条件随机场图模型在《明史》词性标注研究中的应用效果探索
2014-09-22朱晓,金力
朱 晓,金 力
(复旦大学生命科学学院,上海200433)
从20世纪50年代起,自然语言处理就伴随着图灵机的提出成为计算机科学家们希望解决的问题之一[1-4].自然语言处理的研究范围主要包括以下几类:机器翻译、自动分词、词性标注、语法解析、名词实体识别以及实体关系识别.随着计算机技术在中国的快速发展,现代汉语的信息处理研究目前已经取得很多成果[5-10].但是,对于现代汉语的前身——古汉语的信息处理研究至今为数较少.目前只有少数研究者开展对古汉语语料中人名识别的研究[11],而国际会议上也仅出现一篇对文言文进行分句研究的文献[12].
古汉语信息处理研究相对滞后的原因主要有以下几点:①古汉语的信息化程度比较低.虽然国家已经设立重大项目资助历史学家将史书资料转换成电子版,但目前对古汉语的研究大部分还是基于纸质书籍,很多疑难汉字甚至都没有对应的计算机编码.② 古汉语的使用率低.在信息化的互联网时代,几乎不会有人在生活中以及互联网上使用古汉语.古汉语信息处理研究带来的商业价值较低,因此缺乏吸引力.③古汉语研究与信息处理技术缺乏有机结合.目前,大部分资深的古汉语语言学家对信息技术方面的了解十分欠缺,而另一方面从事古汉语信息处理的计算机工作者亟需古汉语语言学家提供大量的语料库以及语言学角度的科学帮助.
研究者们已经发现不同类型的语料学习得到的模型有着显著的差异.例如,新闻题材的知识模型应用到科学论文中的效率是十分低下的.在古汉语中也存在着各种各样的体裁:记叙类,如人物传记、志等;抒情类,如诗赋、辞赋等;议论类以及应用类等文体.编年体是中国传统史书中记载历史事件的一种体裁,以时间为中心,按年、月、日编排史实.中国著名的史书《春秋》、《资治通鉴》、《二十四史》等都是编年体史书.由于编年体体裁语料的时间线索明确、语法规整、易于学习,有利于学习模型的建立,因此本研究选用清张廷玉编的《明史》作为语料素材[13].
词性标注是序列标记算法在自然语言处理中的应用.序列标记算法是基于马尔可夫性质的统计模型.由马尔可夫性质直接转化的序列标记算法是著名的隐马尔可夫模型(HMM).然而,HMM的最大弱点是对状态转移的定义十分局限.随后根据需求,研究者又提出了最大熵马尔可夫模型(MEMM),该方法将最大熵算法中设置特征规则的方法借用到序列算法中.但是MEMM在实际应用中也存在明显缺陷,也就是经典的标识偏倚问题.条件随机场模型(Conditional Random Fields,CRF)的提出很好地解决了这个问题[14].条件随机场模型在现代汉语以及其他语言的词性标注研究被广泛应用,但是在古汉语词性标注中的应用目前尚没有.本研究将CRF应用于《明史》的词性标注.
对于现代汉语而言,分词(Word Segmentation)具有重要意义[6,10].现代汉语的词汇可以分为两大类,单音节词与多音节词.多音节词是两个或者三个及以上的音节(字)组成的词,这些音节组合形成一个完整语义.但是,这些组合在识别上会出现歧义,因此分词在现代汉语研究中是非常重要的一个步骤.然而,在古汉语中,文体主要由单音节词组成,只有少数的名词或动词以多音节词形式出现.这类词多为一些专有名词,如皇帝的称号、固定的地名等.除了专有名词比较难以判别,其他多音节词的组合基本符合一定的词法规则.因此,对于古汉语分词而言,我们仅需要对专有名词进行分词.本研究将在已分词与未分词基础上探讨CRF三种图模型在古汉语词性标注中的应用.
1 材料与方法
1.1 古汉语研究材料
选取《明史》[13]第十五到第十八本纪进行词性标注研究.该部分语料包含3 603个句子,20 037个单字,其中非重复词2 130个.
1.2 古汉语研究材料信息化处理
在对古汉语材料进行词性标注研究之前,我们首先需要将古汉语语料转换成计算机可处理的编码.我们选择以英语语法的10种词性作为基本词性,包括名词、动词、副词、形容词、介词、连词、数词、代词、助词、量词.为了方便提取时间和人物信息,我们在这套标注系统中新增了时间和姓名相关的标签,将专有名词中的时间以及人名单独进行标记.将天干、地支、姓氏以及人名作为4类特殊的标记,加上前面的11种标记,一共设定了15大类标签.词性的标签集合为1:名词;2:专有名词;3:动词;4:形容词;5:副词;6:数词;7:助词;8:量词;9:代词;10:介词;11:连词;12:姓氏;13:天干;14:地支;15:人名.
