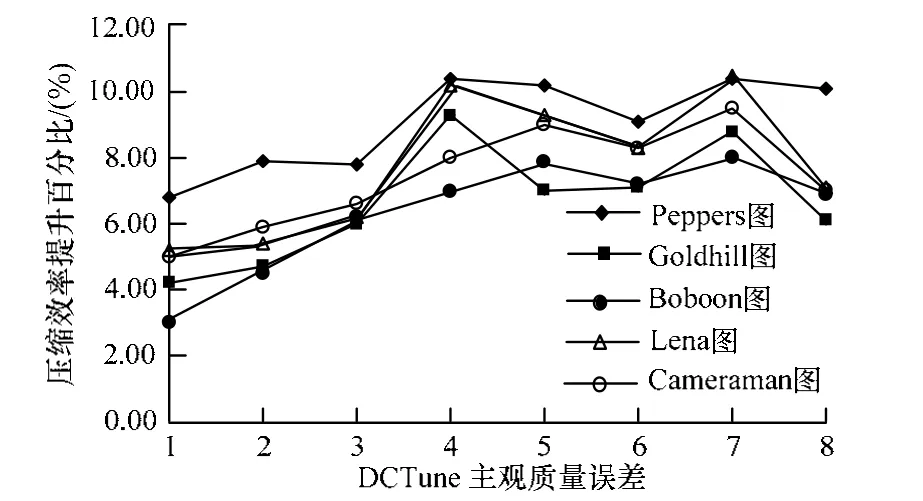
图8 典型图片的压缩效率提升
通过对图8进行分析可得出如下结论:
(1)从曲线的走势看出本文算法优化的趋势为,在主观质量误差较小,即图片压缩比较小的情况下,压缩效率相对提升不大;随着图片压缩比的增加,压缩效率提升变得明显,最大可达 10%;当图片压缩比进一步增大,压缩效率提升又逐渐减小。可见本文算法对于中等压缩比的图片具有较好的压缩效率提升效果。
(2)从不同曲线的对比看出,本文算法对于Peppers这类具有较多的中频成分,Lena这样纹理与边缘分布均匀、亮度适中的图片,以及Cameraman这样包含较多平滑区域的图片具有较好的优化效果,但对Baboon这样具有大量高频成分、纹理细节丰富的图片以及Goldhill这类整体图片较暗的优化效果稍差,原因是本文算法减少了占这类图绝大部分面积的复杂纹理区域或低亮度区域的码率分配。
在测试程序运行时间时发现,本文算法复杂度较低,加入自适应量化参数选择步骤后,相对于原始编码流程增加的软件运行时间几乎可以忽略。
6 结束语
本文将基于HVS感知特点的主观质量评价引入JPEG XR图像编码过程中,在保持压缩图像主观质量不变的前提下,利用自适应量化参数选择算法使压缩效率得到最高10%的提升。该算法不仅可应用在显微镜、照相机、医学影像仪器、视频监控系统等多种系统中,还为JPEG XR图像的主观质量提升提供了一种新的思路。今后的主要研究方向除了进一步提高优化压缩比并解决部分特殊图片压缩效率提升较低的问题,更重要的是扩展本文算法在运动JPEG XR编码标准中的应用,使其在视频编码中发挥作用。
[1]Srinivasan S, Tu Chengjie, Regunathan S L, et al.HD Photo: A New Image Coding Technology for Digital Photography[C]//Proc.of SPIE Optics and Photonics, Applications of Digital Image Processing XXX.San Diego, USA: SPIE Press, 2007.
[2]Dufaux F, Sullivan G J, Ebrahimi T.The JPEG XR Image Coding Standard[J].IEEE Signal Processing Magazine, 2009,26(6): 195-199.
[3]Tran T D, Liu Lijie, Topiwala P.Performance Comparison of Leading Image Codecs: H.264/AVC Intra, JPEG2000, and Microsoft HD Photo[C]//Proc.of SPIE Optics and Photonics,Applications of Digital Image Processing XXX.San Diego,USA: SPIE Press, 2007.
[4]Schonberg D, Sun Shijun, Sullivan G J, et al.Techniques for Enhancing JPEG XR/HD Photo Rate-distortion Performance for Particular Fidelity Metrics[C]//Proc.of SPIE Optics and Photonics, Applications of Digital Image Processing XXXI.San Diego, USA: SPIE Press, 2008.
[5]Schonberg D, Sullivan G J, Sun Shijun, et al.Perceptual Encoding Optimization for JPEG XR Image Coding Using Spatially Adaptive Quantization Step Size Control[C]//Proc.of SPIE Optics and Photonics, Applications of Digital Image Processing XXXII.San Diego, USA: SPIE Press, 2009.
[6]Gao Yu, Chan Duncan, Liang Jie.JPEG XR Optimization with Graph-based Soft decision Quantization[C]//Proc.of the 18th IEEE International Conference on Image Processing.Brussels,Belgium: IEEE Signal Processing Society, 2011.
[7]Tong H H Y, Venetsanopoulos A N.A Perceptual Model for JPEG Applications Based on Block Classification, Texture Masking, and Luminance Masking[C]//Proc.of the 18th IEEE International Conference on Image Processing.Chicago, USA:IEEE Signal Processing Society, 1998.
[8]江东明.视觉模型在JPEG2000中的应用研究[J].计算机工程, 2003, 29(4): 130-131.
[9]Malvar H S.Lapped Transforms for Transform Coding with Reduced Blocking and Ringing Artifacts[J]. IEEE Transactions on Signal Processing, 1998, 46(4): 1043-1053.
[10]Jia Yuting, Lin Weisi, Kassim A A.Estimating Just-noticeable Distortion for Video[J].IEEE Transactions on Circuits and Systems for Video Technology, 2006, 16(7): 820- 829.
[11]Ma Lin, King N N, Zhang Fan, et al.Adaptive Block-size Transform Based Just-Noticeable Difference Model for Images/Videos[J].Signal Processing: Image Communication,2011, 26(3): 162-174.
[12]Yang Xiaokang, Ling W S, Lu Z K, et al.Just Noticeable Distortion Model and Its Applications in Video Coding[J].Signal Processing: Image Communication, 2005, 20(7): 662- 680
[13]Richter T.Spatial Constant Quantization in JPEG XR is Nearly Optimal[C]//Proc.of 2010 Data Compression Conference.Snowbird, USA: [s.n.], 2010.
