云环境下基于DPSO的任务调度算法
2014-09-29邬开俊鲁怀伟
邬开俊,鲁怀伟
(兰州交通大学 a.电子与信息工程学院;b.数理与软件工程学院,兰州 730070)
1 概述
网络带宽的不断增长使得通过网络访问非本地的计算服务变成可能,助推了云计算技术的出现。它是将计算任务分布在大量计算机构成的资源池上,使用户能够按需获取计算能力、存储能力和信息服务[1-2]。云计算透过网络将庞大的计算处理程序自动拆分成多个较小子任务,然后按照适当的算法分配到虚拟计算资源上处理,再将分析、整合处理结果回传给用户。其面向的用户类型多样、计算任务数量巨大,并且各分布式的虚拟计算资源的处理能力各不相同,因此,如何将众多任务进行调度,满足用户对服务质量的要求且资源利用率较高变得十分困难。
目前云计算平台实际使用的调度算法有:单队列调度,简单但资源利用率低;公平调度,支持作业分类调度,但不考虑节点的实际负载状态,导致节点负载实际不均衡;容量调度,支持多作业并行执行,但队列设置和队列选择无法自动进行[3]。
为了解决现有调度算法的不足,一些新的调度算法被提出:文献[4]提出了基于优先级的加权轮转调度算法(PBWRR),文献[5]提出了优先级加权的滑动窗口算法(PWSW),文献[6]提出了基于优先权的自适应作业调度算法。文献[7]提出了一种云计算环境下科学任务流的调度方法。此外,智能优化方法也逐渐被引入。文献[8]提出了一种基于遗传算法(Genetic Algorithm, GA)的云计算环境下任务调度算法。文献[9]提出了一种基于GA的满足QoS需求的云计算任务调度方法。文献[10]提出了基于蚁群算法的云计算任务调度算法。但目前这方面的研究刚起步并不完善,因此,在该领域做一些有益的探索具有现实意义。
本文通过对云环境编程模型及任务调度问题的分析,并结合粒子群优化(Particle Swarm Optimization, PSO)算法,提出一种基于离散粒子群优化(Discrete Particle Swarm Optimization, DPSO)的任务调度算法。
2 云环境任务调度模型
现有的大部分云计算平台均采用 Google提出的MapReduce编程模型,它是一种分布式计算模型,用于大规模数据集的并行计算[11]。MapReduce作业就是一系列Map和Reduce函数,它们被提交给调度系统,并被调度到可用的计算资源上,其执行过程如图1所示。
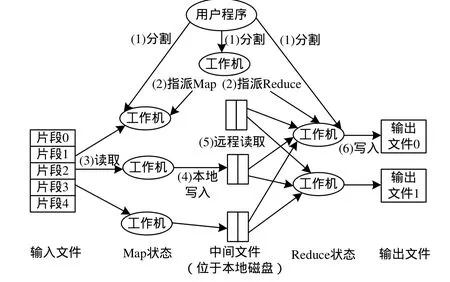
图1 MapReduce执行过程
Map操作将较大的任务分割成多个小的子任务,然后将这些子任务指派到若干计算资源上执行。之后,通过Reduce操作,得到最终结果。
云计算的资源有处理器、存储器、网络等,是按需使用、按使用量付费的。本文将这些资源统一视为计算资源,并假设:子任务所需运算量已知,计算资源的运算能力(速度)已知,子任务在每个计算资源上运行完成所需的时间已知,即:子任务的运算量与计算资源运算能力的比值。
假设子任务数记为M,计算资源数记为N,用M×N的矩阵ETC(Expect Time to Complete)来表示各计算资源上任务运行完成所需的时间,其中,ETC(i, j)表示第i个子任务在第j个计算资源上运行完成所需的时间。
在以上假设前提下,云计算任务调度问题可以简化为:如何将多个任务合理分配到各计算资源,使得所有任务的总完成时间最短。
3 标准PSO简介