在未分词词性标注研究中,我们对每个单音节词进行信息化处理.在已分词词性标注研究中,我们还将对语料中的专有名词进行分词,即将多音节专有名词作为一个计算机字符处理.
1.3 词性标注方法
在本研究中,我们将基于条件随机场模型(CRF)的三种图模型应用在古汉语词性标注研究中[15].条件随机场是一类鉴别式无向图概率模型[14].对于一组观察值x以及一组符合一定条件概率分布的随机变量y,Lafferty对CRF的图模型定义如下:给定一个图G=(V,E),y对于G上的节点集合V中的每一个节点v都有一个标签yv,如果x能够条件决定yv,并且对于G中的任意点的随机变量yv满足马尔可夫性质,那么条件分布P(y|x)便是一个条件随机场模型.根据随机场的基础理论,这个模型的联合条件概率被定义为
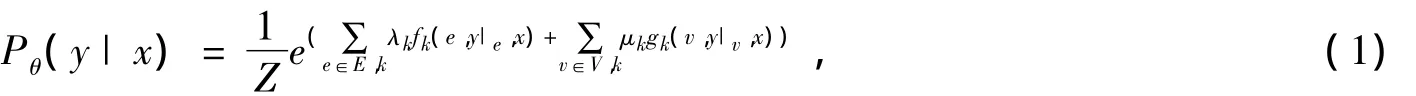
其中,fk(·)和gk(·)分别表示边特征函数和点特征函数.λk和μk表示待估计的特征函数权重.Z表示一个固定的标准化因子.
1.3.1 条件随机场模型的特征设置
特征设置的多样化是CRF的主要优势,对于常规的文本自动标注系统而言,常用的特征有以下几种类型:①边特征:该特征描述条件转移概率.如果假设序列中只有邻接的两个元素存在转移条件,那么CRF图就是一条条转移链.如果假设序列中的某个元素与周围n个元素存在转移条件,则整个随机场成为一张连通图.n越大计算复杂度越高,抽提的特征越丰富,但同样也会带来过拟合的现象.目前现代汉语使用的最高的n元模板的维度是6.②序列起始特征:记录着序列标签的起始状态,在算法中负责检测当前的标签是否能成为一个起始状态标签.③序列终止特征:记录着序列标签的终止状态,在算法中负责检测当前的标签是否能成为一个终止状态标签.④单词特征:该特征负责检查当前的元素在词典中的标签类型以及分布,并按照词典中已有的标签分布给当前元素一定的权重.⑤未登录词特征:该特征负责对词典中查找不到的元素定义标签权重.
1.3.2 三种图模型的选择
比较三种基于条件随机场的图模型在古汉语词性标注中的应用.①无边图模型:该模型构建的图不加入边特征,而只考虑单词自身的属性进行词性判断,如起始特征、结束特征以及在训练词典中的词性概率等.②完全图模型:给定一组标签序列,该模型将构建出每一对元素之间的边,包括该元素与自己的边特征.当给定训练集后,该模型将使用训练集中的转移概率来设定边特征的权重.③ 嵌套图模型:在这个图模型的概念中,一个序列将被视为多个分节序列.每个分节之间组成的连通图被认为是具有马尔可夫性质的随机场,而每一个分节被视作一个子序列图模型.
1.3.3 交叉检验
采用交叉检验方法评估CRF三种图模型在古汉语词性标注中的应用效果[16].首先,我们将元数据平均拆分成10份,每次选择其中9份作为训练集进行模型学习,然后利用剩余一份作为测试集进行模型测试.如此重复选择不同的训练集和测试集,共进行10次测试.最后,我们通过几个统计量评估模型测试结果.①精确性(Precission):指预测结果中正确的结果占全部预测结果的比例,描述了预测模型的可信度;②召回率(Recall):指实际情况中被预测模型预测到的结果比例,描述了预测模型对现实数据的识别率;③Fβ测量值:是对前两个指标综合评定的一个得分.具体的公式为

其中β参数的设定表示研究者认为召回率在目标模型中的重要性是精确性的β倍[17].本研究中,我们选择使用F1测量值.