粒子群算法是由美国心理学家Kennedy和电气工程师Eberhart于1995年提出的一种模拟鸟类群体觅食行为的仿生智能优化方法,它是一种基于群体智能的随机寻优算法,该算法利用鸟类群体个体对信息的共享机制,使整个群体的运动在问题的解空间中产生从无序到有序的演化过程,从而获得最优解[12-13]。

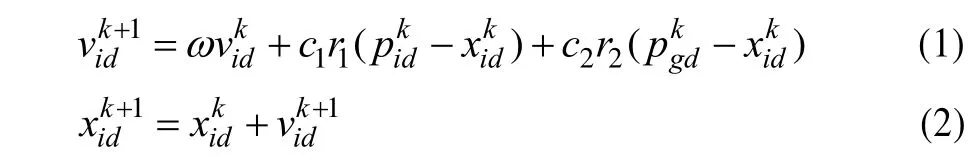
其中,ω称为惯性权重,其大小决定了对粒子当前速度继承的多少,用于平衡PSO的探索能力和开发能力,较大的ω使粒子在原来方向飞的更远,具有更好的探索能力,但收敛较慢,较小的ω使粒子拥有更好的开发能力,但可能导致陷入局优;c1和c2是学习因子,分别表示粒子向自己历史最优点和群体最优点靠近的程度;1r和r2是在[0,1]区间内均匀分布的随机数;为了减少迭代过程中微粒离开搜索空间的可能性,vij通常限定在一定范围内,即vij∈[- vmax,vmax],如果问题的搜索空间限定在 [- xmax,xmax]内,则可设定 vmax=k· xmax,0.1 ≤ k≤1。
4 基于DPSO的云环境任务调度算法
目前,关于粒子群算法的离散方面的研究还很有限,并没有一个很好的解决方案,离散变量进行加法和乘法时,需要专门的变通定义或者合法化处理[14]。因此,粒子群算法应用于离散的云环境任务调度时需要进行必要改进。
4.1 粒子编码
采用资源-任务间接编码方式:子任务顺序编码法[15],编码长度为子任务个数,编码每一位的值为占用的资源编号。假设有 5个子任务(T1,T2,T3,T4,T5),3个可用资源(R1,R2,R3),个体编码长度则为 5,每一位都在集合{1,2,3}中取值。如个体编码[3,2,3,1,2],其第1位编码是3表示T1在R3上运行,第2位是2表示T2在R2上运行,依此类推,第5位是2表示T5在R2上运行。解码结果即为:R1运行T4;R2运行T2,T5;R3运行T1,T3。
4.2 适应度定义
根据ETC矩阵和解码结果,可计算出各计算资源运行对应任务的完成时间。设分配到计算资源j上的子任务集合为Mj,则计算资源j的任务完成时间为EachRTime(j)为:
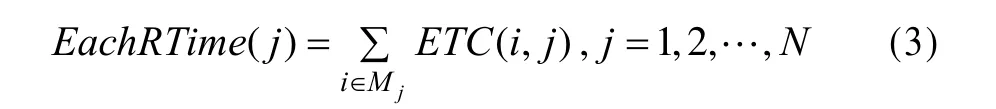
所有任务完成的时间AllRTime为各个计算资源任务完成时间的最大值:
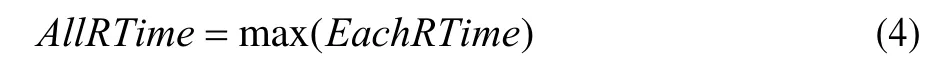
适应度函数定义为:

4.3 种群初始化
设种群规模为NP,子任务数为M,资源数为N,则随机初始化描述为:粒子初始位置为由系统随机产生NP个长度为 M 的个体,每个个体的每一位随机从集合{1,2,…,N}中取值。设 k=0.5、 vmax= 0.5N,则粒子初始速度为系统随机产生 NP个长度为 M 的向量,向量中每一位值vij∈[-0.5 N ,0.5 N]。
4.4 惯性权重的调整
为了让粒子在迭代初期具有较好的探索能力,在后期具有较好的开发能力,则需要随着迭代动态调整 ω。本文采用线性减小的变化方式:设最大迭代次数为 Imax,ω∈[ωmin,ωmax],则第i次迭代时的惯性权重ωi为:
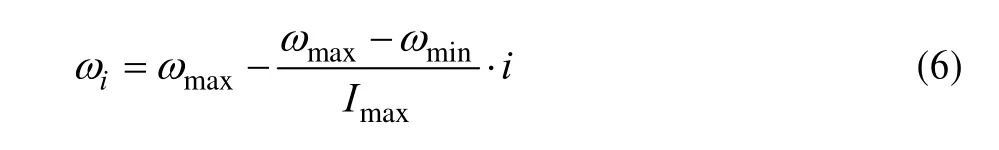
4.5 速度与位置更新及合法化处理
速度的更新按式(1)进行。位置的更新方法如下:首先,按式(2)的定义进行运算,得到含非法编码的一个新的编码序列。然后,对上面得到的新的非法编码进行合法化处理。本文定义的处理方法主要包含取绝对值、向上取整、求余等运算,记为:绝对值取整求余映射法,具体方法如下:
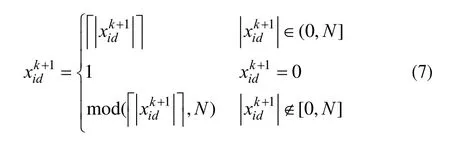