2 结果与分析
2.1 未分词词性标注结果
2.1.1 三种模型的词性标记结果
三种CRF图模型的词性标注结果如表1所示,完全图模型和嵌套图模型的效率相当,比无边图模型的效率稍好一些.
在15个词性标记中,天干和地支的识别效率是最高的.这是因为编年体中天干、地支作为一个月里对时间的衡量,形式十分简单,构词完全固定,因此准确率和召回率均相当高.但在结果中也存在判断错误的极少个例,大部分情况是将天干地支标注成了专有名词.另外,数词的词性标注也有很高的效率,因为数词是一个观察值比较固定的词性.数词判别的主要错误出现在精确性上,模型通常会将作为其他词性出现的数字误认为是数词.
实验结果中形容词、量词、连词的识别效率相对于其他的词性而言十分低下.其中,量词和连词的识别效率十分低下主要是因为数据集中量词和连词的含量过少,导致模型学习不成功.形容词的识别效率低下则是因为词性的活用过多,大部分形容词可以作为名词使用.反之,不少专有名词也有形容词参与构成,因此对形容词进行词性标注的精确性和召回率都非常低.
2.1.2 登录词与未登录词结果比较
由于在编年体中一段时间内会重复出现同一件事物,因此在测试集中识别出的姓名、专有名词等可能是在训练集中已经存在的.我们将测试集与训练集共同出现的词定义为已登录词,而将测试集出现、训练集未出现的词定义为未登录词.我们将未登录词与已登录词分开,检验CRF三种图模型的词性标注效果.由于大部分词性标记在训练集中已经被覆盖,因此在本次试验中我们排除了在训练集中已经完整的标记,而仅对剩下的5个标记(名词、专有名词、动词、姓氏、人名)进行检验.
统计结果如表2所示,总体而言,三种CRF图模型对未登录词的识别效率要比已登录词的识别效率低很多.其中,无边图模型作为边特征效率的负对照实验,其对未登录词的识别效率几乎为0.而完全图模型和嵌套图模型对未登录词的识别效率要高于无边图模型.
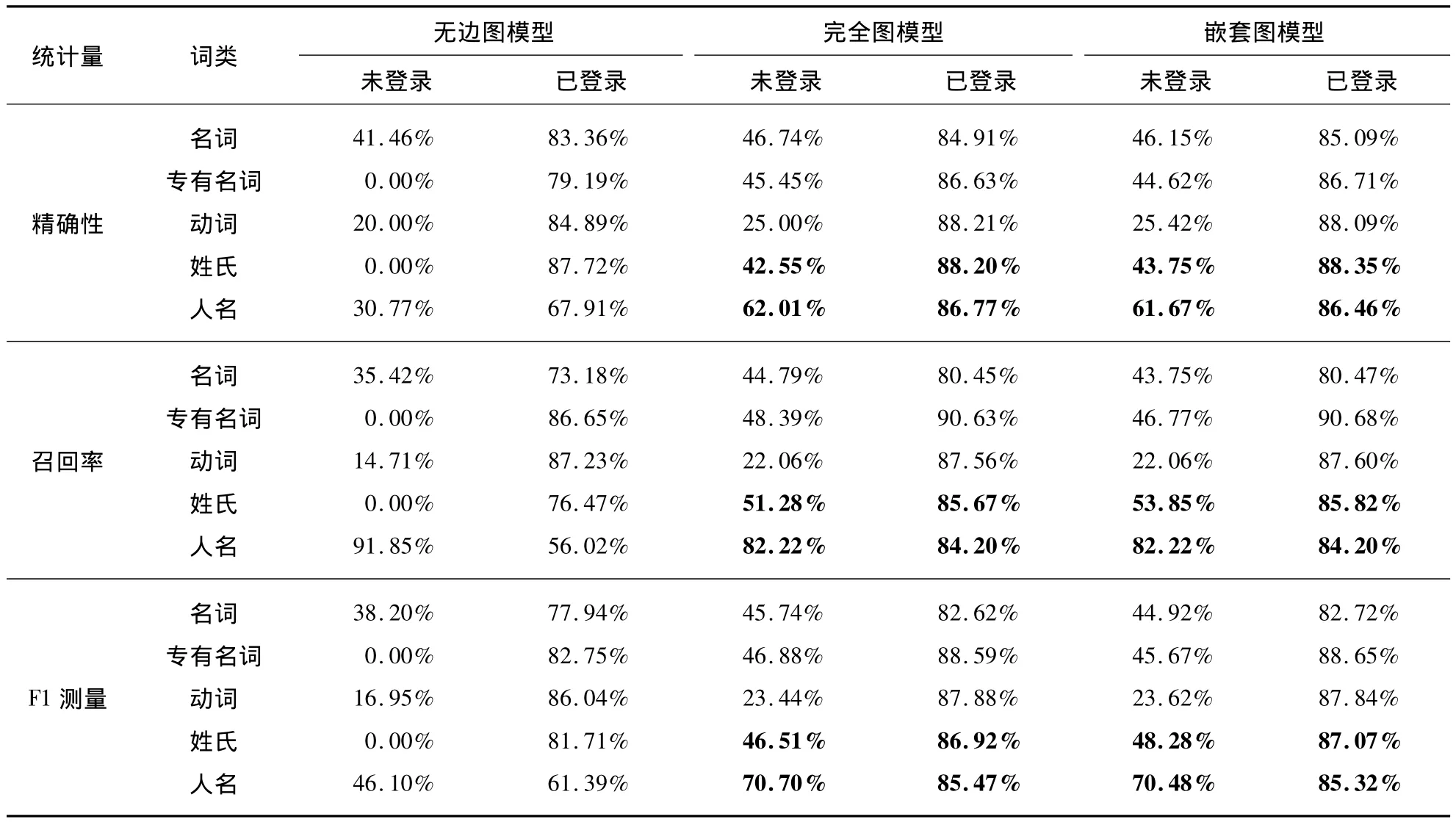
表2 无边图模型、完全图模型和嵌套图模型对未分词已登录词与未登录词词性标注结果Tab.2 Part-of-Speech tagging results of no edge,complete and nested graph models on listed and unlisted words in testing set without word segmentation
在完全图模型和嵌套图模型的结果中,我们发现两个模型对未登录词中姓氏和人名的识别效率已经达到70%.相比于很多未登录词词性标注识别效率低下的结果而言,该现象表明CRF完全图模型和嵌套图模型对于姓氏和人名的推断能力是比较强的,暗示着编年体中姓氏和人名周围的词较其他词性标签拥有很好的规则.