4.6 DPSO算法流程
DPSO算法具体步骤如下:
Step1 初始化参数:设置最大迭代次数Imax,种群规模NP,惯性权重取值范围 [ωmin,ωmax],学习因子c1、c2等参数。
Step2 随机初始化种群:对粒子群的随机位置和速度进行初始设定。
Step3 按式(5)计算所有粒子的适应度值。
Step4 对每个粒子xi,将其适应度值与所经历过的最好位置pi的适应度值进行比较,若较好,则将xi记录为该粒子经历过的最好位置pi。
Step5 对每个粒子xi,将其适应度值与全局最好位置pg的适应度值进行比较,若较好,则将xi作为当前的全局最好位置pg。
Step6 对每个粒子,按式(1)更新速度,按式(2)和式(7)更新位置。
Step7 若迭代次数大于最大迭代次数,则结束并输出结果,否则跳转到Step3继续下一次迭代。
5 仿真实验与结果分析
为评价和分析本文 DPSO算法的性能,在云计算模拟平台CloudSim-3.0.2中[16],通过改写DatacenterBroker类中的bindCloudletToVm方法,添加基于DPSO的调度算法,并且使用 Ant工具对平台进行重编译,从而将基于 DPSO的任务调度算法加入到模拟平台的任务单元调度中,进行模拟实验。同理,进行PSO和GA算法的环境配置。
设置计算资源节点数为10,待调度的子任务数为300,计算资源的计算能力和子任务的计算量使用Matlab随机产生。在此实验数据条件下,将DPSO与PSO、GA进行对比。
根据文献[14]的参数调整原则和多次实验情况,确定DPSO的参数设置如下:最大迭代次数Imax=200,种群规模NP=300,惯性权重的取值范围 [ωmin,ωmax]=[0.4,0.9],学习因子c1=c2= 2。
调度结果如下:在进行 200次迭代后,所有任务的最终调度时间:GA为472.41 s,PSO为467.90 s,DPSO为457.69 s。具体进化过程对比结果如图2所示。从中可以看出,DPSO算法的迭代过程体现了均衡的探索能力和开发能力,在进化过程中不断优化调度结果,最终得到 3种对比算法中的最优调度结果457.69 s。比较而言,标准PSO在进化过程的后期,探索能力不足,在进化前期迅速地探索到局部最优解467.90 s后就没能再跳出。然而,GA虽然在整个进化过程中优化能力比较均衡,但是性能较差,直到200次迭代结束,才优化到472.41 s,是3种比较算法中最差的调度结果。因此,无论是进化的收敛速度还是进化的最终结果,本文提出的DPSO算法都优于PSO和GA算法。
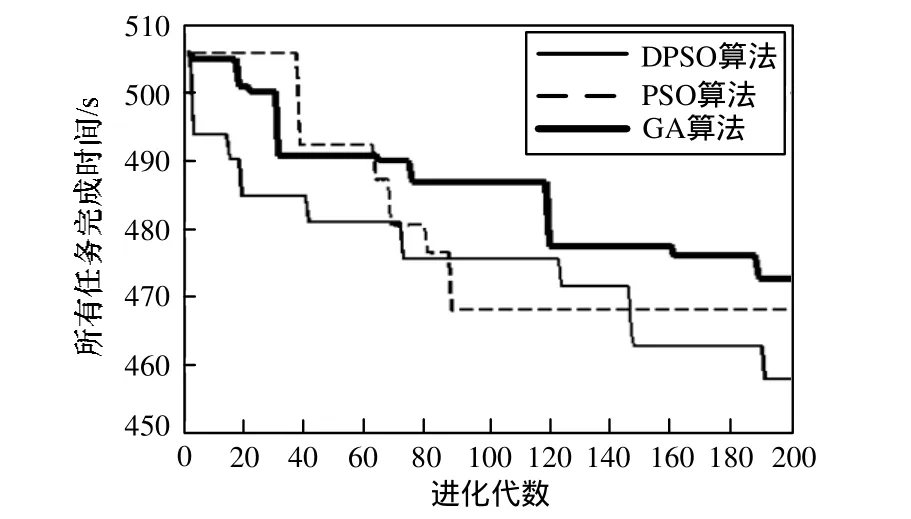
图2 所有任务完成时间的进化过程对比
6 结束语
针对云计算任务调度问题,本文提出一种基于离散粒子群优化的任务调度算法。在该算法中,采用随机方法初始化种群,利用时变方式调整惯性权重,并在位置更新中通过绝对值取整求余映射法进行合法化修复。适应度函数定义为各计算资源任务完成时间的最大值的倒数。通过对比实验可验证,本文提出的 DPSO算法能够有效地解决云计算环境下任务调度问题,并且算法收敛速度优于 GA和标准PSO算法,能够在较小的进化代数下取得良好的调度效果,为求解云环境下的任务调度问题提供了一种新思路。
[1]Armbrust M, Fox A, Griffith R, et al.Above the Clouds: A Berkeley View of Cloud Computing[EB/OL].[2009-02-10].http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-28.html.