2.2 已分词词性标注结果
上一组实验是基于未分词的数据集,一般在现代汉语中词性标注是基于分词之后的语料.而分词在古汉语中与现代汉语有所不同,只有专有名词才存在分词单元的划分问题,其他的词都是单音节词,每个单字即为一个单独的分词单元.因此即使不单独的进行分词,词性标注的结果仍然可以接受.然而专有名词的多音节词对于其他的词性的标注效率或多或少有一定的影响.因此在这组实验中,假设存在一个强大的专有名词词典,已经将所有的专有名词事先划分开,而我们则在此基础上进行词性标注.
实验结果(表3)表明,对专有名词进行分词之后三种CRF图模型对15类词性标记的识别效率较未分词前均有小幅的提升.
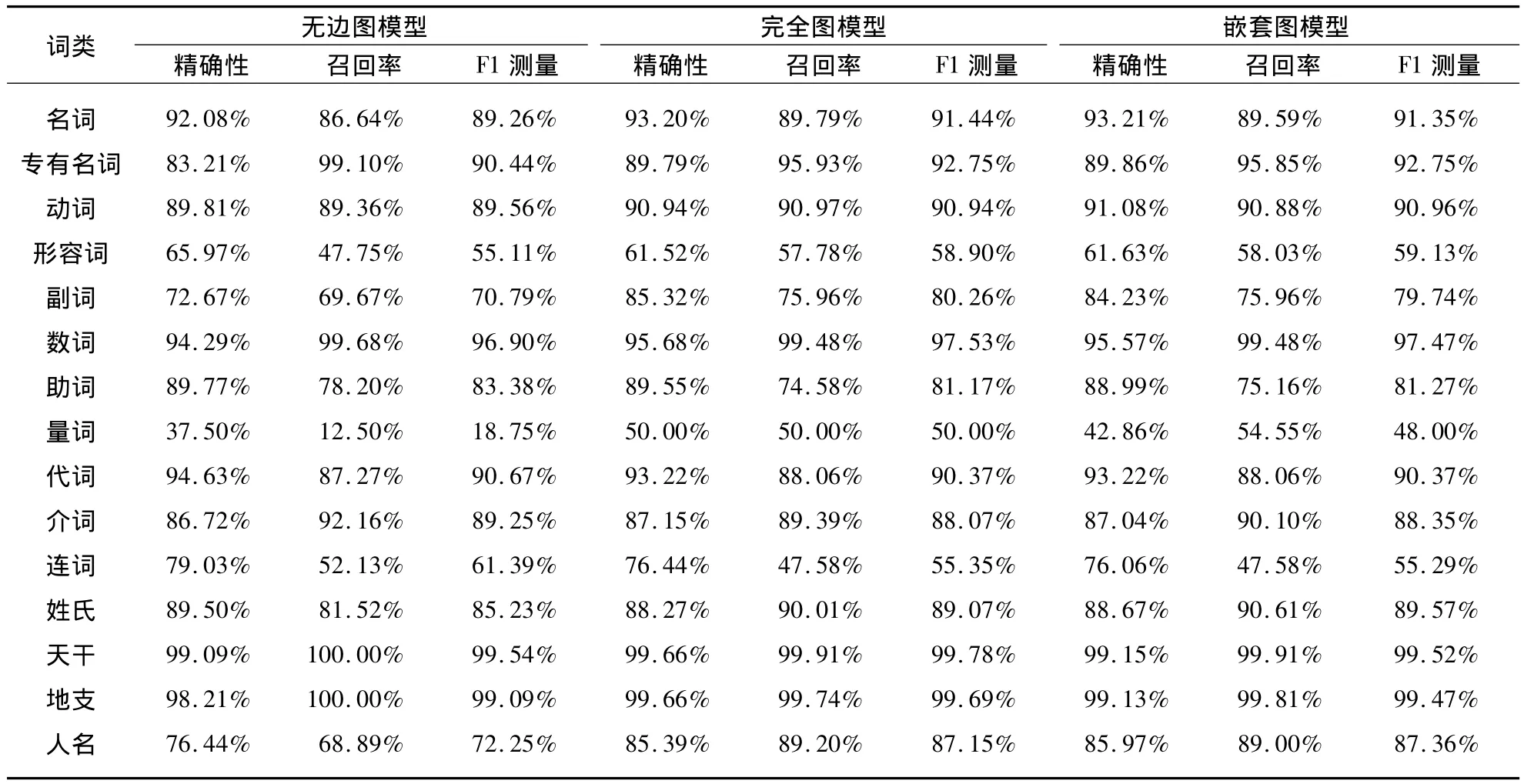
表3 无边图模型、完全图模型和嵌套图模型对专有名词分词训练集与测试集词性标记结果Tab.3 Part-of-Speech tagging results of no edge,complete and nested graph models on training and testing sets with word segmentation of proper nouns
我们同样对未登录词与已登录词的识别效率进行了一个统计比较,结果见表4.进行专有名词分词之后,三种CRF图模型对已登录词的词性标注效率明显提高,但是对于未登录词的词性标记效率却不尽然.对于未登录词,完全图模型和嵌套图模型对专有名词、姓氏以及人名的识别效率较分词之前有所提升,但是对于名词以及动词的识别效率没有提升.而无边图模型对除了专有名词之外的未登录词的识别效率仍然十分低下.
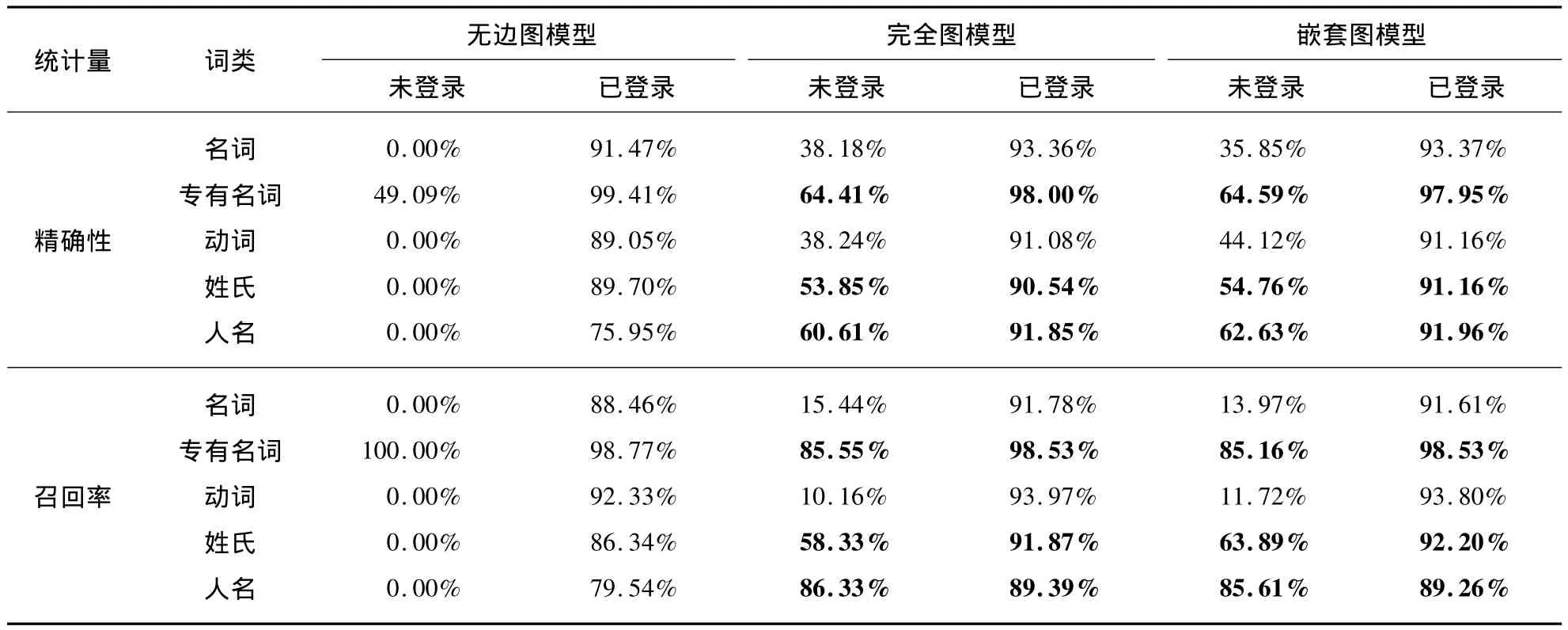
表4 无边图模型、完全图模型和嵌套图模型对分词后已登录词与未登录词词性标注结果Tab.4 Part-of-Speech tagging results of no edge,complete and nested graph models on listed and unlisted words in testing set with word segmentation
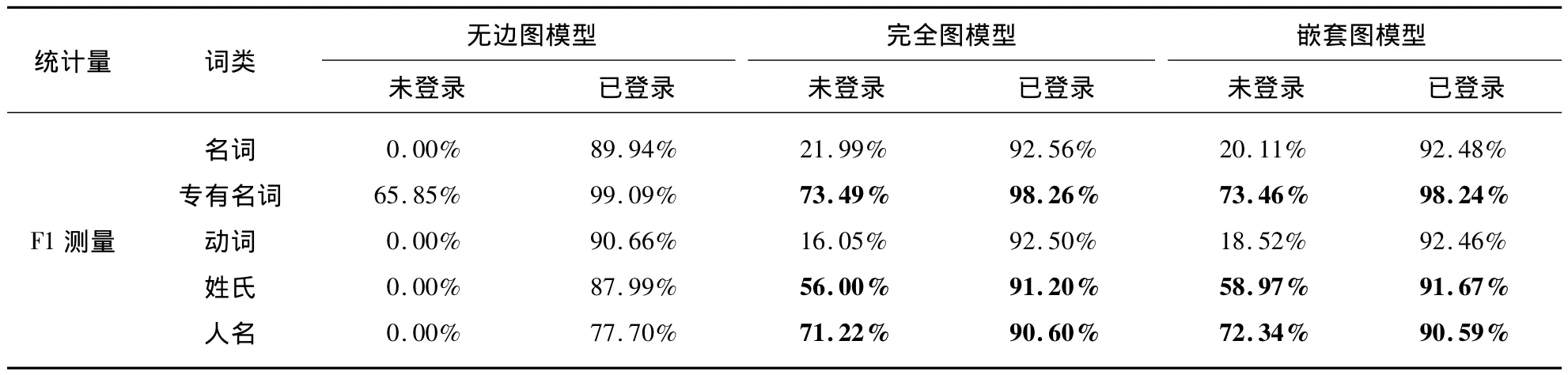
(续表)
3 讨论
3.1 古汉语信息化处理的意义
古汉语作为一门承载了数千年中华文明的语言,对其进行信息处理研究具有重要的价值.一直以来,对于古汉语资料的研究仅限于语言学专业研究者.这在一定程度上限制了中华文华传承以及当今交叉学科的发展.目前已经有部分研究者开始重视古汉语的信息化处理,但是目前尚没有完整的古汉语语料库以及词典,亟需语言学家与计算机信息技术人员的共同努力探讨古汉语信息处理的相关问题.