[2]张建勋, 古志民, 郑 超.云计算研究进展综述[J].计算机应用研究, 2010, 27(2): 429-433.
[3]刘 鹏.云计算[M].2版.北京: 电子工业出版社, 2011.
[4]邓自立.云计算中的网络拓扑设计和Hadoop平台研究[D].合肥: 中国科学技术大学, 2009.
[5]张密密.MapReduce模型在Hadoop实现中的性能分析及改进优化[D].成都: 电子科技大学, 2010.
[6]陈艳金.MapReduce模型在Hadoop平台下实现作业调度算法的研究和改进[D].广州: 华南理工大学, 2011.
[7]Lin Cui.Scheduling Scientific Workflows Elastically for Cloud Computing[C]//Proc.of International Conference on Cloud Computing.Washington D.C., USA: IEEE Press, 2011:746-747.
[8]Ge Yujia, Wei Guiyi.GA-based Task Scheduler for the Cloud Computing Systems[C]//Proc. of 2010 International Conference on Web Information Systems and Mining.Sanya,China: [s.n.], 2010: 181-186.
[9]Dutta D, Joshi R C.A Genetic: Algorithm Approach to Costbased Multi-QoS Job Scheduling in Cloud Computing Environment[C]//Proc.of International Conference and Workshop on Emerging Trends in Technology.Mumbai, India:ACM Press, 2011: 422-427.
[10]范 杰, 彭 舰, 黎红友.基于蚁群算法的云计算需求弹性算法[J].计算机应用, 2011, 31(1): 1-7.
[11]雷葆华, 饶少阳, 江 峰, 等.云计算解码: 技术架构和产业运营[M].北京: 电子工业出版社, 2011: 132-135.
[12]汪定伟, 王俊伟, 王洪峰, 等.智能优化方法[M].北京:高等教育出版社, 2007: 217-223.
[13]张维存.蚁群粒子群混合优化算法及应用[D].天津: 天津大学, 2007.
[14]段海滨, 张祥银, 徐春芳.仿生智能计算[M].北京: 科学出版社, 2011: 63-85.
[15]李建锋, 彭 舰.云计算环境下基于改进遗传算法的任务调度算法[J].计算机应用, 2011, 31(1): 184-186.
[16]Calheiros R N, Ranjan R, Beloglazov A, et al.CloudSim: A Toolkit for Modeling and Simulation of Cloud Computing Environments and Evaluation of Resource Provisioning Algorithms[J].Software: Practice and Experience, 2011, 41(1):23-50.