智能地从大量史书中提取信息对很多学科研究有着重要的辅助作用.例如,史书记载的家谱信息对人类学研究具有重要意义.目前历史人类学家希望依赖分子生物学的手段去寻找一些历史考证的线索,其中最具有解释性的生物学证据就是Y染色体的父系进化体系[18].父系在Y染色体上由于没有同源重组的发生使得进化足迹趋近于一颗庞大的多叉树,每一代可能发生的突变代表着树中的一个节点.而中国的父系家族往往都有家谱的记载,也就是说如果家谱中的记载准确并且分子进化树的构建足够精细,我们就能够将DNA突变与历史中某个时间甚至某个人对应.这不仅为解析历史提供了很好的佐证,同时也为生物进化研究赋予生命力.
古汉语的语法和词法特点与现代汉语有相似之处,可能对现代汉语的研究有一些辅助作用.在现代汉语研究中,多数研究者认为汉语相比于英语更难处理的地方在于汉语语法句法上的灵活性,很难依赖形式语法抽象出一套规则.古汉语是现代汉语的原型,句法和语法相对规则化,研究古汉语也许能够给现代汉语的语法解析带来启发.
3.2 基于条件随机场的图模型在古汉语词性标注中的应用
条件随机场模型(CRF)与最大熵马尔可夫模型(MEMM)都是适用于自然语言处理的方法[19].CRF优于MEMM之处在于CRF将标签之间的转移特征以随机场的图形式展现出来,抽象为点特征与边特征[20].点特征描述某一个待标记对象自身观测值的概率,而边特征描述待标记对象周边的标签对其条件转移概率[15].这样就解决了MEMM中观测值的分布概率无法影响模型概率的标签偏倚问题.条件随机场模型在现代汉语的信息处理研究中已经比较成熟,刘滔等对现代汉语词性标注的研究结果展示CRF对非兼类词(单一词性)的识别效率高达96%,对兼类词的识别效率也达到94%[21].
在本研究中,我们发现基于条件随机场的完全图模型和嵌套图模型在古汉语词性标注中的应用效果均相当好.我们还探讨了古汉语分词对词性标注的影响.在现代汉语中,研究者已经成功使用分词系统来辅助实体识别[5],但是在古汉语中还没有完整的分词系统.在本研究中,我们发现所选语料中只有专有名词存在分词的必要,而其他词汇基本是单音节词.因此,我们比较了专有名词未分词与分词之后三种CRF图模型对古汉语语料词性标注的效果,发现分词后的词性标注结果比未分词的结果要好一些.这说明古汉语分词对提高词性标注的效率是有帮助的.
3.3 古汉语词性标注错误的探讨
虽然在古汉语词性标注的实验结果中,整体效率已经达到91%以上,但是其中仍然不乏大量错误.我们将其总结为3大类错误.
3.3.1 未登录词识别错误
我们对测试集中的已登录词与未登录词分开探讨,发现三种模型对未登录词的识别效果远远低于已登录词.尤其是无边图模型对未登录词的识别效果几乎为0.这可能与无边图模型没有考虑边特征有关.而且我们发现分词对未登录词的词性标注效果也没有很大提高.例如,在序列“命诸司详议害民弊政”中,“害”实际上为形容词,但在测试集里“害”是一个未登录词,于是CRF模型依据边特征对“害”进行了词性判断,考虑到上位单词“议”是一个动词,模型错误的将“害”标记成名词.
3.3.2 词典中具有多个词性的单词词性判断错误
词典里单词的词性分布对标注结果有着较大的影响.如果某个单词具有多个词性,而且不同词性的分布差异很大,则很可能会导致模型将单词自动标注为分布较大的词性.如序列“修撰吕柟言大礼未正”中,“正”在编年体中最常出现的组合是“正月”,所以在词典中“正”作为名词的频率要高于其他词性.而实际上在这个序列中“未正”是一个副词加上动词的组合,然而因为“正”的判断错误,模型将两个单字都标注为名词.
3.3.3 强标注转移特征导致错误
描述转移规则的边特征同样也会带来词性判断失误.这一类错误常见于一些出现频率高的词性组合,如姓氏和人名的组合、天干和地支的组合等.如序列“永顺伯薛斌恭顺伯吴克忠领马队”,动词后接一个人物是很常见的句式,而动词“领”的下位词又恰好是一个常见的姓氏“马”,因此模型将“马”标记为姓氏,将“队”标记为人名,但是这里“马队”显然代表的是一只骑兵队伍.又如序列“代府奉国将军充灼谋反”中,由于“充灼”在训练集中已经被观测为人名,因此“充灼”的上位词被标注为姓氏.
这些错误有些需要人为修正,例如单词具有多个词性导致的错误,需要古汉语语言学专家与计算机信息处理研究人员共同合作对其加以修正.而有些错误,例如未登录词识别错误,可能需要发展更有效的计算机信息处理方法才能有效解决.总而言之,古汉语信息处理仍然需要古汉语语言学相关专家以及计算机信息处理研究人员的共同努力,以期取得长足的发展.
我们的研究结果表明基于条件随机场的完全图模型和嵌套图模型对编年体体裁的《明史》语料的词性标注效果不错.但是,对于该方法是否适用于其他体裁的古汉语语料信息化处理,仍然需要研究者进一步探讨.
[1]Turing A.Computing Machinery and Intelligence[J].Mind,1950,59(236):433-460.
[2]Chowdhury GG.Natural language processing[J].Annual Review of Information Scienceand Technology,2003,37(1):51-89.
[3]Pereira F C N,Gross B J.Natural Language Processing[M].Cambridge:MIT Press,1994.
[4]Jurafsky D,Martin J H.Speech and Language Processing:An introduction to Natural Language Processing,Computational Linguistics,and Speech recognition[M].New Jersey:Pearson Education Inc.,2000.
[5]Gao J,Li M,Wu A,et al.Chinese Word Segmentation and Named Entity Recognition:A Pragmatic Approach[J].Computational Linguistics,2005,31(4):531-574.
[6]Huang C R,Chen K J,Chang L L.Segmentation standard for Chinese natrual language processing[C]∥Proceedings of the 16thConference on Computational Linguistics.Stroudsburg,1996:1045-1048.
[7]Jin G, Chen X.The Fourth International Chinese Language Processing Bakeoff:Chinese Word Segmentation,Named Entity Recognition and Chinese POSTagging[C]∥Proceedings of the Sixth SIGHAN Workshop on Chinese Language Processing.Hyderabad,India:Association for Computational Linguistics,2008:61-68.
[8]Levow G A.The Third International Chinese Language Processing Bakeoff:Word Segmentation and Named Entity Recognition[C]∥Proceedings of the 5thSIGHAN Wookshop on Chinese Language Processing.Sydney,Australia:Association for Computational Linguisties,2006:108-117.
[9]刘开瑛.中文文本自动分词和标注[M].北京:商务印书馆,2000.
[10]苗夺谦,卫志华.中文文本信息处理的原理与应用[M].北京:清华大学出版社,2007.
[11]汪青青.先秦人名识别初探[J].文教资料,2009(18):202-204.
[12]Huang H H,Sun C T,Chen H H.Classical Chinese Sentence Segmentation[C]∥Proceedings of the CIPSSIGHAN Joint Conference on Chinese Language Processing.Beijing,2010:15-22.
[13]张廷玉.明史[M].北京:中华书局,1974.
[14]邱 莎,段 玻,申浩如,等.基于条件随机场的中文人名识别研究[J].昆明学院学报,2011,33(6):64-66.
[15]Lafferty J,McCallum A,Peraira F C N.Conditional Ramdom Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]∥Proceedings of the 18thInternational Conference on Machine Learning.USA:Morgan Karfmann Publishers Inc.,2001:282-289.
[16]Kohavi R.A Study of Cross Validation and Bootstrap for Accuracy Estimation and Model Selection[C]∥Proceedings of The Fourteenth International Joint Conference on Artificial Intelligence.Montreal,Quebec,Canada,1995:1137-11.
[17]Chinchor N,Sundheim B.MUC-5 Evaluation Metrics[M].the 5thconference on Message Understanding.1993:69-78.
[18]Ke Y,Su B,Song X,et al.African Origin of Modern Humans in East Asia:A Tale of 12,000 Y Chromosomes[J].Science,2001,292(5519):1151-1153.
[19]McCallum A,Freitag D,Pereira F.Maximum Entropy Markov Models for Information Extraction and Segmentation[C]∥Proceedings of the 17thInternational Conference on Machine Learning.USA:Morgan Karfmann Publishers Inc.,2000:591-598.
[20]Duan H,Zheng Y.A Study on Features of the CRFs-based Chinese Named Entity Recogniztion[J].International Journal of Advanced Intelligence,2011,3(2):287-294.
[21]刘 滔,雷 霖,陈 荦,等.基于MapReduce的中文词性标注CRF模型并进行训练研究[J].北京大学学报:自然科学版,2013,49(1):147-152.
